 @arXiv_csLG_bot@mastoxiv.page
@arXiv_csLG_bot@mastoxiv.page2026-02-25 16:08:29
Replaced article(s) found for cs.LG. https://arxiv.org/list/cs.LG/new
[6/6]:
- Fast-ThinkAct: Efficient Vision-Language-Action Reasoning via Verbalizable Latent Planning
Chi-Pin Huang, Yunze Man, Zhiding Yu, Min-Hung Chen, Jan Kautz, Yu-Chiang Frank Wang, Fu-En Yang
https://arxiv.org/abs/2601.09708 https://mastoxiv.page/@arXiv_csCV_bot/115898618760721320
- Universality of Many-body Projected Ensemble for Learning Quantum Data Distribution
Quoc Hoan Tran, Koki Chinzei, Yasuhiro Endo, Hirotaka Oshima
https://arxiv.org/abs/2601.18637 https://mastoxiv.page/@arXiv_quantph_bot/115967001797773134
- FROST: Filtering Reasoning Outliers with Attention for Efficient Reasoning
Haozheng Luo, Zhuolin Jiang, Md Zahid Hasan, Yan Chen, Soumalya Sarkar
https://arxiv.org/abs/2601.19001 https://mastoxiv.page/@arXiv_csCL_bot/115972068838908815
- Analysis of Shuffling Beyond Pure Local Differential Privacy
Shun Takagi, Seng Pei Liew
https://arxiv.org/abs/2601.19154 https://mastoxiv.page/@arXiv_csDS_bot/115971701218309765
- CryoLVM: Self-supervised Learning from Cryo-EM Density Maps with Large Vision Models
Weining Fu, Kai Shu, Kui Xu, Qiangfeng Cliff Zhang
https://arxiv.org/abs/2602.02620
- XtraLight-MedMamba for Classification of Neoplastic Tubular Adenomas
Sultana, Afsar, Rahu, Singh, Shula, Combs, Forchetti, Asari
https://arxiv.org/abs/2602.04819
- Flow-Based Conformal Predictive Distributions
Trevor Harris
https://arxiv.org/abs/2602.07633 https://mastoxiv.page/@arXiv_statML_bot/116045671088130364
- GOT-Edit: Geometry-Aware Generic Object Tracking via Online Model Editing
Shih-Fang Chen, Jun-Cheng Chen, I-Hong Jhuo, Yen-Yu Lin
https://arxiv.org/abs/2602.08550 https://mastoxiv.page/@arXiv_csCV_bot/116046486984991360
- UI-Venus-1.5 Technical Report
Venus Team, et al.
https://arxiv.org/abs/2602.09082 https://mastoxiv.page/@arXiv_csCV_bot/116050980295461008
- The Wisdom of Many Queries: Complexity-Diversity Principle for Dense Retriever Training
Xincan Feng, Noriki Nishida, Yusuke Sakai, Yuji Matsumoto
https://arxiv.org/abs/2602.09448 https://mastoxiv.page/@arXiv_csIR_bot/116051022881293649
- Intent Laundering: AI Safety Datasets Are Not What They Seem
Shahriar Golchin, Marc Wetter
https://arxiv.org/abs/2602.16729 https://mastoxiv.page/@arXiv_csCR_bot/116101884238965526
- The Metaphysics We Train: A Heideggerian Reading of Machine Learning
Heman Shakeri
https://arxiv.org/abs/2602.19028 https://mastoxiv.page/@arXiv_csCY_bot/116125225694943789
- Skill-Inject: Measuring Agent Vulnerability to Skill File Attacks
David Schmotz, Luca Beurer-Kellner, Sahar Abdelnabi, Maksym Andriushchenko
https://arxiv.org/abs/2602.20156 https://mastoxiv.page/@arXiv_csCR_bot/116125330557447048
- A Very Big Video Reasoning Suite
Maijunxian Wang, et al.
https://arxiv.org/abs/2602.20159 https://mastoxiv.page/@arXiv_csCV_bot/116125664801070747
toXiv_bot_toot
 @cdarwin@c.im
@cdarwin@c.im2026-03-04 21:00:20
The Military Religious Freedom Foundationhas received a litany of complaints about religious ideology seeping into military orders since the U.S. and Israel began bombing Iran,
independent journalist Jon Larsen first reported.
Mikey Weinstein, founder and president of MRFF,
a nonprofit group established 21 years ago that focuses on ensuring constitutional protections for service members,
spoke with HuffPost by phone Tuesday morning and illuminated some details of the…

 @arXiv_csDS_bot@mastoxiv.page
@arXiv_csDS_bot@mastoxiv.page2026-02-03 07:35:01
End Cover for Initial Value Problem: Complete Validated Algorithms with Complexity Analysis
Bingwei Zhang, Chee Yap
https://arxiv.org/abs/2602.00162 https://arxiv.org/pdf/2602.00162 https://arxiv.org/html/2602.00162
arXiv:2602.00162v1 Announce Type: new
Abstract: We consider the first-order autonomous ordinary differential equation \[ \mathbf{x}' = \mathbf{f}(\mathbf{x}), \] where $\mathbf{f} : \mathbb{R}^n \to \mathbb{R}^n$ is locally Lipschitz. For a box $B_0 \subseteq \mathbb{R}^n$ and $h > 0$, we denote by $\mathrm{IVP}_{\mathbf{f}}(B_0,h)$ the set of solutions $\mathbf{x} : [0,h] \to \mathbb{R}^n$ satisfying \[ \mathbf{x}'(t) = \mathbf{f}(\mathbf{x}(t)), \qquad \mathbf{x}(0) \in B_0 . \]
We present a complete validated algorithm for the following \emph{End Cover Problem}: given $(\mathbf{f}, B_0, \varepsilon, h)$, compute a finite set $\mathcal{C}$ of boxes such that \[ \mathrm{End}_{\mathbf{f}}(B_0,h) \;\subseteq\; \bigcup_{B \in \mathcal{C}} B \;\subseteq\; \mathrm{End}_{\mathbf{f}}(B_0,h) \oplus [-\varepsilon,\varepsilon]^n , \] where \[ \mathrm{End}_{\mathbf{f}}(B_0,h) = \left\{ \mathbf{x}(h) : \mathbf{x} \in \mathrm{IVP}_{\mathbf{f}}(B_0,h) \right\}. \]
Moreover, we provide a complexity analysis of our algorithm and introduce a novel technique for computing the end cover $\mathcal{C}$ based on covering the boundary of $\mathrm{End}_{\mathbf{f}}(B_0,h)$. Finally, we present experimental results demonstrating the practicality of our approach.
toXiv_bot_toot
 @hex@kolektiva.social
@hex@kolektiva.social2026-02-21 21:10:33
After the whole Adam Something "dating advice for leftist men" thing, I realized I should probably write something about that. I didn't, but I realized I should. Here I am sort of getting around to it.
I had a friend call me an "elder" at one point. I was like 35 at that time, but like... a lot of old leftists are just dead or in prison, so we take what we can get I guess. Being also an elder in the sense that I'm an elder millennial, who is also a parent and married for almost 10 years and all that, I guess I'm technically qualified.
So here it is, dating advice for (straight cis) leftist men:
1. Don't.
That's it, actually. That's the whole thing. Let me explain a bit.
First of all, this is dating advice for neuroatypical folks. We're way overrepresented in both extremes because this system wasn't built for us. And that's who is *the most* confused by all the relationship stuff, and most likely to try to apply all this masculinity/manosphere bullshit. I'm also talking a bit from experience here, as a neruo-spicy trying to "figure out" how to date within a paradigm entirely built around neurotypicals and their relationships. It's garbage. Throw it out. There's nothing worth saving.
His video had some line comparing not having sex to your house being on fire. I'm not gonna bother to quote it because I'm busy with actual life. But like, that's exactly what I'm talking about. I recognize that and it's horribly destructive. Men who buy in to patriarchy actually believe this, because those men value themselves based on (hetro) sex. Yeah, if you think you're worthless because you aren't "getting laid" then yeah, you're gonna feel like that's an emergency.
"Dating" as a paradigm turns humans into roles. It dehumanizes us all, and thus makes human connection much harder. It is a game that, like thermonuclear war, can only be won by not playing.
When you abandon "dating" and just act like a human, everything starts to be easier. There's no such thing as being "friend zoned" because you're just friends. Sometimes friendships become other things, sometimes they don't. It doesn't actually matter, because if you're actually there for friendship then you don't *need* anything else.
My grandma, at 98 I think, gave me some advice. My grandparents always got along well, and were married for enough decades that I listened really closely. She told me I should just do things I loved to do and everything else would work itself out.
And it kind of did.
I understand the fear, the idea that you'll die alone. I get that. I get the loneliness. It all hits a lot harder when you have ADHD emotions and past trauma. I get that. But that fear is self-manifesting. When you build your confidence, when you don't *need* to be "in a relationship," you have more room to actually build relationships. For me, dating was dehumanizing. When I abandoned that, I was able to actually be a good partner, and I was able to find my partner.
I would advise against marriage as well, but we did get married for legal reasons. It can still be hard to maintain that, to see each other as people rather than roles. That becomes extra hard as parents. But the times that we cut through that are the times we're closest. Those are the times when it becomes easier to remember that we're both humans and all human relationships need tending.
Roles don't need to be tended because they are classifications. Classifications are static. But relationships between humans are not. Humans are messy and chaotic. Humans have all kinds of complex needs and desires.
So yeah, don't date. Just be a human and see what happens. Maybe google "relationship anarchy" and see where it takes you.
If you have ADHD, it can be especially useful to understand that relationships with neurotypical folks can be especially difficult. Assume you're incompatible with 90% of the population as your baseline, and you'll start to understand why the standard "dating" thing has made you feel so alienated and miserable.
Neurotypical folks generally have no idea that atypicality exists, much less how it impacts relationships. Having to conform to a neurotypical relationship just adds additional mental strain unless you find someone (really special) who can do at least some of the work.
The ADHD thing was especially important for me. There were so many things I was told to do in specific ways by neurotypicals that never worked for me. Their advice always made me feel like a failure. When I was finally diagnosed, I realized they were just giving advice for the wrong type of brain. It was advice I could never use. Basically all dating advice I ever got fell into this same category.
That's my braindump. Maybe I'll develop it more in the future, but I'm busy so maybe not. I hope it helps someone who is struggling like I was.
 @bourgwick@heads.social
@bourgwick@heads.social2025-12-26 21:44:50
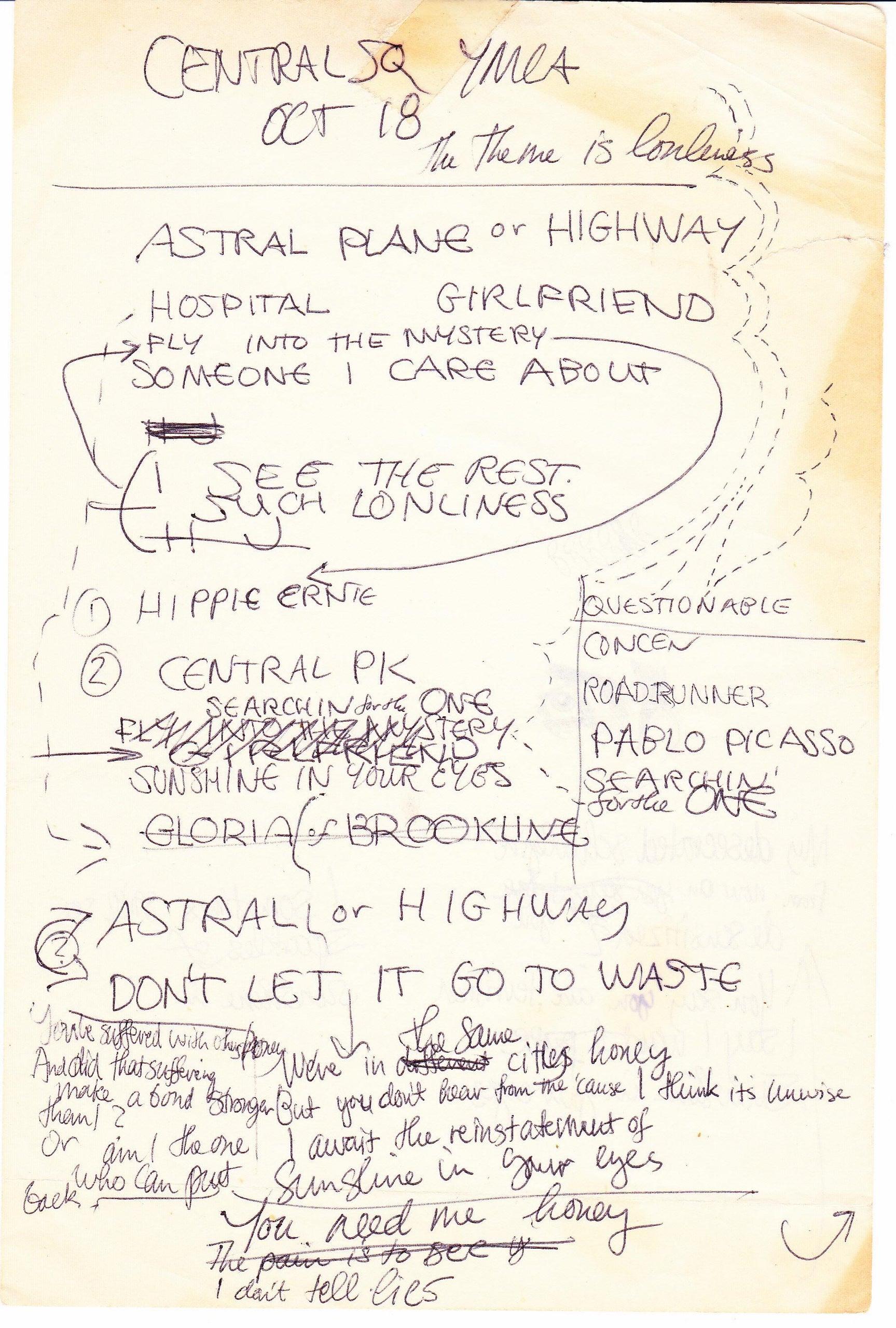
i got a bit obsessed with the modern lovers this year & attempted to assemble a complete-as-possible 1970-1974 live chronology. it's far from complete, but found lots of fun stuff, including a setlist for what might be the 1st gig & ads for their shows in bermuda. https://jessejarnow.com/2025/12/the-mo<…



 @mgorny@social.treehouse.systems
@mgorny@social.treehouse.systems2025-12-25 13:13:41
1. Plan going to Opole, via Kościan.
2. When you enter the train to Kościan, you discover that the change to Opole is delayed 15 minutes already. Consider changing in Leszno instead; if the delay increases, you'd have more options there.
3. Discover that there aren't any more options in Leszno today. Your change is delayed 30 minutes already. Return the reservations, and take one the other way, to Poznań instead.
4. Train station in Kościan. The displays aren't showing any delays, trains are announced normally. Tell people about the delays, so they won't stand in the -10°C waiting for the train to arrive.
5. Take the train to Poznań, and try to figure out what to do next.
6. Discover that the only reasonable choice going forward is Inowrocław: no delays and good return connection. It's the same train, so take another reservation. Your current seat is already taken there, so move elsewhere.
7. Your train should be followed by another one in the same direction, that departs from Poznań 6 minutes later. However, your train ends up waiting for another delayed train, so the other train goes first. The delay further increases as your train needs to slow down after the other train.
8. Reach Inowrocław 10 minutes later. That's not a problem, since you didn't have enough to see for all the time there anyway.
9. Discover that the town is more interesting than you thought, and you'd use more time.
10. When you almost get to the station, discover that your train is 10 minutes late. Not that you have any use for that time at this point.
11. When you're at the station, the train keeps increasing delay while waiting at the previous station, in Bydgoszcz. The station displays are completely useless, as they show only a random subset of regional trains, for no apparent reason. The announcements include all trains, but are rarely given.
12. The delay keeps increasing. Start thinking about getting a reservation for the next train to Poznań, in case it arrived first. You can't return the reservation after the planned departure time, and you can't have two reservations simultaneously, so reserve the seat from Mogilno, the next station.
13. The next train arrives first. While on board, you discover that you're not going to have any train home for 1.5 hr. Take another seat reservation to Leszno, where you can change into a suburban train and get home 15 minutes earlier than from Poznań. This time, your seat is still free.
14. The train departs 15 minutes delayed from Poznań. After all, you're changing trains in Kościan.
So I was going to go south, to Opole, via Kościan. Instead, I've ended up slingshotting north to Inowrocław, and getting back home via the same train as if I were in Opole.
#rail
 @chiraag@mastodon.online
@chiraag@mastodon.online2026-02-26 02:31:02
I'm sorry, *what*
https://discourse.ardour.org/t/basis-for-delay-compensation/113020/2
> Ardour’s latency delay compensation was the subject of a Ph.D thesis.
And somehow this is the first I'm hearing about this. Completely unpretentious…

 @inthehands@hachyderm.io
@inthehands@hachyderm.io2025-12-18 17:03:18
Something that just drives me up the wall about this particular area of Git (merge conflicts) is that, beyond the all-too-typical Git problem of sloppy terminology, this is bad feature design. In most situations, “use ours” and “user theirs” are •both• the wrong answer! There are two doors, and they’re •both• trapdoors.
If you have a merge conflict, that means that you changed something •and• somebody else changed something, and your job is to •synthesize• both changes. To use one is to discard the other, which is usually not what you want!
The thing Git (and every Git GUI) ought to surface is a three-way merge: show me what I changed and what they changed ••relative to the nearest common ancestor••. Yes yes yes, I know it’s possible to finagle that into view with Git. It should be the danged default. It is what I should see first. It is what I should see if I have no idea what I’m doing.
1/ https://hachyderm.io/@jeremydmiller/115741417416659492
 @arXiv_mathDG_bot@mastoxiv.page
@arXiv_mathDG_bot@mastoxiv.page2026-02-27 07:56:40
On the first eigenvalue of the area Jacobi operator for complex curves in K\"ahler surfaces
Zhenxiao Xie
https://arxiv.org/abs/2602.22744 https://arxiv.org/pdf/2602.22744 https://arxiv.org/html/2602.22744
arXiv:2602.22744v1 Announce Type: new
Abstract: In this paper, we investigate the first eigenvalue $\Lambda_1$ of the area Jacobi operator for complex curves in K\"ahler surfaces, establishing an extrinsic counterpart to the classical Lichnerowicz theorem for the Laplace-Beltrami operator. By analyzing the second variation of a conformally invariant Willmore-type functional, we derive the lower bound $\Lambda_1 \geq 2\,\mathfrak{Ric}$, where $\mathfrak{Ric}$ denotes the infimum of the ambient Ricci curvature. For K\"ahler-Einstein surfaces with positive Einstein constant $\mathfrak{c}>0$, this bound reduces to $\Lambda_1 \geq 2\mathfrak{c}$. We then explore the equality case, computing the exact dimension of the corresponding first eigenspace in terms of the area, genus, and the dimension of a space of holomorphic sections. This analysis shows that the equality is achieved for all curves of genus $g \leq 1$.
toXiv_bot_toot
 @penguin42@mastodon.org.uk
@penguin42@mastodon.org.uk2026-01-29 13:31:45
I upgraded my backup Scaleway VM from debian 11 to debian 13 (trixie); 11->12 went easily; but 12->13 was a fight. First off an old motd script (scw-metadata) stopped me logging in; and then after a reboot it landed at grub-rescue> complaining about a messing symbol ('grub_is_lockdown') - that turned out to be that there was an old fallback Grub in /boot/efi/EFI/BOOT/BOOTX64.EFI which is what it was booting from rather than the EFI/debian one
1/n 🧵