 @spamless@mastodon.social
@spamless@mastodon.social2025-09-09 21:17:24
I like this. #linguistics
@spamless@mastodon.socialI like this. #linguistics
 @EgorKotov@datasci.social
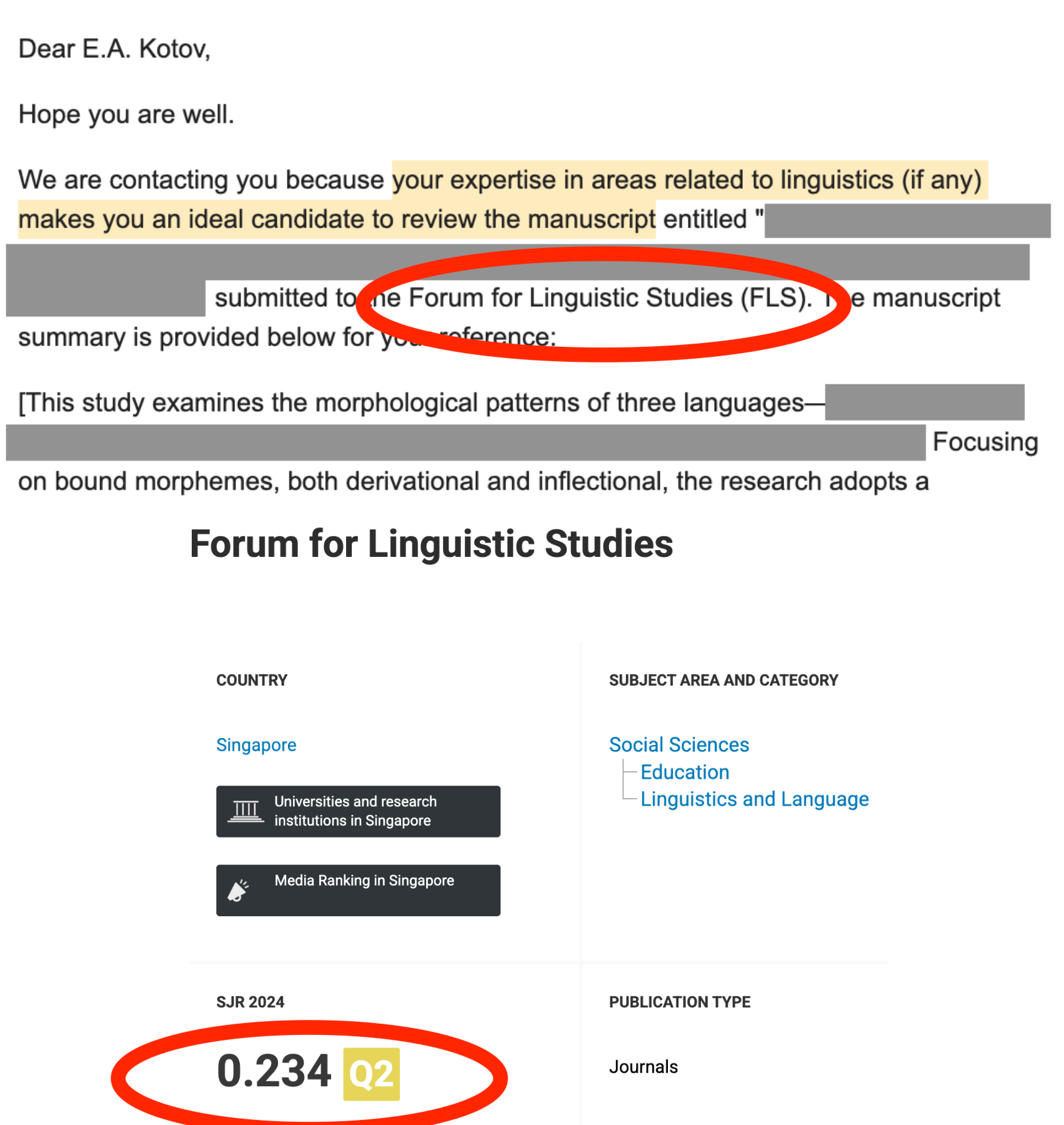
@EgorKotov@datasci.socialFrom a Q2 (according to Elsevier Scopus ) journal asking for a review. They are not even trying. According to them, I have an "expertise in areas related to linguistics (if any)" [I love this "if any"!] , makes me "an ideal candidate to review the manuscript".
 @sascha_wolfer@fediscience.org
@sascha_wolfer@fediscience.orgNew #preprint by Alex Koplenig and me:
"Statistical errors undermine claims about the evolution of polysynthetic languages". (#PNAS (#Linguistics
 @arXiv_csPL_bot@mastoxiv.page
@arXiv_csPL_bot@mastoxiv.pageSound Interval-Based Synthesis for Probabilistic Programs
Guilherme Espada, Alcides Fonseca
https://arxiv.org/abs/2507.06939 https://…
 @CerstinMahlow@mastodon.acm.org
@CerstinMahlow@mastodon.acm.orgHalf an hour to go: closing event of our #swissuniversities
project “Digital Literacy in University Contexts.”
https://www.zhaw.ch/en/linguistics/researc

 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.pageA Survey of Pun Generation: Datasets, Evaluations and Methodologies
Yuchen Su, Yonghua Zhu, Ruofan Wang, Zijian Huang, Diana Benavides-Prado, Michael Witbrock
https://arxiv.org/abs/2507.04793
 @tschfflr@fediscience.org
@tschfflr@fediscience.orgI arrived in Oslo! The Emoji Workshop is on Friday - if you're working on the linguistics of emojis and need the Zoom link, contact me via email
https://www.hf.uio.no/iln/english/research/groups/super-linguistics/events/the-emoji-workshop.html
 @qurlyjoe@mstdn.social
@qurlyjoe@mstdn.social#linguistics
I vaguely recall from long ago studies the concept of #Register in describing and analyzing language usage, and how a given language has many registers, the use of which is prescribed by context.
There is, I think, a register that is used exclusively when narrating a History Ch…
 @arXiv_csFL_bot@mastoxiv.page
@arXiv_csFL_bot@mastoxiv.pageIdentity Testing for Stochastic Languages
Smayan Agarwal, Shobhit Singh, Aalok Thakkar
https://arxiv.org/abs/2508.03826 https://arxiv.org/pdf/2508.03826
 @fanf@mendeddrum.org
@fanf@mendeddrum.orgfrom my link log —
You know more Finnish than you think.
https://dannybate.com/2025/08/03/you-know-more-finnish-than-you-think/
saved 2025-08-07
 @arXiv_csCY_bot@mastoxiv.page
@arXiv_csCY_bot@mastoxiv.pageChatbot Deployment Considerations for Application-Agnostic Human-Machine Dialogues
Pablo Rivas, Chelsi Chelsi, Nishit Nishit, Laharika Ravula
https://arxiv.org/abs/2509.02611 ht…
 @fgraver@hcommons.social
@fgraver@hcommons.socialwriter identity and voice https://patthomson.net/2025/07/30/writer-identity-and-voice/
 @arXiv_csSD_bot@mastoxiv.page
@arXiv_csSD_bot@mastoxiv.pageNon-Verbal Vocalisations and their Challenges: Emotion, Privacy, Sparseness, and Real Life
Anton Batliner, Shahin Amiriparian, Bj\"orn W. Schuller
https://arxiv.org/abs/2508.01960
@tschfflr@fediscience.orgVery excited for The Emoji Workshop tomorrow! Warm-up starting now ☺️
https://www.hf.uio.no/iln/english/research/groups/super-linguistics/events/the-emoji-workshop.html

 @relcfp@mastodon.social
@relcfp@mastodon.socialThe Second Coming of Humanities: 2nd International Conference on Literature, Linguistics, and Language
https://ift.tt/ysZRf8M
updated: Friday, September 5, 2025 - 9:25amfull name / name of organization: University of Central…
via Input 4 RELCFP
@spamless@mastodon.socialGerman-English connections: "anecken" and "to egg on." These words don't mean exactly the same thing, but they are related. Etymologically, they seem closely related. English is a Germanic language. And phrasal verbs offer up interesting connections.
#language #linguistics
 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.pageJoint Modeling of Entities and Discourse Relations for Coherence Assessment
Wei Liu, Michael Strube
https://arxiv.org/abs/2509.04182 https://arxiv.org/pdf/…
 @arXiv_csAI_bot@mastoxiv.page
@arXiv_csAI_bot@mastoxiv.pageBridging Minds and Machines: Toward an Integration of AI and Cognitive Science
Rui Mao, Qian Liu, Xiao Li, Erik Cambria, Amir Hussain
https://arxiv.org/abs/2508.20674 https://…
@qurlyjoe@mstdn.social @felwert@fedihum.org
@felwert@fedihum.orghttps://wisskomm.social/@ids_mannheim/114890809294634742
Mit einem Beitrag von meinen Kolleg*innen @… und Sebastian Reimann aus u…
@arXiv_csCL_bot@mastoxiv.pageUNVEILING: What Makes Linguistics Olympiad Puzzles Tricky for LLMs?
Mukund Choudhary, KV Aditya Srivatsa, Gaurja Aeron, Antara Raaghavi Bhattacharya, Dang Khoa Dang Dinh, Ikhlasul Akmal Hanif, Daria Kotova, Ekaterina Kochmar, Monojit Choudhury
https://arxiv.org/abs/2508.11260
@tschfflr@fediscience.org#omw to The #Emoji Workshop*! Step 1 ✅
#DB true to form with trains just not running without notice, and this helpful schedule
* https://www.hf.uio.no/iln/english/research/groups/super-linguistics/events/the-emoji-workshop.html

 @trochee@dair-community.social
@trochee@dair-community.socialhttps://snarxiv.org/vs-arxiv/
This needs a version for the computational linguistics/machine-learning quartier of arXiv
I'm guessing at about 60% accurate in the string theory/supercollider / early time physics papers there, "better than a monkey" as the robot tells me
Via/blame
@fanf@mendeddrum.orgfrom my link log —
Sapir-Whorf does not apply to programming languages.
https://buttondown.com/hillelwayne/archive/sapir-whorf-does-not-apply-to-programming/
saved 2025-08-21
@sascha_wolfer@fediscience.orgDoes anyone have access to this article?
Bromham et al. (2025): Macroevolutionary analysis of polysynthesis shows that language complexity is more likely to evolve in small, isolated populations.
#papersplease #paper #Linguistics
@sascha_wolfer@fediscience.orgHier eine persönliche Auswahl von tatsächlich im #Korpus vorkommenden schönen Modifikationen von "langsam" (von oben nach unten nach Häufigkeit sortiert). Mit dabei: Viele Tiere!
- zeitlupenlangsam
- schneckenlangsam 🐌
- schnelllangsam (?!?)
- schildkrötenlangsam 🐢
- schweinelangsam 🐷
- hyperlangsam
- hundslangsam 🐕🦺
- rasendlangsam
- ameisenlangsam 🐜
- krötenlangsam 🐸
- lavalangsam
- tuckerlangsam
- zentimeterlangsam
(Quelle: DeReKoGram, #linguistics
@arXiv_csCL_bot@mastoxiv.pageData interference: emojis, homoglyphs, and issues of data fidelity in corpora and their results
Matteo Di Cristofaro
https://arxiv.org/abs/2507.01764 https…
 @arXiv_qbioPE_bot@mastoxiv.page
@arXiv_qbioPE_bot@mastoxiv.pagephylo2vec: a library for vector-based phylogenetic tree manipulation
Neil Scheidwasser, Ayush Nag, Matthew J Penn, Anthony MV Jakob, Frederik M{\o}lkj{\ae}r Andersen, Mark P Khurana, Landung Setiawan, Madeline Gordon, David A Duch\^ene, Samir Bhatt
https://arxiv.org/abs/2506.19490
@sascha_wolfer@fediscience.orgTo whom it may concern...
Kurzauszug aus aktueller #Korpus -Studie
"hin- und/oder herX"
X = finites Verb, Verb im Infinitiv oder Partizip Perfekt
Platz 1: hin- und hergerissen (duh!)
Platz 2: hin- und hergeschoben
Platz 3: hin- und herschieben (s. Platz 2)
Platz 4: hin- und herfahren
Platz 5: hin- und herpendeln
Platz 6: hin- und hergeschickt
Platz 7: hin- und hergefahren (s. Platz 4)
Platz 8: hin- und hergeworfen
Platz 9: hin- und herwechseln
Platz 10: hin- und herpendelt (s. Platz 5)
"hin- und hergerissen" ist dabei immer noch häufiger als Plätze 2 bis 10 zusammengenommen.
Wie gesagt: "und" kann in der obigen Liste auch immer "oder" sein.
Quelle: DeReKoGram (#linguistics
@arXiv_csCL_bot@mastoxiv.pageGenerative AI and the future of scientometrics: current topics and future questions
Benedetto Lepori, Jens Peter Andersen, Karsten Donnay
https://arxiv.org/abs/2507.00783
@arXiv_csSD_bot@mastoxiv.pageAssessing the Impact of Anisotropy in Neural Representations of Speech: A Case Study on Keyword Spotting
Guillaume Wisniewski (LLF - UMR7110), S\'everine Guillaume (LACITO), Clara Rosina Fern\'andez (LACITO)
https://arxiv.org/abs/2506.11096
@arXiv_csCL_bot@mastoxiv.pageFeature-Refined Unsupervised Model for Loanword Detection
Promise Dodzi Kpoglu
https://arxiv.org/abs/2508.17923 https://arxiv.org/pdf/2508.17923
@tschfflr@fediscience.org🤩 We spent today recording video for a new professional short introduction into our ViCom project on #emojis 📹 It was fun trying to find the most photogenic public spots on campus (as emoji research consists mostly of us staring at computer screens all day long, and is not very... visually interesting)
Very excited to show you the results in a few weeks or months! #visualCommunication #linguistics #sciComm @… https://vicom.info/projects/semantics-and-pragmatics-of-emojis-in-digital-communication/
@arXiv_csCL_bot@mastoxiv.pageA comprehensive study of LLM-based argument classification: from LLAMA through GPT-4o to Deepseek-R1
Marcin Pietro\'n, Rafa{\l} Olszowski, Jakub Gomu{\l}ka, Filip Gampel, Andrzej Tomski
https://arxiv.org/abs/2507.08621
@sascha_wolfer@fediscience.orgJust published:
Supplementing CEFR-graded vocabulary lists for language learners by leveraging information on dictionary views, corpus frequency, part-of-speech, and polysemy
A machine-learning method to suggest word candidates for CEFR-graded vocabulary lists.
#CEFR level of previously unlabeled words
#linguistics #CEFR #frequency #dictionary #LanguageLearning
















