Just saw this:
#AI can mean a lot of things these days, but lots of the popular meanings imply a bevy of harms that I definitely wouldn't feel are worth a cute fish game. In fact, these harms are so acute that even "just" playing into the AI hype becomes its own kind of harm (it's similar to blockchain in that way).
@… noticed that the authors claim the code base is 80% AI generated, which is a red flag because people with sound moral compasses wouldn't be using AI to "help" write code in the first place. The authors aren't by some miracle people who couldn't build this app without help, in case that influences your thinking about it: they have the skills to write the code themselves, although it likely would have taken longer (but also been better).
I was more interested in the fish-classification AI, and how much it might be dependent on datacenters. Thankfully, a quick glance at the code confirms they're using ONNX and running a self-trained neural network on your device. While the exponentially-increasing energy & water demands of datacenters to support billion-parameter models are a real concern, this is not that. Even a non-AI game can burn a lot of cycles on someone's phone, and I don't think there's anything to complain about energy-wise if we're just using cycles on the end user's device as long as we're not having them keep it on for hours crunching numbers like blockchain stuff does. Running whatever stuff locally while the user is playing a game is a negligible environmental concern, unlike, say, calling out to ChatGPT where you're directly feeding datacenter demand. Since they claimed to have trained the network themselves, and since it's actually totally reasonable to make your own dataset for this and get good-enough-for-a-silly-game results with just a few hundred examples, I don't have any ethical objections to the data sourcing or training processes either. Hooray! This is finally an example of "ethical use of neutral networks" that I can hold up as an example of what people should be doing instead of the BS they are doing.
But wait... Remember what I said about feeding the AI hype being its own form of harm? Yeah, between using AI tools for coding and calling their classifier "AI" in a way that makes it seem like the same kind of thing as ChatGPT et al., they're leaning into the hype rather than helping restrain it. And that means they're causing harm. Big AI companies can point to them and say "look AI enables cute things you like" when AI didn't actually enable it. So I'm feeling meh about this cute game and won't be sharing it aside from this post. If you love the cute fish, you don't really have to feel bad for playing with it, but I'd feel bad for advertising it without a disclaimer.
Portable High-Performance Kernel Generation for a Computational Fluid Dynamics Code with DaCe
M{\aa}ns I. Andersson, Martin Karp, Niclas Jansson, Stefano Markidis
https://arxiv.org/abs/2506.20994
Study: only 32 countries, mostly in the Northern Hemisphere, host AI data centers, with the US, China, and the EU controlling 50% of the world's top facilities (New York Times)
https://www.nytimes.com…
Noted while reading: 'a data structure or a block of code are things that make implicit and subjective arguments about how to see the world. This is possibly the single most important basic insight that Digital Humanities as a field needs to impart, because it affects so much of the world around us' - excellent post by @…
Modeling Code: Is Text All You Need?
Daniel Nichols, Konstantinos Parasyris, Harshitha Menon, Brian R. Bartoldson, Giorgis Georgakoudis, Tal Ben-Nun, Abhinav Bhatele
https://arxiv.org/abs/2507.11467
Optimizing ASR for Catalan-Spanish Code-Switching: A Comparative Analysis of Methodologies
Carlos Mena, Pol Serra, Jacobo Romero, Abir Messaoudi, Jose Giraldo, Carme Armentano-Oller, Rodolfo Zevallos, Ivan Meza, Javier Hernando
https://arxiv.org/abs/2507.13875
EarthLink: Interpreting Climate Signals with Self-Evolving AI Agents
Zijie Guo, Jiong Wang, Xiaoyu Yue, Wangxu Wei, Zhe Jiang, Wanghan Xu, Ben Fei, Wenlong Zhang, Xinyu Gu, Lijing Cheng, Jing-Jia Luo, Chao Li, Yaqiang Wang, Tao Chen, Wanli Ouyang, Fenghua Ling, Lei Bai
https://arxiv.org/abs/2507.17311
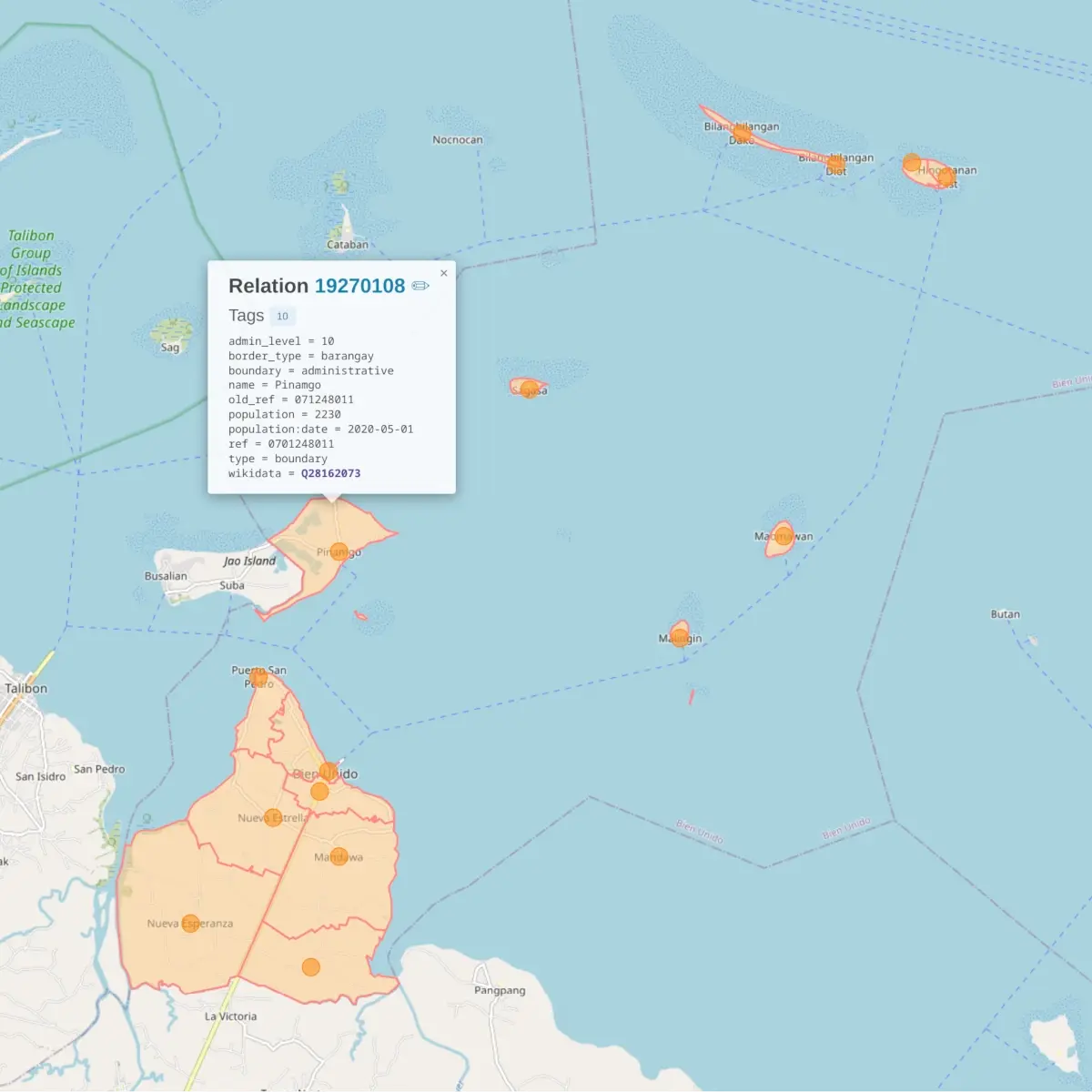
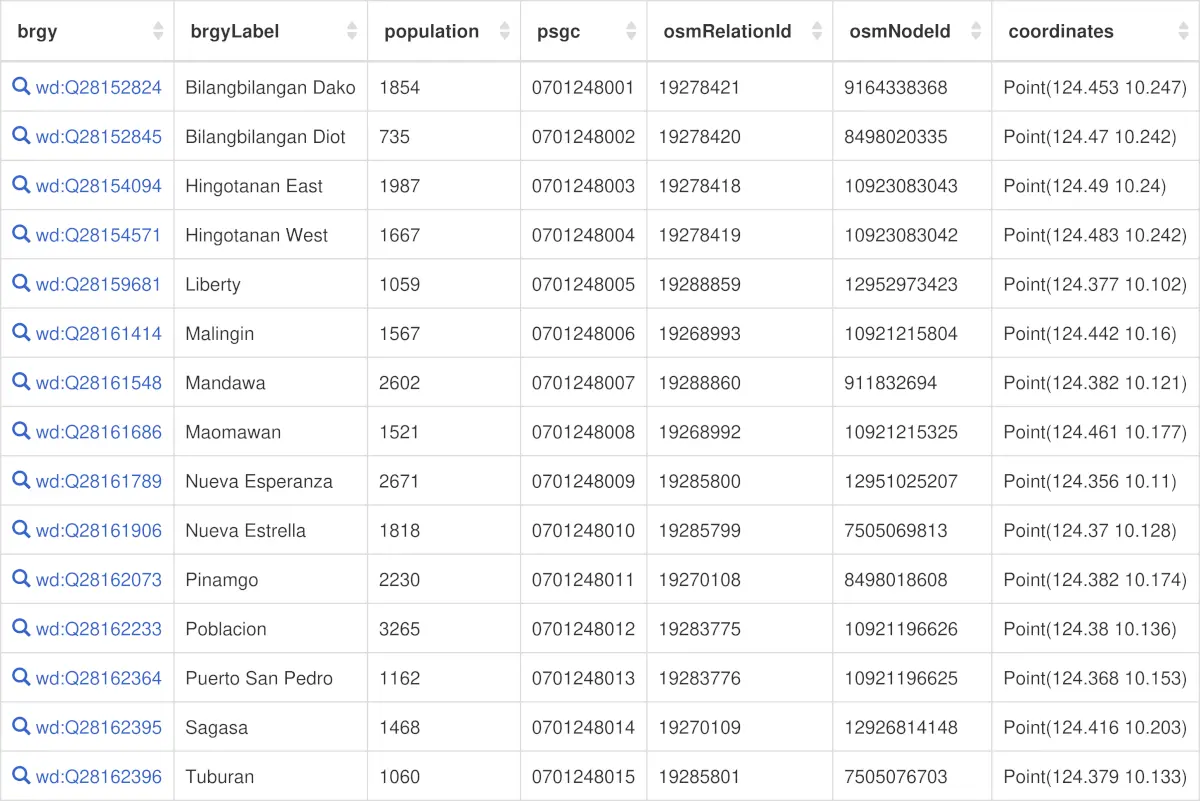
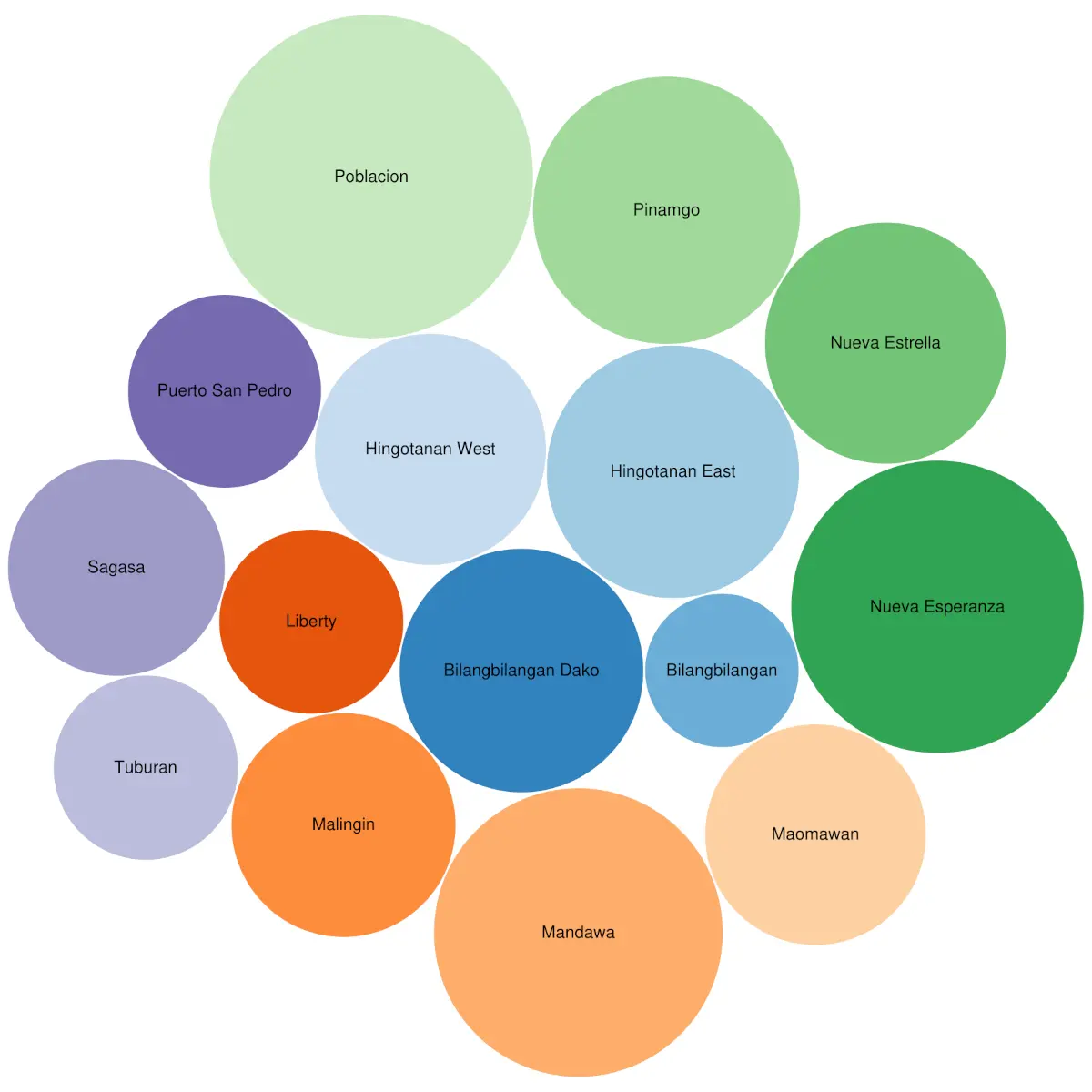
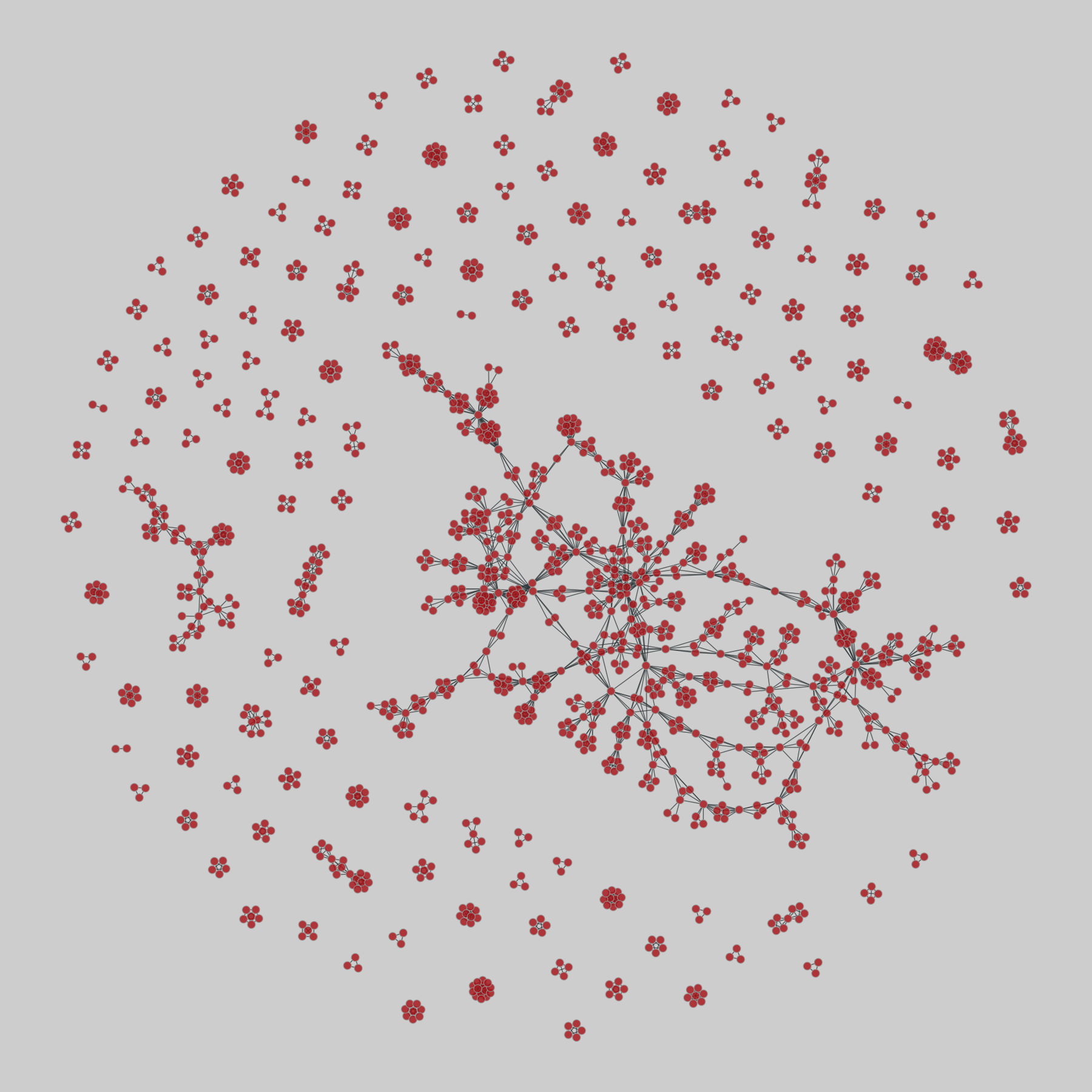
board_directors: Norwegian Boards of Directors (2002-2011)
224 networks of the affiliations among board directors due to sitting on common boards of Norwegian public limited companies (as of 5 August 2009), from May 2002 onward, in monthly snapshots through August 2011. Some metadata is included, such as director and company names, city and postal code for companies, and gender for directors. The 'net2m' data are bipartite company-director networks, while the 'net1m' ar…
Even if “AI” worked (it doesn’t), there’s many reasons why you shouldn’t use it:
1. It’s destroying Internet sites that you love as you use chat bots instead of actually going to sources of information—this will cause them to be less active and eventually shut down.
2. Pollution and water use from server farms cause immediate harm; often—just like other heavy industry—these are built in underprivileged communities and harming poor people. Without any benefits as the big tech companies get tax breaks and don’t pay for power, while workers aren’t from the community but commute in.
3. The basic underlying models of any LLM rely on stolen data, even when specific extra data is obtained legally. Chatbots can’t learn to speak English just by reading open source code.
4. You’re fueling a speculation bubble that is costing many people their jobs—because the illusion of “efficiency” is kept up by firing people and counting that as profit.
5. Whenever you use the great cheat machine in the cloud you’re robbing yourself from doing real research, writing or coding—literally atrophying your brain and making you stupider.
It’s a grift, through and through.
This morning I null routed another dozen IP addresses for scraping my personal git server using repeated http requests. As per usual, a quick inspection reveals that at least some of them are scraping for LLM data. As always, I have not consented to this use of my non-maintained code, experiments, college coursework, and miscellaneous crap that I for whatever reason decided to self host rather than pushing it to Codeberg.
I mean, if you really want to feed your LLM on a diet that inclu…
DHEvo: Data-Algorithm Based Heuristic Evolution for Generalizable MILP Solving
Zhihao Zhang, Siyuan Li, Chenxi Li, Feifan Liu, Mengjing Chen, Kai Li, Tao Zhong, Bo An, Peng Liu
https://arxiv.org/abs/2507.15615
Efficient dataset construction using active learning and uncertainty-aware neural networks for plasma turbulent transport surrogate models
Aaron Ho (MIT Plasma Science and Fusion Center, Cambridge, USA), Lorenzo Zanisi (UKAEA Culham Centre for Fusion Energy, Abingdon, UK), Bram de Leeuw (Radboud University, Nijmegen, Netherlands), Vincent Galvan (MIT Plasma Science and Fusion Center, Cambridge, USA), Pablo Rodriguez-Fernandez (MIT Plasma Science and Fusion Center, Cambridge, USA), Nath…
A look at WindBorne, which uses weather balloons and AI to improve forecasting, as potential budget cuts to NOAA threaten its access to public weather data (Tim Fernholz/New York Times)
https://www.
Your Token Becomes Worthless: Unveiling Rug Pull Schemes in Crypto Token via Code-and-Transaction Fusion Analysis
Hao Wu, Haijun Wang, Shangwang Li, Yin Wu, Ming Fan, Wuxia Jin, Yitao Zhao, Ting Liu
https://arxiv.org/abs/2506.18398
OSMnx is a Python package to retrieve, model, analyze, and visualize street networks from OpenStreetMap.
Users can download and model walkable, drivable, or bikeable urban networks with a single line of Python code
-- and then easily analyze and visualize them.
You can just as easily download and work with amenities/points of interest, building footprints, elevation data, street bearings/orientations, and network routing.
If you use OSMnx in your work, please downlo…
A Code Comprehension Benchmark for Large Language Models for Code
Jayant Havare, Saurav Chaudhary, Ganesh Ramakrishnan, Kaushik Maharajan, Srikanth Tamilselvam
https://arxiv.org/abs/2507.10641
board_directors: Norwegian Boards of Directors (2002-2011)
224 networks of the affiliations among board directors due to sitting on common boards of Norwegian public limited companies (as of 5 August 2009), from May 2002 onward, in monthly snapshots through August 2011. Some metadata is included, such as director and company names, city and postal code for companies, and gender for directors. The 'net2m' data are bipartite company-director networks, while the 'net1m' ar…
MatBYIB: A Matlab-based code for Bayesian inference of extreme mass-ratio inspiral binary with arbitrary eccentricity
Gen-Liang Li, Shu-Jie Zhao, Huai-Ke Guo, Jing-Yu Su, Zhen-Heng Lin
https://arxiv.org/abs/2506.05954
MetaLint: Generalizable Idiomatic Code Quality Analysis through Instruction-Following and Easy-to-Hard Generalization
Atharva Naik, Lawanya Baghel, Dhakshin Govindarajan, Darsh Agrawal, Daniel Fried, Carolyn Rose
https://arxiv.org/abs/2507.11687
Explainer-guided Targeted Adversarial Attacks against Binary Code Similarity Detection Models
Mingjie Chen (Zhejiang University), Tiancheng Zhu (Huazhong University of Science,Technology), Mingxue Zhang (The State Key Laboratory of Blockchain,Data Security, Zhejiang University,Hangzhou High-Tech Zone), Yiling He (University College London), Minghao Lin (University of Southern California), Penghui Li (Columbia University), Kui Ren (The State Key Laboratory of Blockchain,Data Security, Z…
Dynamic Chunking for End-to-End Hierarchical Sequence Modeling
Sukjun Hwang, Brandon Wang, Albert Gu
https://arxiv.org/abs/2507.07955 https://arxiv.org/pdf/2507.07955 https://arxiv.org/html/2507.07955
arXiv:2507.07955v1 Announce Type: new
Abstract: Despite incredible progress in language models (LMs) in recent years, largely resulting from moving away from specialized models designed for specific tasks to general models based on powerful architectures (e.g. the Transformer) that learn everything from raw data, pre-processing steps such as tokenization remain a barrier to true end-to-end foundation models. We introduce a collection of new techniques that enable a dynamic chunking mechanism which automatically learns content -- and context -- dependent segmentation strategies learned jointly with the rest of the model. Incorporating this into an explicit hierarchical network (H-Net) allows replacing the (implicitly hierarchical) tokenization-LM-detokenization pipeline with a single model learned fully end-to-end. When compute- and data- matched, an H-Net with one stage of hierarchy operating at the byte level outperforms a strong Transformer language model operating over BPE tokens. Iterating the hierarchy to multiple stages further increases its performance by modeling multiple levels of abstraction, demonstrating significantly better scaling with data and matching a token-based Transformer of twice its size. H-Nets pretrained on English show significantly increased character-level robustness, and qualitatively learn meaningful data-dependent chunking strategies without any heuristics or explicit supervision. Finally, the H-Net's improvement over tokenized pipelines is further increased in languages and modalities with weaker tokenization heuristics, such as Chinese and code, or DNA sequences (nearly 4x improvement in data efficiency over baselines), showing the potential of true end-to-end models that learn and scale better from unprocessed data.
toXiv_bot_toot
Measurement of radionuclide production probabilities in negative muon nuclear capture and validation of Monte Carlo simulation model
Y. Yamaguchi, M. Niikura, R. Mizuno, M. Tampo, M. Harada, N. Kawamura, I. Umegaki, S. Takeshita, K. Haga
https://arxiv.org/abs/2506.08301
MatBYIB: A Matlab-based code for Bayesian inference of extreme mass-ratio inspiral binary with arbitrary eccentricity
Gen-Liang Li, Shu-Jie Zhao, Huai-Ke Guo, Jing-Yu Su, Zhen-Heng Lin
https://arxiv.org/abs/2506.05954
Observing Fine-Grained Changes in Jupyter Notebooks During Development Time
Sergey Titov, Konstantin Grotov, Cristina Sarasua, Yaroslav Golubev, Dhivyabharathi Ramasamy, Alberto Bacchelli, Abraham Bernstein, Timofey Bryksin
https://arxiv.org/abs/2507.15831
Reasoning-Table: Exploring Reinforcement Learning for Table Reasoning
Fangyu Lei, Jinxiang Meng, Yiming Huang, Tinghong Chen, Yun Zhang, Shizhu He, Jun Zhao, Kang Liu
https://arxiv.org/abs/2506.01710
Probing Audio-Generation Capabilities of Text-Based Language Models
Arjun Prasaath Anbazhagan, Parteek Kumar, Ujjwal Kaur, Aslihan Akalin, Kevin Zhu, Sean O'Brien
https://arxiv.org/abs/2506.00003
Mutual-Supervised Learning for Sequential-to-Parallel Code Translation
Changxin Ke, Rui Zhang, Shuo Wang, Li Ding, Guangli Li, Yuanbo Wen, Shuoming Zhang, Ruiyuan Xu, Jin Qin, Jiaming Guo, Chenxi Wang, Ling Li, Qi Guo, Yunji Chen
https://arxiv.org/abs/2506.11153
MGS3: A Multi-Granularity Self-Supervised Code Search Framework
Rui Li, Junfeng Kang, Qi Liu, Liyang He, Zheng Zhang, Yunhao Sha, Linbo Zhu, Zhenya Huang
https://arxiv.org/abs/2505.24274
 @tante@tldr.nettime.org
@tante@tldr.nettime.org