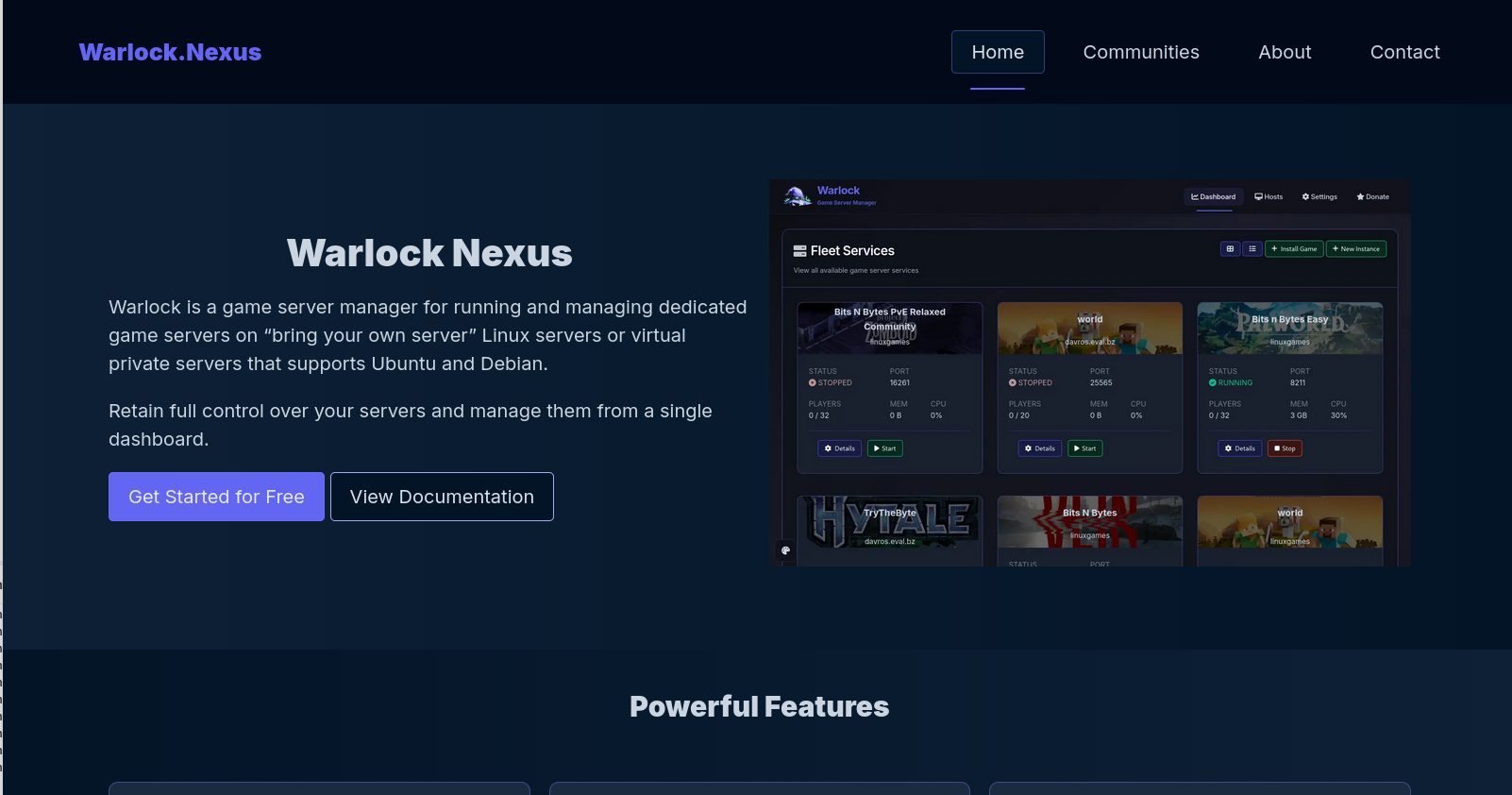
@zachleat@zachleat.com
@zachleat@zachleat.com2026-05-12 14:17:05
A follow up here on action items (assuming you’re already using trusted publishers OIDC to scope releases to a single GitHub Action workflow):
1. Look for any `pull_request_target` GitHub Actions workflows! (this allows external forks/code to run your actions with write access ☠️☠️☠️☠️☠️)
2. Look for use of `cache` in your GitHub Actions release workflow (cache was poisoned/compromised by `pull_request_target` trigger)
Learn more about `pull_request_target`: