@tinoeberl@mastodon.online
@tinoeberl@mastodon.online2026-06-04 08:10:02
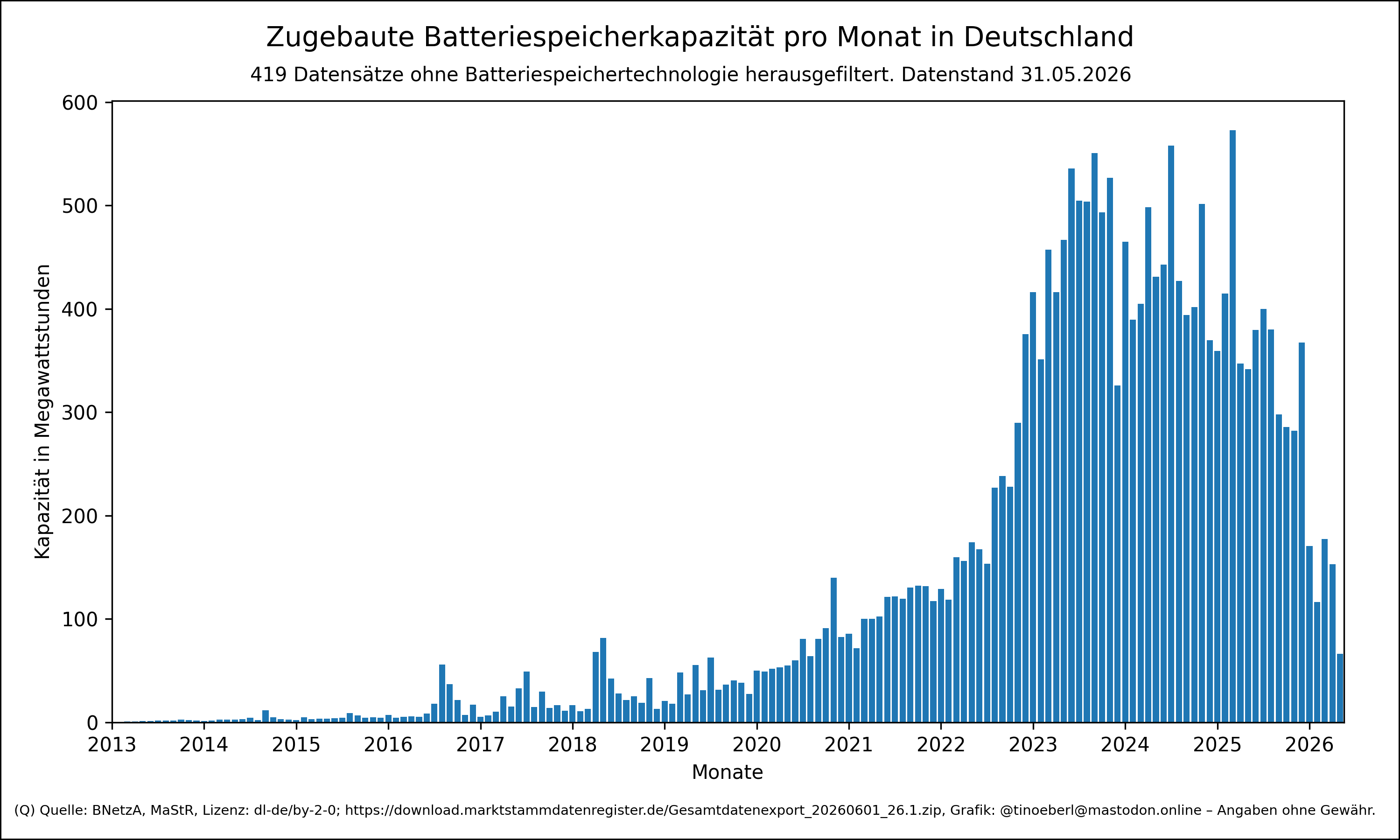
Zugebaute #Batteriespeicherkapazität pro Monat in #Deutschland mit Stand vom 31.05.2026.
419 Datensätze ohne #Batteriespeichertechnologie herausgefil…
 @tinoeberl@mastodon.online
@tinoeberl@mastodon.onlineZugebaute #Batteriespeicherkapazität pro Monat in #Deutschland mit Stand vom 31.05.2026.
419 Datensätze ohne #Batteriespeichertechnologie herausgefil…
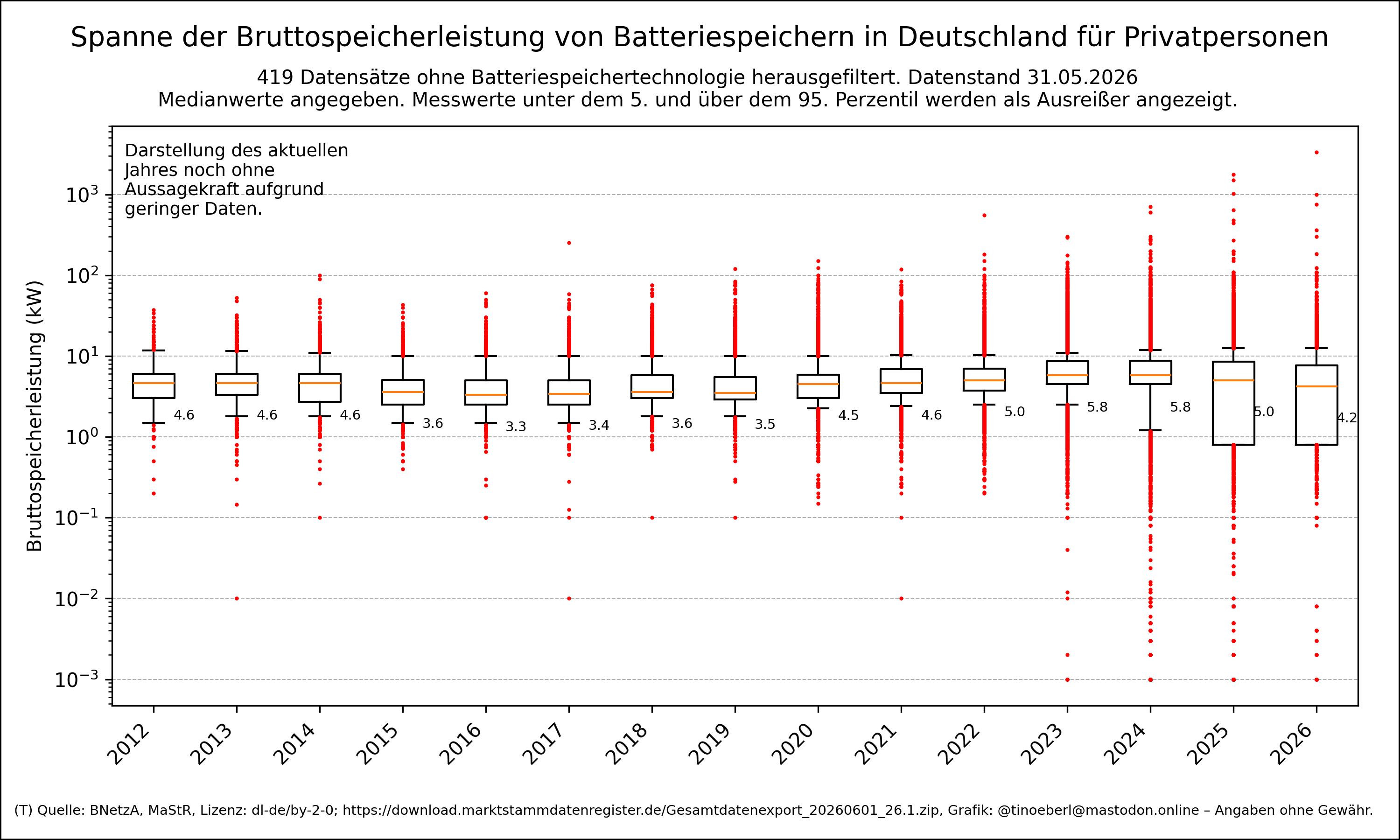
@tinoeberl@mastodon.onlineSpanne der Bruttospeicherleistung von #Batteriespeichern pro Inbetriebnahmejahr von Privatpersonen in Deutschland mit Stand vom 31.05.2026.
419 Datensätze ohne #Batteriespeichertechnologie herausgefiltert.
Der Datenbestand enthält unplausible Datensätze.