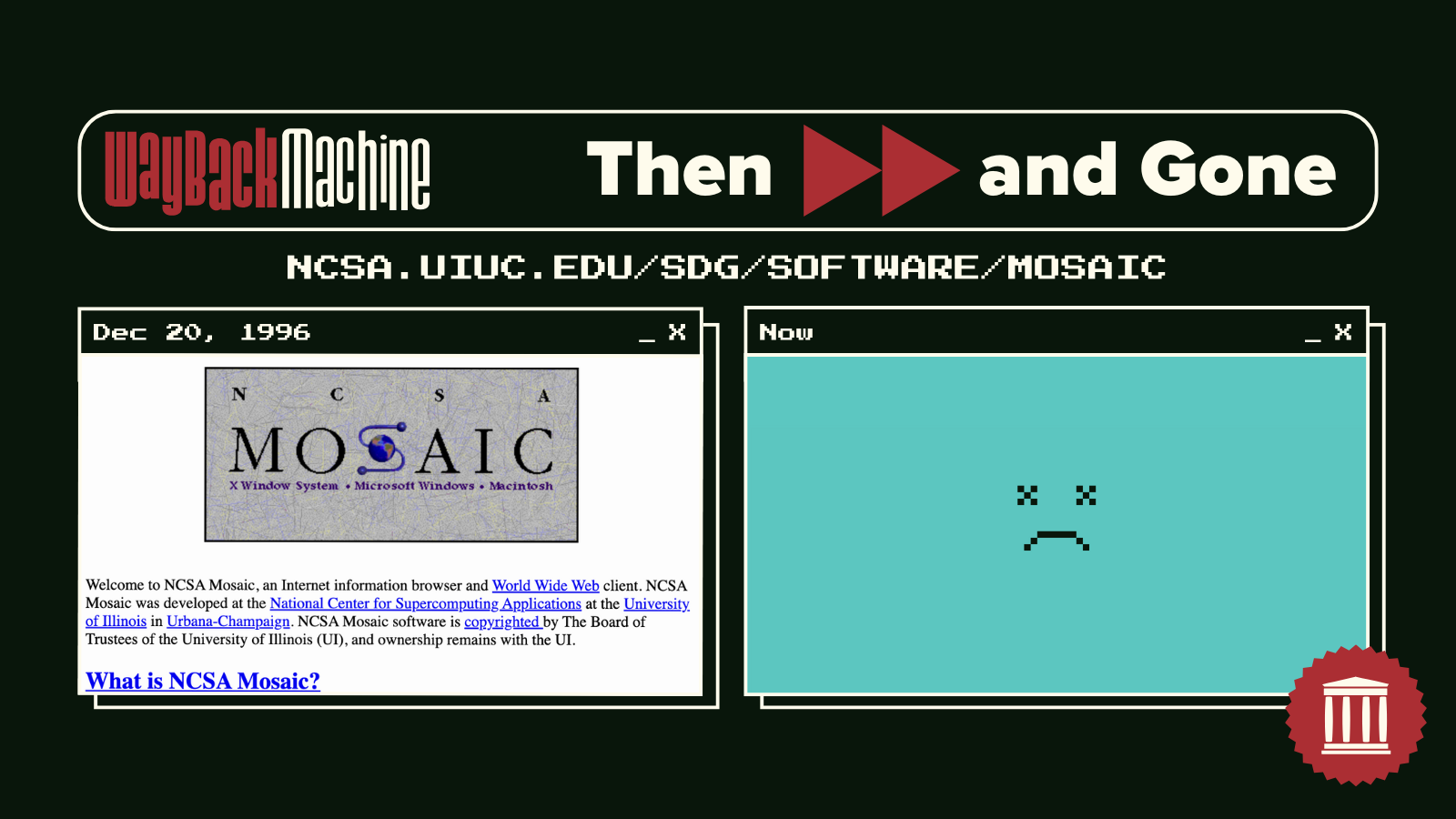
@brewsterkahle@mastodon.archive.org
@brewsterkahle@mastodon.archive.org2025-11-29 16:14:33
@brewsterkahle@mastodon.archive.org @Mediagazer@mstdn.social
@Mediagazer@mstdn.socialThe Guardian, FT, NYT, USA Today Co., and others are blocking or limiting the Internet Archive's crawlers to prevent AI crawlers from using IA as a backdoor (Nieman Lab)
https://www.niemanlab.org/2026/01/news-publishers-limit-i…
 @bourgwick@heads.social
@bourgwick@heads.social*screams in historian/normal person who uses the wayback machine* https://mstdn.social/@Mediagazer/115979614480582544
 @detondev@social.linux.pizza
@detondev@social.linux.pizzaFor the last few days i was avoiding the online as much as i could on a suicidal episode, self isolating from the noise of the world. Yet paradoxically to some, the best thing to happen during this time and the main reason im back so soon was listening to almost nothing but cassettes from the NOISE-ARCH archive. tap in.
https://archive.org…
 @markhburton@mstdn.social
@markhburton@mstdn.socialThe Internet Archive and Wayback Machine is s valuable resource but only 1/1000 users donate to its running costs.
You can join them.
Donate to the Internet Archive.
https://archive.org/donate/
 @stiefkind@mastodon.social
@stiefkind@mastodon.socialORWO Rezepte. Nein, das ist nichts zu kochen/essen, darin geht es um die »Behandlung fotografischer Materialien«. Think Chemiebaukasten: https://archive.org/details/orwo-rezepte-1972/mode/2up
 @jorgecandeias@mastodon.social
@jorgecandeias@mastodon.socialI guess the Internet Archive is now a for-Proffitt...
https://mastodon.archive.org/@internetarchive/115611174274779543
 @pre@boing.world
@pre@boing.worldIt’s about this time of year I like to check my backups and download my archives.
One archive I download is the archive of my Mastodon posts. Pretty much the only one now I’ve left the corporate web really.
I also like to copy the contents of my public fediverse posts into my own diary within my vimwiki.
Keep it all in one place for easy and local search.
Here’s the script I use, it’s very short and just copies the content of every post in the archive into a new diary entry in the vimwiki diary.
If it finds something already there, it appends.
It checks if it’s already written this post into the diary to avoid duplicating it when you run it over and every again every month or year or whatever.
Paste it into a new text-file called toVimWiki.php, download and unzip your mastodon archive, and run the script with php, passing it the path to the archive’s outbox.json and the root diary directory.
My diary is honestly mostly just public posts these days. Ain’t much in it I won’t blab about on the internet for likes and lols.
#archive #mastodon #vimwiki #endOfYear
@brewsterkahle@mastodon.archive.orgHorse Bots ! -- but not what you think-- but I couldn't resist.
Thank you, Department of Ag leaflets, this one from 1973.
https://archive.org/details/horsebotshowtoco450unit_2/page/n1/mode/2up
(lots of leaflets:

 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.deus_agencies: U.S. government agency websites (2018)
50 networks, one for each U.S. state, representing the web-based links between their associated government agencies websites. A node is an entire agency website and a directed edge (i,j) represents the existence of a hyperlink from any webpage in website i to some webpage in website j. Data was collected with a crawler. Nodes are annotated with the number of webpages per website, website name (related to its government function) and U…
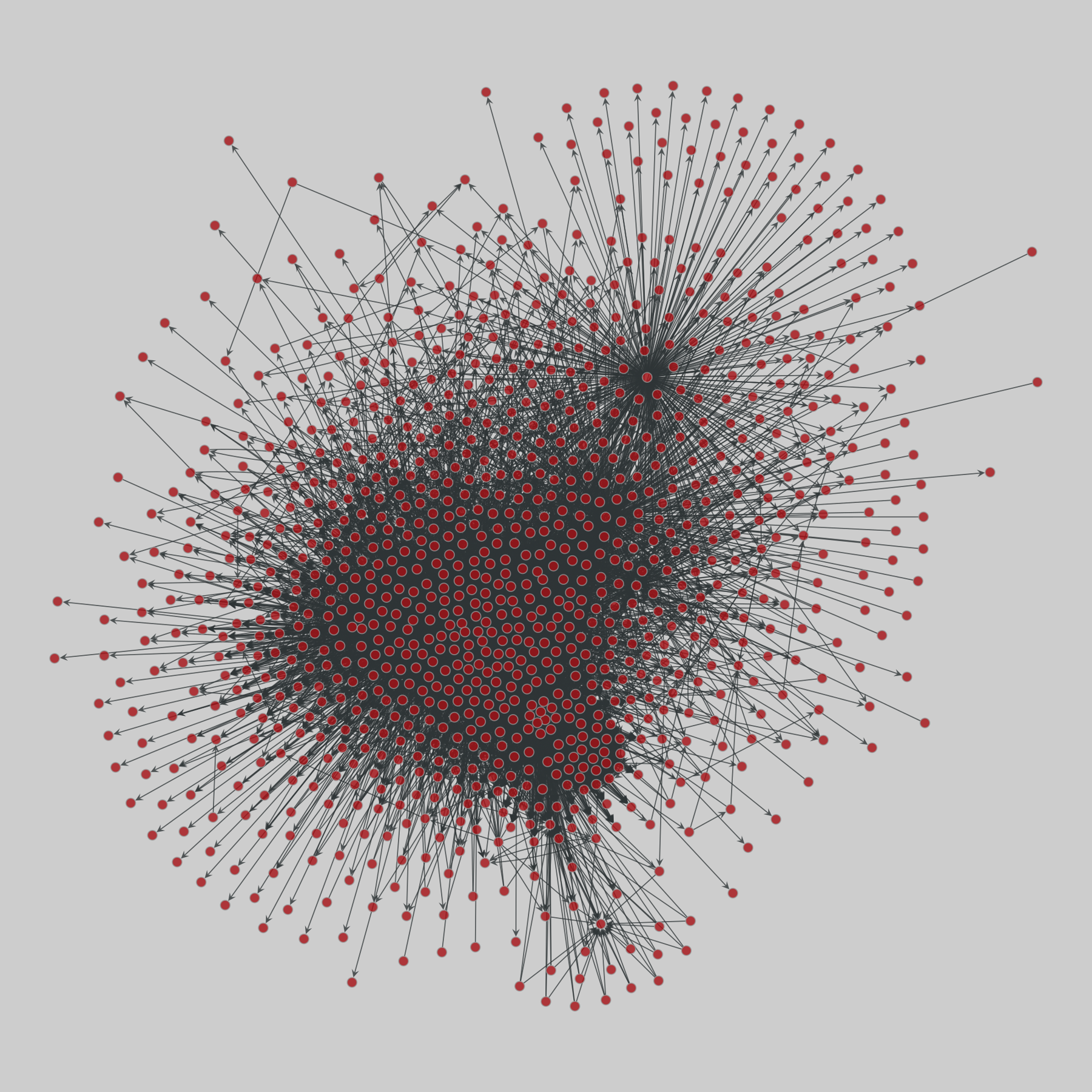
 @fanf@mendeddrum.org
@fanf@mendeddrum.orgfrom my link log —
Engineering and operations at the Internet Archive.
https://hackernoon.com/the-long-now-of-the-web-inside-the-internet-archives-fight-against-forgetting
saved 2026-01-20
@bourgwick@heads.socialevening peace: brian eno & j. peter schwalm perform "4-D music" inside a volcano in spain in 2001, studio-quality radio broadcast. https://archive.org/details/01.-part-i
@brewsterkahle@mastodon.archive.org"Rabbit Recipes," US dept of Ag 1930. (We are looking for things to cook to celebrate public domain day Jan 21st 2026 re: 1930!)
Not so sure about Rabbit Recipes, but nice layout. Thank you US Dept of Ag for digitizing this (I love my job).
What will you cook to celebrate public domain day?
http…

 @oligneisti@social.linux.pizza
@oligneisti@social.linux.pizzaThere is someone who has taken a lot of old films and used AI to colorize them badly and "boosted" the frame rate from 24 to 60fps and then uploaded this trash to the Internet Archive.
I hate this. Films shot in b&w have an aesthetic that is destroyed by colorizing them. Video games might look better with more frames per second but movies don't. We didn't accidentally settle on 24fps, it was trial and error. A film shot in 60fps looks bad. A movie that has been ar…
@netzschleuder@social.skewed.deus_agencies: U.S. government agency websites (2018)
50 networks, one for each U.S. state, representing the web-based links between their associated government agencies websites. A node is an entire agency website and a directed edge (i,j) represents the existence of a hyperlink from any webpage in website i to some webpage in website j. Data was collected with a crawler. Nodes are annotated with the number of webpages per website, website name (related to its government function) and U…
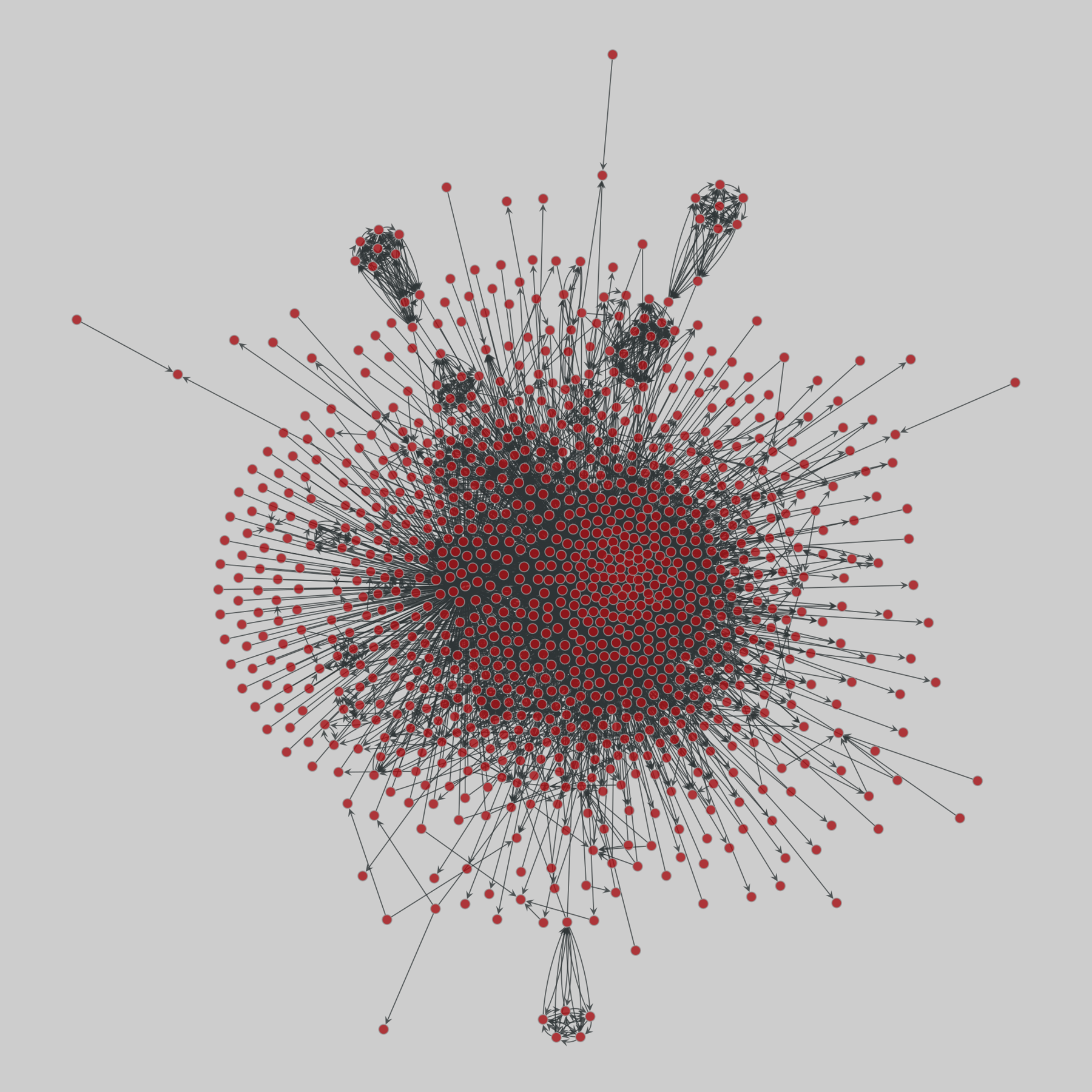
 @Techmeme@techhub.social
@Techmeme@techhub.socialAn interview with Internet Archive founder Brewster Kahle on copyright lawsuits that threatened to bankrupt the nonprofit, fair use, IA's future, AI, and more (Ashley Belanger/Ars Technica)
https://arstechnica.com/tech-policy/20
 @nohillside@smnn.ch
@nohillside@smnn.chPulled 60 Minutes segment on CECOT : CBS : Free Download, Borrow, and Streaming : Internet Archive https://archive.org/details/60minutes-cecotsegment

 @cosmos4u@scicomm.xyz
@cosmos4u@scicomm.xyzRE: #CECOT piece is everywhere on the web - even the Internet Archive: #60Minutes ... a #StreisandEffect writ large: https://en.wikipedia.org/wiki/Streisand_effect
 @cdarwin@c.im
@cdarwin@c.imThe Internet Archive might sound like a thriving organization,
but it only recently emerged from years of bruising copyright battles that threatened to bankrupt the beloved library project.
In the end, the fight led to more than 500,000 books being removed from the Archive’s “Open Library.”
“We survived,” Internet Archive founder Brewster Kahle told Ars.
“But it wiped out the Library.”
An Internet Archive spokesperson confirmed to Ars that the archive currently…
 @floheinstein@chaos.social
@floheinstein@chaos.socialHoly moly, Anna's Archive hat Spotify gescraped und archiviert: ~ 300 TiB
https://annas-archive.org/blog/backing-up-spotify.html
Alleine die Datenbank mit allen Metadaten ist schon 200 GiB und wird munter via Torrent geteilt

 @makeratschool@kanoa.de
@makeratschool@kanoa.deIhr kennt natürlich alle die Greatful Dead Collection im Internet Archive. Nicht?
Dann nehmt euch ein bisschen Zeit, es gibt da knapp 18000 Aufnahmen von diversen Konzerten.
https://archive.org/details/GratefulDead?tab=collection
@jorgecandeias@mastodon.socialOf all the lies of the internet, the worst is probably "the internet is forever".
Anyone who's been here for a while can name hundreds of internet stuff that is completely gone.
(yes, I know about the Internet Archive. I'm also aware of the many blind spots and broken links the Archive has. And of the fact that it isn't really searchable)
 @StephenRees@mas.to
@StephenRees@mas.toThe link leads to a video. Generally speaking I prefer to read rather than watch - but this is an exception
"While the early web promised connection and creativity, today’s internet is increasingly fragmented, paywalled, and dominated by a few powerful platforms.
“The truth is paywalled, and the lies are free”
 @gevoel@mastodon.green
@gevoel@mastodon.greenJarl: Wat in een schimmig hoekje van het internet begon, is nu overal, van Davos tot het Binnenhof | de Volkskrant
https://archive.ph/ueF7e
@brewsterkahle@mastodon.archive.orgPublic Domain Day short film contest by @… on NPR!
https://www.npr.org/2026/01/21/nx-s1-56777

 @teledyn@mstdn.ca
@teledyn@mstdn.cathe Cornell University Library is now online, for free, no registration or login, just there, 76,474 books now tucked in at the Internet Archive
https://archive.org/details/cornell
@brewsterkahle@mastodon.archive.orgnew way to see the breadth and depth of the web, in this case Dutch websites.
fun.
https://display.archive.org/nl
congratulations @…

 @rmdes@mstdn.social
@rmdes@mstdn.socialCurrently retrieving my old blog.rmendes.net data from the internet archive 2020-2023 with the intent to migrate it to this place !
 @fgraver@hcommons.social
@fgraver@hcommons.socialI bought my first modem at a post-Christmas sale in December 1992, and spent a few shot months discovering BBS’s and the text-based net before getting Mosaic and discover WWW in 1993. It opened up a whole new world! https://mastodon.archive.org/@internetarchive/11565105…
@Mediagazer@mstdn.socialAn interview with Internet Archive founder Brewster Kahle on copyright lawsuits that threatened to bankrupt the nonprofit, fair use, IA's future, AI, and more (Ashley Belanger/Ars Technica)
https://arstechnica.com/tech-policy/20
 @UP8@mastodon.social @jorgecandeias@mastodon.social
@UP8@mastodon.social @jorgecandeias@mastodon.socialYeah. I miss this internet. I really do.
https://mastodon.archive.org/@internetarchive/115764640377949472
@netzschleuder@social.skewed.deus_agencies: U.S. government agency websites (2018)
50 networks, one for each U.S. state, representing the web-based links between their associated government agencies websites. A node is an entire agency website and a directed edge (i,j) represents the existence of a hyperlink from any webpage in website i to some webpage in website j. Data was collected with a crawler. Nodes are annotated with the number of webpages per website, website name (related to its government function) and U…
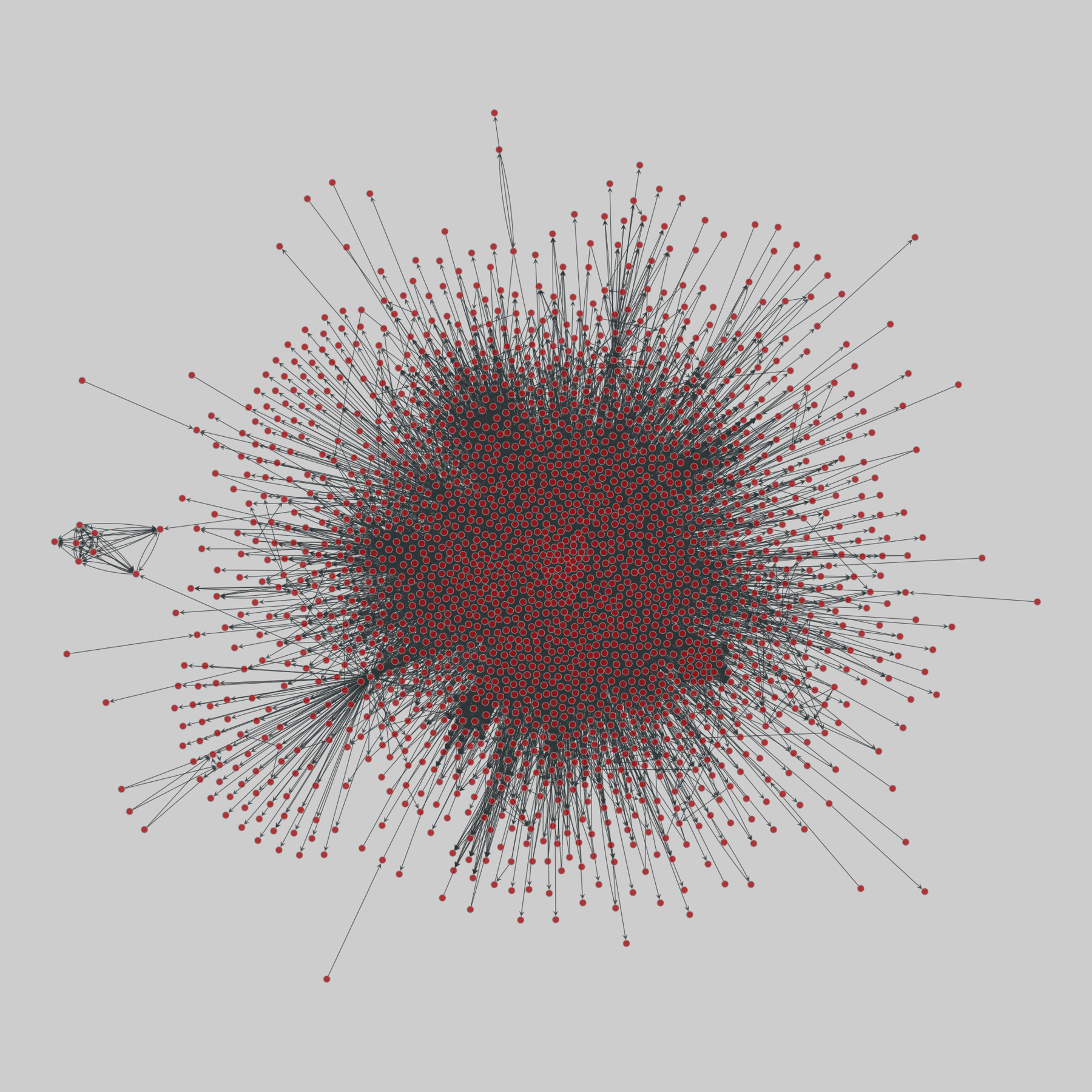
 @thomasfuchs@hachyderm.io
@thomasfuchs@hachyderm.ioGotta love the Internet Archive posting AI slop into my timeline
 @servelan@newsie.social
@servelan@newsie.socialInternet Archive’s legal fights are over, but its founder mourns what was lost - Ars Technica
https://arstechnica.com/tech-policy/2025/11/the-internet-archive-survived-major-copyright-losses-whats-next/
 @simon_lucy@mastodon.social
@simon_lucy@mastodon.social@… @…
We rely upon the Internet Archive, original copies and printed material.
@brewsterkahle@mastodon.archive.org"The Richmond is Home to 1 Trillion Web Pages
A Friday afternoon tour of the Internet Archive, which recently celebrated its 29th anniversary".
Nice article about the free tours at the
@…
every friday at 1pm.

 @davej@dice.camp
@davej@dice.campIf anyone needs me, I’ll be right here rereading Butler’s “War is a Racket”(https://archive.org/details/WarIsARacket/) with Creedence’s “Fortunate Son” (https://
@cdarwin@c.im93 photos released from the Jeffrey Epstein estate (Dec. 12, 2025)
Usage Public Domain Mark 1.0Topics
Jeffrey Epstein
Item Size 63.6M
https://archive.org/details/house-oversight-034614
Photos originally hosted here:
 @mela@zusammenkunft.net
@mela@zusammenkunft.netMela, warum röchelt Jellyfin auf dem Heimserver so?
Hm, vielleicht habe ich herausgefunden, dass das Internet Archive ein umfangreiches Repository uralter Filk-Tapes hat.
 @mia@hcommons.social
@mia@hcommons.socialI love how everything I write now (or edit after reviews) involves extra steps in looking up Internet Archive links for British Library web pages and blog posts so that links in footnotes actually work.
* I lied, I don't love it.
 @nic@geno.social
@nic@geno.social“What the coming of the computer did, "just in time," was to make it unnecessary to create social inventions, to change the system in any way. So in that sense, the computer has acted as fundamentally a conservative force, which kept power or even solidified power where it already existed.” Joseph Weizenbaum, 1985
@brewsterkahle@mastodon.archive.org"The very first question to be considered is the applicability of the Copyright Law to the Moon. "
Thinking ahead (in 1952) about interplanetary copyrights :). if aliens have "Two Heads, Two Authors?"
really fun, worth reading.
ht…
 @nelson@tech.lgbt
@nelson@tech.lgbtRecently reminded of Straight to Hell, the 1975—20?? zine featuring porny gay stories that were often real life narratives. Transgressive and important documentation. The Internet Archive has PDF scans of 5 edited book collections!
Harvard man, Harvard man,
blond for no reason. I'd
sure as shit quit the Quad
for him, scratch every dance
from my card for him; kiss
sunshine goodbye to open
his fly; trade clothes
for sheets, miss other meets
for him, for him
 @brewsterkahle@mastodon.archive.org
@brewsterkahle@mastodon.archive.orgproject idea (possibly using AI): record a take of songs from old sheet music books
Starting with something like the Grange book of sheet music below and record them ... Apparently the music can get to midi via Play Score 2, and other programs can could sing the lyrics.
or better yet, if anyone wants to perform the songs and upload them to the archive, you could link it into a review of the book.
@brewsterkahle@mastodon.archive.orgmedia conglomerates are leading the way against open internet law by fining cloudflare:
Italy's "shadowy cabal of European media elites" ... "scheme to censor the Internet. The scheme, which even the EU has called concerning, required us within a mere 30 minutes of notification to fully censor from the Internet any sites a shadowy cabal of European media elites deemed against their interests. No judicial oversight. No due process. No appeal. No transparency. "
@stiefkind@mastodon.social»Beim Erscheinen des zweiten Theiles der Geschichte von Pommern hat der Verfasser zunächst die Pflicht des Dankes gegen das Gedächtniß des in Gott ruhenden Königs zu bekennen, dessen huldreiche Unterstützung dem Forscher Muße und Freudigkeit zu seinem schweren Werke gewährte.«
SO beginnt man Vorworte 🙂
Quelle: F. W. Barthold, Geschichte von Rügen und Pommern (1840)
@thomasfuchs@hachyderm.ioSure would be cool if one of the big tech companies would give the Internet Archive money to make a full-text searchable index of the Wayback Machine.
@stiefkind@mastodon.socialZufallsfund: im @… liegen alle 49 Jahrgänge der Satire-Zeitschrift "Simplicissimus" (1896-1944). Darin zu blättern ist gar großartig: https://
@Mediagazer@mstdn.socialA profile of nonprofit Common Crawl, which has scraped billions of webpages since 2013, including paywalled ones, to build an archive used by OpenAI and others (Alex Reisner/The Atlantic)
https://www.theatlantic.com/technology/202…
@netzschleuder@social.skewed.deus_agencies: U.S. government agency websites (2018)
50 networks, one for each U.S. state, representing the web-based links between their associated government agencies websites. A node is an entire agency website and a directed edge (i,j) represents the existence of a hyperlink from any webpage in website i to some webpage in website j. Data was collected with a crawler. Nodes are annotated with the number of webpages per website, website name (related to its government function) and U…
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.deus_agencies: U.S. government agency websites (2018)
50 networks, one for each U.S. state, representing the web-based links between their associated government agencies websites. A node is an entire agency website and a directed edge (i,j) represents the existence of a hyperlink from any webpage in website i to some webpage in website j. Data was collected with a crawler. Nodes are annotated with the number of webpages per website, website name (related to its government function) and U…
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.deus_agencies: U.S. government agency websites (2018)
50 networks, one for each U.S. state, representing the web-based links between their associated government agencies websites. A node is an entire agency website and a directed edge (i,j) represents the existence of a hyperlink from any webpage in website i to some webpage in website j. Data was collected with a crawler. Nodes are annotated with the number of webpages per website, website name (related to its government function) and U…
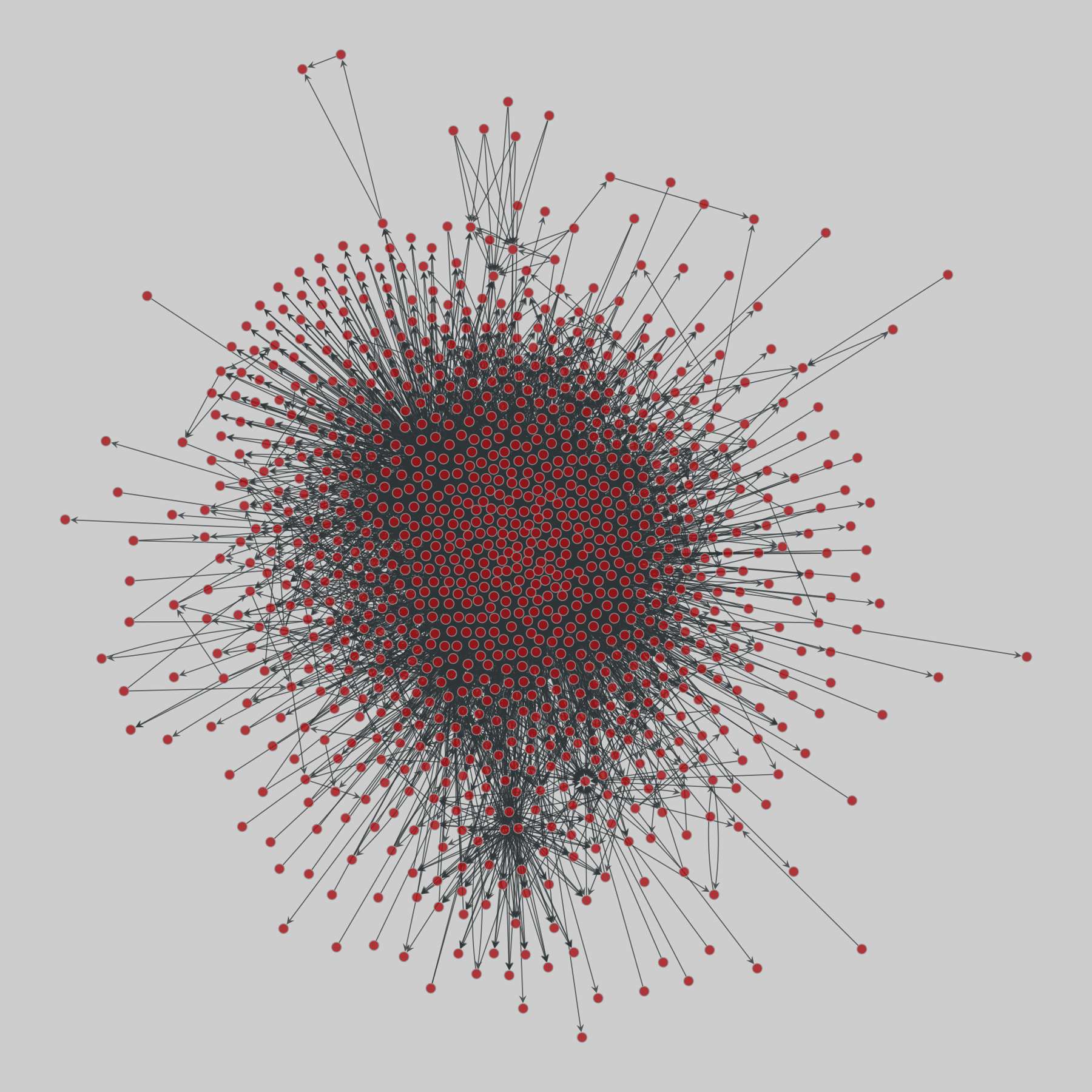 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.deus_agencies: U.S. government agency websites (2018)
50 networks, one for each U.S. state, representing the web-based links between their associated government agencies websites. A node is an entire agency website and a directed edge (i,j) represents the existence of a hyperlink from any webpage in website i to some webpage in website j. Data was collected with a crawler. Nodes are annotated with the number of webpages per website, website name (related to its government function) and U…
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.deus_agencies: U.S. government agency websites (2018)
50 networks, one for each U.S. state, representing the web-based links between their associated government agencies websites. A node is an entire agency website and a directed edge (i,j) represents the existence of a hyperlink from any webpage in website i to some webpage in website j. Data was collected with a crawler. Nodes are annotated with the number of webpages per website, website name (related to its government function) and U…