 @fanf@mendeddrum.org
@fanf@mendeddrum.org2026-04-04 11:42:03
from my link log —
A brief history of instant coffee.
https://worksinprogress.co/issue/a-brief-history-of-instant-coffee/
saved 2026-04-03
@fanf@mendeddrum.orgfrom my link log —
A brief history of instant coffee.
https://worksinprogress.co/issue/a-brief-history-of-instant-coffee/
saved 2026-04-03
 @jamesthebard@social.linux.pizza
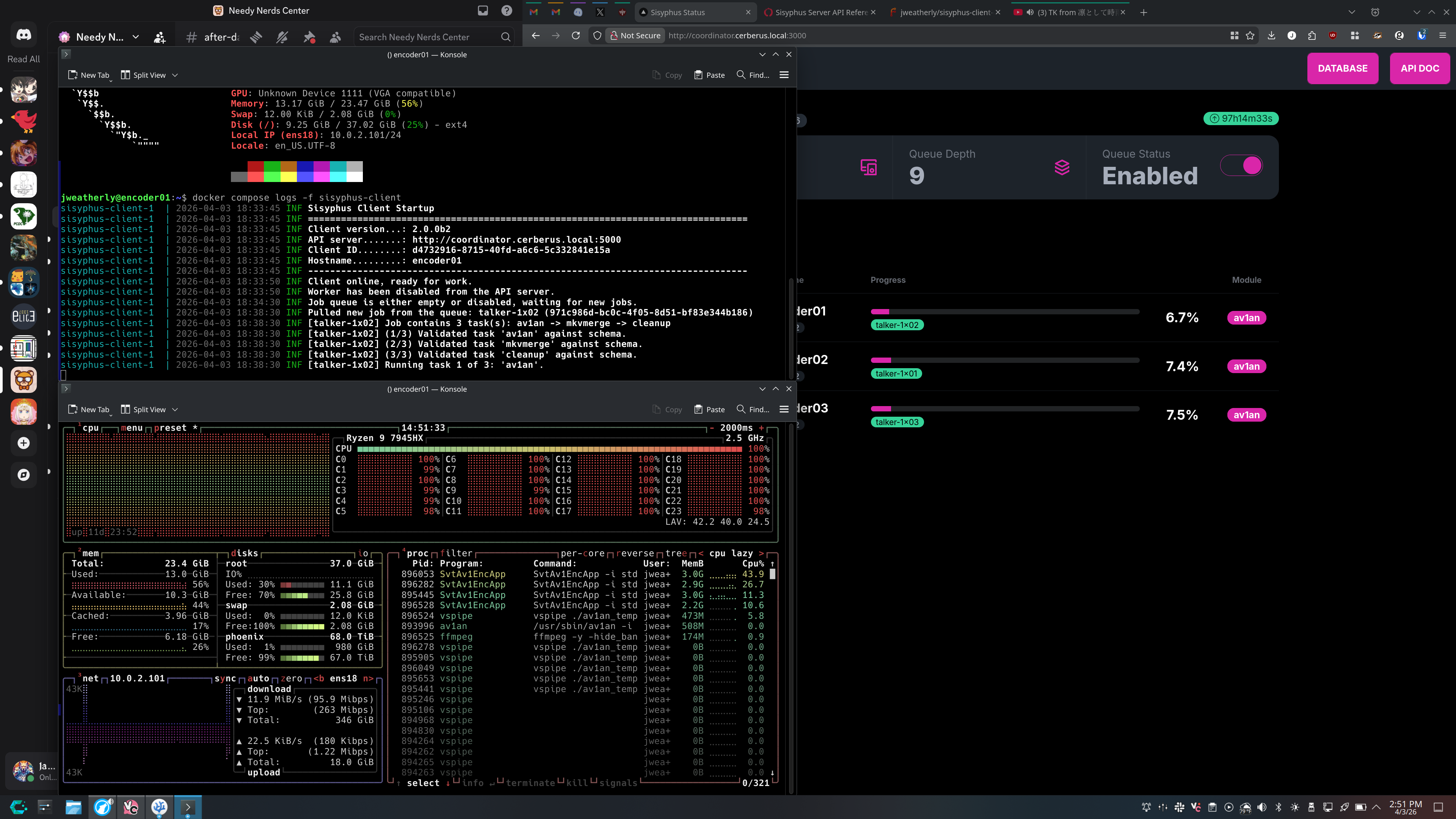
@jamesthebard@social.linux.pizzaLots of progress and a lots of pain. However, all of the Sisyphus modules have been implemented and I'm currently running a test across the `2.0.0b2` version. The most painful thing I fought was literally tailing a log file. Got lazy and brought in `hpcloud/tail` because it did what I needed it to, but what it _didn't_ do was work well for my application. After a day or two of battling it, I removed it and went with `bufio.NewReader`and a nice `context.CloseWith` setup and now it…
 @fanf@mendeddrum.org
@fanf@mendeddrum.orgfrom my link log —
A woman's work: the inside story.
https://longreads.com/2019/04/26/a-womans-work-the-inside-story/
saved 2019-04-27
 @arXiv_csLG_bot@mastoxiv.page
@arXiv_csLG_bot@mastoxiv.pageSki Rental with Distributional Predictions of Unknown Quality
Qiming Cui, Michael Dinitz
https://arxiv.org/abs/2602.21104 https://arxiv.org/pdf/2602.21104 https://arxiv.org/html/2602.21104
arXiv:2602.21104v1 Announce Type: new
Abstract: We revisit the central online problem of ski rental in the "algorithms with predictions" framework from the point of view of distributional predictions. Ski rental was one of the first problems to be studied with predictions, where a natural prediction is simply the number of ski days. But it is both more natural and potentially more powerful to think of a prediction as a distribution p-hat over the ski days. If the true number of ski days is drawn from some true (but unknown) distribution p, then we show as our main result that there is an algorithm with expected cost at most OPT O(min(max({eta}, 1) * sqrt(b), b log b)), where OPT is the expected cost of the optimal policy for the true distribution p, b is the cost of buying, and {eta} is the Earth Mover's (Wasserstein-1) distance between p and p-hat. Note that when {eta} < o(sqrt(b)) this gives additive loss less than b (the trivial bound), and when {eta} is arbitrarily large (corresponding to an extremely inaccurate prediction) we still do not pay more than O(b log b) additive loss. An implication of these bounds is that our algorithm has consistency O(sqrt(b)) (additive loss when the prediction error is 0) and robustness O(b log b) (additive loss when the prediction error is arbitrarily large). Moreover, we do not need to assume that we know (or have any bound on) the prediction error {eta}, in contrast with previous work in robust optimization which assumes that we know this error.
We complement this upper bound with a variety of lower bounds showing that it is essentially tight: not only can the consistency/robustness tradeoff not be improved, but our particular loss function cannot be meaningfully improved.
toXiv_bot_toot
 @UP8@mastodon.social
@UP8@mastodon.socialLogged into Google using Chrome at work and found it's become a Kakfa-esque experience where I had to log in five times before I realized what was going on with "profiles" I've never asked for. Reminds me of the time I did a shoot-out of ten visual recognition APIs and I got demos of the others done in 20 minutes each but Google Cloud Compute took two hours because it trashed my Python #google
 @grahamperrin@bsd.cafe
@grahamperrin@bsd.cafeNot reproducible, however I have a VirtualBox snapshot of the bugged installation.
I can restart SDDM and login, again I get a black screen. Xorg.0.log has one error:
open /dev/dri/card0: No such file or directory
Maybe negligible. The same error occurs when I successfully startx and use twm instead of Plasma (X11).
'reboot -r' is not enough to work around the issue.
Plasma did work, once, after 'shutdown -r now', however this is not a consis…
@fanf@mendeddrum.orgfrom my link log —
Matt Gray hacked car charging to work with his e-bike. (YouTube)
https://youtu.be/i6IyukCIia8
saved 2026-02-23 https://dotat.at/:/LX0C8.…
 @theodric@social.linux.pizza
@theodric@social.linux.pizzaOne of the best features of GrapheneOS is that the Twitter app does not work at all: fails attestation, won't log in, and softblocks your account for suspicious activity. More folks should switch!
@arXiv_csLG_bot@mastoxiv.pageStatistical Query Lower Bounds for Smoothed Agnostic Learning
Ilias Diakonikolas, Daniel M. Kane
https://arxiv.org/abs/2602.21191 https://arxiv.org/pdf/2602.21191 https://arxiv.org/html/2602.21191
arXiv:2602.21191v1 Announce Type: new
Abstract: We study the complexity of smoothed agnostic learning, recently introduced by~\cite{CKKMS24}, in which the learner competes with the best classifier in a target class under slight Gaussian perturbations of the inputs. Specifically, we focus on the prototypical task of agnostically learning halfspaces under subgaussian distributions in the smoothed model. The best known upper bound for this problem relies on $L_1$-polynomial regression and has complexity $d^{\tilde{O}(1/\sigma^2) \log(1/\epsilon)}$, where $\sigma$ is the smoothing parameter and $\epsilon$ is the excess error. Our main result is a Statistical Query (SQ) lower bound providing formal evidence that this upper bound is close to best possible. In more detail, we show that (even for Gaussian marginals) any SQ algorithm for smoothed agnostic learning of halfspaces requires complexity $d^{\Omega(1/\sigma^{2} \log(1/\epsilon))}$. This is the first non-trivial lower bound on the complexity of this task and nearly matches the known upper bound. Roughly speaking, we show that applying $L_1$-polynomial regression to a smoothed version of the function is essentially best possible. Our techniques involve finding a moment-matching hard distribution by way of linear programming duality. This dual program corresponds exactly to finding a low-degree approximating polynomial to the smoothed version of the target function (which turns out to be the same condition required for the $L_1$-polynomial regression to work). Our explicit SQ lower bound then comes from proving lower bounds on this approximation degree for the class of halfspaces.
toXiv_bot_toot
@fanf@mendeddrum.orgfrom my link log —
An update on upki: TLS certificate revocation checking with CRLite in Rust.
https://discourse.ubuntu.com/t/an-update-on-upki/77063
saved 2026-02-19 …
 @arXiv_csDS_bot@mastoxiv.page
@arXiv_csDS_bot@mastoxiv.pageLocal Computation Algorithms for (Minimum) Spanning Trees on Expander Graphs
Pan Peng, Yuyang Wang
https://arxiv.org/abs/2602.07394 https://arxiv.org/pdf/2602.07394 https://arxiv.org/html/2602.07394
arXiv:2602.07394v1 Announce Type: new
Abstract: We study \emph{local computation algorithms (LCAs)} for constructing spanning trees. In this setting, the goal is to locally determine, for each edge $ e \in E $, whether it belongs to a spanning tree $ T $ of the input graph $ G $, where $ T $ is defined implicitly by $ G $ and the randomness of the algorithm. It is known that LCAs for spanning trees do not exist in general graphs, even for simple graph families. We identify a natural and well-studied class of graphs -- \emph{expander graphs} -- that do admit \emph{sublinear-time} LCAs for spanning trees. This is perhaps surprising, as previous work on expanders only succeeded in designing LCAs for \emph{sparse spanning subgraphs}, rather than full spanning trees. We design an LCA with probe complexity $ O\left(\sqrt{n}\left(\frac{\log^2 n}{\phi^2} d\right)\right)$ for graphs with conductance at least $ \phi $ and maximum degree at most $ d $ (not necessarily constant), which is nearly optimal when $\phi$ and $d$ are constants, since $\Omega(\sqrt{n})$ probes are necessary even for expanders. Next, we show that for the natural class of \emph{\ER graphs} $ G(n, p) $ with $ np = n^{\delta} $ for any constant $ \delta > 0 $ (which are expanders with high probability), the $ \sqrt{n} $ lower bound can be bypassed. Specifically, we give an \emph{average-case} LCA for such graphs with probe complexity $ \tilde{O}(\sqrt{n^{1 - \delta}})$.
Finally, we extend our techniques to design LCAs for the \emph{minimum spanning tree (MST)} problem on weighted expander graphs. Specifically, given a $d$-regular unweighted graph $\bar{G}$ with sufficiently strong expansion, we consider the weighted graph $G$ obtained by assigning to each edge an independent and uniform random weight from $\{1,\ldots,W\}$, where $W = O(d)$. We show that there exists an LCA that is consistent with an exact MST of $G$, with probe complexity $\tilde{O}(\sqrt{n}d^2)$.
toXiv_bot_toot
@fanf@mendeddrum.orgfrom my link log —
The asymptotic cost of address translation on memory access time.
https://arxiv.org/abs/1212.0703
saved 2020-10-21 https://dotat.at/:…
@fanf@mendeddrum.orgfrom my link log —
How London finally cracked mobile phone coverage on the Underground.
https://www.ianvisits.co.uk/articles/how-london-finally-cracked-mobile-phone-coverage-on-the-underground-86784/
saved…
@fanf@mendeddrum.orgfrom my link log —
A preview of Coalton 0.2, a statically-typed Lisp.
https://coalton-lang.github.io/20260312-coalton0p2/
saved 2026-03-14 https:/…
@fanf@mendeddrum.orgfrom my link log —
Pushing and pulling: three reactivity algorithms.
https://jonathan-frere.com/posts/reactivity-algorithms/
saved 2026-03-07




