Greptile, maker of an AI-powered code review tool, raised a $25M Series A led by Benchmark and launches Greptile v3 (Mike Wheatley/SiliconANGLE)
https://siliconangle.com/2025/09/23/greptile-bags-25m-funding-take-coderabbit-graphite-a…
Measuring the effectiveness of code review comments in GitHub repositories: A machine learning approach
Shadikur Rahman, Umme Ayman Koana, Hasibul Karim Shanto, Mahmuda Akter, Chitra Roy, Aras M. Ismael
https://arxiv.org/abs/2508.16053
@… @… SmartBear researched this in depth in 2015 and demonstrated, with data, what you’re saying.
AI code review startup CodeRabbit raised a $60M Series B led by Scale Venture Partners, valuing the company at $550M, and says it makes $15M in ARR (Marina Temkin/TechCrunch)
https://techcrunch.com/2025/09/16/coderabbit-raises-6…
from my link log —
Why some of us like "interdiff" code review.
https://gist.github.com/thoughtpolice/9c45287550a56b2047c6311fbadebed2
saved 2025-08-20
LLM-Driven Collaborative Model for Untangling Commits via Explicit and Implicit Dependency Reasoning
Bo Hou, Xin Tan, Kai Zheng, Fang Liu, Yinghao Zhu, Li Zhang
https://arxiv.org/abs/2507.16395
AI-Assisted Fixes to Code Review Comments at Scale
Chandra Maddila, Negar Ghorbani, James Saindon, Parth Thakkar, Vijayaraghavan Murali, Rui Abreu, Jingyue Shen, Brian Zhou, Nachiappan Nagappan, Peter C. Rigby
https://arxiv.org/abs/2507.13499
“Developers on teams with high AI adoption complete 21% more tasks and merge 98% more pull requests, but PR review time increases 91%, revealing a critical bottleneck: human approval.“
Maybe it’s confirmation bias, but I can see that. You generate more, maybe harder to comprehend, code that still has to be double checked by people who weren’t involved in the process. That slows you down unless you ignore understanding by, you guessed it, moving fast and breaking things.
Code-Switching in End-to-End Automatic Speech Recognition: A Systematic Literature Review
Maha Tufail Agro, Atharva Kulkarni, Karima Kadaoui, Zeerak Talat, Hanan Aldarmaki
https://arxiv.org/abs/2507.07741
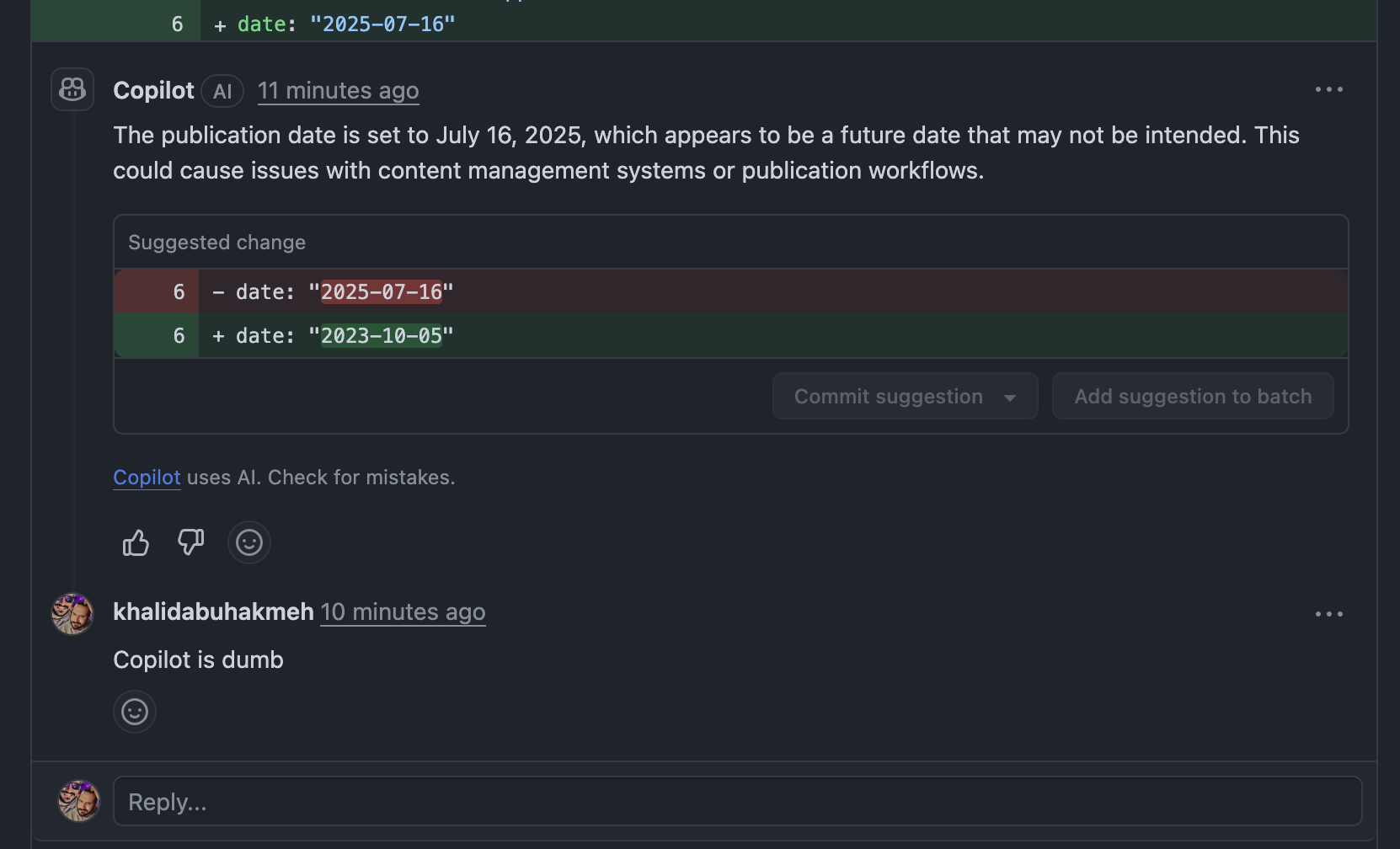
Tried GitHub Copilot code review, and it doesn’t understand the concept of future-dating blog posts. Worse, it suggests a random-ass date. This stuff sucks.
Socio-Technical Smell Dynamics in Code Samples: A Multivocal Review on Emergence, Evolution, and Co-Occurrence
Arthur Bueno, Bruno Cafeo, Maria Cagnin, Awdren Font\~ao
https://arxiv.org/abs/2507.13481

Socio-Technical Smell Dynamics in Code Samples: A Multivocal Review on Emergence, Evolution, and Co-Occurrence
Code samples play a pivotal role in open-source ecosystems (OSSECO), serving as lightweight artifacts that support knowledge transfer, onboarding, and framework adoption. Despite their instructional relevance, these samples are often governed informally, with minimal review and unclear ownership, which increases their exposure to socio-technical degradation. In this context, the co-occurrence and longitudinal interplay of code smells (e.g., large classes, poor modularity) and community smells (…
Some developers say GPT-5 excels at technical reasoning and planning coding tasks and is cost-effective, but Claude Opus and Sonnet still produce better code (Lauren Goode/Wired)
https://www.wired.com/story/gpt-5-coding-review-software-engineering/
@… @… that's something I do reviewing humans. I usually start review with the tests, and if the tests seem to have gaps, the code probably does too. If they seem sufficiently thorough, the code probably needs less focus on the logic a…
From Provable Correctness to Probabilistic Generation: A Comparative Review of Program Synthesis Paradigms
Zurabi Kobaladze, Anna Arnania, Tamar Sanikidze
https://arxiv.org/abs/2508.00013
"the new review of the earlier assessment does not dispute the conclusion that Russia favored the election of Donald J. Trump." #GiftLink
C.I.A. Says Its Leaders Rushed Report on Russia Interference in 2016 Vote - The New York Times
https://www.nytimes.com/2025/07/02/us/politics/russia-trump-2016-election.html?unlocked_article_code=1.Tk8.1oh0.obRdrVnArZxp&smid=url-share
Vibe Coding for UX Design: Understanding UX Professionals' Perceptions of AI-Assisted Design and Development
Jie Li, Youyang Hou, Laura Lin, Ruihao Zhu, Hancheng Cao, Abdallah El Ali
https://arxiv.org/abs/2509.10652
Quo Vadis, Code Review? Exploring the Future of Code Review
Michael Dorner, Andreas Bauer, Darja \v{S}mite, Lukas Thode, Daniel Mendez, Ricardo Britto, Stephan Lukasczyk, Ehsan Zabardast, Michael Kormann
https://arxiv.org/abs/2508.06879
CodeFuse-CR-Bench: A Comprehensiveness-aware Benchmark for End-to-End Code Review Evaluation in Python Projects
Hanyang Guo, Xunjin Zheng, Zihan Liao, Hang Yu, Peng DI, Ziyin Zhang, Hong-Ning Dai
https://arxiv.org/abs/2509.14856
Beim #TagDerDigitalenFreiheit vom @… in #Tübingen am 26./27.07. gibts von mir einen Vortrag, wie man alles Mögliche mit :git:
Next up: principles of using AI for software dev.
For one, don't hand off code for review that you haven't reviewed yourself.
For another, exec expectations don't match current reality on what AI can('t) do.
#GophersUnite
Replaced article(s) found for cs.SE. https://arxiv.org/list/cs.SE/new
[1/1]:
- Knowledge-Guided Prompt Learning for Request Quality Assurance in Public Code Review
Lin Li, Xinchun Yu, Xinyu Chen, Peng Liang
The Impact of Large Language Models (LLMs) on Code Review Process
Antonio Collante, Samuel Abedu, SayedHassan Khatoonabadi, Ahmad Abdellatif, Ebube Alor, Emad Shihab
https://arxiv.org/abs/2508.11034
Automating Thematic Review of Prevention of Future Deaths Reports: Replicating the ONS Child Suicide Study using Large Language Models
Sam Osian, Arpan Dutta, Sahil Bhandari, Iain E. Buchan, Dan W. Joyce
https://arxiv.org/abs/2507.20786
WIP: Leveraging LLMs for Enforcing Design Principles in Student Code: Analysis of Prompting Strategies and RAG
Dhruv Kolhatkar, Soubhagya Akkena, Edward F. Gehringer
https://arxiv.org/abs/2508.11717
Teaching Programming in the Age of Generative AI: Insights from Literature, Pedagogical Proposals, and Student Perspectives
Clemente Rubio-Manzano, Jazna Meza, Rodolfo Fernandez-Santibanez, Christian Vidal-Castro
https://arxiv.org/abs/2507.00108
Does AI Code Review Lead to Code Changes? A Case Study of GitHub Actions
Kexin Sun, Hongyu Kuang, Sebastian Baltes, Xin Zhou, He Zhang, Xiaoxing Ma, Guoping Rong, Dong Shao, Christoph Treude
https://arxiv.org/abs/2508.18771
Automated Code Review Using Large Language Models at Ericsson: An Experience Report
Shweta Ramesh, Joy Bose, Hamender Singh, A K Raghavan, Sujoy Roychowdhury, Giriprasad Sridhara, Nishrith Saini, Ricardo Britto
https://arxiv.org/abs/2507.19115
Fine-Tuning Multilingual Language Models for Code Review: An Empirical Study on Industrial C# Projects
Igli Begolli, Meltem Aksoy, Daniel Neider
https://arxiv.org/abs/2507.19271
Probing Pre-trained Language Models on Code Changes: Insights from ReDef, a High-Confidence Just-in-Time Defect Prediction Dataset
Doha Nam, Taehyoun Kim, Duksan Ryu, Jongmoon Baik
https://arxiv.org/abs/2509.09192
Benchmarking and Studying the LLM-based Code Review
Zhengran Zeng, Ruikai Shi, Keke Han, Yixin Li, Kaicheng Sun, Yidong Wang, Zhuohao Yu, Rui Xie, Wei Ye, Shikun Zhang
https://arxiv.org/abs/2509.01494 …
Metamorphic Testing of Deep Code Models: A Systematic Literature Review
Ali Asgari, Milan de Koning, Pouria Derakhshanfar, Annibale Panichella
https://arxiv.org/abs/2507.22610 h…
Automatic Identification of Machine Learning-Specific Code Smells
Peter Hamfelt, Ricardo Britto, Lincoln Rocha, Camilo Almendra
https://arxiv.org/abs/2508.02541 https://
ChatGPT for Code Refactoring: Analyzing Topics, Interaction, and Effective Prompts
Eman Abdullah AlOmar, Luo Xu, Sofia Martinez, Anthony Peruma, Mohamed Wiem Mkaouer, Christian D. Newman, Ali Ouni
https://arxiv.org/abs/2509.08090
An Empirical Study on the Amount of Changes Required for Merge Request Acceptance
Samah Kansab, Mohammed Sayagh, Francis Bordeleau, Ali Tizghadam
https://arxiv.org/abs/2507.23640
Automated Validation of LLM-based Evaluators for Software Engineering Artifacts
Ora Nova Fandina, Eitan Farchi, Shmulik Froimovich, Rami Katan, Alice Podolsky, Orna Raz, Avi Ziv
https://arxiv.org/abs/2508.02827
 @Techmeme@techhub.social
@Techmeme@techhub.social