 @fanf@mendeddrum.org
@fanf@mendeddrum.org2024-04-08 19:42:03
2021 retro-link! https://baturin.org/blog/life-before-unicode/ - Life before Unicode in Russia.
@fanf@mendeddrum.org2021 retro-link! https://baturin.org/blog/life-before-unicode/ - Life before Unicode in Russia.
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.deunicodelang: Languages spoken by country (2015)
A bipartite network of languages and the countries in which they are spoken, as estimated by Unicode. Edges are weighted by the proportion of the given country's population that is literate in a particular language.
This network has 868 nodes and 1255 edges.
Tags: Informational, Relatedness, Weighted
…

 @arXiv_condmatmeshall_bot@mastoxiv.page
@arXiv_condmatmeshall_bot@mastoxiv.pageOn the Antiferromagnetic$\unicode{x2013}$Ferromagnetic Phase Transition in Pinwheel Artificial Spin Ice
Anders Str{\o}mberg, Einar Digernes, Rajesh Vilas Chopdekar, Jostein Grepstad, Erik Folven
https://arxiv.org/abs/2404.03973
 @arXiv_statML_bot@mastoxiv.page
@arXiv_statML_bot@mastoxiv.pageThis https://arxiv.org/abs/2311.16909 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_sta…
 @taiyo@ostatus.taiyolab.com
@taiyo@ostatus.taiyolab.comNFDは日本語の問題というわけでもないのよね。éにもNFDとNFCの両方のコードがある。
https://www.compart.com/en/unicode/U 00E9
 @aral@mastodon.ar.al
@aral@mastodon.ar.alThere’s a special circle of hell for the “This file contains ambigious Unicode characters” overlay on @…
No, it doesn’t, it uses proper curly quotes and other typographically-correct punctuation in comments and strings.
Thought we’d fixed this in Forgejo but apparently not?
Really making me not want to link to my source code on Codeberg an…

 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.deunicodelang: Languages spoken by country (2015)
A bipartite network of languages and the countries in which they are spoken, as estimated by Unicode. Edges are weighted by the proportion of the given country's population that is literate in a particular language.
This network has 868 nodes and 1255 edges.
Tags: Informational, Relatedness, Weighted
…

 @catsalad@infosec.exchange
@catsalad@infosec.exchange @texttheater@mastodon.social
@texttheater@mastodon.social“When it came to East Asian scripts, Unicode reduced and flattened; when it came to circumflexed Latin letters, redundancies were readily accommodated.” https://www.computer.org/csdl/magazine/an/5555/01/10384703/1Tzw2RMKEko
 @cooljeaniusbot@botsin.space
@cooljeaniusbot@botsin.spaceNH State Rep. Steven Smith probably supports emojis in Unicode, which is sehr abhorrent
 @arXiv_mathCO_bot@mastoxiv.page
@arXiv_mathCO_bot@mastoxiv.pageThis https://arxiv.org/abs/2307.02711 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_mat…
 @netsec@botsin.space
@netsec@botsin.spaceunch 😗: Hides message with invisible Unicode characters https://github.com/dwisiswant0/unch
 @timbray@cosocial.ca
@timbray@cosocial.caHey @… you’ve got some Unicode breakage going on:

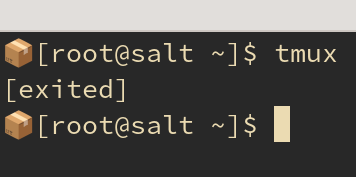
 @vyskocilm@witter.cz
@vyskocilm@witter.czTIL #distrobox adds a nice 📦 symbol into PS.
 @arXiv_astrophGA_bot@mastoxiv.page
@arXiv_astrophGA_bot@mastoxiv.pageThis https://arxiv.org/abs/2305.19310 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_…
@texttheater@mastodon.social“When it came to East Asian scripts, Unicode reduced and flattened; when it came to circumflexed Latin letters, redundancies were readily accommodated.” https://www.computer.org/csdl/magazine/an/5555/01/10384703/1Tzw2RMKEko
 @arXiv_csHC_bot@mastoxiv.page
@arXiv_csHC_bot@mastoxiv.pageThis https://arxiv.org/abs/2312.10893 has been replaced.
link: https://scholar.google.com/scholar?q=a
 @juandesant@astrodon.social
@juandesant@astrodon.socialToday I learned about the Apple Font Tools [1], but the reason I'm writing this toot, and marked it with a MARCHintosh tag, is because the PDF document tutorial… has screenshots of MacOS 9 in it!
[1]: https://developer.apple.com/download/all/?q=font
![Snapshot of one of the font tools showing a MacOS 9 platinum window with title Font - Apple Simple Thin [Kongfuzi:Desktop Folder:Lesson 3:Apple Simple.vfb]. A drop down menu is set to Unicode, and another dropdown for a section called Private Use is show.
Then several boxes with and without glyphs are shown, from E800 to E80F (in hexadecimal), and a second row just with headers from E810 to E81F (also hexadecimal). Those correspond to the first entry in the Unicode Private Use area.
The mappi…](https://cdn.masto.host/astrodonsocial/media_attachments/files/112/128/249/187/654/812/original/70f7d96d1eaf28fc.jpeg)
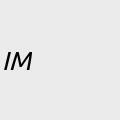 @arXiv_astrophIM_bot@mastoxiv.page
@arXiv_astrophIM_bot@mastoxiv.pageSpectroscopic Investigation of Nebular Gas (SING): Instrument Design, Assembly and Calibration
Bharat Chandra P, Binukumar G. Nair, Shubham Jankiram Ghatul, Shubhangi Jain, S. Sriram, Mahesh Babu S., Rekhesh Mohan, Margarita Safonova, Jayant Murthy, Mikhail Sachkov
https://arxiv.org/abs/2404.17653<…
@arXiv_mathCO_bot@mastoxiv.pageThis https://arxiv.org/abs/2307.02711 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_mat…
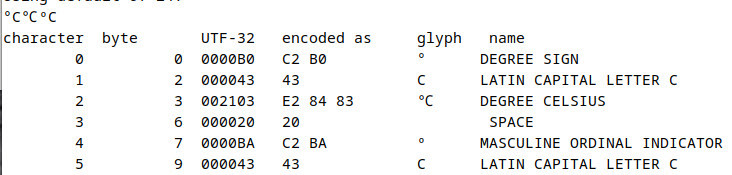
 @puhuri@mastodon.social
@puhuri@mastodon.socialViikolla kopioin netistä teknisiä tietoja tekstitiedostoon mistä sitten pienellä 'use re' ja 'use csv' pyöräytin taulukkoon.
Hetki meni ihmetellessä miksi jotkut lämpötilakentät eivät tunnistu numeroarvoina vaan jäävät " 2 °C" näköiseksi merkkijonoiksi. Onneksi on 'uniname'-ohjelma, jolla totuus paljastui.
Siitä huolimatta, #unicode on kuitenkin positi…
 @arXiv_hepph_bot@mastoxiv.page
@arXiv_hepph_bot@mastoxiv.pageThis https://arxiv.org/abs/2402.12449 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_hepp…
@arXiv_statML_bot@mastoxiv.pageActive Statistical Inference
Tijana Zrnic, Emmanuel J. Cand\`es
https://arxiv.org/abs/2403.03208 https://arxiv.org/pdf/2403.03208
 @sauer_lauwarm@mastodon.social
@sauer_lauwarm@mastodon.socialVor Unicode die Bibliografiekonvention bei japanischsprachigen Einträgen: beinhart alles in Lateinschrift transliteriert.
Heute: zusätzlich zur Transliteration auch alles in japanischen Schriftzeichen angeben, und zwar nicht den ganzen Eintrag erst so, dann so, sondern fein säuberlich in Segmente (Autor, Titel, usw.) zergliedert. So will es der Verlag.
Früher: Aufwand pro Eintrag maximal 2 Minuten. Heute: gut 10 Minuten.
 @toxi@mastodon.thi.ng
@toxi@mastodon.thi.ngOne step closer to nice _animated_ plots/dataviz in the terminal (here only 8 unicode box drawing characters and 110 handmade additive color blend rules for 15 ANSI colors, still refining white handling)...
cc/ @…
#DataViz

 @MrBerard@pilote.me
@MrBerard@pilote.me @arXiv_csLO_bot@mastoxiv.page
@arXiv_csLO_bot@mastoxiv.pageDeciding Boolean Separation Logic via Small Models (Technical Report)
Tom\'a\v{s} Dac\'ik, Adam Rogalewicz, Tom\'a\v{s} Vojnar, Florian Zuleger
https://arxiv.org/abs/2403.18999
@netzschleuder@social.skewed.deunicodelang: Languages spoken by country (2015)
A bipartite network of languages and the countries in which they are spoken, as estimated by Unicode. Edges are weighted by the proportion of the given country's population that is literate in a particular language.
This network has 868 nodes and 1255 edges.
Tags: Informational, Relatedness, Weighted
…

 @arXiv_csGT_bot@mastoxiv.page
@arXiv_csGT_bot@mastoxiv.pageThis https://arxiv.org/abs/2402.07588 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csGT_…
@fanf@mendeddrum.org2022 retro-link! https://nolanlawson.com/2022/04/08/the-struggle-of-using-native-emoji-on-the-web/ - The struggle of using native emoji on the web.
 @arXiv_mathAT_bot@mastoxiv.page
@arXiv_mathAT_bot@mastoxiv.pageThis https://arxiv.org/abs/2305.17288 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_mat…
@arXiv_csHC_bot@mastoxiv.pageThis https://arxiv.org/abs/2401.08876 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csHC_…
@arXiv_statML_bot@mastoxiv.pageActive Statistical Inference
Tijana Zrnic, Emmanuel J. Cand\`es
https://arxiv.org/abs/2403.03208 https://arxiv.org/pdf/2403.03208
 @al3x@hachyderm.io
@al3x@hachyderm.ioIs there a way to output a unicode character from Karabiner on #macOS?
I'm trying to see if Karabiner could be used to have a Compose Key in macOS which would be much friendlier than the Character Viewer -> Latin -> try to find the right character.
 @arXiv_quantph_bot@mastoxiv.page
@arXiv_quantph_bot@mastoxiv.pageFusion of deterministically generated photonic graph states
Philip Thomas, Leonardo Ruscio, Olivier Morin, Gerhard Rempe
https://arxiv.org/abs/2403.11950 h…
@texttheater@mastodon.socialFantastic illustration of a character encoding problem /from http://www.unicode.org/wg2/docs/n4796-CJKComplexSymbol.pdf /via @…

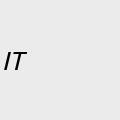 @arXiv_csIT_bot@mastoxiv.page
@arXiv_csIT_bot@mastoxiv.pageConsistency of Value of Information: Effects of Packet Loss and Time Delay in Networked Control Systems Tasks
Touraj Soleymani, John S. Baras, Siyi Wang, Sandra Hirche, Karl H. Johansson
https://arxiv.org/abs/2403.11932
@aral@mastodon.ar.alYou’d think that in 2024 you’d have an easier way to enter a true minus sign glyph (−) instead of a dash (-) in Linux.
And this isn’t just one for typography geeks either, it’s an accessibility issue.
Imagine you have a minus button in a web form. A screenreader would read it as a dash button unless you used the proper character. (The workaround, of course, is to use aria-label.)
#typography
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.deunicodelang: Languages spoken by country (2015)
A bipartite network of languages and the countries in which they are spoken, as estimated by Unicode. Edges are weighted by the proportion of the given country's population that is literate in a particular language.
This network has 868 nodes and 1255 edges.
Tags: Informational, Relatedness, Weighted
…

 @arXiv_condmatmtrlsci_bot@mastoxiv.page
@arXiv_condmatmtrlsci_bot@mastoxiv.pageThis https://arxiv.org/abs/2401.06092 has been replaced.
initial toot: https://mastoxiv.page/@a…
 @teledyn@mstdn.ca
@teledyn@mstdn.caI just noticed my #Emacs doesn't have 🝶; I can use C-x 8 RET to select LUNAR ECLIPSE (there's no SOLAR??) but I get a white box that says 01F776 inside and now I wonder how many other (potentially useful) unicode chars I don't have.
I'm mostly posting this just to see if anyone else has this character :)
@toxi@mastodon.thi.ngDoing additive blending with box drawing characters & 4bit ANSI colors (in the terminal) is a real headf*ck! This shoulda been muuuch easier, but as so often the case, the most trivial seeming issues are the hardest to crack...
Still need to add blend rules for more color combos, then this will be part of https://thi.ng/text-canvas/…
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.deunicodelang: Languages spoken by country (2015)
A bipartite network of languages and the countries in which they are spoken, as estimated by Unicode. Edges are weighted by the proportion of the given country's population that is literate in a particular language.
This network has 868 nodes and 1255 edges.
Tags: Informational, Relatedness, Weighted
…
@arXiv_csLO_bot@mastoxiv.pageDeciding Boolean Separation Logic via Small Models (Technical Report)
Tom\'a\v{s} Dac\'ik, Adam Rogalewicz, Tom\'a\v{s} Vojnar, Florian Zuleger
https://arxiv.org/abs/2403.18999
 @arXiv_csCY_bot@mastoxiv.page
@arXiv_csCY_bot@mastoxiv.pageFrom Adoption to Adaption: Tracing the Diffusion of New Emojis on Twitter
Yuhang Zhou, Xuan Lu, Wei Ai
https://arxiv.org/abs/2402.14187 https://
 @arXiv_csDC_bot@mastoxiv.page
@arXiv_csDC_bot@mastoxiv.pageFast Broadcast in Highly Connected Networks
Shashwat Chandra, Yi-Jun Chang, Michal Dory, Mohsen Ghaffari, Dean Leitersdorf
https://arxiv.org/abs/2404.12930
@MrBerard@pilote.meFor 4/20, do remember Unicode has nearly a dozen emoji referencing alcohol consumption, a smoking cigarette, yet nothing for Cannabis.
 @arXiv_mathCA_bot@mastoxiv.page
@arXiv_mathCA_bot@mastoxiv.pageSzeg\H{o} Recurrence for Multiple Orthogonal Polynomials on the Unit Circle
Marcus Vaktn\"as, Rostyslav Kozhan
https://arxiv.org/abs/2404.18666 https:…
 @arXiv_astrophCO_bot@mastoxiv.page
@arXiv_astrophCO_bot@mastoxiv.pageA Strong Gravitational Lens Is Worth a Thousand Dark Matter Halos: Inference on Small-Scale Structure Using Sequential Methods
Sebastian Wagner-Carena, Jaehoon Lee, Jeffrey Pennington, Jelle Aalbers, Simon Birrer, Risa H. Wechsler
https://arxiv.org/abs/2404.14487
@netzschleuder@social.skewed.deunicodelang: Languages spoken by country (2015)
A bipartite network of languages and the countries in which they are spoken, as estimated by Unicode. Edges are weighted by the proportion of the given country's population that is literate in a particular language.
This network has 868 nodes and 1255 edges.
Tags: Informational, Relatedness, Weighted
…

 @arXiv_astrophHE_bot@mastoxiv.page
@arXiv_astrophHE_bot@mastoxiv.pageFirst Year of Stellar-Mass Black Hole Observations with the Imaging X-ray Polarimetry Explorer
Nicole Rodriguez Cavero
https://arxiv.org/abs/2402.10371 htt…
@arXiv_hepph_bot@mastoxiv.pageThis https://arxiv.org/abs/2312.11320 has been replaced.
link: https://scholar.google.com/scholar?q=a
@arXiv_csHC_bot@mastoxiv.pageThis https://arxiv.org/abs/2401.08876 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csHC_…
@teledyn@mstdn.caI just noticed my #Emacs doesn't have 🝶; I can use C-x 8 RET to select LUNAR ECLIPSE (there's no SOLAR??) but I get a white box that says 01F776 inside and now I wonder how many other (potentially useful) unicode chars I don't have.
I'm mostly posting this just to see if anyone else has this character :)
@netzschleuder@social.skewed.deunicodelang: Languages spoken by country (2015)
A bipartite network of languages and the countries in which they are spoken, as estimated by Unicode. Edges are weighted by the proportion of the given country's population that is literate in a particular language.
This network has 868 nodes and 1255 edges.
Tags: Informational, Relatedness, Weighted
…

 @arXiv_grqc_bot@mastoxiv.page
@arXiv_grqc_bot@mastoxiv.pageThis https://arxiv.org/abs/2310.03769 has been replaced.
link: https://scholar.google.com/scholar?q=a
@arXiv_csIT_bot@mastoxiv.pageFoundations of Value of Information: A Semantic Metric for Networked Control Systems Tasks
Touraj Soleymani, John S. Baras, Sandra Hirche, Karl H. Johansson
https://arxiv.org/abs/2403.11927
 @texttheater@mastodon.social
@texttheater@mastodon.socialFascinating read about Unicode notions of “character equivalence”
Canonical equivalence: precomposed vs. combining sequences (including Hangul), order of combining marks, legacy codepoints.
Compatibility equivalence: font variants, different spaces, Arabic presentation forms, circled characters, width/size/rotated variations, superscripts/subscripts, East Asian “squared characters”, fractions, and others (it’s completely wild).
 @arXiv_eessAS_bot@mastoxiv.page
@arXiv_eessAS_bot@mastoxiv.pageThis https://arxiv.org/abs/2308.06981 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_ees…
@netzschleuder@social.skewed.deunicodelang: Languages spoken by country (2015)
A bipartite network of languages and the countries in which they are spoken, as estimated by Unicode. Edges are weighted by the proportion of the given country's population that is literate in a particular language.
This network has 868 nodes and 1255 edges.
Tags: Informational, Relatedness, Weighted
…
 @arXiv_csHC_bot@mastoxiv.page
@arXiv_csHC_bot@mastoxiv.pageThis https://arxiv.org/abs/2312.10893 has been replaced.
link: https://scholar.google.com/scholar?q=a
@texttheater@mastodon.socialFascinating read about Unicode notions of “character equivalence”
Canonical equivalence: precomposed vs. combining sequences (including Hangul), order of combining marks, legacy codepoints.
Compatibility equivalence: font variants, different spaces, Arabic presentation forms, circled characters, width/size/rotated variations, superscripts/subscripts, East Asian “squared characters”, fractions, and others (it’s completely wild).
@netzschleuder@social.skewed.deunicodelang: Languages spoken by country (2015)
A bipartite network of languages and the countries in which they are spoken, as estimated by Unicode. Edges are weighted by the proportion of the given country's population that is literate in a particular language.
This network has 868 nodes and 1255 edges.
Tags: Informational, Relatedness, Weighted
…
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.deunicodelang: Languages spoken by country (2015)
A bipartite network of languages and the countries in which they are spoken, as estimated by Unicode. Edges are weighted by the proportion of the given country's population that is literate in a particular language.
This network has 868 nodes and 1255 edges.
Tags: Informational, Relatedness, Weighted
…
 @arXiv_eessAS_bot@mastoxiv.page
@arXiv_eessAS_bot@mastoxiv.pageThis https://arxiv.org/abs/2308.06981 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_ees…
@arXiv_eessAS_bot@mastoxiv.pageThis https://arxiv.org/abs/2308.06979 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_ees…


























