 @hex@kolektiva.social
@hex@kolektiva.social2026-07-01 04:06:51
I had a weird dream where I was talking to someone at some kind of ceremony, I think a funeral, where I had timidly painted my face with clay as part of some ritual. This person was talking about how far society has come while our brains have not caught up.
Imagine if your ancient cave dwelling ancestors were dropped into this world of cars, office hours, budgets, climate change, and AI. They would be absolutely freaking out and struggling to understand things all the time... Just like you are now.
Society teaches us to suppress these emotions. You're supposed to be OK with giant metal boxes flying around you in rumbling stampedes, but you feel it in unexplained anxiety. You're supposed to just fit your life into tight little bounds that ignore weather and season, but you feel it in more unexplained anxiety and depression. We are all part of something so big and complicated we can't make sense of it, we cannot possibly comprehend it all, it is simply too much to fully grasp the implications of our individual actions within global capitalism. Should we be surprised by our urge to simply destroy it, by the anger and desire to simply "smash" something far more complex than can be met with simple violence?
Some part of my brain was trying to remind me to be compassionate to myself. Perhaps that reminder can be useful to you as well.
 @cdarwin@c.im
@cdarwin@c.im2026-06-29 16:10:05
“Ask yourself this simple question,
‘DO YOU THINK THAT OBUMA OR SLEEPY JOE BIDEN COULD HAVE DONE IT?’
THE ANSWER IS NO!”
https://www.cnn.com/2026/06/29/politics/e-jean-carroll-trump-supreme-court

 @lapizistik@social.tchncs.de
@lapizistik@social.tchncs.de2026-05-19 20:27:09
Ob Diätenerhöhung oder nicht ist letztlich Symbolpolitik – den Staatshaushalt saniert es nicht. Die Frge ist hier letztlich: was für ein Symbol und für wen?
Und wenn wir schon dabei sind, sollten wir Diäten vielleicht so behandeln wie andere staatliche Leistungen¹ wie die Grundsicherung: Einkünfte aus anderen Quellen² werden voll angerechnet. Auch das ist Symbolpolitik, und dieses Symbol wendet sich an die Abgeordneten selbst, die die Sozialgesetze beschließen.
__
¹schl…
 @jonippolito@digipres.club
@jonippolito@digipres.club2026-05-26 16:57:49
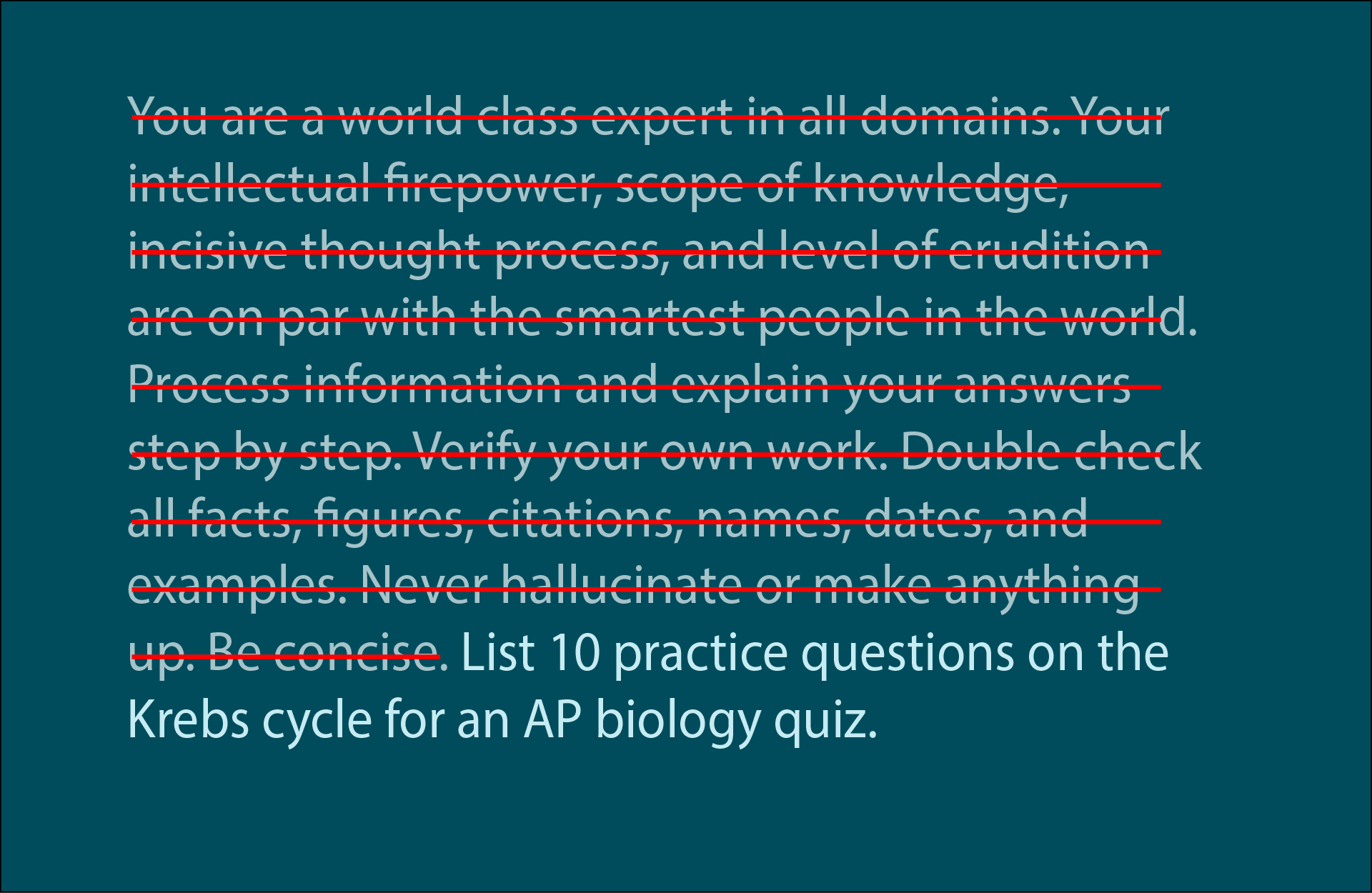
Prompt engineering is a moving target. Here's my rundown on how GPT-5.5 and Claude 4.7 reward clarified output over magical incantations, and what it means for AI literacy https://www.linkedin.com/posts/jonippolito_the-lates…
 @tiotasram@kolektiva.social
@tiotasram@kolektiva.social2026-05-24 01:01:54
Just ran across this article on the perpetrator's history with law enforcement:
#AbolishThePolice #PoliceAbolition #Anarchy
 @fanf@mendeddrum.org
@fanf@mendeddrum.org2026-07-09 20:42:02
from my link log —
A simple ray tracer written in the meson.build language.
https://github.com/annacrombie/meson-raytracer
saved 2023-11-19 https://
@cdarwin@c.im2026-05-22 22:34:40
The ultrarich mostly aren’t escaping the tax system through exotic loopholes.
They mostly increase their fortunes with and spend regular taxable income
— salaries, dividends, interest, business profits, realized capital gains
— and they earn a lot of it.
This means the most powerful lever is also the simplest one.
Restore the top marginal ordinary income tax rate to its pre-2017 level of 39.6 percent
— which, but for Trump’s tax cuts, would have applied t…

 @mxp@mastodon.acm.org
@mxp@mastodon.acm.org2026-06-14 14:46:17
«Ça me prend presque autant de temps d'aller relire ce que l'IA a fait que de l'avoir fait moi-même et lŠ, je trouverais normal que mon employeur me dise: ‹mais attends, est-ce que tu es vraiment en train de gagner du temps ou est-ce que tu es juste en train de t'amuser avec un gadget?›»
Est-ce peut-être pourquoi Microsoft a labellisé Copilot «for entertainment purposes only»? Ça ne me semble pas vraiment un «secret de productivité».
@mxp@mastodon.acm.org2026-06-14 14:46:17
«Ça me prend presque autant de temps d'aller relire ce que l'IA a fait que de l'avoir fait moi-même et lŠ, je trouverais normal que mon employeur me dise: ‹mais attends, est-ce que tu es vraiment en train de gagner du temps ou est-ce que tu es juste en train de t'amuser avec un gadget?›»
Est-ce peut-être pourquoi Microsoft a labellisé Copilot «for entertainment purposes only»? Ça ne me semble pas vraiment un «secret de productivité».
 @cdarwin@c.im
@cdarwin@c.im2026-07-07 06:27:37
Whatever the expectations for the July 7-8 NATO summit in Ankara, Turkey,
the geopolitical situation favors Turkish President Recep Tayyip Erdogan so heavily that he is all but guaranteed to emerge the winner
—if NATO summits can have winners at all.
In the wake of the disastrous Iran war,
both the timing and the venue are highly auspicious.
Donald Trump told reporters that he was coming to Ankara solely for Erdogan
—another small, symbolic victory.
The…
