@arXiv_csSD_bot@mastoxiv.page
@arXiv_csSD_bot@mastoxiv.page2025-10-14 09:45:18
Matchmaker: An Open-source Library for Real-time Piano Score Following and Systematic Evaluation
Jiyun Park, Carlos Cancino-Chac\'on, Suhit Chiruthapudi, Juhan Nam
https://arxiv.org/abs/2510.10087 …
@arXiv_csSD_bot@mastoxiv.pageMatchmaker: An Open-source Library for Real-time Piano Score Following and Systematic Evaluation
Jiyun Park, Carlos Cancino-Chac\'on, Suhit Chiruthapudi, Juhan Nam
https://arxiv.org/abs/2510.10087 …
 @arXiv_statML_bot@mastoxiv.page
@arXiv_statML_bot@mastoxiv.pagetorchsom: The Reference PyTorch Library for Self-Organizing Maps
Louis Berthier, Ahmed Shokry, Maxime Moreaud, Guillaume Ramelet, Eric Moulines
https://arxiv.org/abs/2510.11147 …
 @arXiv_csAR_bot@mastoxiv.page
@arXiv_csAR_bot@mastoxiv.pageFeNOMS: Enhancing Open Modification Spectral Library Search with In-Storage Processing on Ferroelectric NAND (FeNAND) Flash
Sumukh Pinge, Ashkan Moradifirouzabadi, Keming Fan, Prasanna Venkatesan Ravindran, Tanvir H. Pantha, Po-Kai Hsu, Zheyu Li, Weihong Xu, Zihan Xia, Flavio Ponzina, Winston Chern, Taeyoung Song, Priyankka Ravikumar, Mengkun Tian, Lance Fernandes, Huy Tran, Hari Jayasankar, Hang Chen, Chinsung Park, Amrit Garlapati, Kijoon Kim, Jongho Woo, Suhwan Lim, Kwangsoo Kim, Wa…
 @erc_bk@fosstodon.org
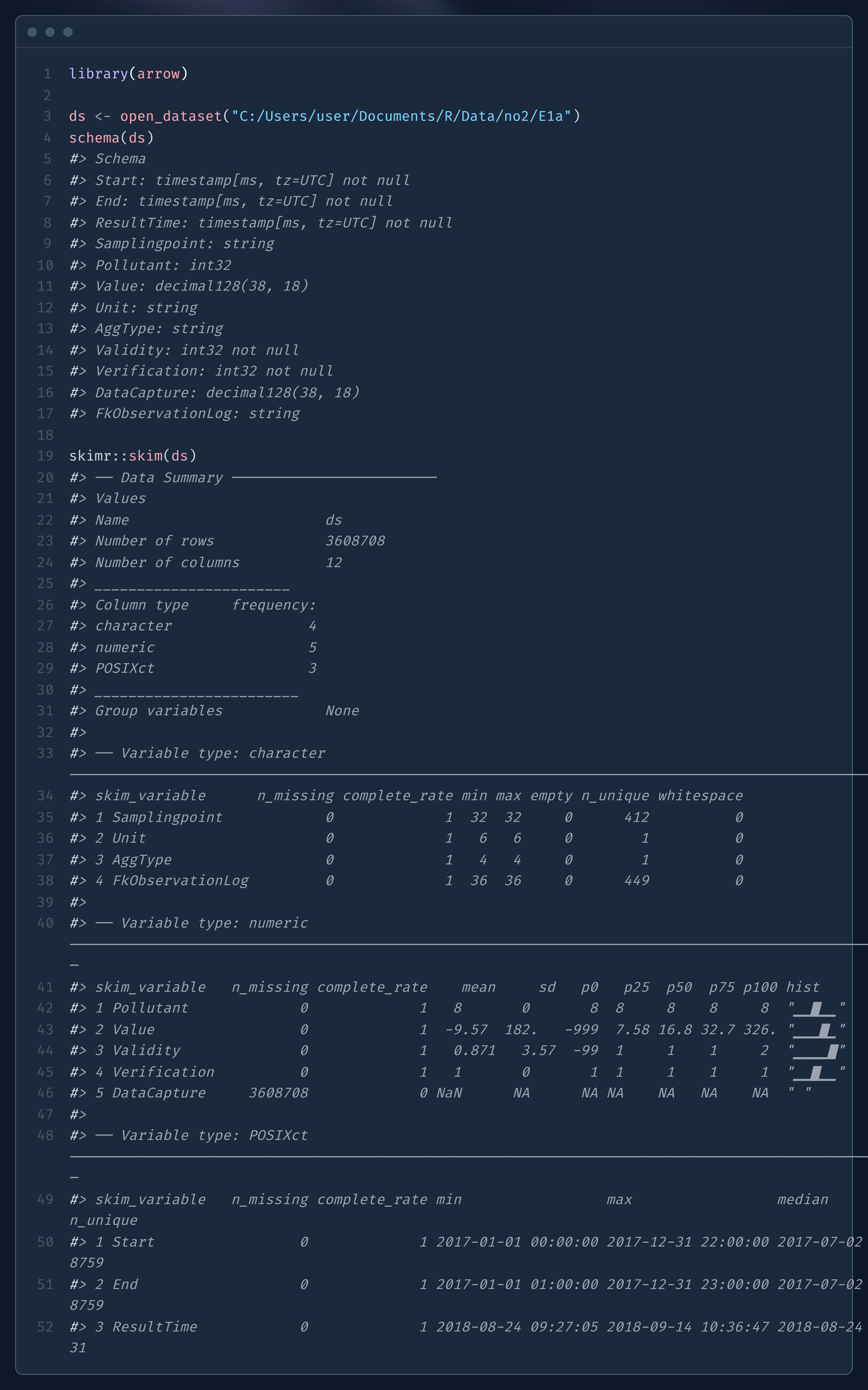
@erc_bk@fosstodon.orgDidn't know that {skimr::skim} worked an arrow object. It's pretty cool, but it hits your RAM pretty hard. That's only a 70MB directory of parquet files, and my RAM usage went up by ~1.3GB. #RStats Code: https://ray.so/fCoXwso
 @Adam@social.lein.us
@Adam@social.lein.usA cool open source UI component library, but a lot of them I looked at don't have good semantics or accessibility compliance. #webdevelopment
 @Techmeme@techhub.social
@Techmeme@techhub.socialPolars, the Amsterdam-based startup behind the popular open-source library for data manipulation of the same name, raised a €18M Series A led by Accel (Anna Heim/TechCrunch)
https://techcrunch.com/2025/09/29/the-startup-behind-open-source-t…
 @mia@hcommons.social
@mia@hcommons.socialJoin me at two events at the British Library later this month:
https://www.bl.uk/stories/blogs/posts/knowledge-is-human
On 20 October, the British Library is joining forces with Wikimedia UK and the Wikimedia Foundation to explore the impact of AI on ope…
 @cheeaun@mastodon.social
@cheeaun@mastodon.socialWondering what happened 🤔
“Quiet UI, Cory LaViska's recently open-sourced library, just vanished” #WebDev
 @johl@mastodon.xyz
@johl@mastodon.xyz"This project is unmaintained and has known security issues. It is foolish to use this software to process untrusted data“,
says the README of libxml2, a library that many other Open Source projects depend on.
https://gitlab.gnome.org/GNOME/libxml2
 @fanf@mendeddrum.org
@fanf@mendeddrum.orgfrom my link log —
libcpu: a library to emulate several CPU architectures using LLVM.
https://github.com/libcpu/libcpu
saved 2020-04-14 https://dotat.a…
 @lschiff@mastodon.sdf.org
@lschiff@mastodon.sdf.orgA great opportunity is now open for a Tech Team Manager in the Discovery and Delivery Program at the California Digital Library where I work! This is a great group of folks doing innovative work in core library areas. #jobs #libraries
 @jerome@jasette.facil.services
@jerome@jasette.facil.servicesStarging this Sunday, every single Toronto Public Library will be open on Sunday.
Thank you Olivia Chow for that
https://www.thestar.com/news/gta/city-hall/all-toronto-…
@fanf@mendeddrum.orgfrom my link log —
libcpu: a library to emulate several CPU architectures using LLVM.
https://github.com/libcpu/libcpu
saved 2020-04-14 https://dotat.a…
 @teledyn@mstdn.ca
@teledyn@mstdn.ca"Literature in Context evolved from two independent projects, one by John O’Brien at The University of Virginia, and one by Tonya Howe, at Marymount University. O’Brien and Howe joined forces in 2017 and successfully applied for a Level II Advancement Grant from the National Endowment for the Humanities Office of Digital Humanities in collaboration with Christine Ruotolo, Director of Research in the Arts and Humanities at The University of Virginia Libraries (HAA-258768-18). In 2022, the project was awarded a second grant from the NEH ODH (HAA-290349-23), as well as an Open Course Grant from VIVA, Virginia’s academic library consortium. In April 2025, the second federal grant was terminated, along with many others, by DOGE."
 @jorgecandeias@mastodon.social
@jorgecandeias@mastodon.socialI guess the Internet Archive is now a for-Proffitt...
https://mastodon.archive.org/@internetarchive/115611174274779543
 @frankel@mastodon.top
@frankel@mastodon.top @arXiv_physicsfludyn_bot@mastoxiv.page
@arXiv_physicsfludyn_bot@mastoxiv.pagekh2d-solver: A Python Library for Idealized Two-Dimensional Incompressible Kelvin-Helmholtz Instability
Sandy H. S. Herho, Nurjanna J. Trilaksono, Faiz R. Fajary, Gandhi Napitupulu, Iwan P. Anwar, Faruq Khadami, Dasapta E. Irawan
https://arxiv.org/abs/2509.16080
 @awinkler@openbiblio.social
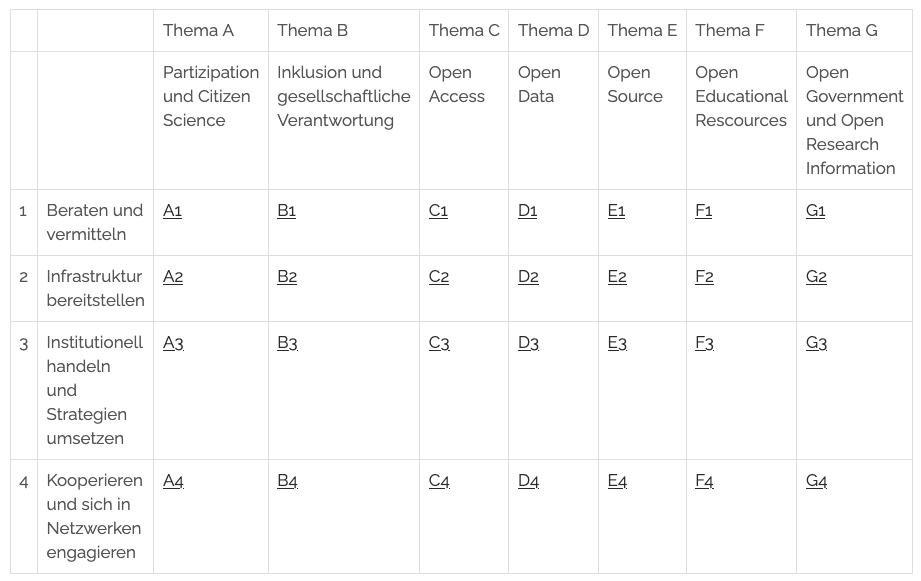
@awinkler@openbiblio.socialNützliche Matrix zum Thema openness für die diesjährige Auflage des Open Library Badge (#openness
 @arXiv_eessSP_bot@mastoxiv.page
@arXiv_eessSP_bot@mastoxiv.pageLibEMER: A novel benchmark and algorithms library for EEG-based Multimodal Emotion Recognition
Zejun Liu, Yunshan Chen, Chengxi Xie, Huan Liu
https://arxiv.org/abs/2509.19330 ht…
@lschiff@mastodon.sdf.orgLast night's #elections lesson: change is possible! Start where you're at, which includes your local library board!
@librariesftp.bsky.social
helps folks do this with candidate training. Learn more in this newsletter & at the Dec. 4 open house!
 @paulwermer@sfba.social
@paulwermer@sfba.socialAm I the only one who is bewildered that a location so close to city hall, less than 1/3 of a mile to Van Ness BRT, BART, CIvic Center MUNI station, 5, 6 and 19 bus lines is a low priority location for urban infill? Close to a great library and large open space with playgrounds? Why there is not serious activity on the part of the city to build mixed income housing so as to help bring a range of incomes into the community? Why isn't the city mapping a strategy that transitions this n…
@PaulWermer@sfba.socialAm I the only one who is bewildered that a location so close to city hall, less than 1/3 of a mile to Van Ness BRT, BART, CIvic Center MUNI station, 5, 6 and 19 bus lines is a low priority location for urban infill? Close to a great library and large open space with playgrounds? Why there is not serious activity on the part of the city to build mixed income housing so as to help bring a range of incomes into the community? Why isn't the city mapping a strategy that transitions this n…
 @arXiv_physicschemph_bot@mastoxiv.page
@arXiv_physicschemph_bot@mastoxiv.pageA Reusable Library for Second-Order Orbital Optimization Using the Trust Region Method
Jonas Greiner, Ida-Marie H{\o}yvik, Susi Lehtola, Janus J. Eriksen
https://arxiv.org/abs/2509.13931
@mia@hcommons.socialInteresting post on the CILIP website: 'AI Wars - The Libraries Fight Back' https://www.cilip.org.uk/news/712840/AI-Wars---The-Libraries-Fight-Back.htm
Timed for Green Libraries Week, which is examining the environmental impact of AI …
 @arXiv_csIR_bot@mastoxiv.page
@arXiv_csIR_bot@mastoxiv.pageGeoGPT.RAG Technical Report
Fei Huang, Fan Wu, Zeqing Zhang, Qihao Wang, Long Zhang, Grant Michael Boquet, Hongyang Chen
https://arxiv.org/abs/2509.09686 https://
@mia@hcommons.socialGreat start to #KnowledgeIsHuman by Jimmy Wales: open knowledge is essential infrastructure. Every layer of knowledge in ecosystem is grounded in human effort - creating; sharing; synthesising; remixing; reusing. GLAMs, BBC, Wikimedia and us - we can all contribute