@arXiv_csCV_bot@mastoxiv.page
@arXiv_csCV_bot@mastoxiv.page2025-08-19 12:08:10
Precise Action-to-Video Generation Through Visual Action Prompts
Yuang Wang, Chao Wen, Haoyu Guo, Sida Peng, Minghan Qin, Hujun Bao, Xiaowei Zhou, Ruizhen Hu
https://arxiv.org/abs/2508.13104
@arXiv_csCV_bot@mastoxiv.pagePrecise Action-to-Video Generation Through Visual Action Prompts
Yuang Wang, Chao Wen, Haoyu Guo, Sida Peng, Minghan Qin, Hujun Bao, Xiaowei Zhou, Ruizhen Hu
https://arxiv.org/abs/2508.13104
 @arXiv_csHC_bot@mastoxiv.page
@arXiv_csHC_bot@mastoxiv.pageUMind: A Unified Multitask Network for Zero-Shot M/EEG Visual Decoding
Chengjian Xu, Yonghao Song, Zelin Liao, Haochuan Zhang, Qiong Wang, Qingqing Zheng
https://arxiv.org/abs/2509.14772
 @seeingwithsound@mas.to
@seeingwithsound@mas.to(2024) Visual neuroprostheses for impaired human nervous system: State-of-the-art and future outlook #BCI
 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.pageV-SEAM: Visual Semantic Editing and Attention Modulating for Causal Interpretability of Vision-Language Models
Qidong Wang, Junjie Hu, Ming Jiang
https://arxiv.org/abs/2509.14837
 @UP8@mastodon.social
@UP8@mastodon.social⏱️ Researchers discover how the human brain organizes its visual memories through precise neural timing
https://medicalxpress.com/news/2025-07-human-brain-visual-memories-precise.html
 @arXiv_csSD_bot@mastoxiv.page
@arXiv_csSD_bot@mastoxiv.pageFrom Hype to Insight: Rethinking Large Language Model Integration in Visual Speech Recognition
Rishabh Jain, Naomi Harte
https://arxiv.org/abs/2509.14880 https://
 @arXiv_qbioNC_bot@mastoxiv.page
@arXiv_qbioNC_bot@mastoxiv.pageMouse vs. AI: A Neuroethological Benchmark for Visual Robustness and Neural Alignment
Marius Schneider, Joe Canzano, Jing Peng, Yuchen Hou, Spencer LaVere Smith, Michael Beyeler
https://arxiv.org/abs/2509.14446
 @Techmeme@techhub.social
@Techmeme@techhub.socialMicrosoft adds auto model selection to Visual Studio Code that primarily favors Claude Sonnet 4 over GPT-5 for paid GitHub Copilot users (Tom Warren/The Verge)
https://www.theverge.com/report/778641/microsoft-visual-studio-code-anthropic-claude-4…
 @ErikJonker@mastodon.social
@ErikJonker@mastodon.socialQwen-Image-Edit: Image Editing with Higher Quality and Efficiency
https://qwenlm.github.io/blog/qwen-image-edit/?utm_source=www.the…
 @arXiv_csRO_bot@mastoxiv.page
@arXiv_csRO_bot@mastoxiv.pageBEV-ODOM2: Enhanced BEV-based Monocular Visual Odometry with PV-BEV Fusion and Dense Flow Supervision for Ground Robots
Yufei Wei, Wangtao Lu, Sha Lu, Chenxiao Hu, Fuzhang Han, Rong Xiong, Yue Wang
https://arxiv.org/abs/2509.14636
 @laurentperrinet@neuromatch.social
@laurentperrinet@neuromatch.social🧠 Excited to share our latest research presented at #CNS2025 in beautiful Firenze, Italy!
"Population decoding of visual motion direction in V1 marmoset monkey: effects of uncertainty"
Our work explores how populations of neurons in the primary visual cortex (V1) of marmoset monkeys encode visual motion direction, with a particular focus on understanding how uncertainty influences…
 @Migurski@mastodon.social
@Migurski@mastodon.socialVisual aid for Boeing Power-Sat presentation, 1975 Via https://70sscifiart.tumblr.com/post/791791976739700736/visual-aid-for-boeing-power-sat-presentation-1975

 @arXiv_eessIV_bot@mastoxiv.page
@arXiv_eessIV_bot@mastoxiv.pageAutomated Cervical Cancer Detection through Visual Inspection with Acetic Acid in Resource-Poor Settings with Lightweight Deep Learning Models Deployed on an Android Device
Leander Melroy Maben, Keerthana Prasad, Shyamala Guruvare, Vidya Kudva, P C Siddalingaswamy
https://arxiv.org/abs/2508.13253
 @poppastring@dotnet.social
@poppastring@dotnet.socialA post from the archive 📫:
Using Visual Studio to search objects in a memory dump
https://www.poppastring.com/blog/using-visual-studio-to-search-objects-in-a-memory-dump
 @arXiv_csCR_bot@mastoxiv.page
@arXiv_csCR_bot@mastoxiv.pageUnlearning Comparator: A Visual Analytics System for Comparative Evaluation of Machine Unlearning Methods
Jaeung Lee, Suhyeon Yu, Yurim Jang, Simon S. Woo, Jaemin Jo
https://arxiv.org/abs/2508.12730
@seeingwithsound@mas.to(LinkedIn) Revision Implant is despite its name already quickly looking for markets beyond visual prostheses https://www.linkedin.com/posts/revision-implant-nv_elmedix-medicalinnovation-oncology-activity-7363137424329252864-bp…
@arXiv_csHC_bot@mastoxiv.pageSensing the Shape of Data: Non-Visual Exploration of Statistical Concepts in Histograms with Blind and Low-Vision Learners
Sanchita S. Kamath, Omar Khan, Aziz N Zeidieh, JooYoung Seo
https://arxiv.org/abs/2509.14452
@arXiv_csCV_bot@mastoxiv.pageLeveraging Geometric Visual Illusions as Perceptual Inductive Biases for Vision Models
Haobo Yang, Minghao Guo, Dequan Yang, Wenyu Wang
https://arxiv.org/abs/2509.15156 https://…
@arXiv_csCL_bot@mastoxiv.pageAdaDocVQA: Adaptive Framework for Long Document Visual Question Answering in Low-Resource Settings
Haoxuan Li, Wei Song, Aofan Liu, Peiwu Qin
https://arxiv.org/abs/2508.13606 ht…
 @arXiv_eessAS_bot@mastoxiv.page
@arXiv_eessAS_bot@mastoxiv.pageDiffusion-Based Unsupervised Audio-Visual Speech Separation in Noisy Environments with Noise Prior
Yochai Yemini, Rami Ben-Ari, Sharon Gannot, Ethan Fetaya
https://arxiv.org/abs/2509.14379
 @arXiv_eessSY_bot@mastoxiv.page
@arXiv_eessSY_bot@mastoxiv.pageModel-based Multi-object Visual Tracking: Identification and Standard Model Limitations
Jan Krej\v{c}\'i, Oliver Kost, Yuxuan Xia, Lennart Svensson, Ond\v{r}ej Straka
https://arxiv.org/abs/2508.13647
 @fanf@mendeddrum.org
@fanf@mendeddrum.orgfrom my link log —
Game math: precise control over numeric springing.
https://allenchou.net/2015/04/game-math-precise-control-over-numeric-springing/
saved 2025-05-21
@arXiv_csSD_bot@mastoxiv.pageLeveraging Mamba with Full-Face Vision for Audio-Visual Speech Enhancement
Rong Chao, Wenze Ren, You-Jin Li, Kuo-Hsuan Hung, Sung-Feng Huang, Szu-Wei Fu, Wen-Huang Cheng, Yu Tsao
https://arxiv.org/abs/2508.13624
 @arXiv_condmatsoft_bot@mastoxiv.page
@arXiv_condmatsoft_bot@mastoxiv.pageLarge-scale dynamics in visual quorum sensing chiral suspensions
Yuxin Zhou, Qingqing Yin, Shubhadip Nayak, Poulami Bag, Pulak K. Ghosh, Yunyun Li, Fabio Marchesoni
https://arxiv.org/abs/2508.11254
 @blakes7bot@mas.torpidity.net
@blakes7bot@mas.torpidity.netSeries C, Episode 07 - Children of Auron
C.A. ONE: For what reason?
FRANTON: Conquest.
C.A. ONE: That's ridiculous.
FRANTON: Surely it would be safer to wait for the Liberator. At least we can trust them, and we know they're coming, Zelda heard.
https://blake.torpidity.net/m/307/223

 @arXiv_csSE_bot@mastoxiv.page
@arXiv_csSE_bot@mastoxiv.pageVisDocSketcher: Towards Scalable Visual Documentation with Agentic Systems
Lu\'is F. Gomes, Xin Zhou, David Lo, Rui Abreu
https://arxiv.org/abs/2509.11942 https://
@arXiv_csRO_bot@mastoxiv.pageASC-SW: Atrous strip convolution network with sliding windows for visual-assisted map navigation
Cheng Liu, Fan Zhu, Yaoyu Zhuang Zhinan Chen Jiefeng Tang
https://arxiv.org/abs/2507.12744
@arXiv_csCV_bot@mastoxiv.pageOmni Survey for Multimodality Analysis in Visual Object Tracking
Zhangyong Tang, Tianyang Xu, Xuefeng Zhu, Hui Li, Shaochuan Zhao, Tao Zhou, Chunyang Cheng, Xiaojun Wu, Josef Kittler
https://arxiv.org/abs/2508.13000
@seeingwithsound@mas.toNeuralink for visual prosthesis #Neuralink
 @arXiv_csIR_bot@mastoxiv.page
@arXiv_csIR_bot@mastoxiv.pageDeveloping Visual Augmented Q&A System using Scalable Vision Embedding Retrieval & Late Interaction Re-ranker
Rachna Saxena, Abhijeet Kumar, Suresh Shanmugam
https://arxiv.org/abs/2507.12378
 @arXiv_csAI_bot@mastoxiv.page
@arXiv_csAI_bot@mastoxiv.pageEGOILLUSION: Benchmarking Hallucinations in Egocentric Video Understanding
Ashish Seth, Utkarsh Tyagi, Ramaneswaran Selvakumar, Nishit Anand, Sonal Kumar, Sreyan Ghosh, Ramani Duraiswami, Chirag Agarwal, Dinesh Manocha
https://arxiv.org/abs/2508.12687
@Techmeme@techhub.socialGoogle's new AI features for Pixel include Magic Cue for contextual suggestions across apps, Voice Translate for calls, and Visual Overlays for the camera (Sarah Perez/TechCrunch)
https://techcrunch.com/2025/08/20/google-doubles-down-on-ai-pho…
 @leftsidestory@mstdn.social
@leftsidestory@mstdn.socialOn The Road - To Xi’An/ Geometry 📐
在路上 - 去西安/ 几何 📐
📷 Pentax MX
🎞️Fujifilm Neopan F, expired 1993
#filmphotography #Photography #blackandwhite


 @arXiv_csCV_bot@mastoxiv.page
@arXiv_csCV_bot@mastoxiv.pageVisionLaw: Inferring Interpretable Intrinsic Dynamics from Visual Observations via Bilevel Optimization
Jailing Lin, Shu Jiang, Qingyuan Zeng, Zhenzhong Wang, Min Jiang
https://arxiv.org/abs/2508.13792
@arXiv_csHC_bot@mastoxiv.pagePy maidr: Bridging Visual and Non-Visual Data Experiences Through a Unified Python Framework
JooYoung Seo, Saairam Venkatesh, Daksh Pokar, Sanchita Kamath, Krishna Anandan Ganesan
https://arxiv.org/abs/2509.13532
@arXiv_csSD_bot@mastoxiv.pageCross-Modal Knowledge Distillation with Multi-Level Data Augmentation for Low-Resource Audio-Visual Sound Event Localization and Detection
Qing Wang, Ya Jiang, Hang Chen, Sabato Marco Siniscalchi, Jun Du, Jianqing Gao
https://arxiv.org/abs/2508.12334
@arXiv_csCL_bot@mastoxiv.pageDataset Creation for Visual Entailment using Generative AI
Rob Reijtenbach, Suzan Verberne, Gijs Wijnholds
https://arxiv.org/abs/2508.11605 https://arxiv.o…
@seeingwithsound@mas.toOptimizing electrical stimulation parameters to enhance visual cortex activation in retina degeneration rats #BCI
@arXiv_csRO_bot@mastoxiv.pageLearning Discrete Abstractions for Visual Rearrangement Tasks Using Vision-Guided Graph Coloring
Abhiroop Ajith, Constantinos Chamzas
https://arxiv.org/abs/2509.14460 https://…
@arXiv_csCV_bot@mastoxiv.pageUnsupervised Urban Tree Biodiversity Mapping from Street-Level Imagery Using Spatially-Aware Visual Clustering
Diaa Addeen Abuhani, Marco Seccaroni, Martina Mazzarello, Imran Zualkernan, Fabio Duarte, Carlo Ratti
https://arxiv.org/abs/2508.13814
@Techmeme@techhub.socialGoogle unveils the $999 Pixel 10 Pro and $1,199 10 Pro XL, with 6.3" and 6.8" OLED displays, Tensor G5 chips, Zoned UFS storage, available on August 28 (Ben Schoon/9to5Google)
https://9to5google.com/2025/08/20/google-pixel-10-pro-xl-seri…
@arXiv_qbioNC_bot@mastoxiv.pageSynchronization and semantization in deep spiking networks
Jonas Oberste-Frielinghaus, Anno C. Kurth, Julian G\"oltz, Laura Kriener, Junji Ito, Mihai A. Petrovici, Sonja Gr\"un
https://arxiv.org/abs/2508.12975
@arXiv_csSD_bot@mastoxiv.pageTemporally Heterogeneous Graph Contrastive Learning for Multimodal Acoustic event Classification
Yuanjian Chen, Yang Xiao, Jinjie Huang
https://arxiv.org/abs/2509.14893 https://…
@arXiv_csAI_bot@mastoxiv.pageCrosslisted article(s) found for cs.AI. https://arxiv.org/list/cs.AI/new
[4/6]:
- End-to-End Audio-Visual Learning for Cochlear Implant Sound Coding in Noisy Environments
Meng-Ping Lin, Enoch Hsin-Ho Huang, Shao-Yi Chien, Yu Tsao
@poppastring@dotnet.socialJust published 🚀: Visual Studio Insiders
#visualstudio
@arXiv_csRO_bot@mastoxiv.pageManipulate-to-Navigate: Reinforcement Learning with Visual Affordances and Manipulability Priors
Yuying Zhang, Joni Pajarinen
https://arxiv.org/abs/2508.13151 https://
@arXiv_csHC_bot@mastoxiv.pagefCrit: A Visual Explanation System for Furniture Design Creative Support
Vuong Nguyen, Gabriel Vigliensoni
https://arxiv.org/abs/2508.12416 https://arxiv.o…
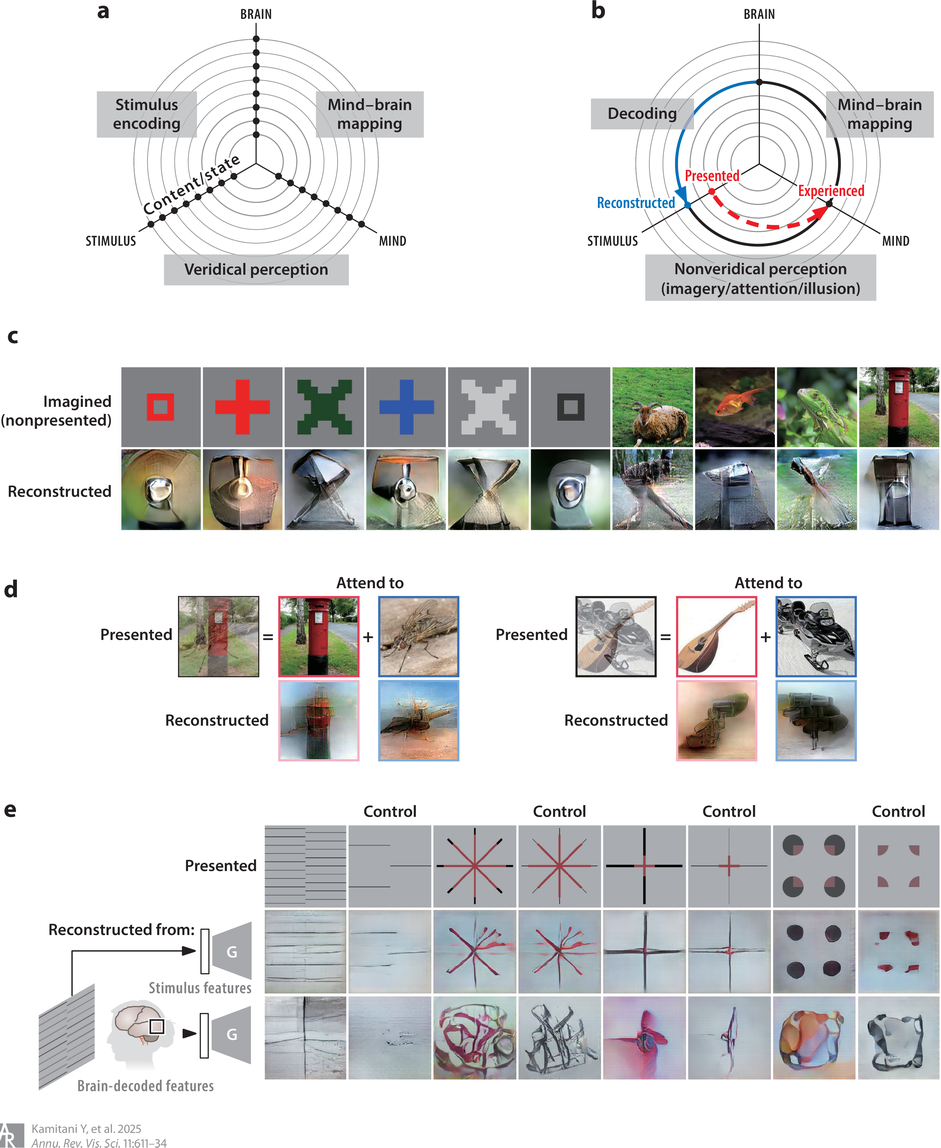
@seeingwithsound@mas.toVisual image reconstruction from brain activity via latent representation https://www.annualreviews.org/content/journals/10.1146/annurev-vision-110423-023616 by @…
 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.pageMulti-Agent Synergy-Driven Iterative Visual Narrative Synthesis
Wang Xi, Quan Shi, Tian Yu, Yujie Peng, Jiayi Sun, Mengxing Ren, Zenghui Ding, Ningguang Yao
https://arxiv.org/abs/2507.13285
@arXiv_csHC_bot@mastoxiv.pageVisMoDAl: Visual Analytics for Evaluating and Improving Corruption Robustness of Vision-Language Models
Huanchen Wang, Wencheng Zhang, Zhiqiang Wang, Zhicong Lu, Yuxin Ma
https://arxiv.org/abs/2509.14571
@arXiv_csRO_bot@mastoxiv.pageVisual Perception Engine: Fast and Flexible Multi-Head Inference for Robotic Vision Tasks
Jakub {\L}ucki, Jonathan Becktor, Georgios Georgakis, Robert Royce, Shehryar Khattak
https://arxiv.org/abs/2508.11584
@arXiv_csCV_bot@mastoxiv.pageLeveraging Pre-Trained Visual Models for AI-Generated Video Detection
Keerthi Veeramachaneni, Praveen Tirupattur, Amrit Singh Bedi, Mubarak Shah
https://arxiv.org/abs/2507.13224
@arXiv_csAI_bot@mastoxiv.pageV2P: From Background Suppression to Center Peaking for Robust GUI Grounding Task
Jikai Chen, Long Chen, Dong Wang, Leilei Gan, Chenyi Zhuang, Jinjie Gu
https://arxiv.org/abs/2508.13634
@arXiv_csCV_bot@mastoxiv.pageTeacher-Guided Pseudo Supervision and Cross-Modal Alignment for Audio-Visual Video Parsing
Yaru Chen, Ruohao Guo, Liting Gao, Yang Xiang, Qingyu Luo, Zhenbo Li, Wenwu Wang
https://arxiv.org/abs/2509.14097
@arXiv_csRO_bot@mastoxiv.pageFFI-VTR: Lightweight and Robust Visual Teach and Repeat Navigation based on Feature Flow Indicator and Probabilistic Motion Planning
Jikai Wang, Yunqi Cheng, Zonghai Chen
https://arxiv.org/abs/2507.12800
@seeingwithsound@mas.toHow tree shrews see the world - A compressed hierarchy for visual form processing in the tree shrew #neuroscience
@arXiv_csCV_bot@mastoxiv.pageCheckmate: interpretable and explainable RSVQA is the endgame
Lucrezia Tosato, Christel Tartini Chappuis, Syrielle Montariol, Flora Weissgerber, Sylvain Lobry, Devis Tuia
https://arxiv.org/abs/2508.13086
@arXiv_csHC_bot@mastoxiv.pageVisuo-Tactile Feedback with Hand Outline Styles for Modulating Affective Roughness Perception
Minju Baeck, Yoonseok Shin, Dooyoung Kim, Hyunjin Lee, Sang Ho Yoon, Woontack Woo
https://arxiv.org/abs/2508.13504
@Techmeme@techhub.socialMicrosoft releases its first preview of Visual Studio 2026, the first major update since November 2021, with a new look and deeper AI integration (Tim Anderson/The Register)
https://www.theregister.com/2025/09/10/visual_studio_2026_previewed_deeper/
@arXiv_csCV_bot@mastoxiv.pageOpenConstruction: A Systematic Synthesis of Open Visual Datasets for Data-Centric Artificial Intelligence in Construction Monitoring
Ruoxin Xiong, Yanyu Wang, Jiannan Cai, Kaijian Liu, Yuansheng Zhu, Pingbo Tang, Nora El-Gohary
https://arxiv.org/abs/2508.11482
@seeingwithsound@mas.toNeurons and Pixels https://www.neurotechreports.com/pages/publishersletterJul24.html by James Cavuoto on Neuralink Blindsight and the graveyard of commercial failures: Optobionics, Retina Implant, Second Sight, Pixium Vision and others.
@arXiv_csRO_bot@mastoxiv.pageRobust Online Calibration for UWB-Aided Visual-Inertial Navigation with Bias Correction
Yizhi Zhou, Jie Xu, Jiawei Xia, Zechen Hu, Weizi Li, Xuan Wang
https://arxiv.org/abs/2508.10999
@arXiv_csCV_bot@mastoxiv.pageUnderstand Before You Generate: Self-Guided Training for Autoregressive Image Generation
Xiaoyu Yue, Zidong Wang, Yuqing Wang, Wenlong Zhang, Xihui Liu, Wanli Ouyang, Lei Bai, Luping Zhou
https://arxiv.org/abs/2509.15185
@Techmeme@techhub.socialGoogle says users created 100M videos using its AI filmmaking tool Flow since its May launch; Flow leverages Veo 3 and focuses on maintaining visual consistency (Katelyn Chedraoui/CNET)
https://www.cnet.com/tech/services-and-sof
@arXiv_csCL_bot@mastoxiv.pageUnifiedVisual: A Framework for Constructing Unified Vision-Language Datasets
Pengyu Wang, Shaojun Zhou, Chenkun Tan, Xinghao Wang, Wei Huang, Zhen Ye, Zhaowei Li, Botian Jiang, Dong Zhang, Xipeng Qiu
https://arxiv.org/abs/2509.14738
@arXiv_csRO_bot@mastoxiv.pageBIM Informed Visual SLAM for Construction Monitoring
Asier Bikandi, Miguel Fernandez-Cortizas, Muhammad Shaheer, Ali Tourani, Holger Voos, Jose Luis Sanchez-Lopez
https://arxiv.org/abs/2509.13972
@arXiv_csCV_bot@mastoxiv.pageOmniSegmentor: A Flexible Multi-Modal Learning Framework for Semantic Segmentation
Bo-Wen Yin, Jiao-Long Cao, Xuying Zhang, Yuming Chen, Ming-Ming Cheng, Qibin Hou
https://arxiv.org/abs/2509.15096
@arXiv_csHC_bot@mastoxiv.pageDeconstructing Implicit Beliefs in Visual Data Journalism: Unstable Meanings Behind Data as Truth & Design for Insight
Ke Er Amy Zhang, Jodie Jenkinson, Laura Garrison
https://arxiv.org/abs/2507.12377
@arXiv_csCV_bot@mastoxiv.pageA Fully Transformer Based Multimodal Framework for Explainable Cancer Image Segmentation Using Radiology Reports
Enobong Adahada, Isabel Sassoon, Kate Hone, Yongmin Li
https://arxiv.org/abs/2508.13796 …
@arXiv_csRO_bot@mastoxiv.pageComparison of Localization Algorithms between Reduced-Scale and Real-Sized Vehicles Using Visual and Inertial Sensors
Tobias Kern, Leon Tolksdorf, Christian Birkner
https://arxiv.org/abs/2507.11241
@arXiv_csHC_bot@mastoxiv.pageMore than Meets the Eye: Understanding the Effect of Individual Objects on Perceived Visual Privacy
Mete Harun Akcay, Siddharth Prakash Rao, Alexandros Bakas, Buse Gul Atli
https://arxiv.org/abs/2509.13051
@arXiv_csCV_bot@mastoxiv.pageTowards Understanding Visual Grounding in Visual Language Models
Georgios Pantazopoulos, Eda B. \"Ozyi\u{g}it
https://arxiv.org/abs/2509.10345 https://
@arXiv_csCV_bot@mastoxiv.pageHERO: Rethinking Visual Token Early Dropping in High-Resolution Large Vision-Language Models
Xu Li, Yuxuan Liang, Xiaolei Chen, Yi Zheng, Haotian Chen, Bin Li, Xiangyang Xue
https://arxiv.org/abs/2509.13067
@arXiv_csRO_bot@mastoxiv.pageAssessing the Value of Visual Input: A Benchmark of Multimodal Large Language Models for Robotic Path Planning
Jacinto Colan, Ana Davila, Yasuhisa Hasegawa
https://arxiv.org/abs/2507.12391
@seeingwithsound@mas.toEncoding visual stimuli by striatal neurons (in mice) https://www.biorxiv.org/content/10.1101/2025.09.15.676378v1 "Although visual object encoding is considered a cortical attribute, subcortical areas also contain visual processing circuits."
@arXiv_csRO_bot@mastoxiv.pageDVDP: An End-to-End Policy for Mobile Robot Visual Docking with RGB-D Perception
Haohan Min, Zhoujian Li, Yu Yang, Jinyu Chen, Shenghai Yuan
https://arxiv.org/abs/2509.13024 htt…
@arXiv_csCV_bot@mastoxiv.pageDistractor-Aware Memory-Based Visual Object Tracking
Jovana Videnovic, Matej Kristan, Alan Lukezic
https://arxiv.org/abs/2509.13864 https://arxiv.org/pdf/2…
@arXiv_csCV_bot@mastoxiv.page$\pi^3$: Scalable Permutation-Equivariant Visual Geometry Learning
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, Tong He
https://arxiv.org/abs/2507.13347
@arXiv_csCV_bot@mastoxiv.pageAn Exploratory Study on Abstract Images and Visual Representations Learned from Them
Haotian Li, Jianbo Jiao
https://arxiv.org/abs/2509.14149 https://arxiv…
@arXiv_csCV_bot@mastoxiv.pageHierarchical Graph Feature Enhancement with Adaptive Frequency Modulation for Visual Recognition
Feiyue Zhao, Zhichao Zhang
https://arxiv.org/abs/2508.11497 https://
@arXiv_csCV_bot@mastoxiv.pageVSE-MOT: Multi-Object Tracking in Low-Quality Video Scenes Guided by Visual Semantic Enhancement
Jun Du, Weiwei Xing, Ming Li, Fei Richard Yu
https://arxiv.org/abs/2509.14060 ht…
@arXiv_csRO_bot@mastoxiv.pageLaViPlan : Language-Guided Visual Path Planning with RLVR
Hayeon Oh
https://arxiv.org/abs/2507.12911 https://arxiv.org/pdf/2507.12911…
@arXiv_csCV_bot@mastoxiv.pageInside Knowledge: Graph-based Path Generation with Explainable Data Augmentation and Curriculum Learning for Visual Indoor Navigation
Daniel Airinei, Elena Burceanu, Marius Leordeanu
https://arxiv.org/abs/2508.11446
@arXiv_csRO_bot@mastoxiv.pageGenFlowRL: Shaping Rewards with Generative Object-Centric Flow in Visual Reinforcement Learning
Kelin Yu, Sheng Zhang, Harshit Soora, Furong Huang, Heng Huang, Pratap Tokekar, Ruohan Gao
https://arxiv.org/abs/2508.11049
@arXiv_csCV_bot@mastoxiv.pageLook Again, Think Slowly: Enhancing Visual Reflection in Vision-Language Models
Pu Jian, Junhong Wu, Wei Sun, Chen Wang, Shuo Ren, Jiajun Zhang
https://arxiv.org/abs/2509.12132 …
@arXiv_csCV_bot@mastoxiv.pageDiving into Mitigating Hallucinations from a Vision Perspective for Large Vision-Language Models
Weihang Wang, Xinhao Li, Ziyue Wang, Yan Pang, Jielei Zhang, Peiyi Li, Qiang Zhang, Longwen Gao
https://arxiv.org/abs/2509.13836
@arXiv_csCV_bot@mastoxiv.pageDescribe Anything Model for Visual Question Answering on Text-rich Images
Yen-Linh Vu, Dinh-Thang Duong, Truong-Binh Duong, Anh-Khoi Nguyen, Thanh-Huy Nguyen, Le Thien Phuc Nguyen, Jianhua Xing, Xingjian Li, Tianyang Wang, Ulas Bagci, Min Xu
https://arxiv.org/abs/2507.12441
@arXiv_csCV_bot@mastoxiv.pagePerception Before Reasoning: Two-Stage Reinforcement Learning for Visual Reasoning in Vision-Language Models
Yan Chen, Long Li, Teng Xi, Long Zeng, Jingdong Wang
https://arxiv.org/abs/2509.13031
@arXiv_csCV_bot@mastoxiv.pageDepth AnyEvent: A Cross-Modal Distillation Paradigm for Event-Based Monocular Depth Estimation
Luca Bartolomei, Enrico Mannocci, Fabio Tosi, Matteo Poggi, Stefano Mattoccia
https://arxiv.org/abs/2509.15224
@arXiv_csCV_bot@mastoxiv.pagePRISM: Product Retrieval In Shopping Carts using Hybrid Matching
Arda Kabadayi, Senem Velipasalar, Jiajing Chen
https://arxiv.org/abs/2509.14985 https://ar…
@arXiv_csCV_bot@mastoxiv.pageCan Current AI Models Count What We Mean, Not What They See? A Benchmark and Systematic Evaluation
Gia Khanh Nguyen, Yifeng Huang, Minh Hoai
https://arxiv.org/abs/2509.13939 htt…
@arXiv_csCV_bot@mastoxiv.pageVITA: Vision-to-Action Flow Matching Policy
Dechen Gao, Boqi Zhao, Andrew Lee, Ian Chuang, Hanchu Zhou, Hang Wang, Zhe Zhao, Junshan Zhang, Iman Soltani
https://arxiv.org/abs/2507.13231
@arXiv_csCV_bot@mastoxiv.pageRotBench: Evaluating Multimodal Large Language Models on Identifying Image Rotation
Tianyi Niu, Jaemin Cho, Elias Stengel-Eskin, Mohit Bansal
https://arxiv.org/abs/2508.13968 ht…
@arXiv_csCV_bot@mastoxiv.pageMitigating Cross-Image Information Leakage in LVLMs for Multi-Image Tasks
Yeji Park, Minyoung Lee, Sanghyuk Chun, Junsuk Choe
https://arxiv.org/abs/2508.13744 https://
@arXiv_csCV_bot@mastoxiv.pageVisionThink: Smart and Efficient Vision Language Model via Reinforcement Learning
Senqiao Yang, Junyi Li, Xin Lai, Bei Yu, Hengshuang Zhao, Jiaya Jia
https://arxiv.org/abs/2507.13348
@arXiv_csCV_bot@mastoxiv.pageHumanPCR: Probing MLLM Capabilities in Diverse Human-Centric Scenes
Keliang Li, Hongze Shen, Hao Shi, Ruibing Hou, Hong Chang, Jie Huang, Chenghao Jia, Wen Wang, Yiling Wu, Dongmei Jiang, Shiguang Shan, Xilin Chen
https://arxiv.org/abs/2508.13692
@arXiv_csCV_bot@mastoxiv.pageSPATIALGEN: Layout-guided 3D Indoor Scene Generation
Chuan Fang, Heng Li, Yixun Liang, Jia Zheng, Yongsen Mao, Yuan Liu, Rui Tang, Zihan Zhou, Ping Tan
https://arxiv.org/abs/2509.14981
@arXiv_csCV_bot@mastoxiv.pageEyes on the Image: Gaze Supervised Multimodal Learning for Chest X-ray Diagnosis and Report Generation
Tanjim Islam Riju, Shuchismita Anwar, Saman Sarker Joy, Farig Sadeque, Swakkhar Shatabda
https://arxiv.org/abs/2508.13068
@arXiv_csCV_bot@mastoxiv.pageEnhancing Targeted Adversarial Attacks on Large Vision-Language Models through Intermediate Projector Guidance
Yiming Cao, Yanjie Li, Kaisheng Liang, Yuni Lai, Bin Xiao
https://arxiv.org/abs/2508.13739
@arXiv_csCV_bot@mastoxiv.pageControlling Multimodal LLMs via Reward-guided Decoding
Oscar Ma\~nas, Pierluca D'Oro, Koustuv Sinha, Adriana Romero-Soriano, Michal Drozdzal, Aishwarya Agrawal
https://arxiv.org/abs/2508.11616