@aardrian@toot.cafe
@aardrian@toot.cafe2025-11-15 15:57:15
Ana Tudor rolling into the comments with corrections and useful #CSS values context (trousers!):
https://css-tricks.com/headings-semantics-fluidity-and-styling-oh-my/#…
@aardrian@toot.cafeAna Tudor rolling into the comments with corrections and useful #CSS values context (trousers!):
https://css-tricks.com/headings-semantics-fluidity-and-styling-oh-my/#…
 @arXiv_csPL_bot@mastoxiv.page
@arXiv_csPL_bot@mastoxiv.pageOperational methods in semantics
Roberto M. Amadio
https://arxiv.org/abs/2510.12295 https://arxiv.org/pdf/2510.12295
 @arXiv_csIR_bot@mastoxiv.page
@arXiv_csIR_bot@mastoxiv.pageLeveraging Language Semantics for Collaborative Filtering with TextGCN and TextGCN-MLP: Zero-Shot vs In-Domain Performance
Andrei Chernov, Haroon Wahab, Oleg Novitskij
https://arxiv.org/abs/2510.12461 …
 @tschfflr@fediscience.org
@tschfflr@fediscience.orgInternational postdocs: Come to Bochum for a two-week stay to plan a research project and learn how to apply for funding for it in Germany.
I'm available as a host for any topic related to my research interests: digital forensic linguistics, experimental semantics/pragmatics, emojis, (computational analyses of) harmful language, metaphors, discourse, etc.
https://www.research-academy-ruhr.de/programm/researchexplorer/
 @cyrevolt@mastodon.social
@cyrevolt@mastodon.social @arXiv_csLG_bot@mastoxiv.page
@arXiv_csLG_bot@mastoxiv.pageKoALA: KL-L0 Adversarial Detector via Label Agreement
Siqi Li, Yasser Shoukry
https://arxiv.org/abs/2510.12752 https://arxiv.org/pdf/2510.12752
 @arXiv_csLO_bot@mastoxiv.page
@arXiv_csLO_bot@mastoxiv.pageCrosslisted article(s) found for cs.LO. https://arxiv.org/list/cs.LO/new
[1/1]:
- Operational methods in semantics
Roberto M. Amadio
https://
 @arXiv_csCV_bot@mastoxiv.page
@arXiv_csCV_bot@mastoxiv.pageAdvancing End-to-End Pixel Space Generative Modeling via Self-supervised Pre-training
Jiachen Lei, Keli Liu, Julius Berner, Haiming Yu, Hongkai Zheng, Jiahong Wu, Xiangxiang Chu
https://arxiv.org/abs/2510.12586
 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.pagePRoH: Dynamic Planning and Reasoning over Knowledge Hypergraphs for Retrieval-Augmented Generation
Xiangjun Zai, Xingyu Tan, Xiaoyang Wang, Qing Liu, Xiwei Xu, Wenjie Zhang
https://arxiv.org/abs/2510.12434
 @arXiv_csGR_bot@mastoxiv.page
@arXiv_csGR_bot@mastoxiv.pageCan Representation Gaps Be the Key to Enhancing Robustness in Graph-Text Alignment?
Heng Zhang, Tianyi Zhang, Yuling Shi, Xiaodong Gu, Yaomin Shen, Zijian Zhang, Yilei Yuan, Hao Zhang, Jin Huang
https://arxiv.org/abs/2510.12087
@arXiv_csCV_bot@mastoxiv.pageData or Language Supervision: What Makes CLIP Better than DINO?
Yiming Liu, Yuhui Zhang, Dhruba Ghosh, Ludwig Schmidt, Serena Yeung-Levy
https://arxiv.org/abs/2510.11835 https:/…
 @lysander07@sigmoid.social
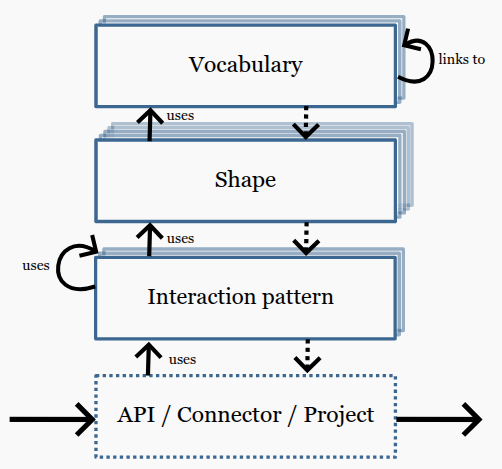
@lysander07@sigmoid.socialWe are happy to welcome @… from RWTH in today's #nfdicore playground talking about "Bridging the Gap from Biomedical to Domain-Agnostic Semantics".
Besides others, he is demonstrating that our
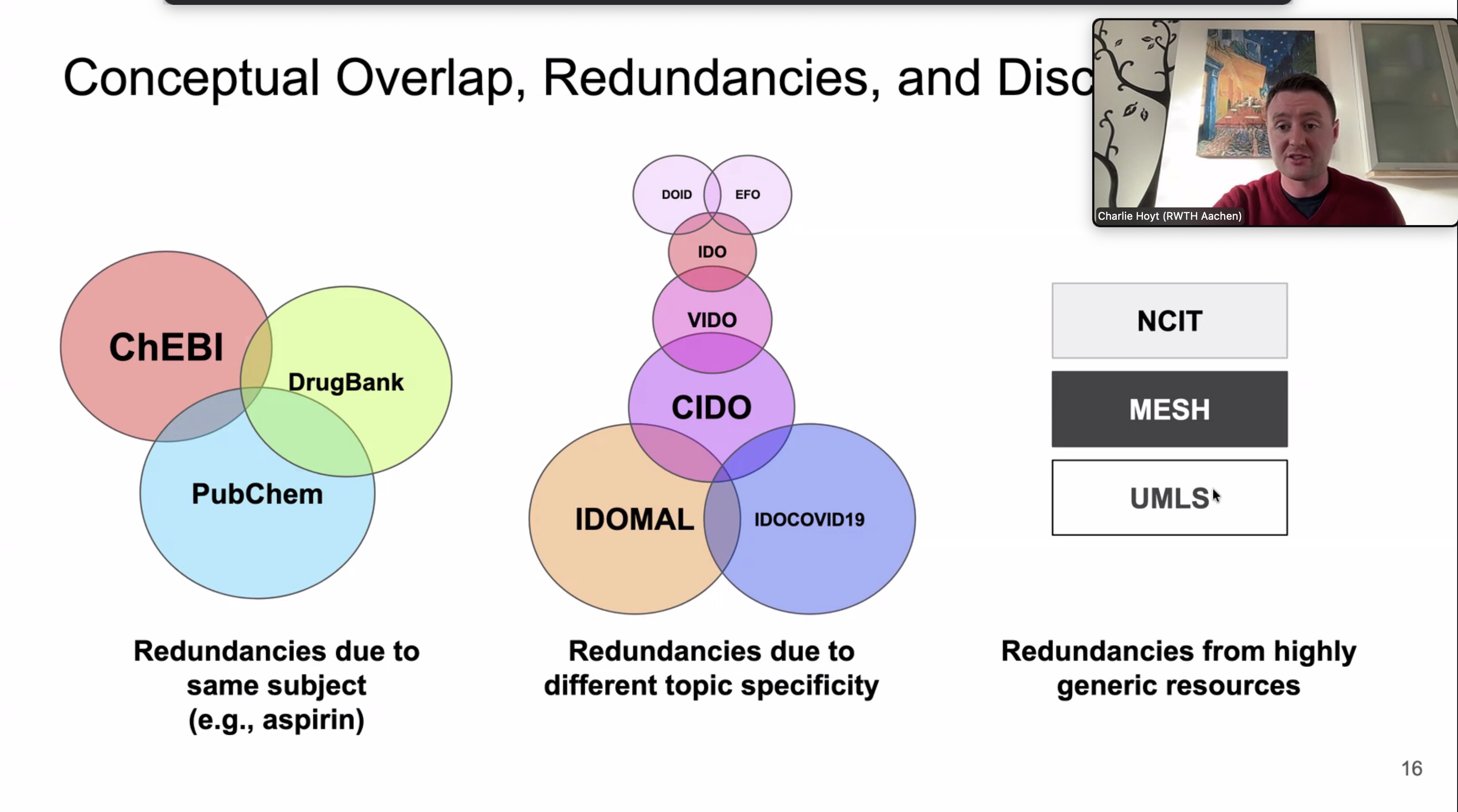
 @mia@hcommons.social
@mia@hcommons.socialI wasn't surprised to see Rob Sanderson quoted in this, because rich vs aligned semantics - specifically , wanting both at the same time - is *such* a cultural heritage data interoperability problem #MuseTech
From: @…
 @Adam@social.lein.us
@Adam@social.lein.usA cool open source UI component library, but a lot of them I looked at don't have good semantics or accessibility compliance. #webdevelopment
 @vrandecic@mas.to
@vrandecic@mas.toOpenAI and Perplexity, armed with significant AI capabilities, have targeted the shopping domain. And have run into many problems around data access and semantics.
This raises three thoughts:
First, companies which are bullish about AI “changing everything”, are stumbling in maybe the most traditional, mundane domain: shopping. This doesn’t inspire confidence in their technology.
1/5
#ai
@Adam@social.lein.usA cool open source UI component library, but a lot of them I looked at don't have good semantics or accessibility compliance. #webdevelopment
 @seeingwithsound@mas.to
@seeingwithsound@mas.toBrain-aligning of semantic vectors improves neural decoding of visual stimuli #BCI
 @cdarwin@c.im
@cdarwin@c.imSyntax is not Semantics
Language is not the same as intelligence.
The entire AI bubble is built on ignoring that.
https://www.theverge.com/ai-artificial-intelligence/827820/large-language-models-ai-intellige…
 @arXiv_qbioNC_bot@mastoxiv.page
@arXiv_qbioNC_bot@mastoxiv.pageRevised comment on the paper titled "The Origin of Quantum Mechanical Statistics: Insights from Research on Human Language
Miko{\l}aj Sienicki, Krzysztof Sienicki
https://arxiv.org/abs/2512.07881 https://arxiv.org/pdf/2512.07881 https://arxiv.org/html/2512.07881
arXiv:2512.07881v1 Announce Type: new
Abstract: This short note comments on \citet{Aerts2024Origin}, which proposes that ranked word frequencies in texts should be read through the lens of Bose--Einstein (BE) statistics and even used to illuminate the origin of quantum statistics in physics. The core message here is modest: the paper offers an interesting analogy and an eye-catching fit, but several key steps mix physical claims with definitions and curve-fitting choices. We highlight three such points: (i) a normalization issue that is presented as "bosonic enhancement", (ii) an identification of rank with energy that makes the BE fit only weakly diagnostic of an underlying mechanism, and (iii) a baseline comparison that is too weak to support an ontological conclusion. We also briefly flag a few additional concerns (interpretation drift, parameter semantics, and reproducibility).
toXiv_bot_toot
 @Jyoti@mas.to @aardrian@toot.cafe
@Jyoti@mas.to @aardrian@toot.cafeScott helpfully reminds us of the differences between technical purity, semantics, and what actually matters to users in the context of — yes, really — paragraphs:
https://www.scottohara.me/blog/2024/08/29/paragraphs.html
@tschfflr@fediscience.org🚨 Yesterday, I received official notification that our #emoji project EmDiCom is being funded for another three years! 🥳
I'm looking forward to a lot more 🤩 emoji research 🤩 together with Patrick Grosz and Lea Fricke! #linguistics #dfg #vicom @… https://vicom.info/projects/semantics-and-pragmatics-of-emojis-in-digital-communication/