@mia@hcommons.social
@mia@hcommons.social2025-09-19 14:22:23
Some nice examples in the 'use cases' section of AI for Humanists https://aiforhumanists.com/guides/usecases/ - from OCR to annotation to identifying voices and styles
@mia@hcommons.socialSome nice examples in the 'use cases' section of AI for Humanists https://aiforhumanists.com/guides/usecases/ - from OCR to annotation to identifying voices and styles
 @arXiv_csDL_bot@mastoxiv.page
@arXiv_csDL_bot@mastoxiv.pageLayout-Aware OCR for Black Digital Archives with Unsupervised Evaluation
Fitsum Sileshi Beyene, Christopher L. Dancy
https://arxiv.org/abs/2509.13236 https://
 @mgorny@social.treehouse.systems
@mgorny@social.treehouse.systemsPaperwork does OCR on everything I scan. I've just scanned a document with my signature on it. It OCR-ed the signature (which is literally a scrawl on "Michał Górny") as "NBA".
 @avstockhausen@fedihum.org
@avstockhausen@fedihum.orgBookmarked: calfa-co/hye-tesseract: Open OCR model for Armenian #Armenisch_OCR_Tesseract
 @arXiv_csCV_bot@mastoxiv.page
@arXiv_csCV_bot@mastoxiv.pageVisionThink: Smart and Efficient Vision Language Model via Reinforcement Learning
Senqiao Yang, Junyi Li, Xin Lai, Bei Yu, Hengshuang Zhao, Jiaya Jia
https://arxiv.org/abs/2507.13348
 @arXiv_csCL_bot@mastoxiv.page
@arXiv_csCL_bot@mastoxiv.pageBenchmarking Vision-Language Models on Chinese Ancient Documents: From OCR to Knowledge Reasoning
Haiyang Yu, Yuchuan Wu, Fan Shi, Lei Liao, Jinghui Lu, Xiaodong Ge, Han Wang, Minghan Zhuo, Xuecheng Wu, Xiang Fei, Hao Feng, Guozhi Tang, An-Lan Wang, Hanshen Zhu, Yangfan He, Quanhuan Liang, Liyuan Meng, Chao Feng, Can Huang, Jingqun Tang, Bin Li
https://
@arXiv_csCV_bot@mastoxiv.pageDesign and Implementation of an OCR-Powered Pipeline for Table Extraction from Invoices
Parshva Dhilankumar Patel
https://arxiv.org/abs/2507.07029 https://…
@arXiv_csCL_bot@mastoxiv.pageE-ARMOR: Edge case Assessment and Review of Multilingual Optical Character Recognition
Aryan Gupta, Anupam Purwar
https://arxiv.org/abs/2509.03615 https://…
 @arXiv_csCY_bot@mastoxiv.page
@arXiv_csCY_bot@mastoxiv.pageIntegrating Generative AI into Cybersecurity Education: A Study of OCR and Multimodal LLM-assisted Instruction
Karan Patel, Yu-Zheng Lin, Gaurangi Raul, Bono Po-Jen Shih, Matthew W. Redondo, Banafsheh Saber Latibari, Jesus Pacheco, Soheil Salehi, Pratik Satam
https://arxiv.org/abs/2509.02998
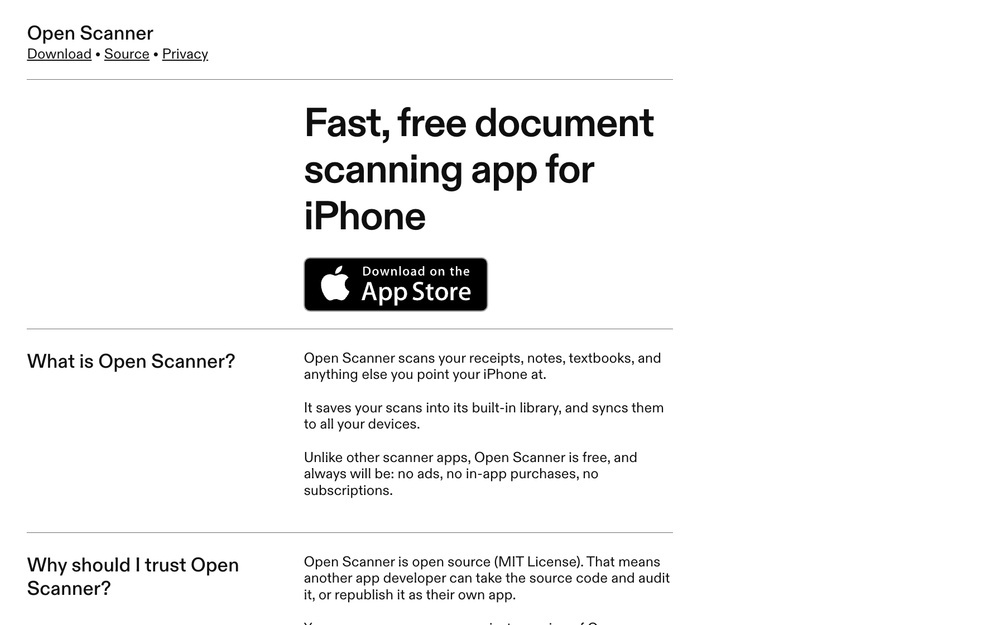
 @toxi@mastodon.thi.ng
@toxi@mastodon.thi.ngFinally found a great ad-free and tracking-free #OpenSource document scanner for iOS, with OCR and multi-page PDF output:
https://openscanner.app/
 @arXiv_csIR_bot@mastoxiv.page
@arXiv_csIR_bot@mastoxiv.pageUncertainty-Aware Complex Scientific Table Data Extraction
Kehinde Ajayi, Yi He, Jian Wu
https://arxiv.org/abs/2507.02009 https://arx…
 @grumpybozo@toad.social
@grumpybozo@toad.social33k one-page TIFFs is an OCR challenge, but it's not insurmountable. https://fed.brid.gy/r/https://bsky.app/profile/did:plc:gvda6fem6r7selm4gzjjww4a/post/3lxvbrbeabc2a
 @vform@openbiblio.social
@vform@openbiblio.socialBei dem ganzen KI-Gedöns würde ich ja denken, die perfekten und freien, sparsamen Modelle für Autokorrektur und OCR-Erkennung sollte da sein. So als quasi Kernkompetenz von LLMs. Aber hören und lesen tu ich hauptsächlich in Richtung "Chat"-Nutzung.
 @michabbb@social.vivaldi.net
@michabbb@social.vivaldi.net#MistralAI Document #AI: Advanced #OCR solution for complex document processing 📄
📺

 @mela@zusammenkunft.net
@mela@zusammenkunft.netGibt's eine brauchbare Scanner-App für Android, ohne Abo? Braucht kein OCR, nur gute mehrseitige Scans2PDF.
@arXiv_csCV_bot@mastoxiv.pageVARCO-VISION-2.0 Technical Report
Young-rok Cha, Jeongho Ju, SunYoung Park, Jong-Hyeon Lee, Younghyun Yu, Youngjune Kim
https://arxiv.org/abs/2509.10105 https://
 @nelson@tech.lgbt
@nelson@tech.lgbtOne of my most useful tools these days are things that take screenshots. Greenshot, a Windows tool with excellent usability. And Powertools Text Extractor which lets me OCR bits of text on the screen. Usability is important here: press one button and stuff is copied to clipboard.
@arXiv_csCL_bot@mastoxiv.pageZero-shot OCR Accuracy of Low-Resourced Languages: A Comparative Analysis on Sinhala and Tamil
Nevidu Jayatilleke, Nisansa de Silva
https://arxiv.org/abs/2507.18264 https://
@arXiv_csCV_bot@mastoxiv.pageWhy Stop at Words? Unveiling the Bigger Picture through Line-Level OCR
Shashank Vempati, Nishit Anand, Gaurav Talebailkar, Arpan Garai, Chetan Arora
https://arxiv.org/abs/2508.21693
@arXiv_csDL_bot@mastoxiv.pageComparing OCR Pipelines for Folkloristic Text Digitization
Octavian M. Machidon, Alina L. Machidon
https://arxiv.org/abs/2507.19092 https://arxiv.org/pdf/2…
 @arXiv_csHC_bot@mastoxiv.page
@arXiv_csHC_bot@mastoxiv.pageEmail as the Interface to Generative AI Models: Seamless Administrative Automation
Andres Navarro, Carlos de Quinto, Jos\'e Alberto Hern\'andez
https://arxiv.org/abs/2506.23850
@arXiv_csCY_bot@mastoxiv.pageReal-Time AI-Driven Pipeline for Automated Medical Study Content Generation in Low-Resource Settings: A Kenyan Case Study
Emmanuel Korir, Eugene Wechuli
https://arxiv.org/abs/2507.05212
@arXiv_csCV_bot@mastoxiv.pageImproving OCR using internal document redundancy
Diego Belzarena, Seginus Mowlavi, Aitor Artola, Camilo Mari\~no, Marina Gardella, Ignacio Ram\'irez, Antoine Tadros, Roy He, Natalia Bottaioli, Boshra Rajaei, Gregory Randall, Jean-Michel Morel
https://arxiv.org/abs/2508.14557
@michabbb@social.vivaldi.net @arXiv_csIR_bot@mastoxiv.pageEvaluating VisualRAG: Quantifying Cross-Modal Performance in Enterprise Document Understanding
Varun Mannam, Fang Wang, Xin Chen
https://arxiv.org/abs/2506.21604
@arXiv_csIR_bot@mastoxiv.pageExtracting Information from Scientific Literature via Visual Table Question Answering Models
Dongyoun Kim, Hyung-do Choi, Youngsun Jang, John Kim
https://arxiv.org/abs/2508.18661