 @heiseonline@social.heise.de
@heiseonline@social.heise.de2025-10-14 05:21:00
@heiseonline@social.heise.de @cdarwin@c.im
@cdarwin@c.imAI startup Perplexity is crawling and scraping content from websites that have explicitly indicated they don’t want to be scraped, according to internet infrastructure provider Cloudflare.
On Monday, Cloudflare published research saying it observed the AI startup ignore blocks and hide its crawling and scraping activities.
The network infrastructure giant accused Perplexity of obscuring its identity when trying to scrape web pages “in an attempt to circumvent the website’s prefe…
 @Techmeme@techhub.social
@Techmeme@techhub.socialReddit says it will block the Internet Archive from indexing most of its pages after it caught AI companies scraping its data from the Wayback Machine (Jay Peters/The Verge)
https://www.theverge.com/news/757538/reddit-internet-archive-wayback-machine-…
 @Mediagazer@mstdn.social
@Mediagazer@mstdn.socialReddit says it will block the Internet Archive from indexing most of its pages after it caught AI companies scraping its data from the Wayback Machine (Jay Peters/The Verge)
https://www.theverge.com/news/757538/reddit-internet-archive-wayback-machine-…
@cdarwin@c.imReddit says that it has caught AI companies scraping its data from the Internet Archive’s Wayback Machine,
-- and it’s going to start blocking the Internet Archive from indexing the vast majority of Reddit.
The Wayback Machine will no longer be able to crawl post detail pages, comments, or profiles;
instead, it will only be able to index the Reddit.com homepage,
which effectively means Internet Archive will only be able to archive insights into which news headlines …
@Techmeme@techhub.socialLinkedIn sues a company called ProAPIs for allegedly operating millions of fake accounts to scrape LinkedIn member data and selling it for ~$15,000 per month (Suzanne Smalley/The Record)
https://therecord.media/linkedin-sues-data-scraping-company
 @philip@mastodon.mallegolhansen.com
@philip@mastodon.mallegolhansen.com@… *If* scrapers would actually follow the spec, I’m somewhat for it. It *does* allow for you to insert a custom license that says “No scraping, under any circumstances”.
But would any scraper actually follow it? Of course not.
 @newsie@darktundra.xyz
@newsie@darktundra.xyzLinkedIn sues software company allegedly scraping data from millions of profiles https://therecord.media/linkedin-sues-data-scraping-company
 @fgraver@hcommons.social
@fgraver@hcommons.socialPay-per-output? AI firms blindsided by beefed up robots.txt instructions. https://arstechnica.com/tech-policy/2025/09/pay-per-output-ai-firms-blindsided-by-beefed-up-robots-txt-instructions/
 @johnleonard@mastodon.social
@johnleonard@mastodon.socialA review of the legal challenges associated with generative AI training disputes emphasises the need for clarity from the UK government, legislature and courts.
https://www.computing.co.uk/feature/2025/scraping-surface-generative-ai-training-disputes…
 @Stomata@social.linux.pizza
@Stomata@social.linux.pizzaAccording to Dropsitenews Meta is training AI on multiple Lemmy instances. I also saw some mastodon instance in the PDF.
Full article https://www.dropsitenews.com/p/meta-facebook-tech-copyright-privacy-whistleblower
Full list:
 @gedankenstuecke@scholar.social
@gedankenstuecke@scholar.social«Google quietly vanishes its net zero carbon pledge»
Of course, gotta spend all the energy scraping the web to death and using that for training some "AI" that advises people to kill themselves. The Butlerian Jihad truly can't come fast enough…
https://pivot-to-ai.com/2025/09/05/google-quietly-vanishes-its-net-zero-carbon-commitment/
@Mediagazer@mstdn.socialReddit, Yahoo, Medium, Quora, People, O'Reilly, wikiHow, Ziff Davis, and others adopt the Really Simple Licensing (RSL) Standard to set terms for AI scraping (Emma Roth/The Verge)
https://www.theverge.com/news/775072/rsl-standard-licensing-ai…
@Techmeme@techhub.socialReddit, Yahoo, Medium, Quora, People, O'Reilly, wikiHow, Ziff Davis, and others adopt the Really Simple Licensing (RSL) Standard to set terms for AI scraping (Emma Roth/The Verge)
https://www.theverge.com/news/775072/rsl-standard-licensing-ai…
 @toxi@mastodon.thi.ng
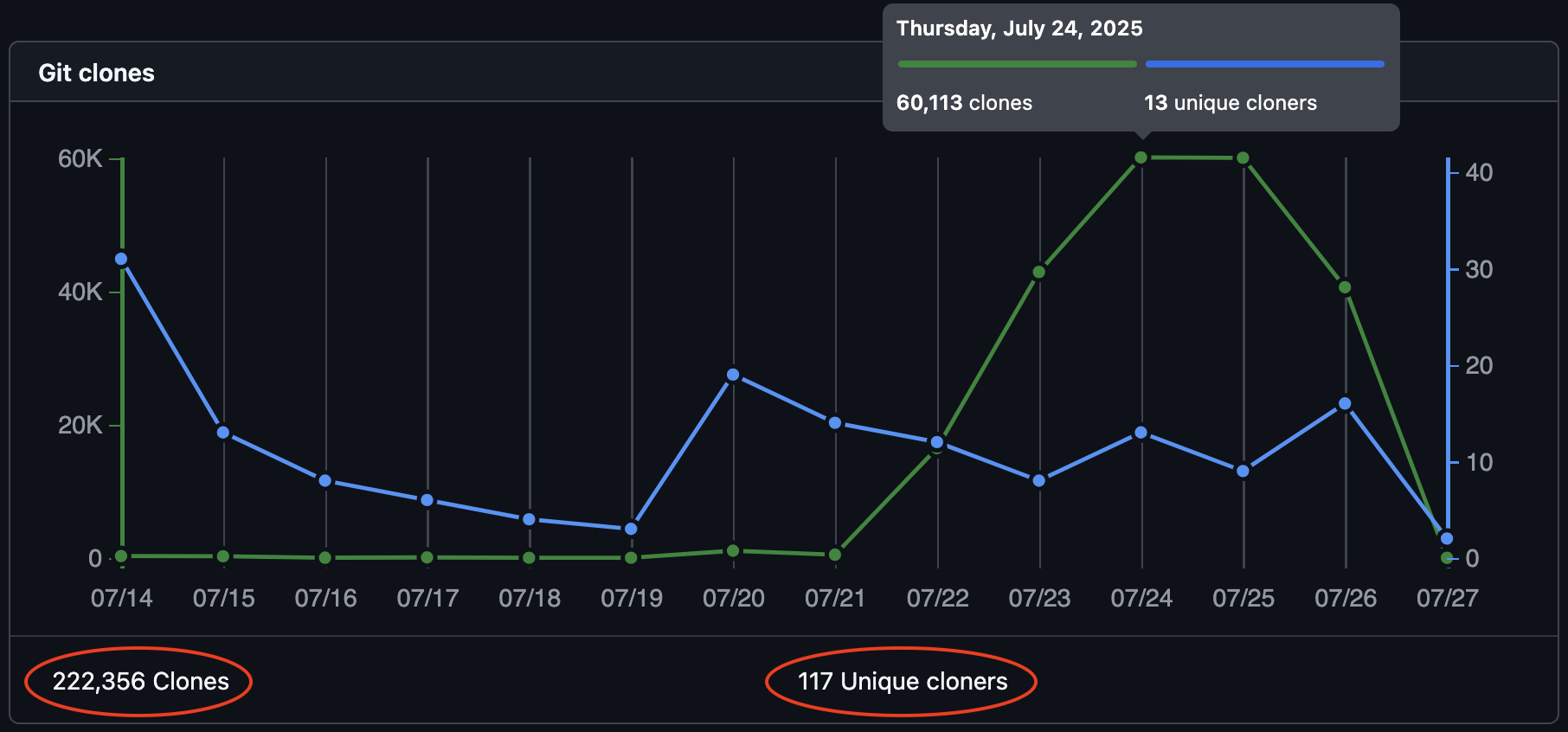
@toxi@mastodon.thi.ngAnyone else getting these ridiculous repo scraping spikes? A clean checkout of the https://thi.ng/umbrella monorepo is ~370MB. Over the past 14 days there were 222k clones (only 117 unique) of this repo which have caused downloads of a whopping ~78TB. WTF! 🤯
 @metacurity@infosec.exchange
@metacurity@infosec.exchangeMetacurity is pleased to offer our free and premium subscribers a weekly digest of the best long-form (and longish) infosec-related pieces we couldn't properly fit into our daily news crush.
This week's selection covers
--How an NYT reporter almost fell for a scam,
--Hackers increasingly take aim at small-town water systems,
--Citizens must shift their threat models under Trump's regime,
--Even the most innocent AI model can spew out dark material,
@gedankenstuecke@scholar.socialSpent the evening improving my #RSS setup by getting more into the possibilities of https://www.freshrss.org/:
Thanks to its support for web scraping, I've now managed to get the full text of articles, instead of just the snippets, of @… en español into my reader.
And even managed to get BBC Mundo scraped into it through the scraping, despite @… unfortunately not providing any official feeds for the Spanish-language news at all.
 @arXiv_csAI_bot@mastoxiv.page
@arXiv_csAI_bot@mastoxiv.pageThrottling Web Agents Using Reasoning Gates
Abhinav Kumar, Jaechul Roh, Ali Naseh, Amir Houmansadr, Eugene Bagdasarian
https://arxiv.org/abs/2509.01619 https://
 @alejandrobdn@social.linux.pizza
@alejandrobdn@social.linux.pizzaFor anyone who wants to self-host their catalog of book video game or movie collections, Koillection is a good open-source option.
It can also be installed using Docker, which can speed up the setup process.
I've only been using this tool for a couple of days, and it looks promising. The only thing that doesn't seem very intuitive at the moment is the scraping system, although its developer has commented on GitHub that they are working on it.
 @adulau@infosec.exchange
@adulau@infosec.exchangeWe are excited to announce the release of Vulnerability-Lookup 2.15.0!
This version brings new features, performance improvements, and several bug fixes.
Thanks to @… for the hard work.
#vulnerability
 @tgpo@social.linux.pizza
@tgpo@social.linux.pizzaPainting and ceiling scraping is finally done!
Now I can set my office back up and get back into the swing of things.
But first, I must clean every single thing I own because it's all covered in a think layer of white dust 😐
 @arXiv_csCY_bot@mastoxiv.page
@arXiv_csCY_bot@mastoxiv.pageBubble, Bubble, AI's Rumble: Why Global Financial Regulatory Incident Reporting is Our Shield Against Systemic Stumbles
Anchal Gupta, Gleb Pappyshev, James T Kwok
https://arxiv.org/abs/2509.26150
 @arXiv_csRO_bot@mastoxiv.page
@arXiv_csRO_bot@mastoxiv.pageLanternNet: A Novel Hub-and-Spoke System to Seek and Suppress Spotted Lanternfly Populations
Vinil Polepalli
https://arxiv.org/abs/2507.20800 https://arxiv…
 @trezzer@social.linux.pizza
@trezzer@social.linux.pizzaI think I want to try a ZX Spectrum Next setup on MiSTer to see if I should get the Kickstarter hardware. Does anyone know of any packs that combine the free/demo Next software so I don’t have to spend hours scraping it from various places on the net? I have found packs of the classic Spectrum software.
 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.pageUPRPRC: Unified Pipeline for Reproducing Parallel Resources -- Corpus from the United Nations
Qiuyang Lu, Fangjian Shen, Zhengkai Tang, Qiang Liu, Hexuan Cheng, Hui Liu, Wushao Wen
https://arxiv.org/abs/2509.15789
 @arXiv_csHC_bot@mastoxiv.page
@arXiv_csHC_bot@mastoxiv.pageTides of Memory: Digital Echoes of Netizen Remembran
Lingyu Peng, Chang Ge, Liying Long, Xin Li, Xiao Hu, Pengda Lu, Qingchuan Li, Jiangyue Wu
https://arxiv.org/abs/2509.16579 h…
@gedankenstuecke@scholar.socialI've blogged about how I'm using #FreshRSS to get full-text #RSS feeds – and about crowdsourcing configs that will allow folks to subscribe to more things thanks to the web scraping feature!
https://tzovar.as/fulltext-freshrss/
(Responses to this toot will also become blog comments)
 @arXiv_csSD_bot@mastoxiv.page
@arXiv_csSD_bot@mastoxiv.pageOn the de-duplication of the Lakh MIDI dataset
Eunjin Choi, Hyerin Kim, Jiwoo Ryu, Juhan Nam, Dasaem Jeong
https://arxiv.org/abs/2509.16662 https://arxiv.o…
@arXiv_csAI_bot@mastoxiv.pageRISK: A Framework for GUI Agents in E-commerce Risk Management
Renqi Chen, Zeyin Tao, Jianming Guo, Jingzhe Zhu, Yiheng Peng, Qingqing Sun, Tianyi Zhang, Shuai Chen
https://arxiv.org/abs/2509.21982
@Techmeme@techhub.socialWhile facial recognition tech remains unregulated at the US federal level, 23 states have passed or expanded laws to restrict mass scraping of biometric data (Bobby Allyn/NPR)
https://www.npr.org/2025/08/28/nx-s1-5519756/biometrics-facial-recognition-l…
 @arXiv_csSI_bot@mastoxiv.page
@arXiv_csSI_bot@mastoxiv.pagePoliTok-DE: A Multimodal Dataset of Political TikToks and Deletions From Germany
Tomas Ruiz, Andreas Nanz, Ursula Kristin Schmid, Carsten Schwemmer, Yannis Theocharis, Diana Rieger
https://arxiv.org/abs/2509.15860
@newsie@darktundra.xyzPodcast: Landlords Demand Your Workplace Logins to Scrape Paystubs https://www.404media.co/podcast-landlords-demand-your-workplace-logins-to-scrape-paystubs/


















