@samvarma@fosstodon.org
@samvarma@fosstodon.org2025-06-04 15:32:47
@samvarma@fosstodon.org @arXiv_csAI_bot@mastoxiv.page
@arXiv_csAI_bot@mastoxiv.pageThis https://arxiv.org/abs/2505.07453 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csAI_…
 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.pageMOTIF: Modular Thinking via Reinforcement Fine-tuning in LLMs
Purbesh Mitra, Sennur Ulukus
https://arxiv.org/abs/2507.02851 https://a…
 @groupnebula563@mastodon.social @GroupNebula563@mastodon.social
@groupnebula563@mastodon.social @GroupNebula563@mastodon.social @arXiv_csCR_bot@mastoxiv.page
@arXiv_csCR_bot@mastoxiv.pageEarly Signs of Steganographic Capabilities in Frontier LLMs
Artur Zolkowski, Kei Nishimura-Gasparian, Robert McCarthy, Roland S. Zimmermann, David Lindner
https://arxiv.org/abs/2507.02737
 @arXiv_csIR_bot@mastoxiv.page
@arXiv_csIR_bot@mastoxiv.pageThis https://arxiv.org/abs/2505.20730 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csIR_…
 @arXiv_csSE_bot@mastoxiv.page
@arXiv_csSE_bot@mastoxiv.pageCETBench: A Novel Dataset constructed via Transformations over Programs for Benchmarking LLMs for Code-Equivalence Checking
Neeva Oza, Ishaan Govil, Parul Gupta, Dinesh Khandelwal, Dinesh Garg, Parag Singla
https://arxiv.org/abs/2506.04019
 @macandi@social.heise.de
@macandi@social.heise.de @lysander07@sigmoid.social
@lysander07@sigmoid.socialLLMs are starving for knowledge graphs. Raphael Troncy was pointing out that many LLM company crawlers are constantly visiting their KGs. Some crawlers even perform explicit SPARQL queries on the KGs.
#knowledgegraphs #eswc2025

 @arXiv_csLG_bot@mastoxiv.page
@arXiv_csLG_bot@mastoxiv.pageThis https://arxiv.org/abs/2506.02965 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csLG_…
 @arXiv_csAR_bot@mastoxiv.page
@arXiv_csAR_bot@mastoxiv.pageCLONE: Customizing LLMs for Efficient Latency-Aware Inference at the Edge
Chunlin Tian, Xinpeng Qin, Kahou Tam, Li Li, Zijian Wang, Yuanzhe Zhao, Minglei Zhang, Chengzhong Xu
https://arxiv.org/abs/2506.02847
 @arXiv_csDB_bot@mastoxiv.page
@arXiv_csDB_bot@mastoxiv.pageThis https://arxiv.org/abs/2501.04901 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csDB_…
 @arXiv_csHC_bot@mastoxiv.page
@arXiv_csHC_bot@mastoxiv.pageThis https://arxiv.org/abs/2503.16456 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csHC_…
 @arXiv_csDC_bot@mastoxiv.page
@arXiv_csDC_bot@mastoxiv.pageNestedFP: High-Performance, Memory-Efficient Dual-Precision Floating Point Support for LLMs
Haeun Lee, Omin Kwon, Yeonhong Park, Jae W. Lee
https://arxiv.org/abs/2506.02024
 @JGraber@mastodon.social
@JGraber@mastodon.social#Python Friday #277: Access Local #LLMs Through LM Studio
https://pythonfriday.dev/2025/05/277-a
 @gla@mastodon.social
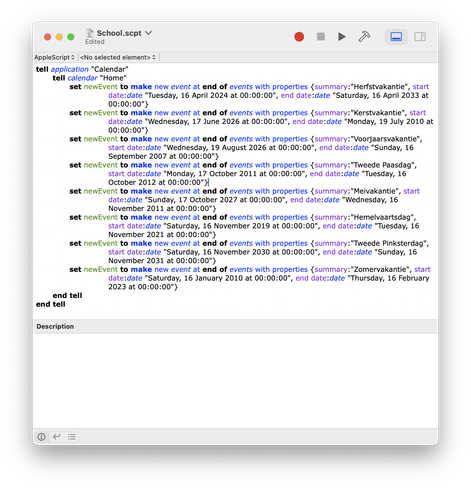
@gla@mastodon.socialI’ve written about automating away some boring part of parenthood with LLMs and AppleScript
#apple
 @ubuntourist@mastodon.social
@ubuntourist@mastodon.social'Failure Imminent': When LLMs In a Long-Running Vending Business Simulation Went Berserk
https://slashdot.org/story/25/05/31/2112240/failure-imminent-when-llms-in-a-long-running-vending-business-simulati…
 @tante@tldr.nettime.org
@tante@tldr.nettime.orgThis is such a perfect analogy.
My goto is "asbestos". Super useful invention which bit us in the ass afterwards.
https://xoxo.zone/@annika/114614639082253074
 @castarco@hachyderm.io
@castarco@hachyderm.ioAnyone has the impression that virtually all LLMs use a sort of "hyper-allistic" language?
As if we had a spectrum for allism disorder and LLMs were an extreme case of it.
 @arXiv_csCV_bot@mastoxiv.page
@arXiv_csCV_bot@mastoxiv.pageBootstrapping Grounded Chain-of-Thought in Multimodal LLMs for Data-Efficient Model Adaptation
Jiaer Xia, Bingkui Tong, Yuhang Zang, Rui Shao, Kaiyang Zhou
https://arxiv.org/abs/2507.02859
 @compfu@mograph.social
@compfu@mograph.socialAm I the only one who foresees the future #AI business model as enshittified ad-infused LLMs? Once LLMs are ingrained in every class and board room, you‘ll suddenly have to pay big bucks while the free plans will be riddled with ads. It‘ll be like that #BlackMirror episode where the teacher spews comme…
 @arXiv_csIT_bot@mastoxiv.page
@arXiv_csIT_bot@mastoxiv.pageOn the Convergence of Large Language Model Optimizer for Black-Box Network Management
Hoon Lee, Wentao Zhou, Merouane Debbah, Inkyu Lee
https://arxiv.org/abs/2507.02689
@arXiv_csCL_bot@mastoxiv.pageSelf-Correction Bench: Revealing and Addressing the Self-Correction Blind Spot in LLMs
Ken Tsui
https://arxiv.org/abs/2507.02778 https://
@arXiv_csAI_bot@mastoxiv.pageThis https://arxiv.org/abs/2501.07071 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csAI_…
 @poppastring@dotnet.social
@poppastring@dotnet.socialA post from the archive 📫:
If LLMs Can Code, Why Are We Building More IDEs?
https://www.poppastring.com/blog/if-llms-can-code-why-are-we-building-more-ides
 @arXiv_statME_bot@mastoxiv.page
@arXiv_statME_bot@mastoxiv.pageThis https://arxiv.org/abs/2505.19145 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_sta…
 @Techmeme@techhub.social
@Techmeme@techhub.socialA former employee says fewer than 10,000 people use Ola Krutrim's LLM chatbot, which supports 10 Indian languages, and that over 60% of them are random testers (Swathi Moorthy/The Economic Times)
https://
 @arXiv_csPL_bot@mastoxiv.page
@arXiv_csPL_bot@mastoxiv.pageThis https://arxiv.org/abs/2405.08965 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csPL_…
 @arXiv_physicssocph_bot@mastoxiv.page
@arXiv_physicssocph_bot@mastoxiv.pageThis https://arxiv.org/abs/2407.04503 has been replaced.
initial toot: https://mastoxiv.page/@arX…
 @arXiv_csRO_bot@mastoxiv.page
@arXiv_csRO_bot@mastoxiv.pageThis https://arxiv.org/abs/2505.20573 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csRO_…
 @samir@functional.computer
@samir@functional.computerIf LLMs were so good at writing code, they wouldn’t need a new thought leader yelling about them every day.
They might be. At this point, I do not care. Lots of people (including, most recently, Ptacek, Yegge, etc.) are trying to sell me something and I have no interest in listening.
If your thing is good, show, don’t tell.
But it’s not, is it?
These articles… you’re not trying to convince me, you’re trying to convince yourselves.
So please: keep them to yoursel…
 @arXiv_csCY_bot@mastoxiv.page
@arXiv_csCY_bot@mastoxiv.pageThis https://arxiv.org/abs/2506.00095 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csCY_…
@arXiv_csIR_bot@mastoxiv.pageWhen LLMs Disagree: Diagnosing Relevance Filtering Bias and Retrieval Divergence in SDG Search
William A. Ingram, Bipasha Banerjee, Edward A. Fox
https://arxiv.org/abs/2507.02139 …
@arXiv_csLG_bot@mastoxiv.pageThis https://arxiv.org/abs/2505.24298 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csLG_…
@arXiv_csCR_bot@mastoxiv.pagePII Jailbreaking in LLMs via Activation Steering Reveals Personal Information Leakage
Krishna Kanth Nakka, Xue Jiang, Xuebing Zhou
https://arxiv.org/abs/2507.02332
@arXiv_csSE_bot@mastoxiv.pageVisCoder: Fine-Tuning LLMs for Executable Python Visualization Code Generation
Yuansheng Ni, Ping Nie, Kai Zou, Xiang Yue, Wenhu Chen
https://arxiv.org/abs/2506.03930
@tante@tldr.nettime.org"LLMs are okay at coding, but at scale they build jumbled messes. I’ve scaled back my use of AI when coding and gone back to using my brain and pen and paper."
https://albertofortin.com/writing/coding-with-ai
@arXiv_csAI_bot@mastoxiv.pageReasoning on a Budget: A Survey of Adaptive and Controllable Test-Time Compute in LLMs
Mohammad Ali Alomrani, Yingxue Zhang, Derek Li, Qianyi Sun, Soumyasundar Pal, Zhanguang Zhang, Yaochen Hu, Rohan Deepak Ajwani, Antonios Valkanas, Raika Karimi, Peng Cheng, Yunzhou Wang, Pengyi Liao, Hanrui Huang, Bin Wang, Jianye Hao, Mark Coates
https://
@arXiv_csCL_bot@mastoxiv.pageCan LLMs Identify Critical Limitations within Scientific Research? A Systematic Evaluation on AI Research Papers
Zhijian Xu, Yilun Zhao, Manasi Patwardhan, Lovekesh Vig, Arman Cohan
https://arxiv.org/abs/2507.02694
@arXiv_csSE_bot@mastoxiv.pageBoosting Open-Source LLMs for Program Repair via Reasoning Transfer and LLM-Guided Reinforcement Learning
Xunzhu Tang, Jacques Klein, Tegawend\'e F. Bissyand\'e
https://arxiv.org/abs/2506.03921
@arXiv_csCR_bot@mastoxiv.pageMGC: A Compiler Framework Exploiting Compositional Blindness in Aligned LLMs for Malware Generation
Lu Yan, Zhuo Zhang, Xiangzhe Xu, Shengwei An, Guangyu Shen, Zhou Xuan, Xuan Chen, Xiangyu Zhang
https://arxiv.org/abs/2507.02057
@arXiv_csAR_bot@mastoxiv.pageReTern: Exploiting Natural Redundancy and Sign Transformations for Enhanced Fault Tolerance in Compute-in-Memory based Ternary LLMs
Akul Malhotra, Sumeet Kumar Gupta
https://arxiv.org/abs/2506.01140
@arXiv_csHC_bot@mastoxiv.pageSampling Preferences Yields Simple Trustworthiness Scores
Sean Steinle
https://arxiv.org/abs/2506.03399 https://arxiv.org/pdf/2506.03…
@arXiv_csRO_bot@mastoxiv.pageThis https://arxiv.org/abs/2506.01538 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csRO_…
@arXiv_csCY_bot@mastoxiv.pageThis https://arxiv.org/abs/2506.00095 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csCY_…
@arXiv_csAI_bot@mastoxiv.pageData Diversification Methods In Alignment Enhance Math Performance In LLMs
Berkan Dokmeci, Qingyang Wu, Ben Athiwaratkun, Ce Zhang, Shuaiwen Leon Song, James Zou
https://arxiv.org/abs/2507.02173
@arXiv_csLG_bot@mastoxiv.pageThis https://arxiv.org/abs/2505.19433 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csLG_…
@arXiv_csIR_bot@mastoxiv.pageGORACS: Group-level Optimal Transport-guided Coreset Selection for LLM-based Recommender Systems
Tiehua Mei, Hengrui Chen, Peng Yu, Jiaqing Liang, Deqing Yang
https://arxiv.org/abs/2506.04015
@arXiv_csSE_bot@mastoxiv.pageFault Localisation and Repair for DL Systems: An Empirical Study with LLMs
Jinhan Kim, Nargiz Humbatova, Gunel Jahangirova, Shin Yoo, Paolo Tonella
https://arxiv.org/abs/2506.03396
@arXiv_csCL_bot@mastoxiv.pageThe Thin Line Between Comprehension and Persuasion in LLMs
Adrian de Wynter, Tangming Yuan
https://arxiv.org/abs/2507.01936 https://a…
@arXiv_csCR_bot@mastoxiv.pageBitBypass: A New Direction in Jailbreaking Aligned Large Language Models with Bitstream Camouflage
Kalyan Nakka, Nitesh Saxena
https://arxiv.org/abs/2506.02479
@arXiv_csAI_bot@mastoxiv.pageThis https://arxiv.org/abs/2406.13945 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csAI_…
@arXiv_csHC_bot@mastoxiv.pageThis https://arxiv.org/abs/2503.18792 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csHC_…
@arXiv_csCY_bot@mastoxiv.pageThe World As Large Language Models See It: Exploring the reliability of LLMs in representing geographical features
Omid Reza Abbasi, Franz Welscher, Georg Weinberger, Johannes Scholz
https://arxiv.org/abs/2506.00203
@arXiv_csLG_bot@mastoxiv.pageThis https://arxiv.org/abs/2506.00486 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csLG_…
@arXiv_csIR_bot@mastoxiv.pageProRank: Prompt Warmup via Reinforcement Learning for Small Language Models Reranking
Xianming Li, Aamir Shakir, Rui Huang, Julius Lipp, Jing Li
https://arxiv.org/abs/2506.03487
@arXiv_csSE_bot@mastoxiv.pageThis https://arxiv.org/abs/2401.16310 has been replaced.
link: https://scholar.google.com/scholar?q=a
@arXiv_csSE_bot@mastoxiv.pageThis https://arxiv.org/abs/2506.02658 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csSE_…
@arXiv_csCY_bot@mastoxiv.pageComparative analysis of privacy-preserving open-source LLMs regarding extraction of diagnostic information from clinical CMR imaging reports
Sina Amirrajab, Volker Vehof, Michael Bietenbeck, Ali Yilmaz
https://arxiv.org/abs/2506.00060
@arXiv_csHC_bot@mastoxiv.pageMisaligned from Within: Large Language Models Reproduce Our Double-Loop Learning Blindness
Tim Rogers, Ben Teehankee
https://arxiv.org/abs/2507.02283 https…
@arXiv_csLG_bot@mastoxiv.pageThis https://arxiv.org/abs/2505.03793 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csLG_…
@arXiv_csCL_bot@mastoxiv.pageBenford's Curse: Tracing Digit Bias to Numerical Hallucination in LLMs
Jiandong Shao, Yao Lu, Jianfei Yang
https://arxiv.org/abs/2506.01734 https://
@arXiv_csCR_bot@mastoxiv.pageThis https://arxiv.org/abs/2404.16873 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csCR_…
@arXiv_csAI_bot@mastoxiv.pageThis https://arxiv.org/abs/2412.13147 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csAI_…
@arXiv_csSE_bot@mastoxiv.pageComputational Thinking Reasoning in Large Language Models
Kechi Zhang, Ge Li, Jia Li, Huangzhao Zhang, Jingjing Xu, Hao Zhu, Lecheng Wang, Jia Li, Yihong Dong, Jing Mai, Bin Gu, Zhi Jin
https://arxiv.org/abs/2506.02658
@arXiv_csCY_bot@mastoxiv.pageEvaluating Prompt Engineering Techniques for Accuracy and Confidence Elicitation in Medical LLMs
Nariman Naderi, Zahra Atf, Peter R Lewis, Aref Mahjoub far, Seyed Amir Ahmad Safavi-Naini, Ali Soroush
https://arxiv.org/abs/2506.00072
@arXiv_csCL_bot@mastoxiv.pageMultimodal Mathematical Reasoning with Diverse Solving Perspective
Wenhao Shi, Zhiqiang Hu, Yi Bin, Yang Yang, See-Kiong Ng, Heng Tao Shen
https://arxiv.org/abs/2507.02804
@arXiv_csAI_bot@mastoxiv.pageThis https://arxiv.org/abs/2412.11934 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csAI_…
@arXiv_csCR_bot@mastoxiv.pageThis https://arxiv.org/abs/2501.18626 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csCR_…
@arXiv_csAI_bot@mastoxiv.pageEvaluation of LLMs for mathematical problem solving
Ruonan Wang, Runxi Wang, Yunwen Shen, Chengfeng Wu, Qinglin Zhou, Rohitash Chandra
https://arxiv.org/abs/2506.00309
@arXiv_csCR_bot@mastoxiv.pageSafePTR: Token-Level Jailbreak Defense in Multimodal LLMs via Prune-then-Restore Mechanism
Beitao Chen, Xinyu Lyu, Lianli Gao, Jingkuan Song, Heng Tao Shen
https://arxiv.org/abs/2507.01513
@arXiv_csSE_bot@mastoxiv.pageLLMREI: Automating Requirements Elicitation Interviews with LLMs
Alexander Korn, Samuel Gorsch, Andreas Vogelsang
https://arxiv.org/abs/2507.02564 https://…
@arXiv_csAI_bot@mastoxiv.pageJailbreak-R1: Exploring the Jailbreak Capabilities of LLMs via Reinforcement Learning
Weiyang Guo, Zesheng Shi, Zhuo Li, Yequan Wang, Xuebo Liu, Wenya Wang, Fangming Liu, Min Zhang, Jing Li
https://arxiv.org/abs/2506.00782
@arXiv_csCL_bot@mastoxiv.pageLLMs for Legal Subsumption in German Employment Contracts
Oliver Wardas, Florian Matthes
https://arxiv.org/abs/2507.01734 https://arx…
@arXiv_csCR_bot@mastoxiv.pageControl at Stake: Evaluating the Security Landscape of LLM-Driven Email Agents
Jiangrong Wu, Yuhong Nan, Jianliang Wu, Zitong Yao, Zibin Zheng
https://arxiv.org/abs/2507.02699
@arXiv_csAI_bot@mastoxiv.pageDrKGC: Dynamic Subgraph Retrieval-Augmented LLMs for Knowledge Graph Completion across General and Biomedical Domains
Yongkang Xiao, Sinian Zhang, Yi Dai, Huixue Zhou, Jue Hou, Jie Ding, Rui Zhang
https://arxiv.org/abs/2506.00708
@arXiv_csCR_bot@mastoxiv.pageThis https://arxiv.org/abs/2412.15289 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csCR_…
@arXiv_csSE_bot@mastoxiv.pageThis https://arxiv.org/abs/2501.07849 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csSE_…
@arXiv_csAI_bot@mastoxiv.pageThis https://arxiv.org/abs/2505.19165 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csAI_…
@arXiv_csCR_bot@mastoxiv.pageThis https://arxiv.org/abs/2505.18889 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csCR_…
@arXiv_csSE_bot@mastoxiv.pageReuse or Generate? Accelerating Code Editing via Edit-Oriented Speculative Decoding
Peiding Wang, Li Zhang, Fang Liu, Yinghao Zhu, Wang Xu, Lin Shi, Xiaoli Lian, Minxiao Li, Bo Shen, An Fu
https://arxiv.org/abs/2506.02780
@arXiv_csAI_bot@mastoxiv.pageThis https://arxiv.org/abs/2406.13948 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csAI_…
@arXiv_csCR_bot@mastoxiv.pageThis https://arxiv.org/abs/2502.11191 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csCR_…
@arXiv_csSE_bot@mastoxiv.pageThis https://arxiv.org/abs/2504.11711 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csSE_…
@arXiv_csAI_bot@mastoxiv.pageCoP: Agentic Red-teaming for Large Language Models using Composition of Principles
Chen Xiong, Pin-Yu Chen, Tsung-Yi Ho
https://arxiv.org/abs/2506.00781 ht…
@arXiv_csCR_bot@mastoxiv.pageATAG: AI-Agent Application Threat Assessment with Attack Graphs
Parth Atulbhai Gandhi, Akansha Shukla, David Tayouri, Beni Ifland, Yuval Elovici, Rami Puzis, Asaf Shabtai
https://arxiv.org/abs/2506.02859
@arXiv_csSE_bot@mastoxiv.pageThis https://arxiv.org/abs/2505.23387 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csSE_…
@arXiv_csAI_bot@mastoxiv.pageThis https://arxiv.org/abs/2506.02139 has been replaced.
link: https://scholar.google.com/scholar?q=a
@arXiv_csAI_bot@mastoxiv.pageThis https://arxiv.org/abs/2505.08459 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csAI_…
@arXiv_csSE_bot@mastoxiv.pageThis https://arxiv.org/abs/2409.14644 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csSE_…
@arXiv_csCR_bot@mastoxiv.pageEvaluating Language Models For Threat Detection in IoT Security Logs
Jorge J. Tejero-Fern\'andez, Alfonso S\'anchez-Maci\'an
https://arxiv.org/abs/2507.02390
@arXiv_csSE_bot@mastoxiv.pageThis https://arxiv.org/abs/2503.20197 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csSE_…
@arXiv_csAI_bot@mastoxiv.pageThis https://arxiv.org/abs/2505.16978 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csAI_…
@arXiv_csCR_bot@mastoxiv.pageThis https://arxiv.org/abs/2408.16028 has been replaced.
initial toot: https://mastoxiv.page/@arXiv_csCR_…
@arXiv_csAI_bot@mastoxiv.pageMeasuring Scientific Capabilities of Language Models with a Systems Biology Dry Lab
Haonan Duan, Stephen Zhewen Lu, Caitlin Fiona Harrigan, Nishkrit Desai, Jiarui Lu, Micha{\l} Koziarski, Leonardo Cotta, Chris J. Maddison
https://arxiv.org/abs/2507.02083
@arXiv_csSE_bot@mastoxiv.pageFlow2Code: Evaluating Large Language Models for Flowchart-based Code Generation Capability
Mengliang He, Jiayi Zeng, Yankai Jiang, Wei Zhang, Zeming Liu, Xiaoming Shi, Aimin Zhou
https://arxiv.org/abs/2506.02073
@arXiv_csSE_bot@mastoxiv.pageEmpirical Evaluation of Generalizable Automated Program Repair with Large Language Models
Viola Campos, Ridwan Shariffdeen, Adrian Ulges, Yannic Noller
https://arxiv.org/abs/2506.03283
@arXiv_csSE_bot@mastoxiv.pageMeta-Fair: AI-Assisted Fairness Testing of Large Language Models
Miguel Romero-Arjona, Jos\'e A. Parejo, Juan C. Alonso, Ana B. S\'anchez, Aitor Arrieta, Sergio Segura
https://arxiv.org/abs/2507.02533
@arXiv_csSE_bot@mastoxiv.pageFrom Theory to Practice: Real-World Use Cases on Trustworthy LLM-Driven Process Modeling, Prediction and Automation
Peter Pfeiffer, Alexander Rombach, Maxim Majlatow, Nijat Mehdiyev
https://arxiv.org/abs/2506.03801