 @davej@dice.camp
@davej@dice.camp2026-06-25 11:14:04
Per @…'s suggestion—following on from @…’s theme last week, and much more in keeping with my own wintry location—today’s #ThursdayFiveList

 @padraig@mastodon.ie
@padraig@mastodon.ie2026-07-24 15:05:29

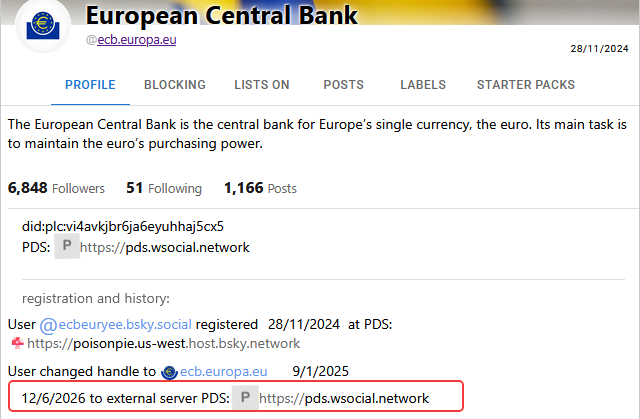
 @cdarwin@c.im
@cdarwin@c.im2026-07-22 00:14:52
Astronomers hypothesized that the Milky Way was flipped on its side following a direct hit from a wayward galaxy long before the solar system was born.
The cataclysmic collision is thought to have taken place about 10bn years ago
when the Milky Way was struck head-on by an incoming dwarf dubbed the Gaia Sausage.
The Milky Way tore the interloper to shreds and absorbed its stars,
but the chaos unleashed in the event probably flipped the entire disc of the Milky Way by m…

 @hynek@mastodon.social
@hynek@mastodon.social2026-07-22 13:17:23
Career advice from people who cannot follow it themselves, but whose careers benefit from your following it, should be taken with a grain of salt. #influencers
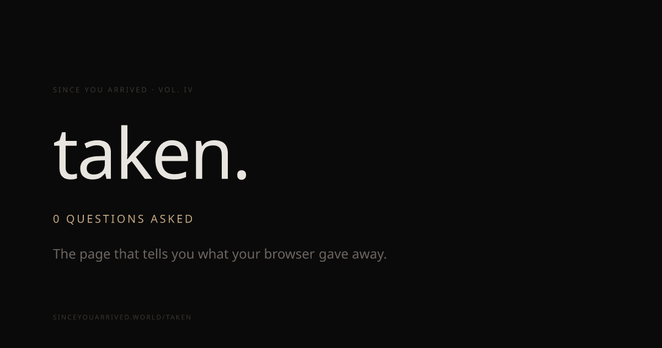
 @migueldeicaza@mastodon.social
@migueldeicaza@mastodon.social2026-05-09 13:00:14
“You opened this page. It already knows the following.”
https://sinceyouarrived.world/taken
 @Mediagazer@mstdn.social
@Mediagazer@mstdn.social2026-07-09 00:55:46
Nexstar appeals a district court judge's injunction blocking its Tegna acquisition while an antitrust lawsuit proceeds and calls the injunction "overbroad" (Dominic Patten/Deadline)
https://deadline.com/2026/07/nexstar-reactions-tegna-merger-i…

 @leftsidestory@mstdn.social
@leftsidestory@mstdn.social2026-06-20 00:30:01
The Deity that Struggles ⛪️
挣扎的神衹 ⛪️
📷 Nikon F4E
🎞️ Ilford Pan 400
If you like my work, Support by buying me a coffee or a roll of film from
PayPal https://www.paypal.com/paypalme/ydcdingsite
Wise




 @cjust@infosec.exchange
@cjust@infosec.exchange2026-06-18 17:24:53
No, Artificial Intelligence Is Not Conscious
--Ted Chiang, The Atlantic
Should we seriously consider the possibility that Claude, or any large language model, might be conscious? And if it has feelings, is it capable of receiving moral instruction?
No. Absolutely not. Generative AI is harmful enough when we understand it as a conventional technology, but if we confuse fluency at generating text with consciousness or moral agency, we’re at risk of assigning re…

 @Yogi77@hessen.social
@Yogi77@hessen.social2026-05-13 17:42:48
Wir waren gestern Abend in #Ingelheim im Kino. Im Rahmen der Filmauslese gab es Jim Jarmuschs „Father Mother Sister Brother“ zu sehen. Mir hat es gut gefallen. Die Karten konnten wir vorab mit #wero bezahlen. #filmnase
 @grumpybozo@toad.social
@grumpybozo@toad.social2026-07-17 22:12:05
So, https://mastodon.social/@JenniferSmith345 is an odd bot. I don’t think it’s even a LLM behind it, the replies are just too weird.
Profile looks like it was taken from someone real…
