 @burger_jaap@mastodon.social
@burger_jaap@mastodon.social2025-09-16 12:14:38
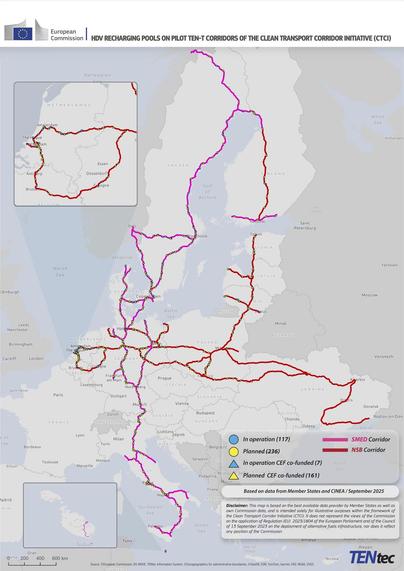
Nine EU countries are joining forces to push for public charging infrastructure for heavy-duty vehicles along two major European corridors. The goal is to speed up grid connections and permits for charging hubs along these routes, making smart use of available grid capacity wherever possible.
https://www.
 @tiotasram@kolektiva.social
@tiotasram@kolektiva.social2025-07-04 20:14:31
Long; central Massachusetts colonial history
Today on a whim I visited a site in Massachusetts marked as "Huguenot Fort Ruins" on OpenStreetMaps. I drove out with my 4-year-old through increasingly rural central Massachusetts forests & fields to end up on a narrow street near the top of a hill beside a small field. The neighboring houses had huge lawns, some with tractors.
Appropriately for this day and this moment in history, the history of the site turns out to be a microcosm of America. Across the field beyond a cross-shaped stone memorial stood an info board with a few diagrams and some text. The text of the main sign (including typos/misspellings) read:
"""
Town Is Formed
Early in the 1680's, interest began to generate to develop a town in the area west of Natick in the south central part of the Commonwealth that would be suitable for a settlement. A Mr. Hugh Campbell, a Scotch merchant of Boston petitioned the court for land for a colony. At about the same time, Joseph Dudley and William Stoughton also were desirous of obtaining land for a settlement. A claim was made for all lands west of the Blackstone River to the southern land of Massachusetts to a point northerly of the Springfield Road then running southwesterly until it joined the southern line of Massachusetts.
Associated with Dudley and Stoughton was Robert Thompson of London, England, Dr. Daniel Cox and John Blackwell, both of London and Thomas Freak of Hannington, Wiltshire, as proprietors. A stipulation in the acquisition of this land being that within four years thirty families and an orthodox minister settle in the area. An extension of this stipulation was granted at the end of the four years when no group large enough seemed to be willing to take up the opportunity.
In 1686, Robert Thompson met Gabriel Bernor and learned that he was seeking an area where his countrymen, who had fled their native France because of the Edict of Nantes, were desirous of a place to live. Their main concern was to settle in a place that would allow them freedom of worship. New Oxford, as it was the so-named, at that time included the larger part of Charlton, one-fourth of Auburn, one-fifth of Dudley and several square miles of the northeast portion of Southbridge as well as the easterly ares now known as Webster.
Joseph Dudley's assessment that the area was capable of a good settlement probably was based on the idea of the meadows already established along with the plains, ponds, brooks and rivers. Meadows were a necessity as they provided hay for animal feed and other uses by the settlers. The French River tributary books and streams provided a good source for fishing and hunting. There were open areas on the plains as customarily in November of each year, the Indians burnt over areas to keep them free of underwood and brush. It appeared then that this area was ready for settling.
The first seventy-five years of the settling of the Town of Oxford originally known as Manchaug, embraced three different cultures. The Indians were known to be here about 1656 when the Missionary, John Eliott and his partner Daniel Gookin visited in the praying towns. Thirty years later, in 1686, the Huguenots walked here from Boston under the guidance of their leader Isaac Bertrand DuTuffeau. The Huguenot's that arrived were not peasants, but were acknowledged to be the best Agriculturist, Wine Growers, Merchant's, and Manufacter's in France. There were 30 families consisting of 52 people. At the time of their first departure (10 years), due to Indian insurrection, there were 80 people in the group, and near their Meetinghouse/Church was a Cemetery that held 20 bodies. In 1699, 8 to 10 familie's made a second attempt to re-settle, failing after only four years, with the village being completely abandoned in 1704.
The English colonist made their way here in 1713 and established what has become a permanent settlement.
"""
All that was left of the fort was a crumbling stone wall that would have been the base of a higher wooden wall according to a picture of a model (I didn't think to get a shot of that myself). Only trees and brush remain where the multi-story main wooden building was.
This story has so many echoes in the present:
- The rich colonialists from Boston & London agree to settle the land, buying/taking land "rights" from the colonial British court that claimed jurisdiction without actually having control of the land. Whether the sponsors ever actually visited the land themselves I don't know. They surely profited somehow, whether from selling on the land rights later or collecting taxes/rent or whatever, by they needed poor laborers to actually do the work of developing the land (& driving out the original inhabitants, who had no say in the machinations of the Boston court).
- The land deal was on condition that there capital-holders who stood to profit would find settlers to actually do the work of colonizing. The British crown wanted more territory to be controlled in practice not just in theory, but they weren't going to be the ones to do the hard work.
- The capital-holders actually failed to find enough poor suckers to do their dirty work for 4 years, until the Huguenots, fleeing religious persecution in France, were desperate enough to accept their terms.
- Of course, the land was only so ripe for settlement because of careful tending over centuries by the natives who were eventually driven off, and whose land management practices are abandoned today. Given the mention of praying towns (& dates), this was after King Phillip's war, which resulted in at least some forced resettlement of native tribes around the area, but the descendants of those "Indians" mentioned in this sign are still around. For example, this is the site of one local band of Nipmuck, whose namesake lake is about 5 miles south of the fort site: #LandBack.
 @tiotasram@kolektiva.social
@tiotasram@kolektiva.social2025-08-04 15:49:00
Should we teach vibe coding? Here's why not.
Should AI coding be taught in undergrad CS education?
1/2
I teach undergraduate computer science labs, including for intro and more-advanced core courses. I don't publish (non-negligible) scholarly work in the area, but I've got years of craft expertise in course design, and I do follow the academic literature to some degree. In other words, In not the world's leading expert, but I have spent a lot of time thinking about course design, and consider myself competent at it, with plenty of direct experience in what knowledge & skills I can expect from students as they move through the curriculum.
I'm also strongly against most uses of what's called "AI" these days (specifically, generative deep neutral networks as supplied by our current cadre of techbro). There are a surprising number of completely orthogonal reasons to oppose the use of these systems, and a very limited number of reasonable exceptions (overcoming accessibility barriers is an example). On the grounds of environmental and digital-commons-pollution costs alone, using specifically the largest/newest models is unethical in most cases.
But as any good teacher should, I constantly question these evaluations, because I worry about the impact on my students should I eschew teaching relevant tech for bad reasons (and even for his reasons). I also want to make my reasoning clear to students, who should absolutely question me on this. That inspired me to ask a simple question: ignoring for one moment the ethical objections (which we shouldn't, of course; they're very stark), at what level in the CS major could I expect to teach a course about programming with AI assistance, and expect students to succeed at a more technically demanding final project than a course at the same level where students were banned from using AI? In other words, at what level would I expect students to actually benefit from AI coding "assistance?"
To be clear, I'm assuming that students aren't using AI in other aspects of coursework: the topic of using AI to "help you study" is a separate one (TL;DR it's gross value is not negative, but it's mostly not worth the harm to your metacognitive abilities, which AI-induced changes to the digital commons are making more important than ever).
So what's my answer to this question?
If I'm being incredibly optimistic, senior year. Slightly less optimistic, second year of a masters program. Realistic? Maybe never.
The interesting bit for you-the-reader is: why is this my answer? (Especially given that students would probably self-report significant gains at lower levels.) To start with, [this paper where experienced developers thought that AI assistance sped up their work on real tasks when in fact it slowed it down] (https://arxiv.org/abs/2507.09089) is informative. There are a lot of differences in task between experienced devs solving real bugs and students working on a class project, but it's important to understand that we shouldn't have a baseline expectation that AI coding "assistants" will speed things up in the best of circumstances, and we shouldn't trust self-reports of productivity (or the AI hype machine in general).
Now we might imagine that coding assistants will be better at helping with a student project than at helping with fixing bugs in open-source software, since it's a much easier task. For many programming assignments that have a fixed answer, we know that many AI assistants can just spit out a solution based on prompting them with the problem description (there's another elephant in the room here to do with learning outcomes regardless of project success, but we'll ignore this over too, my focus here is on project complexity reach, not learning outcomes). My question is about more open-ended projects, not assignments with an expected answer. Here's a second study (by one of my colleagues) about novices using AI assistance for programming tasks. It showcases how difficult it is to use AI tools well, and some of these stumbling blocks that novices in particular face.
But what about intermediate students? Might there be some level where the AI is helpful because the task is still relatively simple and the students are good enough to handle it? The problem with this is that as task complexity increases, so does the likelihood of the AI generating (or copying) code that uses more complex constructs which a student doesn't understand. Let's say I have second year students writing interactive websites with JavaScript. Without a lot of care that those students don't know how to deploy, the AI is likely to suggest code that depends on several different frameworks, from React to JQuery, without actually setting up or including those frameworks, and of course three students would be way out of their depth trying to do that. This is a general problem: each programming class carefully limits the specific code frameworks and constructs it expects students to know based on the material it covers. There is no feasible way to limit an AI assistant to a fixed set of constructs or frameworks, using current designs. There are alternate designs where this would be possible (like AI search through adaptation from a controlled library of snippets) but those would be entirely different tools.
So what happens on a sizeable class project where the AI has dropped in buggy code, especially if it uses code constructs the students don't understand? Best case, they understand that they don't understand and re-prompt, or ask for help from an instructor or TA quickly who helps them get rid of the stuff they don't understand and re-prompt or manually add stuff they do. Average case: they waste several hours and/or sweep the bugs partly under the rug, resulting in a project with significant defects. Students in their second and even third years of a CS major still have a lot to learn about debugging, and usually have significant gaps in their knowledge of even their most comfortable programming language. I do think regardless of AI we as teachers need to get better at teaching debugging skills, but the knowledge gaps are inevitable because there's just too much to know. In Python, for example, the LLM is going to spit out yields, async functions, try/finally, maybe even something like a while/else, or with recent training data, the walrus operator. I can't expect even a fraction of 3rd year students who have worked with Python since their first year to know about all these things, and based on how students approach projects where they have studied all the relevant constructs but have forgotten some, I'm not optimistic seeing these things will magically become learning opportunities. Student projects are better off working with a limited subset of full programming languages that the students have actually learned, and using AI coding assistants as currently designed makes this impossible. Beyond that, even when the "assistant" just introduces bugs using syntax the students understand, even through their 4th year many students struggle to understand the operation of moderately complex code they've written themselves, let alone written by someone else. Having access to an AI that will confidently offer incorrect explanations for bugs will make this worse.
To be sure a small minority of students will be able to overcome these problems, but that minority is the group that has a good grasp of the fundamentals and has broadened their knowledge through self-study, which earlier AI-reliant classes would make less likely to happen. In any case, I care about the average student, since we already have plenty of stuff about our institutions that makes life easier for a favored few while being worse for the average student (note that our construction of that favored few as the "good" students is a large part of this problem).
To summarize: because AI assistants introduce excess code complexity and difficult-to-debug bugs, they'll slow down rather than speed up project progress for the average student on moderately complex projects. On a fixed deadline, they'll result in worse projects, or necessitate less ambitious project scoping to ensure adequate completion, and I expect this remains broadly true through 4-6 years of study in most programs (don't take this as an endorsement of AI "assistants" for masters students; we've ignored a lot of other problems along the way).
There's a related problem: solving open-ended project assignments well ultimately depends on deeply understanding the problem, and AI "assistants" allow students to put a lot of code in their file without spending much time thinking about the problem or building an understanding of it. This is awful for learning outcomes, but also bad for project success. Getting students to see the value of thinking deeply about a problem is a thorny pedagogical puzzle at the best of times, and allowing the use of AI "assistants" makes the problem much much worse. This is another area I hope to see (or even drive) pedagogical improvement in, for what it's worth.
1/2
@tiotasram@kolektiva.social2025-06-21 02:34:13
Why AI can't possibly make you more productive; long
#AI and "productivity", some thoughts:
Edit: fixed some typos.
Productivity is a concept that isn't entirely meaningless outside the context of capitalism, but it's a concept that is heavily inflected in a capitalist context. In many uses today it effectively means "how much you can satisfy and/or exceed your boss' expectations." This is not really what it should mean: even in an anarchist utopia, people would care about things like how many shirts they can produce in a week, although in an "I'd like to voluntarily help more people" way rather than an "I need to meet this quota to earn my survival" way. But let's roll with this definition for a second, because it's almost certainly what your boss means when they say "productivity", and understanding that word in a different (even if truer) sense is therefore inherently dangerous.
Accepting "productivity" to mean "satisfying your boss' expectations," I will now claim: the use of generative AI cannot increase your productivity.
Before I dive in, it's imperative to note that the big generative models which most people think of as constituting "AI" today are evil. They are 1: pouring fuel on our burning planet, 2: psychologically strip-mining a class of data laborers who are exploited for their precarity, 3: enclosing, exploiting, and polluting the digital commons, and 4: stealing labor from broad classes of people many of whom are otherwise glad to give that labor away for free provided they get a simple acknowledgement in return. Any of these four "ethical issues" should be enough *alone* to cause everyone to simply not use the technology. These ethical issues are the reason that I do not use generative AI right now, except for in extremely extenuating circumstances. These issues are also convincing for a wide range of people I talk to, from experts to those with no computer science background. So before I launch into a critique of the effectiveness of generative AI, I want to emphasize that such a critique should be entirely unnecessary.
But back to my thesis: generative AI cannot increase your productivity, where "productivity" has been defined as "how much you can satisfy and/or exceed your boss' expectations."
Why? In fact, what the fuck? Every AI booster I've met has claimed the opposite. They've given me personal examples of time saved by using generative AI. Some of them even truly believe this. Sometimes I even believe they saved time without horribly compromising on quality (and often, your boss doesn't care about quality anyways if the lack of quality is hard to measure of doesn't seem likely to impact short-term sales/feedback/revenue). So if generative AI genuinely lets you write more emails in a shorter period of time, or close more tickets, or something else along these lines, how can I say it isn't increasing your ability to meet your boss' expectations?
The problem is simple: your boss' expectations are not a fixed target. Never have been. In virtue of being someone who oversees and pays wages to others under capitalism, your boss' game has always been: pay you less than the worth of your labor, so that they can accumulate profit and thus more capital to remain in charge instead of being forced into working for a wage themselves. Sure, there are layers of management caught in between who aren't fully in this mode, but they are irrelevant to this analysis. It matters not how much you please your manager if your CEO thinks your work is not worth the wages you are being paid. And using AI actively lowers the value of your work relative to your wages.
Why do I say that? It's actually true in several ways. The most obvious: using generative AI lowers the quality of your work, because the work it produces is shot through with errors, and when your job is reduced to proofreading slop, you are bound to tire a bit, relax your diligence, and let some mistakes through. More than you would have if you are actually doing and taking pride in the work. Examples are innumerable and frequent, from journalists to lawyers to programmers, and we laugh at them "haha how stupid to not check whether the books the AI reviewed for you actually existed!" but on a deeper level if we're honest we know we'd eventually make the same mistake ourselves (bonus game: spot the swipe-typing typos I missed in this post; I'm sure there will be some).
But using generative AI also lowers the value of your work in another much more frightening way: in this era of hype, it demonstrates to your boss that you could be replaced by AI. The more you use it, and no matter how much you can see that your human skills are really necessary to correct its mistakes, the more it appears to your boss that they should hire the AI instead of you. Or perhaps retain 10% of the people in roles like yours to manage the AI doing the other 90% of the work. Paradoxically, the *more* you get done in terms of raw output using generative AI, the more it looks to your boss as if there's an opportunity to get enough work done with even fewer expensive humans. Of course, the decision to fire you and lean more heavily into AI isn't really a good one for long-term profits and success, but the modern boss did not get where they are by considering long-term profits. By using AI, you are merely demonstrating your redundancy, and the more you get done with it, the more redundant you seem.
In fact, there's even a third dimension to this: by using generative AI, you're also providing its purveyors with invaluable training data that allows them to make it better at replacing you. It's generally quite shitty right now, but the more use it gets by competent & clever people, the better it can become at the tasks those specific people use it for. Using the currently-popular algorithm family, there are limits to this; I'm not saying it will eventually transcend the mediocrity it's entwined with. But it can absolutely go from underwhelmingly mediocre to almost-reasonably mediocre with the right training data, and data from prompting sessions is both rarer and more useful than the base datasets it's built on.
For all of these reasons, using generative AI in your job is a mistake that will likely lead to your future unemployment. To reiterate, you should already not be using it because it is evil and causes specific and inexcusable harms, but in case like so many you just don't care about those harms, I've just explained to you why for entirely selfish reasons you should not use it.
If you're in a position where your boss is forcing you to use it, my condolences. I suggest leaning into its failures instead of trying to get the most out of it, and as much as possible, showing your boss very clearly how it wastes your time and makes things slower. Also, point out the dangers of legal liability for its mistakes, and make sure your boss is aware of the degree to which any of your AI-eager coworkers are producing low-quality work that harms organizational goals.
Also, if you've read this far and aren't yet of an anarchist mindset, I encourage you to think about the implications of firing 75% of (at least the white-collar) workforce in order to make more profit while fueling the climate crisis and in most cases also propping up dictatorial figureheads in government. When *either* the AI bubble bursts *or* if the techbros get to live out the beginnings of their worker-replacement fantasies, there are going to be an unimaginable number of economically desperate people living in increasingly expensive times. I'm the kind of optimist who thinks that the resulting social crucible, though perhaps through terrible violence, will lead to deep social changes that effectively unseat from power the ultra-rich that continue to drag us all down this destructive path, and I think its worth some thinking now about what you might want the succeeding stable social configuration to look like so you can advocate towards that during points of malleability.
As others have said more eloquently, generative AI *should* be a technology that makes human lives on average easier, and it would be were it developed & controlled by humanists. The only reason that it's not, is that it's developed and controlled by terrible greedy people who use their unfairly hoarded wealth to immiserate the rest of us in order to maintain their dominance. In the long run, for our very survival, we need to depose them, and I look forward to what the term "generative AI" will mean after that finally happens.
 @mlawton@mstdn.social
@mlawton@mstdn.social2025-06-20 19:36:23
Chelsea playing a strong lineup, but their defending, especially headed balls back across the face of goal... has been shocking in the second half. 👀
Conceded two goals in 4 minutes. Immediately after conceding the second, Nicolas Jackson gets a straight 🔴 for a textbook studs up challenge high up the leg. Indefensible. He'd just subbed on and was on the pitch for 4 whole minutes.
#FLACHE
@tiotasram@kolektiva.social2025-07-31 16:25:48
LLM coding is the opposite of DRY
An important principle in software engineering is DRY: Don't Repeat Yourself. We recognize that having the same code copied in more than one place is bad for several reasons:
1. It makes the entire codebase harder to read.
2. It increases maintenance burden, since any problems in the duplicated code need to be solved in more than one place.
3. Because it becomes possible for the copies to drift apart if changes to one aren't transferred to the other (maybe the person making the change has forgotten there was a copy) it makes the code more error-prone and harder to debug.
All modern programming languages make it almost entirely unnecessary to repeat code: we can move the repeated code into a "function" or "module" and then reference it from all the different places it's needed. At a larger scale, someone might write an open-source "library" of such functions or modules and instead of re-implementing that functionality ourselves, we can use their code, with an acknowledgement. Using another person's library this way is complicated, because now you're dependent on them: if they stop maintaining it or introduce bugs, you've inherited a problem, but still, you could always copy their project and maintain your own version, and it would be not much more work than if you had implemented stuff yourself from the start. It's a little more complicated than this, but the basic principle holds, and it's a foundational one for software development in general and the open-source movement in particular. The network of "citations" as open-source software builds on other open-source software and people contribute patches to each others' projects is a lot of what makes the movement into a community, and it can lead to collaborations that drive further development. So the DRY principle is important at both small and large scales.
Unfortunately, the current crop of hyped-up LLM coding systems from the big players are antithetical to DRY at all scales:
- At the library scale, they train on open source software but then (with some unknown frequency) replicate parts of it line-for-line *without* any citation [1]. The person who was using the LLM has no way of knowing that this happened, or even any way to check for it. In theory the LLM company could build a system for this, but it's not likely to be profitable unless the courts actually start punishing these license violations, which doesn't seem likely based on results so far and the difficulty of finding out that the violations are happening. By creating these copies (and also mash-ups, along with lots of less-problematic stuff), the LLM users (enabled and encouraged by the LLM-peddlers) are directly undermining the DRY principle. If we see what the big AI companies claim to want, which is a massive shift towards machine-authored code, DRY at the library scale will effectively be dead, with each new project simply re-implementing the functionality it needs instead of every using a library. This might seem to have some upside, since dependency hell is a thing, but the downside in terms of comprehensibility and therefore maintainability, correctness, and security will be massive. The eventual lack of new high-quality DRY-respecting code to train the models on will only make this problem worse.
- At the module & function level, AI is probably prone to re-writing rather than re-using the functions or needs, especially with a workflow where a human prompts it for many independent completions. This part I don't have direct evidence for, since I don't use LLM coding models myself except in very specific circumstances because it's not generally ethical to do so. I do know that when it tries to call existing functions, it often guesses incorrectly about the parameters they need, which I'm sure is a headache and source of bugs for the vibe coders out there. An AI could be designed to take more context into account and use existing lookup tools to get accurate function signatures and use them when generating function calls, but even though that would probably significantly improve output quality, I suspect it's the kind of thing that would be seen as too-baroque and thus not a priority. Would love to hear I'm wrong about any of this, but I suspect the consequences are that any medium-or-larger sized codebase written with LLM tools will have significant bloat from duplicate functionality, and will have places where better use of existing libraries would have made the code simpler. At a fundamental level, a principle like DRY is not something that current LLM training techniques are able to learn, and while they can imitate it from their training sets to some degree when asked for large amounts of code, when prompted for many smaller chunks, they're asymptotically likely to violate it.
I think this is an important critique in part because it cuts against the argument that "LLMs are the modern compliers, if you reject them you're just like the people who wanted to keep hand-writing assembly code, and you'll be just as obsolete." Compilers actually represented a great win for abstraction, encapsulation, and DRY in general, and they supported and are integral to open source development, whereas LLMs are set to do the opposite.
[1] to see what this looks like in action in prose, see the example on page 30 of the NYTimes copyright complaint against OpenAI (#AI #GenAI #LLMs #VibeCoding