@heiseonline@social.heise.de
@heiseonline@social.heise.de2026-06-24 11:39:00
@heiseonline@social.heise.de @Techmeme@techhub.social
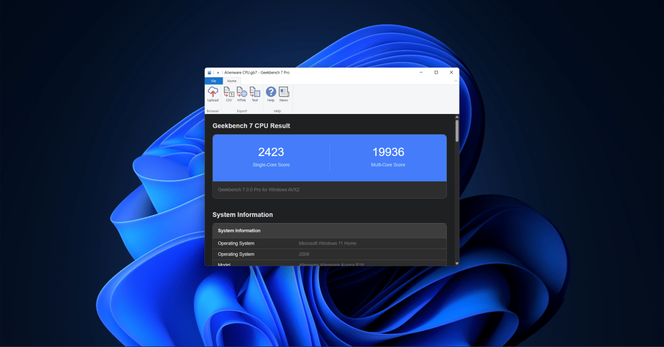
@Techmeme@techhub.socialPrimate Labs releases Geekbench 7, featuring larger, more demanding datasets for CPUs and GPUs, along with new video and audio encoding/decoding tests, and more (Antonio G. Di Benedetto/The Verge)
https://www.theverge.com/gadgets/970012/primate…
 @macandi@social.heise.de
@macandi@social.heise.de @cheeaun@mastodon.social
@cheeaun@mastodon.social🤔 Seems like WP (7.1) now uses wasm-vips for processing images and mediabunny to convert opaque animated GIFs to videos (MP4/WebM) https://make.wordpress.org/core/2026/07/22/client-side-media-processing-in-wordpress-7-1/
Its feature detect…

 @markhburton@mstdn.social
@markhburton@mstdn.social2) Two Palestinians shot dead by Israeli forces as West Bank fields set ablaze | Israel-Palestine conflict News | Al Jazeera
https://www.aljazeera.com/news/2026/7/23/two-palestinians-shot-dead-by-israeli-f…
 @memeorandum@universeodon.com
@memeorandum@universeodon.com7.1 magnitude earthquake strikes Venezuela, triggers tsunami advisory for Puerto Rico, Virgin Islands (Faris Tanyos/CBS News)
https://www.cbsnews.com/news/7-1-magnitude-earthquake-venezuela-tsunami-advisory-puerto-rico-virgin-islands/
http://www.memeorandum.com/260624/p122#a260624p122
 @mia@hcommons.social
@mia@hcommons.socialSo helpful! '7 Ways to More Frugal AI' by James Martin - from don't use AI to use the smallest model possible, use non-US models for greener electricity, host your own to 'green prompting'
https://bettertech.blog/2026/04/09/7-ways-to-more-frugal-ai/…
 @newsie@darktundra.xyz
@newsie@darktundra.xyz @zachleat@zachleat.com
@zachleat@zachleat.comWordPress updates required: https://wordpress.org/news/2026/07/wordpress-7-0-2-release/
> The attack has no preconditions and can be exploited by an anonymous user in a stock install of WordPress with no plugins —
 @kurtsh@mastodon.social
@kurtsh@mastodon.socialJFC.
✅ TSA's viral tweet just confirmed you can fly with a whole rotisserie chicken — and 7 other foods that surprise travelers at security
https://creators.yahoo.com/lifes…
 @Mediagazer@mstdn.social
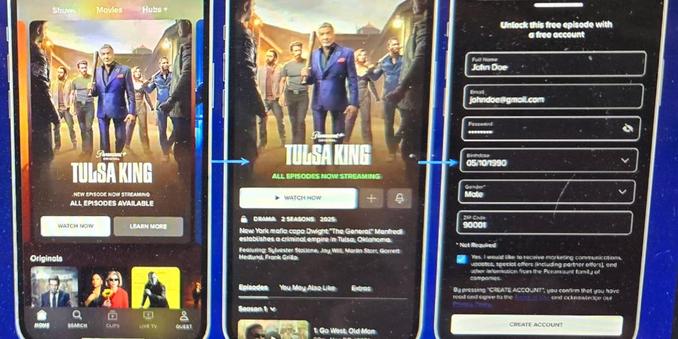
@Mediagazer@mstdn.socialInternal docs: Paramount plans to launch a free tier for movies and shows in Q3, requiring users to register via email (James Faris/Business Insider)
https://www.businessinsider.com/paramount-free-tier-pluto-tv-streaming-youtube-tubi-elliso…
@Techmeme@techhub.socialOracle wins a 10-year software contract with the Pentagon worth up to $7B; the contract covers the use of Oracle software in on-premises data centers (Jordan Novet/CNBC)
https://www.cnbc.com/2026/07/23/oracle-wins-10-year-pentagon-sof…
 @Dragofix@veganism.social
@Dragofix@veganism.socialWorld's highest-consuming 10% cause up to $5.7 trillion a year in environmental damage, study finds https://phys.org/news/2026-06-world-highest-consuming-trillion-year.html
 @realmurphy@social.linux.pizza
@realmurphy@social.linux.pizzawww.maptap.gg June 23
99🎯 94🏅 98🎯 74🤗 84😁
Final score: 863
1. x: 1 pts, 13,186 km, 1 min, 4 sec, 0 steps
2. x: 2,443 pts, 1,068 km, 1 min, 4 sec, 0 steps
3. x: 604 pts, 3,153 km, 1 min, 34 sec, 0 steps
4. x: 4,361 pts, 204 km, 3 min, 0 steps
5. x: 4,715 pts, 88 km, 58 sec, 0 steps
Total: 12,124 pts, 17,699 km, 7 min, 40 sec, 0 steps
TimeGuessr #1119 — 37,129/50,000
1️⃣ 🏆5921 - 📅17y - 🌍3.7 km
2️⃣ 🏆9936 - 📅0y - 🌍2.7 km
3️⃣ 🏆9092 - …
 @raiders@darktundra.xyz
@raiders@darktundra.xyzCarson Beck signs $7.4 million deal with Cardinals: How much is Fernando Mendoza entitled to with Raiders? https://bolavip.com/en/nfl/carson-beck-signs-7-4-million-deal-with-cardinals-how-much-is-fernando-mendoza-en…
 @grahamperrin@bsd.cafe
@grahamperrin@bsd.cafe @catsalad@infosec.exchange
@catsalad@infosec.exchange6-7
 @ruari@velocipederider.com
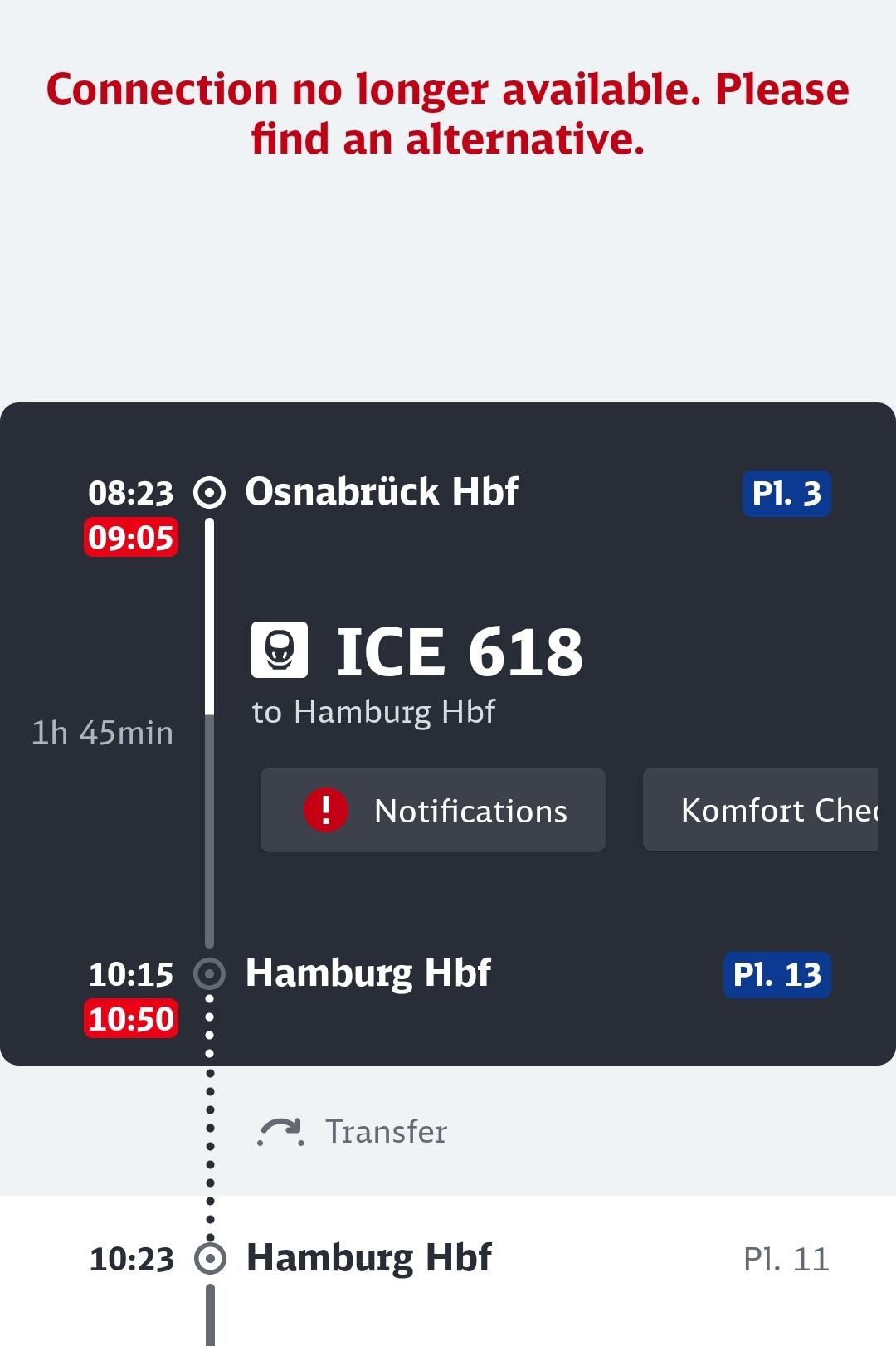
@ruari@velocipederider.com7 hours of train trips today. The first connection was already adjusted to be razor thin due to timetable changes that happened after I first booked it. Now in addition the train is also massively delayed.
This means the rest of my route is a bust and any possible alternative route at short notice will take hours longer.
It is tricky to explain to the kids why we always take trains while their friends fly, especially when this often happens in Germany.
The reason is clima…
 @heiseonline@social.heise.de
@heiseonline@social.heise.de @migueldeicaza@mastodon.social
@migueldeicaza@mastodon.socialWhen you are a game developer, every Godot release feels like Xmas!
https://godotengine.org/releases/4.7/
 @cdarwin@c.im
@cdarwin@c.imTrump's motorcade drove directly across the drained Reflecting Pool while it was being painted.
On May 7, Trump paid a visit to the Reflecting Pool to meet with reporters and inspect the new paint personally.
To get there, the motorcade drove across the drained Reflecting Pool from the Washington Monument side.
It made an impressive spectacle,
but may have damaged the bottom of the pool in the process.
Not that this administration cares much about science, …
 @presseportal_pol_NDS@frawas.de
@presseportal_pol_NDS@frawas.dePOL-VER: Korrektur zur Meldung: Drei Verletzte nach Verkehrsunfall Landkreis Verden (ots) - Thedinghausen. Am Mittwochmorgen kam es gegen 7 Uhr zu einem Verkehrsunfall auf der Brückenstraße, bei dem fünf Personen verletzt wurden. Ein 38-jähriger Volvo-Fahrer befuhr die Brückenstraße in Richtung Achim, als er ... https://www.
 @floheinstein@chaos.social
@floheinstein@chaos.socialWar vor 7 Uhr im klimatisierten Gebäude, 8 Stunden später trete ich vor die Tür in die Asphalt-Wüste und hab nun Verständnis dafür, was "scharf anbraten" mit dem Fleisch macht.
#hitzewelle
 @tinoeberl@mastodon.online
@tinoeberl@mastodon.online#Steady #Klimacrew
#BahnMonitor-Projekt: 7. Zufall ist nicht gleich Zufall. 🤭
Nach der Verspätungsmeldung kommt ein Wissenshäppchen. Der
 @cosmos4u@scicomm.xyz
@cosmos4u@scicomm.xyz @Tupp_ed@mastodon.ie
@Tupp_ed@mastodon.ieThere are always surprise wins
https://bsky.app/profile/did:plc:pruto64zme7b7pmxnporm4tm/post/3mmlitura3s22
 @mela@zusammenkunft.net
@mela@zusammenkunft.netWeil ich heute danach gefragt wurde, meine Schnell-und-Schmutzig-Anleitung für einen Kühlschal oder ein Kühlarmband:
Zeitbedarf: 15–20 Minuten mit Nähmaschine und Übung, 1–2 Stunden mit der Hand oder wenig Übung.
Ihr braucht:
1. Stoff
Am besten Baumwolle oder dünnes Leinen. Ideal sind z.B. Baumwoll-Bandanas.
2. Wasserperlen/Hydrokugeln/Orbeez
Ihr bekommt diese in Bastel- oder Dekoläden, Blumenläden oder dem Kaufhaus Eures Vertrauens.
1/7

 @tanyakaroli@expressional.social
@tanyakaroli@expressional.socialAftenbilleder ud af hotelvinduer har en særlig charme, ikke mindst når der er tændt lys bag én, så der kommer genskin indefra på ruden.


 @servelan@newsie.social
@servelan@newsie.socialA pittance compared to the actual need.
Trump Admin Commits $7.5 Million to Bring More Protein to Food Banks | Civil Eats
https://civileats.com/2026/05/21/trump-admin-commits-7-5-million-to-bring-more-protein-to-food-banks/
 @cyrevolt@mastodon.social
@cyrevolt@mastodon.socialLooking forward to another round of fiddling with configs. 🙃
https://devblogs.microsoft.com/typescript/announcing-typescript-7-0-rc/
 @qurlyjoe@mstdn.social
@qurlyjoe@mstdn.social#maudlinMaunderings of a doddering fool. Caveat lector.
Hey, it’s been a while. Thanks for stopping by.
Here’s a mundane thing I discovered about my body tonight. Totally SFW. PG. I’m old and arthritic. I’m used to all the various aches and pains that are either constant or intermittent. IIWIS… (1/7)


 @bourgwick@heads.social
@bourgwick@heads.socialnow posted: complete transcripts for season 12 of the good ol' grateful deadcast, our extended hang at the 1975 "blues for allah" sessions, plus our episode with engineer dan healy. https://www.dead.net/deadcast-index

![Season 12
Dan Healy 80 (7/31/25) [transcript]
Blues For Allah 50: Help On the Way (8/14/25) [transcript]
Blues For Allah 50: Slipknot! (8/28/25) [transcript]
Blues For Allah 50: Franklin's Tower (9/11/25) [transcript]
Blues For Allah 50: King Solomon's Marbles/Stronger Than Dirt or Milkin'
The Turkey (9/25/25) [transcript]
Blues For Allah 50: The Music Never Stopped (10/9/25) [transcript]
Blues For Allah 50: Crazy Fingers (10/22/25) [transcript]
Blues For Allah 50: Sage and Spirit (11/5/25) [tr…](https://cdn.masto.host/headssocial/media_attachments/files/116/624/528/290/475/491/original/3105b99ff909c6c4.jpeg)
 @primonatura@mstdn.social
@primonatura@mstdn.social"Europe’s heat pumps replace Middle East gas imports twice over. Which country is leading the way?"
#Europe #HeatPumps #Energy
 @philip@mastodon.mallegolhansen.com
@philip@mastodon.mallegolhansen.com“Socially Responsible” fund comprised of:
9% Nvidia
7.5% Apple
5.5% Microsoft
4.5% Amazon
4% Alphabet
2.3% Meta
2% Tesla
(Among others)
Certainly suggests Vanguard has a very different definition of responsible than I do.
 @dotproto@toot.cafe
@dotproto@toot.cafe @rainerzufall_le@mastodon.social
@rainerzufall_le@mastodon.social @georgiamuseum@glammr.us
@georgiamuseum@glammr.us“I want them to think about the ways in which they grew up — whether it was an urban environment or rural environment, whether it was the United States or outside the United States, how did that particular place itself inform a sense of who they are?” said McCaskill.
7/
 @chiraag@mastodon.online
@chiraag@mastodon.onlineI reached the Genius 🎓 level in Spelling Bee.
My stats:
Words: 45/45
Score: 223/223
Play Spelling Bee 🐝 https://spellbee.org/
 @penguin42@mastodon.org.uk
@penguin42@mastodon.org.uk @SmartmanApps@dotnet.social
@SmartmanApps@dotnet.socialI was just reminded of a funny moment in my Year 7 #Mathematics class yesterday. We were covering ratioes, and I didn't hear it, but apparently one of the kids asked what "ratioed" meant. I heard some of the banter, so I explained, complete with board illustrations, what ratioed meant, upon which one of the kids said "OMG!
 @exil_inselette@norden.social
@exil_inselette@norden.social#fedihelp bitte:
(Mac Sequoia 15.7.7)
Seit einiger Zeit habe ich Probleme beim Kopieren von Texten.
Gerade eben hab ich einen Text in FF kopiert und wollte ihn in Text Edit einfügen. Das Ergebnis seht ihr im Screenshot. Den Effekt habe ich auch bei anderen Anwendungen. Andere Browser (Safari/Vivaldi) und zum Beispiel auch beim Einfügen im Programm „Notizzettel“. Hat bitte eine:r vo…
 @Techmeme@techhub.social
@Techmeme@techhub.socialAdam Mosseri says Instagram will take down "pickup line" and other videos shot on Meta glasses that feature harassment of strangers in public places (Katie Notopoulos/Business Insider)
https://www.businessinsider.com/instagram-meta-glasses-…
 @aligyie@digitalcourage.social
@aligyie@digitalcourage.social @Speckdaene@nrw.social
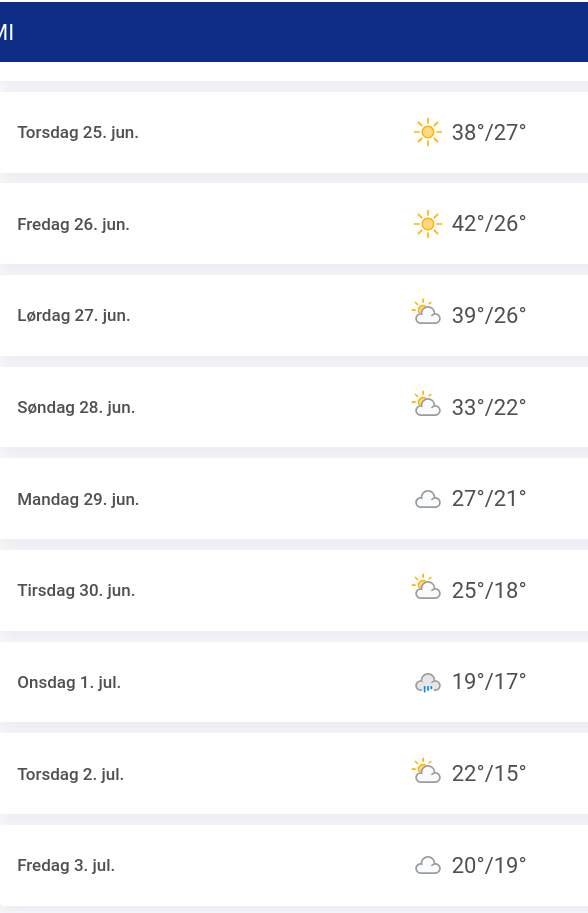
@Speckdaene@nrw.socialDänisches meteorologisches Institut, Prognose für #Dortmund, wird regelmäßig aktualisiert, im Moment 42° für Freitag. https://www.dmi.dk/lokation/show/DE/2935517/Dortmund/
 @jom@social.kontrollapparat.de
@jom@social.kontrollapparat.deRE: https://ard.social/@tagesschau/116968748659961616
Bei einem Nettogewinn 2025 von Alphabet/Google mit rund 132,2 Milliarden US-Dollar, dann entsprechen 890 Millionen Euro ungefähr 0,7 % davon.
 @jdrm@social.linux.pizza
@jdrm@social.linux.pizza @matematico314@social.linux.pizza
@matematico314@social.linux.pizzaRE: https://mathstodon.xyz/@Bruce/116963834901518261
Eu quase me esqueci. Hoje é 22/7, dia da aproximação do pi. Pq dia da aproximação do pi? Porque 22/7 = 3,142857142857142857..., que é uma excelente aproximação para pi = 3,14159265358...
 @davej@dice.camp
@davej@dice.campI've finally done it! It took me over five years, but I've *finally* finished a game of #Stellaris!
And now, I need sleep.



 @berlinbuzzwords@floss.social
@berlinbuzzwords@floss.socialWe are excited to welcome Hornet to 2026 Berlin Buzzwords as a Silver Partner!
Take a look at what they are building: https://hornet.dev/
Join us for Berlin Buzzwords on June 7-9 at Kulturbrauerei or online. https://2026.berlinbuzzwords.de/

 @randombaywatch@mastodon.social
@randombaywatch@mastodon.social#PamelaAnderson
Season 5 Episode 7 "Someone To Baywatch Over You"
#RandomBaywatch #lvdlpx

 @metacurity@infosec.exchange
@metacurity@infosec.exchangeOnce again, Metacurity kicks off with a concise summary of yesterday's blizzard of AI developments that cyber defenders should know, followed by briefs on other critical infosec developments, including
--US seizes 1,000 piracy sites streaming World Cup matches,
--7-Zip fixes critical RCE flaw,
--Attackers begin exploiting critical ServiceNow AI platform flaw,
--Millions of aftermarket car alarms can be hacked over Bluetooth,
--SonicWall zero-days used to d…
 @DieGesellschafterinLang@swiss.social
@DieGesellschafterinLang@swiss.socialToo hot - Deutsches Architekturmuseum zeigt Wege gegen die Hitze
Was? Ausstellung „Too hot“ – Heisse Städte, neue Wege
Wann? 20. Juni 2026 – 7. Februar 2027
Wo? Deutsches Architekturmuseum #Frankfurt am Main
Website: dam-online.de/veranstaltung/too-hot/
 @steve@s.yelvington.com
@steve@s.yelvington.comThis is a theft of $1.7 billion in taxpayer money to be used for political rewards to traitors who tried to overthrow the elected government of the United States.
https://www.pbs.org/newshour/politics/just
 @pixel@mastodon.online
@pixel@mastodon.onlineimagine investing in astro db just for astro 7 to come around and kill it out of nowhere
 @krone@frawas.de
@krone@frawas.deErste Absagen - Porsche verlangt 12,7 Millionen € für Zweig-Villa #News #Nachrichten
 @NFL@darktundra.xyz
@NFL@darktundra.xyzDak Prescott says playoffs are 'minimum' expectation for Cowboys in 2026 https://www.nfl.com/news/dak-prescott-playoffs-minimum-expectation-cowboys-2026
 @thesaigoneer@social.linux.pizza
@thesaigoneer@social.linux.pizzaWith all my explorations going on, it's easy to forget that both my Slackware KDE and Gentoo dwm installs are on the cutting edge of basically everything and just humming along nicely. Through all kernel upgrades and beta software (kde 6.7!) they just work. Amazing tools!
 @askans@bonn.social
@askans@bonn.socialWer meine persönlichen AI Lösungen sehen will:
https://bonn.jetzt/event/agentic-coding-meetup-bonn-7
 @netzschleuder@social.skewed.de
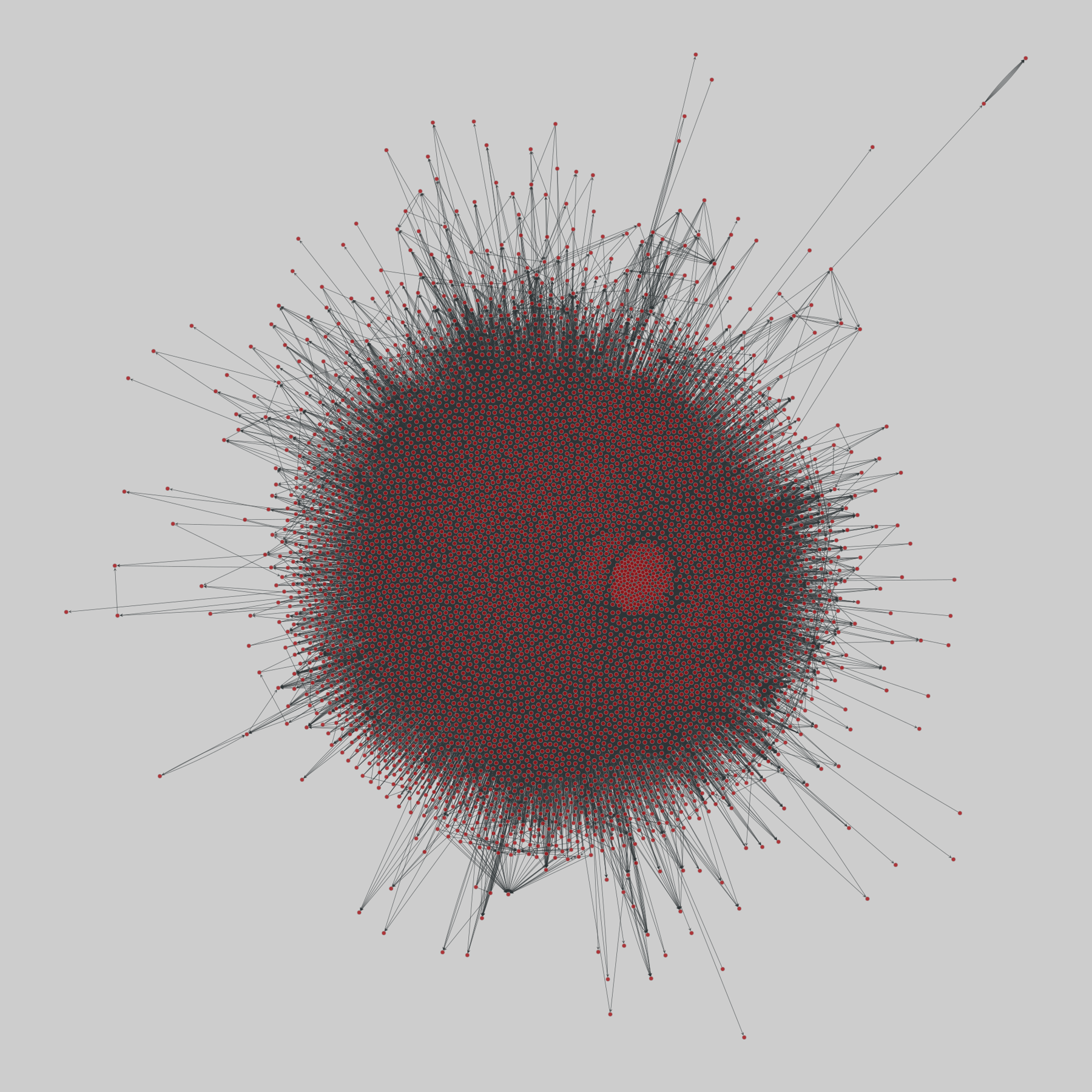
@netzschleuder@social.skewed.dejung: JUNG and javax class dependencies (2012)
A network of software class dependency within the JUNG 2.0.1 and javax 1.6.0.7 library namespaces edu.uci.ics.jung and java/javax. Nodes represent classes and a directed edge indicates a dependency of one class on another.
This network has 6120 nodes and 138706 edges.
Tags: Technological, Software, Unweighted
 @catsalad@infosec.exchange
@catsalad@infosec.exchangeRE: https://infosec.exchange/@perfect10_bot/116632102611950288
Vendor: TOTOLINK
Product: A8000RU
Version: 7.1cu.643_b20200521
Vulnerability: Command Injection
 @CubitOom@social.linux.pizza
@CubitOom@social.linux.pizzaFascists raid construction site, illegally detain two U.S. citizens (Brownsville, TX, 7/21/26)
Video Source:
https://reddit.com/comments/1v42lp2
More Info:
…

 @matthiasott@mastodon.social
@matthiasott@mastodon.socialEurope, next 7 days: up to 18 °C above normal.
“It’s been hot before.” Sure. And the last ten years are the ten hottest ever recorded. This is the second heatwave in a month – made 3–5 times more likely by climate change. We decide how much worse it gets. #ClimateAction #Vote accordingly
 @Techmeme@techhub.social
@Techmeme@techhub.socialSources: Hadrian, which is building AI-powered factories to produce space and defense parts, is in talks to raise ~$1B at a ~$7.5B post-money valuation (Bloomberg)
https://www.bloomberg.com/news/articles/2026-06-23/startup-had…
@markhburton@mstdn.socialA bit of a trip down memory lane. Early British Ecology organisation, the Conservation Society. herring-7-4.pdf https://www.environmentandsociety.org/sites/default/files/key_docs/herring-7-4.pdf
herring-7-4.pdf
@presseportal_pol_NDS@frawas.dePOL-VER: Drei Verletzte nach Verkehrsunfall Lkw in Brückenunterführung festgefahren Landkreise Verden & Osterholz (ots) - LANDKREIS VERDEN Drei Verletzte nach Verkehrsunfall Thedinghausen. Am Mittwochmorgen kam es gegen 7 Uhr zu einem Verkehrsunfall auf der Brückenstraße, bei dem drei Personen verletzt wurden. Ein Volvo-Fahrer ... https://ww…
@heiseonline@social.heise.deKDE Plasma 6.7 bringt Detailverbesserungen
Versionspflege: KDE hievt den Plasma-Desktop auf Stand 6.7. Jeder Bildschirm kann nun einen virtuellen Desktop bekommen.
https://www.heise.de/news/KDE-Plas…
@cdarwin@c.imTrump returned to office promising lower costs across the economy,
but an important interest rate that his administration cites as a barometer of its success recently hit its highest level of Trump’s second term.
The yield on the 10-year Treasury bond,
considered one of the most important interest rates in the world,
jumped this week to 4.7 percent,
up from less than 4 percent before the start of the war in Iran in late February.
It was 4.6 percent on the …
@Mediagazer@mstdn.socialDigital News Report: 10% of people across 48 markets use AI chatbots for news weekly, up from 7% in 2025; the most common use was asking questions about a story (Amy Ross Arguedas/Nieman Lab)
https://www.niemanlab.org/2026/06/the-use-of-ai…
@qurlyjoe@mstdn.social#Virga is rain that doesn’t reach the ground. It’s a thing here in the US mountain west. Very cool and photogenic and strikingly dramatic to see in the distance, especially depending on where the sun is when you see it. I just stepped out of my house and a bit of virga exceeded expectations and reached the ground around me. So, just rain, but no clouds overhead, sun casting solstice 7 o’clock shadows…
@tanyakaroli@expressional.socialNogle gange lykkes det så … ikke så godt 😅
(Det er svært at fange med kameraet hvor fladt det her brŸd blev - men det smager aldeles udmærket alligevel)
 @chiraag@mastodon.online
@chiraag@mastodon.onlineI reached the Genius 🎓 level in Spelling Bee.
My stats:
Words: 40/40
Score: 170/170
Play Spelling Bee 🐝 https://spellbee.org/
@grahamperrin@bsd.cafe@… I have had no problem with 2.7.4.
If a problem persists: more detail will help, however Mastodon is not suitable for this type of thing. I should recommend <https://billboard.bsd.cafe/cat…
@penguin42@mastodon.org.ukFun, electrical activity in blobs of moss; spiking patterns!
https://royalsocietypublishing.org/rsos/article/13/7/252341/482568/Multi-scale-electrical-activity-and-signal
@raiders@darktundra.xyz2026 NFL Schedule Release: The 7 Biggest Winners — And 7 Biggest Losers https://www.foxsports.com/stories/nfl/2026-nfl-schedule-release-7-biggest-winners-7-biggest-losers
@berlinbuzzwords@floss.socialRadu Gheorghe and Rafał Kuć are joining #bbuzz26 to talk about ways to untangle it: lexical search, significant terms, training an embedder from scratch, etc.
Learn more about their amazing session: https://2026.berlinbuzzwords.de/session/circular-dependency-fixes-when-bootstrapping-a-golden-set/
Join us for Berlin Buzzwords on June 7-9 at Kulturbrauerei or online
 @heiseonline@social.heise.de
@heiseonline@social.heise.deEinige der zuletzt hier besonders häufig geteilten #News:
Anonymisierendes Linux Tails: Notfallupdate 7.7.3 fixt DirtyFrag-Lücke
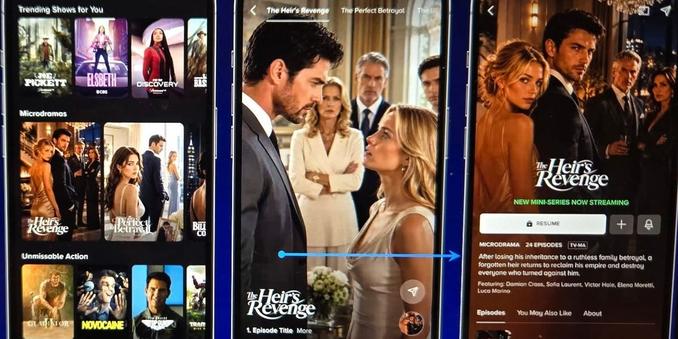
@Mediagazer@mstdn.socialSources: Paramount is planning to test adding micro dramas in its mobile app in the coming months to drive visit frequency and keep people engaged for longer (James Faris/Business Insider)
https://www.businessinsider.com/paramount-p…
@thesaigoneer@social.linux.pizza @kurtsh@mastodon.socialYeah, 8,000 layoffs & 7,000 internal transfers tend to piss people off.
✅ Meta AI Reshuffle Sparks Employee Morale Revolt
https://winbuzzer.com/2026/06/21/meta-ai-reshuffle-sparks-reported-employee-morale-revolt-xcxwbn/
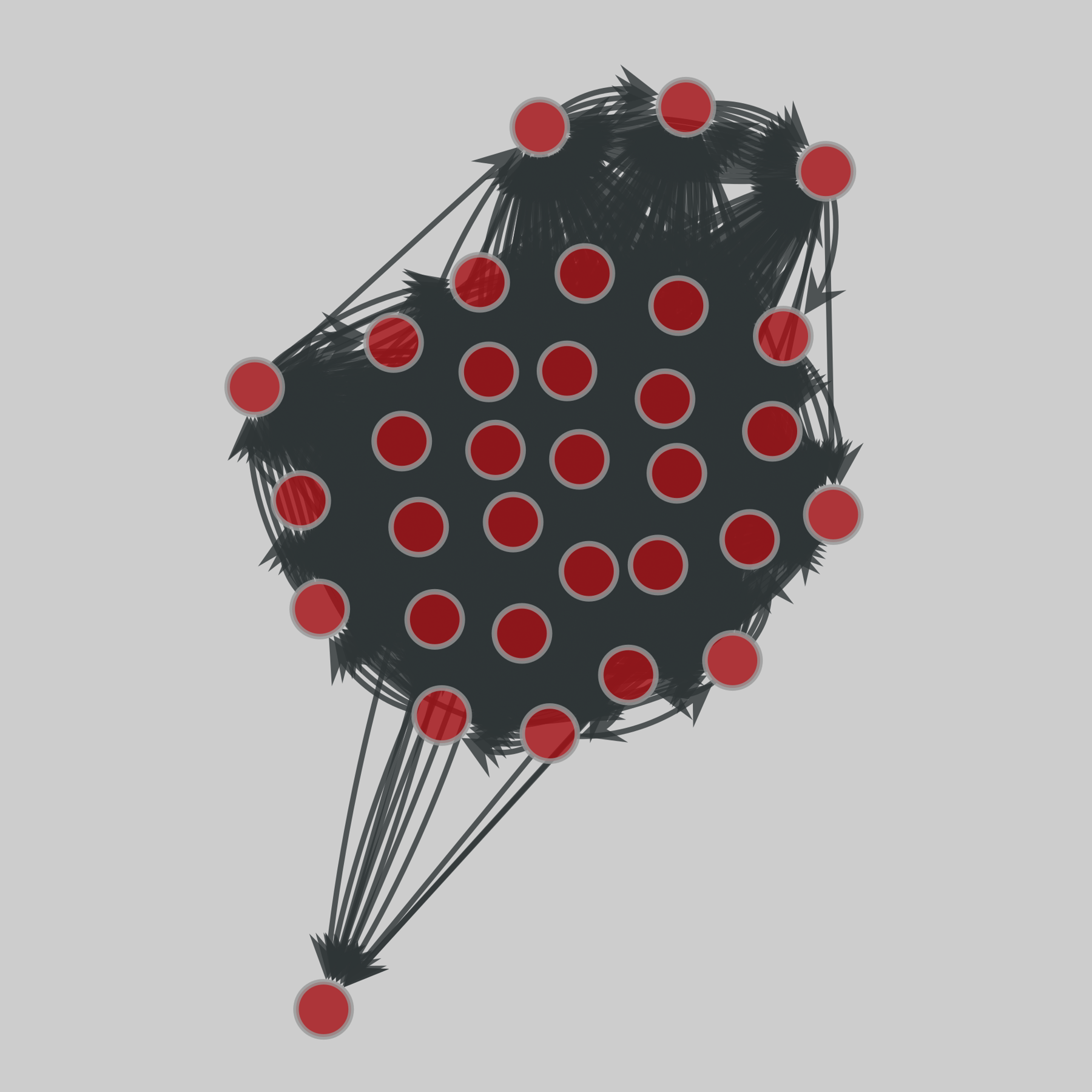
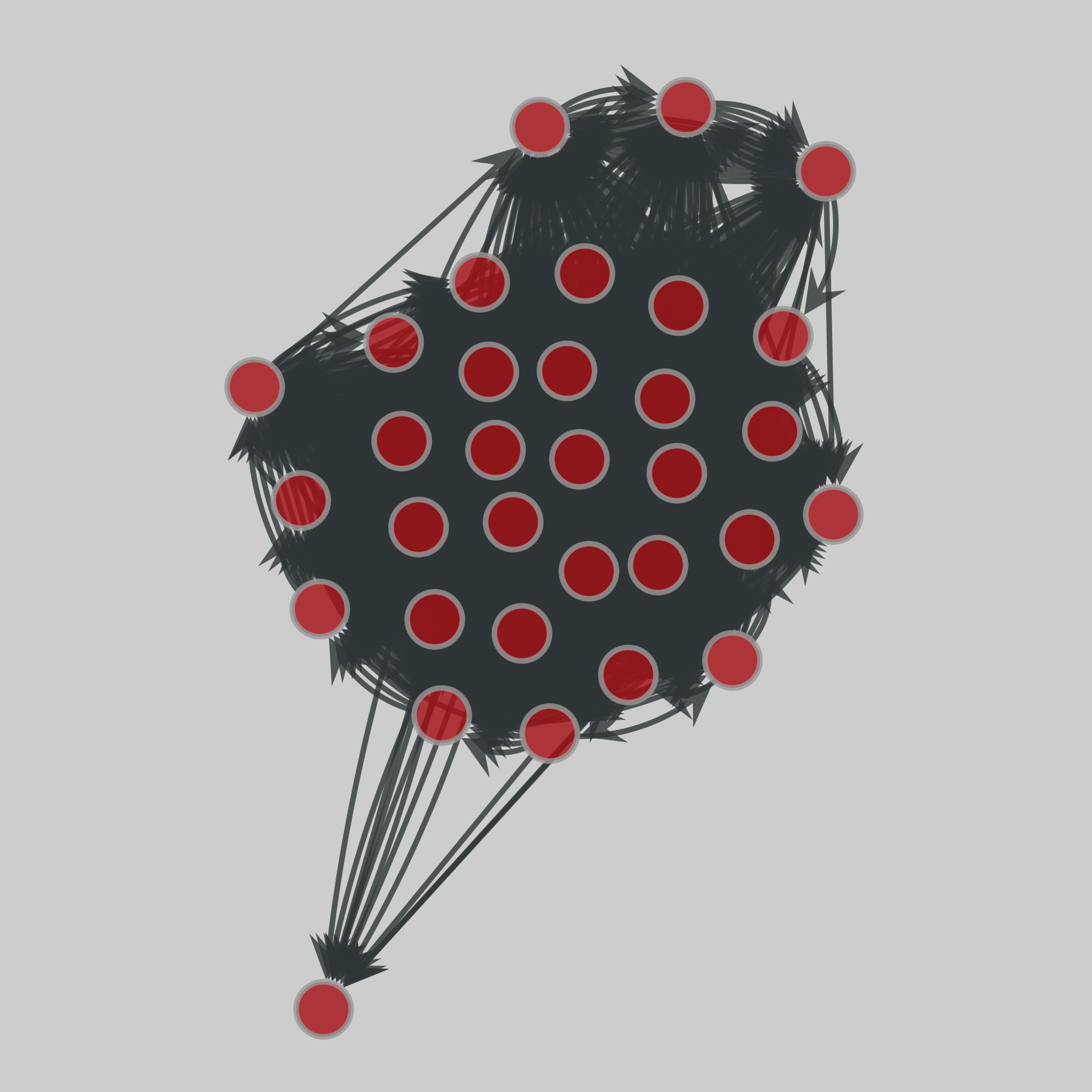
@netzschleuder@social.skewed.decollege_freshmen: Dutch college freshman (1995)
A small network of friendships among freshmen at Dutch College in 1994-1995. Friendship ties were surveyed at 7 different times over the year, and each edge is timestamped. The direction of an edge indicates that person i named person j, and the edge weight represents their level of friendship, ranging from -1 (risk of conflict) to 3 (best friend).
This network has 32 nodes and 3062 edges.
Tags: Social, Offline, Weighted, Tim…
 @cosmos4u@scicomm.xyz
@cosmos4u@scicomm.xyzDiscovery of #stromatolite formation in post-impact hydrothermal lacustrine environments and its implications for early Earth: #impact site reveals possible traces of early life: #life.
@CubitOom@social.linux.pizzaFascist Paramilitary Brutalize Our Neighbors and Send Them to Concentration Camps (100-30 40th Rd, Corona, NY, 7/23/26)
Source:
https://iceout.org/en/reportInfo/132503
(ffmpeg was used to combine the videos from the source into one with minimal quality loss)
 @krone@frawas.de
@krone@frawas.deBlutige Szenen - 46-Jährige wurde auf Straße geschlagen und gewürgt #News #Nachrichten
@Techmeme@techhub.socialDocs: OpenAI burned through $3.7B in Q1, on revenue of $5.7B, and ended the quarter with $73B in cash and marketable securities vs. $40B at the end of December (Erin Woo/The Information)
https://www.theinformation.com/articles/openai-burned-3-7-bill…
@heiseonline@social.heise.deNoch ein paar der zuletzt hier besonders häufig geteilten #News:
Anonymisierendes Linux Tails: Notfallupdate 7.7.3 fixt DirtyFrag-Lücke
@Techmeme@techhub.socialEli Lilly plans to use its $7.3B cash reserve to fund an "App Store" for biotech scientists after launching a data center with 1,016 Blackwell chips in 2025 (Patrick Temple-West/Financial Times)
https://www.ft.com/content/d524396a-4986-46e9-9a93-a982e330d157
@cdarwin@c.imThe Trump administration is advancing plans to resettle an additional 10,000 white South Africans in the United States as refugees.
Under Trump’s proposal, which was submitted to Congress on Monday, the U.S. would lift its record-low refugee admissions figure from 7,500 to 17,500,
with the additional openings reserved for Afrikaners.
This comes as the administration continues to block the entry of refugees from other countries.
The U.S. has resettled just over 6,000 …
@heiseonline@social.heise.deAndroid 17 QPR1: Google veröffentlicht Beta 7 mit Bugfixes
Google liefert nur zwei Wochen nach der Beta 6 das nächste Update für Android 17 QPR1 aus. Die Beta 7 fixt vornehmlich Bugs.
https://www.
@netzschleuder@social.skewed.decollege_freshmen: Dutch college freshman (1995)
A small network of friendships among freshmen at Dutch College in 1994-1995. Friendship ties were surveyed at 7 different times over the year, and each edge is timestamped. The direction of an edge indicates that person i named person j, and the edge weight represents their level of friendship, ranging from -1 (risk of conflict) to 3 (best friend).
This network has 32 nodes and 3062 edges.
Tags: Social, Offline, Weighted, Tim…
 @CubitOom@social.linux.pizza
@CubitOom@social.linux.pizzaFascists assult and abuduct man, he was confronting ICE for trying to abduct his neighbors (Passaic, NJ, 7/23/26)
Video made using these sources:
- https://iceout.org/en/reportInfo/132311
-
 @Techmeme@techhub.social
@Techmeme@techhub.socialSouth Korea's tech-heavy Kospi index falls 10%, dragged down by SK Hynix and Samsung; STMicro and ASML fall ~7%, and US tech stocks fall in pre-market trading (Chloe Taylor/CNBC)
https://www.cnbc.com/2026/06/23/tech-stocks-sell-off-mag7-samsung-sk-hynix.ht…
@heiseonline@social.heise.deNoch ein paar der zuletzt hier besonders häufig geteilten #News:
Anonymisierendes Linux Tails: Notfallupdate 7.7.3 fixt DirtyFrag-Lücke
@heiseonline@social.heise.deNoch ein paar der zuletzt hier besonders häufig geteilten #News:
Linux 7.1 mit neuem NTFS und FRED erschienen
https://www.
@Techmeme@techhub.socialSources: DeepSeek closed a $7.4B round at a $50B valuation under an unusual structure requiring investors to put capital into an LP run by CEO Liang Wenfeng (The Information)
https://www.theinformation.com/articles/deepseek-closes-…
@heiseonline@social.heise.de @heiseonline@social.heise.de„Civ 7“: Großes Update „Test of Time“ krempelt das Spiel um
Nach monatelangem Feinschliff steht das „Test of Time“-Update für „Civilization 7“ nun allen Spielern zum Download bereit. Es ist eine Art Neuanfang.
https…
@Techmeme@techhub.socialAlphabet stock fell as much as 7.2%, the most intraday since February, after Google DeepMind VP John Jumper became its second top AI exec to leave in a week (Felice Maranz/Bloomberg)
https://www.bloomberg.com/news/articles/2026…
@Techmeme@techhub.socialTencent's Hong Kong-listed shares fall ~7%, the most since April 2025, as investors worry over "rumors" of weaker earnings on August 12, and NetEase drops 5% (Bloomberg)
https://www.bloomberg.com/news/articles/20
@heiseonline@social.heise.deNoch ein paar der zuletzt hier besonders häufig geteilten #News:
FreeBSD 15.1: WiFi-Treiber von Linux 7.0, mehr Cloud und viel KI
@Techmeme@techhub.socialCognition releases SWE-1.7, trained from Kimi K2.7 and available at 1,000 tokens/second, claiming it nears GPT-5.5 and Opus 4.8 on benchmarks at a lower cost (Cognition)
https://cognition.com/blog/swe-1-7