 @macandi@social.heise.de
@macandi@social.heise.de2026-04-23 07:03:00
Tipp: iTunes-Extras auf dem Smart-TV ansehen
Beim Filmekauf kommen manchmal Zusatzmaterialien mit, die man auf Apple-TV-Geräten leicht anzeigen kann. Geht das auch auf Smart-TVs?
https://www.he…
 @cdarwin@c.im
@cdarwin@c.im2026-05-22 00:45:52
The IPO prospectus SpaceX dropped last night revealed how much the world’s largest public offering is underpinned by a founder firmly in control.
Elon Musk, who previously complained he didn’t have a big enough say in Tesla,
will control 85% of the vote at SpaceX through special shares
(and will get another billion shares if SpaceX puts a million-person colony on Mars).
The filing raised speculation that after SpaceX goes public, a purchase of Tesla isn’t far off.

 @Sustainable2050@mastodon.energy
@Sustainable2050@mastodon.energy2026-07-21 19:45:56
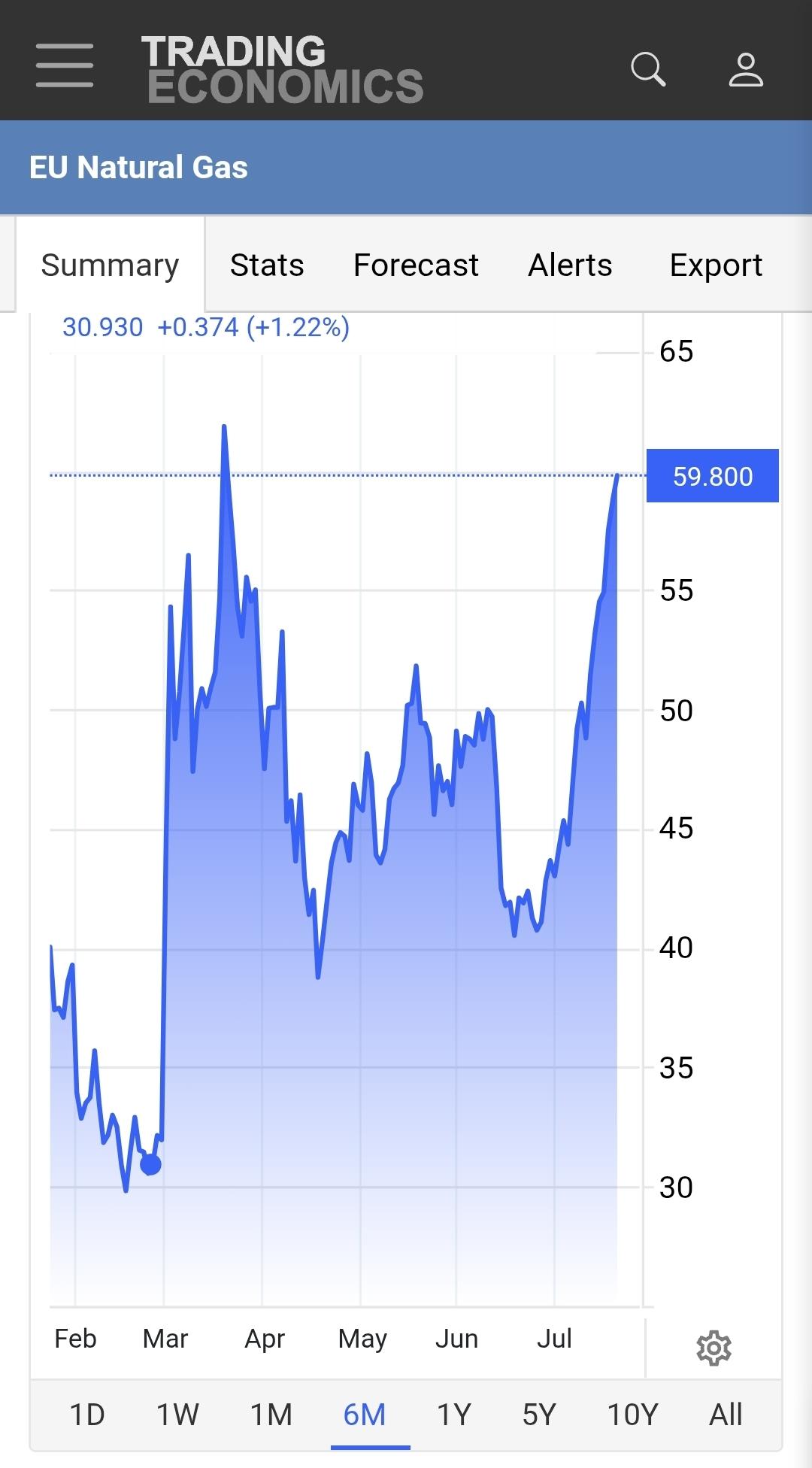
The natural gas price for the EU is up sharply now the Trump-Netanyahu war escalates again. Close to €60/MWh now; that's 100% compared to the price before the war vs 'only' 50% for oil (Brent).
Not a good combination with sluggishly filling up our gas storages. I guess we'll notice in winter.
#Iran
 @hikingdude@mastodon.social
@hikingdude@mastodon.social2026-06-23 06:08:02
Good morning! I replaced the morning walk with a morning ride. 😊 I tried to push a bit harder today for training. Next time should be lighter again. But it felt really good!
#cycling #goodmorning

 @raiders@darktundra.xyz
@raiders@darktundra.xyz2026-06-22 19:02:50
Raiders Get Good News on Rookie Flying Under the Radar https://heavy.com/sports/nfl/las-vegas-raiders/malik-benson-biggest-surprise/
 @tiotasram@kolektiva.social
@tiotasram@kolektiva.social2026-07-22 01:13:23
That feeling when "ancient Native American burial mounds" are mentioned on page 2 and you think "oh God here we go with some intense racism/cultural appropriation again" but then you remember that you checked this book out because it was Native-authored and so it's actually a good thing.
 @cosmos4u@scicomm.xyz
@cosmos4u@scicomm.xyz2026-06-22 18:08:49
#Kilonovae and Long-duration Gamma-Ray Bursts: https://iopscience.iop.org/article/10.3847/2041-8213/ae5e53 -> "detections of kilonova-like emission following long-duration gamma-ray bursts GRB 211211A and GRB 230307A have been interpreted as originating from the merger of two neutron stars. In this work, we demonstrate that these observations are also consistent with nucleosynthesis originating from a collapsar scenario" -> Los Alamos scientists uncover new insights into gamma ray bursts: https://www.lanl.gov/media/news/0617-gamma-ray-bursts - extreme high-energy events in the universe corroborated as originating from collapsing stars.
 @inthehands@hachyderm.io
@inthehands@hachyderm.io2026-05-22 20:55:46
Hey, Twin Cities folks! I'm in an upcoming show that I'm excited about.
It’s visual art, it’s theater, it’s music, it’s ritual, it’s community meditation, it’s one of those •experiences• that defies categorization. It's the brainchild of Summer Hills-Bonczyk, who runs the cermics studio at Macalester, and I'm working with her brother to create music for the show.
I have a good feeling about this. I think it's going to be really cool!
#MSP #StPaul #Minneapolis
 @Demirramon@cyberfurz.social
@Demirramon@cyberfurz.social2026-05-23 14:35:46
I finally got to layer 3 on Casualties: Unknown.
The random spikes falling from the ceiling were spooky. I also fell past a turret thing and it gave me a damn heart attack, but it didn't hurt me.
Then I saw a land mine. I stepped on it by accident, then ran as far as I could, and... kaboom. A few dislocated bones, got debris stuck EVERYWHERE, and quite a bunch of bleeding. Surprisingly, I could heal everything (which took a while), except for their poor left eye... but it is…
@cdarwin@c.im2026-07-23 04:35:02
When we encounter something that promises enjoyment or discovery, the brain’s reward system becomes active.
One important pathway runs from the ventral tegmental area,
a dopamine-producing region in the midbrain involved in motivation,
to the nucleus accumbens, a structure that helps generate feelings of reward.
Dopamine is often described as a pleasure chemical, but that is too simple.
One of its key roles is helping the brain identify opportunities worth pursu…
