OpenAI and Apollo Research trained o3 and o4-mini versions to not engage in "scheming", or secretly pursuing undesirable goals, reducing "covert actions" ~30X (Radhika Rajkumar/ZDNET)
https://www.zdnet.com/article/ai-models-kn
A Study on Thinking Patterns of Large Reasoning Models in Code Generation
Kevin Halim, Sin G. Teo, Ruitao Feng, Zhenpeng Chen, Yang Gu, Chong Wang, Yang Liu
https://arxiv.org/abs/2509.13758
Defending Diffusion Models Against Membership Inference Attacks via Higher-Order Langevin Dynamics
Benjamin Sterling, Yousef El-Laham, M\'onica F. Bugallo
https://arxiv.org/abs/2509.14225
Evaluation Awareness Scales Predictably in Open-Weights Large Language Models
Maheep Chaudhary, Ian Su, Nikhil Hooda, Nishith Shankar, Julia Tan, Kevin Zhu, Ashwinee Panda, Ryan Lagasse, Vasu Sharma
https://arxiv.org/abs/2509.13333
All Models Are Wrong, But Can They Be Useful? Lessons from COVID-19 Agent-Based Models: A Systematic Review
Emma Von Hoene, Sara Von Hoene, Szandra Peter, Ethan Hopson, Emily Csizmadia, Faith Fenyk, Kai Barner, Timothy Leslie, Hamdi Kavak, Andreas Zufle, Amira Roess, Taylor Anderson
https://arxiv.org/abs/2509.13346
Dual-Actor Fine-Tuning of VLA Models: A Talk-and-Tweak Human-in-the-Loop Approach
Piaopiao Jin, Qi Wang, Guokang Sun, Ziwen Cai, Pinjia He, Yangwei You
https://arxiv.org/abs/2509.13774
Comprehensive Evaluation of CNN-Based Audio Tagging Models on Resource-Constrained Devices
Jordi Grau-Haro, Ruben Ribes-Serrano, Javier Naranjo-Alcazar, Marta Garcia-Ballesteros, Pedro Zuccarello
https://arxiv.org/abs/2509.14049
PREDICT-GBM: Platform for Robust Evaluation and Development of Individualized Computational Tumor Models in Glioblastoma
L. Zimmer, J. Weidner, M. Balcerak, F. Kofler, I. Ezhov, B. Menze, B. Wiestler
https://arxiv.org/abs/2509.13360
Sample Size Calculations for the Development of Risk Prediction Models that Account for Performance Variability
Menelaos Pavlou, Rumana Z. Omar, Gareth Ambler
https://arxiv.org/abs/2509.14028
Parallelizable Feynman-Kac Models for Universal Probabilistic Programming
Michele Boreale (University of Florence), Luisa Collodi (University of Florence)
https://arxiv.org/abs/2509.14092
The impact of modeling approaches on controlling safety-critical, highly perturbed systems: the case for data-driven models
Piotr {\L}aszkiewicz, Maria Carvalho, Cl\'audia Soares, Pedro Louren\c{c}o
https://arxiv.org/abs/2509.13531
Evaluating the Limits of QAOA Parameter Transfer at High-Rounds on Sparse Ising Models With Geometrically Local Cubic Terms
Elijah Pelofske, Marek Rams, Andreas B\"artschi, Piotr Czarnik, Paolo Braccia, Lukasz Cincio, Stephan Eidenbenz
https://arxiv.org/abs/2509.13528
@… we need better licensing models across the board
Scrub It Out! Erasing Sensitive Memorization in Code Language Models via Machine Unlearning
Zhaoyang Chu, Yao Wan, Zhikun Zhang, Di Wang, Zhou Yang, Hongyu Zhang, Pan Zhou, Xuanhua Shi, Hai Jin, David Lo
https://arxiv.org/abs/2509.13755
A small number of samples can poison LLMs of any size:
https://www.anthropic.com/research/small-samples-poison
"In a joint study with the UK AI Security Institute and the Alan Turing Institute, we found that as few as 250 malicious documents can produce a "
RepCaM : Exploring Transparent Visual Prompt With Inference-Time Re-Parameterization for Neural Video Delivery
Rongyu Zhang, Xize Duan, Jiaming Liu, Li Du, Yuan Du, Dan Wang, Shanghang Zhang, Fangxin Wang
https://arxiv.org/abs/2509.14002
Differential Privacy in Federated Learning: Mitigating Inference Attacks with Randomized Response
Ozer Ozturk, Busra Buyuktanir, Gozde Karatas Baydogmus, Kazim Yildiz
https://arxiv.org/abs/2509.13987
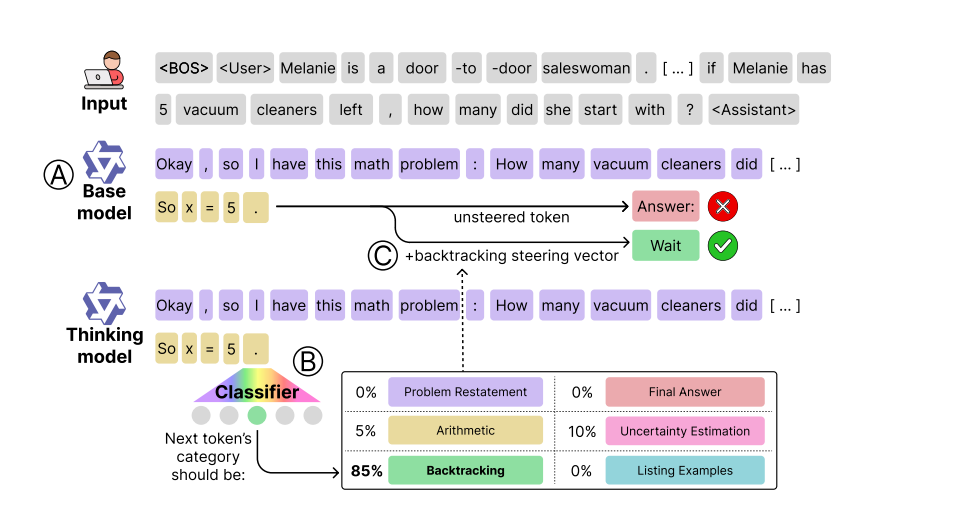
Always fun/challenging to read new AI (pre)papers like this. "Base models know how to reason, thinking models learn when".
#AI #Google #reasoning
"By examining several widely used AI models designed for cancer detection, the researchers found that performance varied depending on patients’ self-reported gender, race, and age. They also identified multiple reasons why these disparities occur."
What AI Learned From Cancer Slides Shocked Researchers
https://scitechdaily.com/what-ai-learned-from-cancer-slides-shocked-researchers/
Diving into Mitigating Hallucinations from a Vision Perspective for Large Vision-Language Models
Weihang Wang, Xinhao Li, Ziyue Wang, Yan Pang, Jielei Zhang, Peiyi Li, Qiang Zhang, Longwen Gao
https://arxiv.org/abs/2509.13836
TICL: Text-Embedding KNN For Speech In-Context Learning Unlocks Speech Recognition Abilities of Large Multimodal Models
Haolong Zheng, Yekaterina Yegorova, Mark Hasegawa-Johnson
https://arxiv.org/abs/2509.13395
New OpenAI models likely to pose "high" cybersecurity risk
OpenAI says the cyber capabilities of its frontier AI models are accelerating and warns Wednesday that upcoming models are likely to pose a "high" risk […]
😶🌫️ https://www.axios.com/2025/12/10/openai-ne
OpenHA: A Series of Open-Source Hierarchical Agentic Models in Minecraft
Zihao Wang, Muyao Li, Kaichen He, Xiangyu Wang, Zhancun Mu, Anji Liu, Yitao Liang
https://arxiv.org/abs/2509.13347
A tree-based Polynomial Chaos expansion for surrogate modeling and sensitivity analysis of complex numerical models
Faten Ben Said (CERMICS, EDF R\&D LNHE), Aur\'elien Alfonsi (CERMICS, MATHRISK), Anne Dutfoy (EDF R\&D PERICLES), C\'edric Goeury (EDF R\&D LNHE, LHSV), Magali Jodeau (EDF R\&D LNHE, LHSV), Julien Reygner (CERMICS, RT-UQ), Fabrice Zaoui (EDF R\&D LNHE)
PhysicalAgent: Towards General Cognitive Robotics with Foundation World Models
Artem Lykov, Jeffrin Sam, Hung Khang Nguyen, Vladislav Kozlovskiy, Yara Mahmoud, Valerii Serpiva, Miguel Altamirano Cabrera, Mikhail Konenkov, Dzmitry Tsetserukou
https://arxiv.org/abs/2509.13903
End-to-End Complexity Analysis for Quantum Simulation of the Extended Jaynes-Cummings Models
Nam Nguyen, Michael Yu, Alan Robertson, Hiromichi Nishimura, Samuel J. Elman, Benjamin Koltenbah
https://arxiv.org/abs/2509.13546
Integrating Text and Time-Series into (Large) Language Models to Predict Medical Outcomes
Iyadh Ben Cheikh Larbi, Ajay Madhavan Ravichandran, Aljoscha Burchardt, Roland Roller
https://arxiv.org/abs/2509.13696
Consistent View Alignment Improves Foundation Models for 3D Medical Image Segmentation
Puru Vaish, Felix Meister, Tobias Heimann, Christoph Brune, Jelmer M. Wolterink
https://arxiv.org/abs/2509.13846
Crash Report Enhancement with Large Language Models: An Empirical Study
S M Farah Al Fahim (Peter), Md Nakhla Rafi (Peter), Zeyang Ma (Peter), Dong Jae Kim (Peter), Tse-Hsun (Peter), Chen
https://arxiv.org/abs/2509.13535
FlightDiffusion: Revolutionising Autonomous Drone Training with Diffusion Models Generating FPV Video
Valerii Serpiva, Artem Lykov, Faryal Batool, Vladislav Kozlovskiy, Miguel Altamirano Cabrera, Dzmitry Tsetserukou
https://arxiv.org/abs/2509.14082
Large Language Models Discriminate Against Speakers of German Dialects
Minh Duc Bui, Carolin Holtermann, Valentin Hofmann, Anne Lauscher, Katharina von der Wense
https://arxiv.org/abs/2509.13835
Interleaving Natural Language Prompting with Code Editing for Solving Programming Tasks with Generative AI Models
Victor-Alexandru P\u{a}durean, Paul Denny, Andrew Luxton-Reilly, Alkis Gotovos, Adish Singla
https://arxiv.org/abs/2509.14088
Evolution of meta's llama models and parameter-efficient fine-tuning of large language models: a survey
Abdulhady Abas Abdullah, Arkaitz Zubiaga, Seyedali Mirjalili, Amir H. Gandomi, Fatemeh Daneshfar, Mohammadsadra Amini, Alan Salam Mohammed, Hadi Veisi
https://arxiv.org/abs/2510.12178
OpenAI launches FrontierScience, a benchmark to measure models' expert-level scientific reasoning with 700 questions, finding GPT-5.2 is its strongest model (OpenAI)
https://openai.com/index/frontierscience/
Benchmarking foundation models for hyperspectral image classification: Application to cereal crop type mapping
Walid Elbarz, Mohamed Bourriz, Hicham Hajji, Hamd Ait Abdelali, Fran\c{c}ois Bourzeix
https://arxiv.org/abs/2510.11576
Automated Triaging and Transfer Learning of Incident Learning Safety Reports Using Large Language Representational Models
Peter Beidler, Mark Nguyen, Kevin Lybarger, Ola Holmberg, Eric Ford, John Kang
https://arxiv.org/abs/2509.13706
Source: OpenAI rolled back ChatGPT's model router, which sent some queries to reasoning models, for Free and $5/month Go tiers, as it was costly and hurt DAUs (Maxwell Zeff/Wired)
https://www.wired.com/story/openai-router-relaunch-gpt-5-sam-altman/
Explicit Reasoning Makes Better Judges: A Systematic Study on Accuracy, Efficiency, and Robustness
Pratik Jayarao, Himanshu Gupta, Neeraj Varshney, Chaitanya Dwivedi
https://arxiv.org/abs/2509.13332
Evaluating Classical Software Process Models as Coordination Mechanisms for LLM-Based Software Generation
Duc Minh Ha, Phu Trac Kien, Tho Quan, Anh Nguyen-Duc
https://arxiv.org/abs/2509.13942
Crosslisted article(s) found for cs.CY. https://arxiv.org/list/cs.CY/new
[1/1]:
- All Models Are Wrong, But Can They Be Useful? Lessons from COVID-19 Agent-Based Models: A Systema...
Von Hoene, Von Hoene, Peter, Hopson, Csizmadia, Fenyk, Barner, Leslie, Kavak, Zufle, Roess, Anderson
…
Multi-robot Multi-source Localization in Complex Flows with Physics-Preserving Environment Models
Benjamin Shaffer, Victoria Edwards, Brooks Kinch, Nathaniel Trask, M. Ani Hsieh
https://arxiv.org/abs/2509.14228
Apertus: Democratizing Open and Compliant LLMs for Global Language Environments
Alejandro Hern\'andez-Cano, Alexander H\"agele, Allen Hao Huang, Angelika Romanou, Antoni-Joan Solergibert, Barna Pasztor, Bettina Messmer, Dhia Garbaya, Eduard Frank \v{D}urech, Ido Hakimi, Juan Garc\'ia Giraldo, Mete Ismayilzada, Negar Foroutan, Skander Moalla, Tiancheng Chen, Vinko Sabol\v{c}ec, Yixuan Xu, Michael Aerni, Badr AlKhamissi, Ines Altemir Marinas, Mohammad Hossein Amani, Matin An…
CrowdAgent: Multi-Agent Managed Multi-Source Annotation System
Maosheng Qin, Renyu Zhu, Mingxuan Xia, Chenkai Chen, Zhen Zhu, Minmin Lin, Junbo Zhao, Lu Xu, Changjie Fan, Runze Wu, Haobo Wang
https://arxiv.org/abs/2509.14030
The Allen Institute of AI launches Bolmo 7B and Bolmo 1B, claiming they are "the first fully open byte-level language models", built on its Olmo 3 models (Emilia David/VentureBeat)
https://venturebeat.com/ai/bolmos-architecture-unlock…
DriveVLA-W0: World Models Amplify Data Scaling Law in Autonomous Driving
Yingyan Li, Shuyao Shang, Weisong Liu, Bing Zhan, Haochen Wang, Yuqi Wang, Yuntao Chen, Xiaoman Wang, Yasong An, Chufeng Tang, Lu Hou, Lue Fan, Zhaoxiang Zhang
https://arxiv.org/abs/2510.12796
TGPO: Tree-Guided Preference Optimization for Robust Web Agent Reinforcement Learning
Ziyuan Chen, Zhenghui Zhao, Zhangye Han, Miancan Liu, Xianhang Ye, Yiqing Li, Hongbo Min, Jinkui Ren, Xiantao Zhang, Guitao Cao
https://arxiv.org/abs/2509.14172
Teaching LLMs to Plan: Logical Chain-of-Thought Instruction Tuning for Symbolic Planning
Pulkit Verma, Ngoc La, Anthony Favier, Swaroop Mishra, Julie A. Shah
https://arxiv.org/abs/2509.13351
Mind the Ethics! The Overlooked Ethical Dimensions of GenAI in Software Modeling Education
Shalini Chakraborty, Lola Burgue\~no, Nathalie Moreno, Javier Troya, Paula Mu\~noz
https://arxiv.org/abs/2509.13896
Imagined Autocurricula
Ahmet H. G\"uzel, Matthew Thomas Jackson, Jarek Luca Liesen, Tim Rockt\"aschel, Jakob Nicolaus Foerster, Ilija Bogunovic, Jack Parker-Holder
https://arxiv.org/abs/2509.13341
Google releases Cell2Sentence-Scale 27B (C2S-Scale), a 27B-parameter foundation model for single-cell analysis built on its Gemma family of open models (The Keyword)
https://blog.google/technology/ai/google-gemma-ai-cancer-therapy-discovery/
Canary-1B-v2 & Parakeet-TDT-0.6B-v3: Efficient and High-Performance Models for Multilingual ASR and AST
Monica Sekoyan, Nithin Rao Koluguri, Nune Tadevosyan, Piotr Zelasko, Travis Bartley, Nick Karpov, Jagadeesh Balam, Boris Ginsburg
https://arxiv.org/abs/2509.14128
Anthropic's Skills for Claude, which are conceptually very simple, may become a bigger deal than MCP, whose high token usage is its most significant limitation (Simon Willison/Simon Willison's Weblog)
https://simonwillison.net/2025/Oct/16/claude-skills/
You Are What You Train: Effects of Data Composition on Training Context-aware Machine Translation Models
Pawe{\l} M\k{a}ka, Yusuf Can Semerci, Jan Scholtes, Gerasimos Spanakis
https://arxiv.org/abs/2509.14031
EvoCAD: Evolutionary CAD Code Generation with Vision Language Models
Tobias Preintner, Weixuan Yuan, Adrian K\"onig, Thomas B\"ack, Elena Raponi, Niki van Stein
https://arxiv.org/abs/2510.11631
OpenAI says the cyber capabilities of its frontier AI models are accelerating and warns that upcoming models are likely to pose a "high" risk (Ina Fried/Axios)
https://www.axios.com/2025/12/10/openai-new-models-cybersecurity-risks
Improving Context Fidelity via Native Retrieval-Augmented Reasoning
Suyuchen Wang, Jinlin Wang, Xinyu Wang, Shiqi Li, Xiangru Tang, Sirui Hong, Xiao-Wen Chang, Chenglin Wu, Bang Liu
https://arxiv.org/abs/2509.13683
Hybrid Quantum-Classical Neural Networks for Few-Shot Credit Risk Assessment
Zheng-an Wang, Yanbo J. Wang, Jiachi Zhang, Qi Xu, Yilun Zhao, Jintao Li, Yipeng Zhang, Bo Yang, Xinkai Gao, Xiaofeng Cao, Kai Xu, Pengpeng Hao, Xuan Yang, Heng Fan
https://arxiv.org/abs/2509.13818
Teaching According to Talents! Instruction Tuning LLMs with Competence-Aware Curriculum Learning
Yangning Li, Tingwei Lu, Yinghui Li, Yankai Chen, Wei-Chieh Huang, Wenhao Jiang, Hui Wang, Hai-Tao Zheng, Philip S. Yu
https://arxiv.org/abs/2509.13790
Multitask finetuning and acceleration of chemical pretrained models for small molecule drug property prediction
Matthew Adrian, Yunsie Chung, Kevin Boyd, Saee Paliwal, Srimukh Prasad Veccham, Alan C. Cheng
https://arxiv.org/abs/2510.12719
DiffEM: Learning from Corrupted Data with Diffusion Models via Expectation Maximization
Danial Hosseintabar, Fan Chen, Giannis Daras, Antonio Torralba, Constantinos Daskalakis
https://arxiv.org/abs/2510.12691
Mitigating the Noise Shift for Denoising Generative Models via Noise Awareness Guidance
Jincheng Zhong, Boyuan Jiang, Xin Tao, Pengfei Wan, Kun Gai, Mingsheng Long
https://arxiv.org/abs/2510.12497
Representation-Based Exploration for Language Models: From Test-Time to Post-Training
Jens Tuyls, Dylan J. Foster, Akshay Krishnamurthy, Jordan T. Ash
https://arxiv.org/abs/2510.11686
 @Techmeme@techhub.social
@Techmeme@techhub.social