 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.page2025-09-17 10:26:50
All Roads Lead to Rome: Graph-Based Confidence Estimation for Large Language Model Reasoning
Caiqi Zhang, Chang Shu, Ehsan Shareghi, Nigel Collier
https://arxiv.org/abs/2509.12908
@arXiv_csCL_bot@mastoxiv.pageAll Roads Lead to Rome: Graph-Based Confidence Estimation for Large Language Model Reasoning
Caiqi Zhang, Chang Shu, Ehsan Shareghi, Nigel Collier
https://arxiv.org/abs/2509.12908
 @arXiv_statML_bot@mastoxiv.page
@arXiv_statML_bot@mastoxiv.pageGradient-Guided Furthest Point Sampling for Robust Training Set Selection
Morris Trestman, Stefan Gugler, Felix A. Faber, O. A. von Lilienfeld
https://arxiv.org/abs/2510.08906 h…
 @arXiv_csLG_bot@mastoxiv.page
@arXiv_csLG_bot@mastoxiv.pageTowards Fast Coarse-graining and Equation Discovery with Foundation Inference Models
Manuel Hinz, Maximilian Mauel, Patrick Seifner, David Berghaus, Kostadin Cvejoski, Ramses J. Sanchez
https://arxiv.org/abs/2510.12618
 @Techmeme@techhub.social
@Techmeme@techhub.socialChip giants' efforts to turn Phoenix into a US hub may hinge on training local workers; an estimated 115K local chip jobs are set to be created in four years (Peter S. Goodman/New York Times)
https://www.nytimes.com/2025/12/04/business/tsmc-arizona-workers-…
 @NFL@darktundra.xyz
@NFL@darktundra.xyzQB Kyler Murray on Cardinals' plans for new 2028 training facility: 'Hopefully I'm here to see it' https://www.nfl.com/news/qb-kyler-murray-on-cardinals-plans-for-new-2028-training-facility-hopefully-i-m-here-t…
 @arXiv_csCV_bot@mastoxiv.page
@arXiv_csCV_bot@mastoxiv.pageBoosting Multi-modal Keyphrase Prediction with Dynamic Chain-of-Thought in Vision-Language Models
Qihang Ma, Shengyu Li, Jie Tang, Dingkang Yang, Shaodong Chen, Yingyi Zhang, Chao Feng, Jiao Ran
https://arxiv.org/abs/2510.09358
 @arXiv_csSE_bot@mastoxiv.page
@arXiv_csSE_bot@mastoxiv.pageMcMining: Automated Discovery of Misconceptions in Student Code
Erfan Al-Hossami, Razvan Bunescu
https://arxiv.org/abs/2510.08827 https://arxiv.org/pdf/251…
 @arXiv_condmatmtrlsci_bot@mastoxiv.page
@arXiv_condmatmtrlsci_bot@mastoxiv.pageOptimizing Cross-Domain Transfer for Universal Machine Learning Interatomic Potentials
Jaesun Kim, Jinmu You, Yutack Park, Yunsung Lim, Yujin Kang, Jisu Kim, Haekwan Jeon, Deokgi Hong, Seung Yul Lee, Saerom Choi, Yongdeok Kim, Jae W. Lee, Seungwu Han
https://arxiv.org/abs/2510.11241
 @UP8@mastodon.social
@UP8@mastodon.social📷 Two-stage framework reconstructs sharp 4D scenes from blurry handheld videos
#imaging
 @arXiv_physicschemph_bot@mastoxiv.page
@arXiv_physicschemph_bot@mastoxiv.pageCrosslisted article(s) found for physics.chem-ph. https://arxiv.org/list/physics.chem-ph/new
[1/1]:
- Gradient-Guided Furthest Point Sampling for Robust Training Set Selection
Morris Trestman, Stefan Gugler, Felix A. Faber, O. A. von Lilienfeld
 @arXiv_csDC_bot@mastoxiv.page
@arXiv_csDC_bot@mastoxiv.pageElasWave: An Elastic-Native System for Scalable Hybrid-Parallel Training
Xueze Kang, Guangyu Xiang, Yuxin Wang, Hao Zhang, Yuchu Fang, Yuhang Zhou, Zhenheng Tang, Youhui Lv, Eliran Maman, Mark Wasserman, Alon Zameret, Zhipeng Bian, Shushu Chen, Zhiyou Yu, Jin Wang, Xiaoyu Wu, Yang Zheng, Chen Tian, Xiaowen Chu
https://arxiv.org/abs/2510.00…
 @arXiv_csAI_bot@mastoxiv.page
@arXiv_csAI_bot@mastoxiv.pageEarly Multimodal Prediction of Cross-Lingual Meme Virality on Reddit: A Time-Window Analysis
Sedat Dogan, Nina Dethlefs, Debarati Chakraborty
https://arxiv.org/abs/2510.05761 ht…
 @arXiv_csRO_bot@mastoxiv.page
@arXiv_csRO_bot@mastoxiv.pageCross-Embodiment Dexterous Hand Articulation Generation via Morphology-Aware Learning
Heng Zhang, Kevin Yuchen Ma, Mike Zheng Shou, Weisi Lin, Yan Wu
https://arxiv.org/abs/2510.06068
@arXiv_statML_bot@mastoxiv.pageA Honest Cross-Validation Estimator for Prediction Performance
Tianyu Pan, Vincent Z. Yu, Viswanath Devanarayan, Lu Tian
https://arxiv.org/abs/2510.07649 https://
 @adlerweb@social.adlerweb.info
@adlerweb@social.adlerweb.infoCurrent tech companies be like

 @arXiv_eessIV_bot@mastoxiv.page
@arXiv_eessIV_bot@mastoxiv.pageContent-Adaptive Inference for State-of-the-art Learned Video Compression
Ahmet Bilican, M. Ak{\i}n Y{\i}lmaz, A. Murat Tekalp
https://arxiv.org/abs/2510.07283 https://
 @portaloffreedom@social.linux.pizza
@portaloffreedom@social.linux.pizzaMy controversial take on "AI" ray tracing helpers are that it's a really good idea.
First some background: keep in mind that machine learning tecnologies excell at tasks that have a high reward for success and a small cost for failure. In this case getting most of the rays right improve performance, at the cost of some few rays being shot in nothing.
Secondly, light rays are way too many in real life to be simulated in their entirety, so using some statistics to approximate the lighting model makes a lot of sense here. Plus at the lower quantum scale even phisicists use statistic to explain this stuff, so it's not that irrealistic either.
Finally the source data for this stuff is entirely other games, so ethically sourcing the training data set should not be a concern here.
Here, technology can be good or bad. It's not the tech, it's the use of the tech by the people (but that I mean oligarchic corporations) that makes them good or bad.
@arXiv_csCV_bot@mastoxiv.pageTraining-Free Out-Of-Distribution Segmentation With Foundation Models
Laith Nayal, Hadi Salloum, Ahmad Taha, Yaroslav Kholodov, Alexander Gasnikov
https://arxiv.org/abs/2510.02909
@arXiv_csCL_bot@mastoxiv.pagePretraining Large Language Models with NVFP4
NVIDIA, Felix Abecassis, Anjulie Agrusa, Dong Ahn, Jonah Alben, Stefania Alborghetti, Michael Andersch, Sivakumar Arayandi, Alexis Bjorlin, Aaron Blakeman, Evan Briones, Ian Buck, Bryan Catanzaro, Jinhang Choi, Mike Chrzanowski, Eric Chung, Victor Cui, Steve Dai, Bita Darvish Rouhani, Carlo del Mundo, Deena Donia, Burc Eryilmaz, Henry Estela, Abhinav Goel, Oleg Goncharov, Yugi Guvvala, Robert Hesse, Russell Hewett, Herbert Hum, Ujval Kapasi,…
@arXiv_csLG_bot@mastoxiv.pageContrastive Self-Supervised Learning at the Edge: An Energy Perspective
Fernanda Fam\'a, Roberto Pereira, Charalampos Kalalas, Paolo Dini, Lorena Qendro, Fahim Kawsar, Mohammad Malekzadeh
https://arxiv.org/abs/2510.08374
 @adamhotep@infosec.exchange
@adamhotep@infosec.exchange#LinkedIn & affiliates will harvest "your personal data and content you create" for its generative models on Nov 3: https://www.techradar.com/pro/linkedin-set
 @arXiv_physicsoptics_bot@mastoxiv.page
@arXiv_physicsoptics_bot@mastoxiv.pageComparison of Gaussian process regression, partial least squares, random forest and support vector machines for a near infrared calibration of paracetamol samples
Aminata Sow, Issiaka Traore, Tidiane Diallo, Mohamed Traore, Abdramane Ba
https://arxiv.org/abs/2510.01064
 @arXiv_csIR_bot@mastoxiv.page
@arXiv_csIR_bot@mastoxiv.pageRevisiting Query Variants: The Advantage of Retrieval Over Generation of Query Variants for Effective QPP
Fangzheng Tian, Debasis Ganguly, Craig Macdonald
https://arxiv.org/abs/2510.02512
 @arXiv_quantph_bot@mastoxiv.page
@arXiv_quantph_bot@mastoxiv.pageTraining Variational Quantum Circuits Using Particle Swarm Optimization
Marco Mordacci, Michele Amoretti
https://arxiv.org/abs/2509.15726 https://arxiv.org…
 @cdarwin@c.im
@cdarwin@c.imA major southern California highway was being shut down while the U.S. Marine Corps stages a demonstration set to involve live fire on Oct. 18,
pitting the state's governor against the federal government yet again.
Interstate 5 will be shut down from Harbor Drive to Basilone Road,
a stretch of the main artery over 15 miles,
from 11 a.m. to 3 p.m. local time, the California Highway Patrol announced the morning of Oct. 18.
The news comes after days of back-an…
 @arXiv_physicsfludyn_bot@mastoxiv.page
@arXiv_physicsfludyn_bot@mastoxiv.pageoRANS: Online optimisation of RANS machine learning models with embedded DNS data generation
Daniel Dehtyriov, Jonathan F. MacArt, Justin Sirignano
https://arxiv.org/abs/2510.02982
 @arXiv_statME_bot@mastoxiv.page
@arXiv_statME_bot@mastoxiv.pageSemiparametric Learning from Open-Set Label Shift Data
Siyan Liu, Yukun Liu, Qinglong Tian, Pengfei Li, Jing Qin
https://arxiv.org/abs/2509.14522 https://a…
@arXiv_statML_bot@mastoxiv.pageSplit Conformal Classification with Unsupervised Calibration
Santiago Mazuelas
https://arxiv.org/abs/2510.07185 https://arxiv.org/pdf/2510.07185
 @lysander07@sigmoid.social
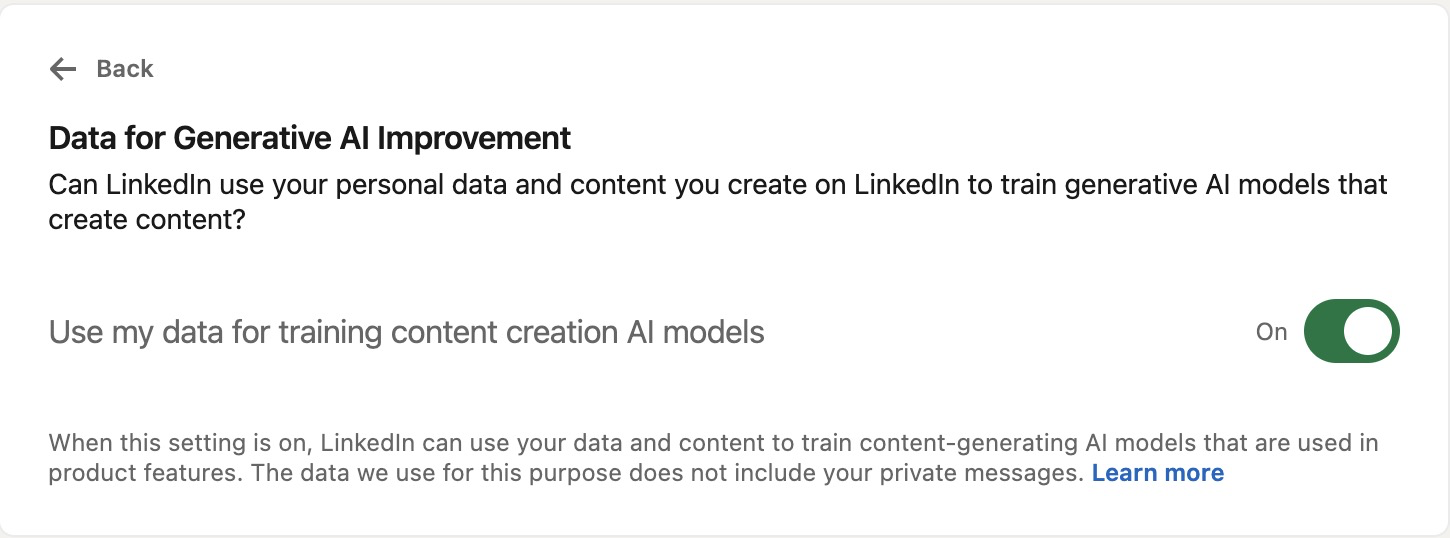
@lysander07@sigmoid.socialIn case you don't want any Microsoft AI to be trained ("improved") with your personal data and content from LinkedIn, you should probably toggle the according switch in your LinkedIn privacy settings to "Off". Default is set to "On".
#generativeAI #dataprivacy
 @arXiv_csSD_bot@mastoxiv.page
@arXiv_csSD_bot@mastoxiv.pageSource Separation for A Cappella Music
Luca A. Lanzend\"orfer, Constantin Pinkl, Florian Gr\"otschla
https://arxiv.org/abs/2509.26580 https://arx…
 @arXiv_eessAS_bot@mastoxiv.page
@arXiv_eessAS_bot@mastoxiv.pageAdvancing Zero-Shot Open-Set Speech Deepfake Source Tracing
Manasi Chhibber, Jagabandhu Mishra, Tomi H. Kinnunen
https://arxiv.org/abs/2509.24674 https://a…
 @arXiv_astrophEP_bot@mastoxiv.page
@arXiv_astrophEP_bot@mastoxiv.pageRAVEN: RAnking and Validation of ExoplaNets
Andreas Hadjigeorghiou, David J. Armstrong, Kaiming Cui, Marina Lafarga Magro, Luis Agust\'in Nieto, Rodrigo F. D\'iaz, Lauren Doyle, Vedad Kunovac
https://arxiv.org/abs/2509.17645
 @arXiv_qbioNC_bot@mastoxiv.page
@arXiv_qbioNC_bot@mastoxiv.pageOvercoming Output Dimension Collapse: How Sparsity Enables Zero-shot Brain-to-Image Reconstruction at Small Data Scales
Kenya Otsuka, Yoshihiro Nagano, Yukiyasu Kamitani
https://arxiv.org/abs/2509.15832
@arXiv_physicschemph_bot@mastoxiv.pageActive learning and explicit electrostatics enable accurate modeling of electrolytes
Olga Chalykh, Mikhail Polovinkin, Dmitry Korogod, Nikita Rybin, Alexander Shapeev
https://arxiv.org/abs/2510.03479
 @arXiv_mathST_bot@mastoxiv.page
@arXiv_mathST_bot@mastoxiv.pageMathematical Theory of Collinearity Effects on Machine Learning Variable Importance Measures
Kelvyn K. Bladen, D. Richard Cutler, Alan Wisler
https://arxiv.org/abs/2510.00557 ht…
 @arXiv_csNE_bot@mastoxiv.page
@arXiv_csNE_bot@mastoxiv.pageFrom Embeddings to Equations: Genetic-Programming Surrogates for Interpretable Transformer Classification
Mohammad Sadegh Khorshidi, Navid Yazdanjue, Hassan Gharoun, Mohammad Reza Nikoo, Fang Chen, Amir H. Gandomi
https://arxiv.org/abs/2509.21341
 @arXiv_physicsplasmph_bot@mastoxiv.page
@arXiv_physicsplasmph_bot@mastoxiv.pageElectron neural closure for turbulent magnetosheath simulations: energy channels
George Miloshevich, Luka Vranckx, Felipe Nathan de Oliveira Lopes, Pietro Dazzi, Giuseppe Arr\`o, Giovanni Lapenta
https://arxiv.org/abs/2510.00282
@arXiv_csLG_bot@mastoxiv.pageScore-based Membership Inference on Diffusion Models
Mingxing Rao, Bowen Qu, Daniel Moyer
https://arxiv.org/abs/2509.25003 https://arxiv.org/pdf/2509.25003…
@arXiv_csAI_bot@mastoxiv.pageCrosslisted article(s) found for cs.AI. https://arxiv.org/list/cs.AI/new
[6/12]:
- Generation Properties of Stochastic Interpolation under Finite Training Set
Yunchen Li, Shaohui Lin, Zhou Yu
@arXiv_csCV_bot@mastoxiv.pageNoiseShift: Resolution-Aware Noise Recalibration for Better Low-Resolution Image Generation
Ruozhen He, Moayed Haji-Ali, Ziyan Yang, Vicente Ordonez
https://arxiv.org/abs/2510.02307
 @arXiv_physicsaoph_bot@mastoxiv.page
@arXiv_physicsaoph_bot@mastoxiv.pageAn update to ECMWF's machine-learned weather forecast model AIFS
Gabriel Moldovan, Ewan Pinnington, Ana Prieto Nemesio, Simon Lang, Zied Ben Bouall\`egue, Jesper Dramsch, Mihai Alexe, Mario Santa Cruz, Sara Hahner, Harrison Cook, Helen Theissen, Mariana Clare, Cathal O'Brien, Jan Polster, Linus Magnusson, Gert Mertes, Florian Pinault, Baudouin Raoult, Patricia de Rosnay, Richard Forbes, Matthew Chantry
 @arXiv_eessSP_bot@mastoxiv.page
@arXiv_eessSP_bot@mastoxiv.pageEfficient Solutions for Mitigating Initialization Bias in Unsupervised Self-Adaptive Auditory Attention Decoding
Yuanyuan Yao, Simon Geirnaert, Tinne Tuytelaars, Alexander Bertrand
https://arxiv.org/abs/2509.14764
@arXiv_csRO_bot@mastoxiv.pageEfficient Construction of Implicit Surface Models From a Single Image for Motion Generation
Wei-Teng Chu, Tianyi Zhang, Matthew Johnson-Roberson, Weiming Zhi
https://arxiv.org/abs/2509.20681
@arXiv_csLG_bot@mastoxiv.pageNo Prior, No Leakage: Revisiting Reconstruction Attacks in Trained Neural Networks
Yehonatan Refael, Guy Smorodinsky, Ofir Lindenbaum, Itay Safran
https://arxiv.org/abs/2509.21296
@arXiv_physicschemph_bot@mastoxiv.pageLearning from the electronic structure of molecules across the periodic table
Manasa Kaniselvan, Benjamin Kurt Miller, Meng Gao, Juno Nam, Daniel S. Levine
https://arxiv.org/abs/2510.00224
@arXiv_csCV_bot@mastoxiv.pageA Scalable Distributed Framework for Multimodal GigaVoxel Image Registration
Rohit Jena, Vedant Zope, Pratik Chaudhari, James C. Gee
https://arxiv.org/abs/2509.25044 https://
@arXiv_csCL_bot@mastoxiv.pageCanary-1B-v2 & Parakeet-TDT-0.6B-v3: Efficient and High-Performance Models for Multilingual ASR and AST
Monica Sekoyan, Nithin Rao Koluguri, Nune Tadevosyan, Piotr Zelasko, Travis Bartley, Nick Karpov, Jagadeesh Balam, Boris Ginsburg
https://arxiv.org/abs/2509.14128
@arXiv_csCV_bot@mastoxiv.pageSparse Multiview Open-Vocabulary 3D Detection
Olivier Moliner, Viktor Larsson, Kalle {\AA}str\"om
https://arxiv.org/abs/2509.15924 https://arxiv.org/p…
@arXiv_eessAS_bot@mastoxiv.pageMixture of Low-Rank Adapter Experts in Generalizable Audio Deepfake Detection
Janne Laakkonen, Ivan Kukanov, Ville Hautam\"aki
https://arxiv.org/abs/2509.13878 https://








































