So, been wondering why my mic audio has been absolutely wretched over the last few videos and such. Come to find out, if you accidentally wreck almost all of the settings on the compressor/gate then things are going to go very, very poorly. Did a quick test run in OBS and everything sounded so much better.
Current setup for the microphone: Earthworks Audio Ethos -> Universal Audio SOLO/610 -> dbx 286s -> [insert generic audio interface] -> Linux rig
Google plans to update the Pixel Buds Pro 2 in September with adaptive audio, background noise reduction when using Gemini Live, and a new "moonstone" color (Victoria Song/The Verge)
https://www.theverge.com/news/762048/googles-pixel-buds-pro-2…
»Kernenergie erzeugt kein CO2 und ist deshalb die Lösung für unser Energieproblem.« Es ist natürlich nicht ganz so simpel, wie diese Sorte populistischer Parolen. Der Beitrag "Milliardengrab Atomkraft" von 2022 (50min) beleuchtet da ein paar problematische Ecken. Leider werden diejenigen, die da aufmerksam zuhören sollten, auch hier konsequent weghören. Podcast-Empfehlung trotzdem:
Zahlen, bitte! 74 Minuten – Die krumme Abspieldauer der Audio-CD
Geschichten ranken sich um die 74-Minuten-Abspieldauer der CD: offiziell um Beethovens 9. Symphonie komplett abzuspielen ist der wahre Grund wohl profaner.
There are few investments more valuable than a set of good speakers and headphones. It makes such a vast difference when you’re listening to your favourite music every day. 😍🎶
My setup atm:
🎧 Austrian Audio Hi-X60
https://austrian.audio/product/hi-x60/
🔈 ADAM Audio T5V
DegDiT: Controllable Audio Generation with Dynamic Event Graph Guided Diffusion Transformer
Yisu Liu, Chenxing Li, Wanqian Zhang, Wenfu Wang, Meng Yu, Ruibo Fu, Zheng Lin, Weiping Wang, Dong Yu
https://arxiv.org/abs/2508.13786
InfiniteTalk: Audio-driven Video Generation for Sparse-Frame Video Dubbing
Shaoshu Yang, Zhe Kong, Feng Gao, Meng Cheng, Xiangyu Liu, Yong Zhang, Zhuoliang Kang, Wenhan Luo, Xunliang Cai, Ran He, Xiaoming Wei
https://arxiv.org/abs/2508.14033
AVL Drumkits and New Jams
# music #improvisation I have been using the Hydrogen drum sequencer to make drum grooves. I was saving them as audio files because when I saved them as midi files, the drum mapping was usually off for the drum kit plugins I had in Reaper. The disadvantages of this approach are a) I can't change the tempo, and b) I can't modify the groove by addin…
Inside Apple's Audio Labs, where the company develops features like spatial audio and uses tuning studios as reference points for AirPods and other products (Lance Ulanoff/TechRadar)
https://www.
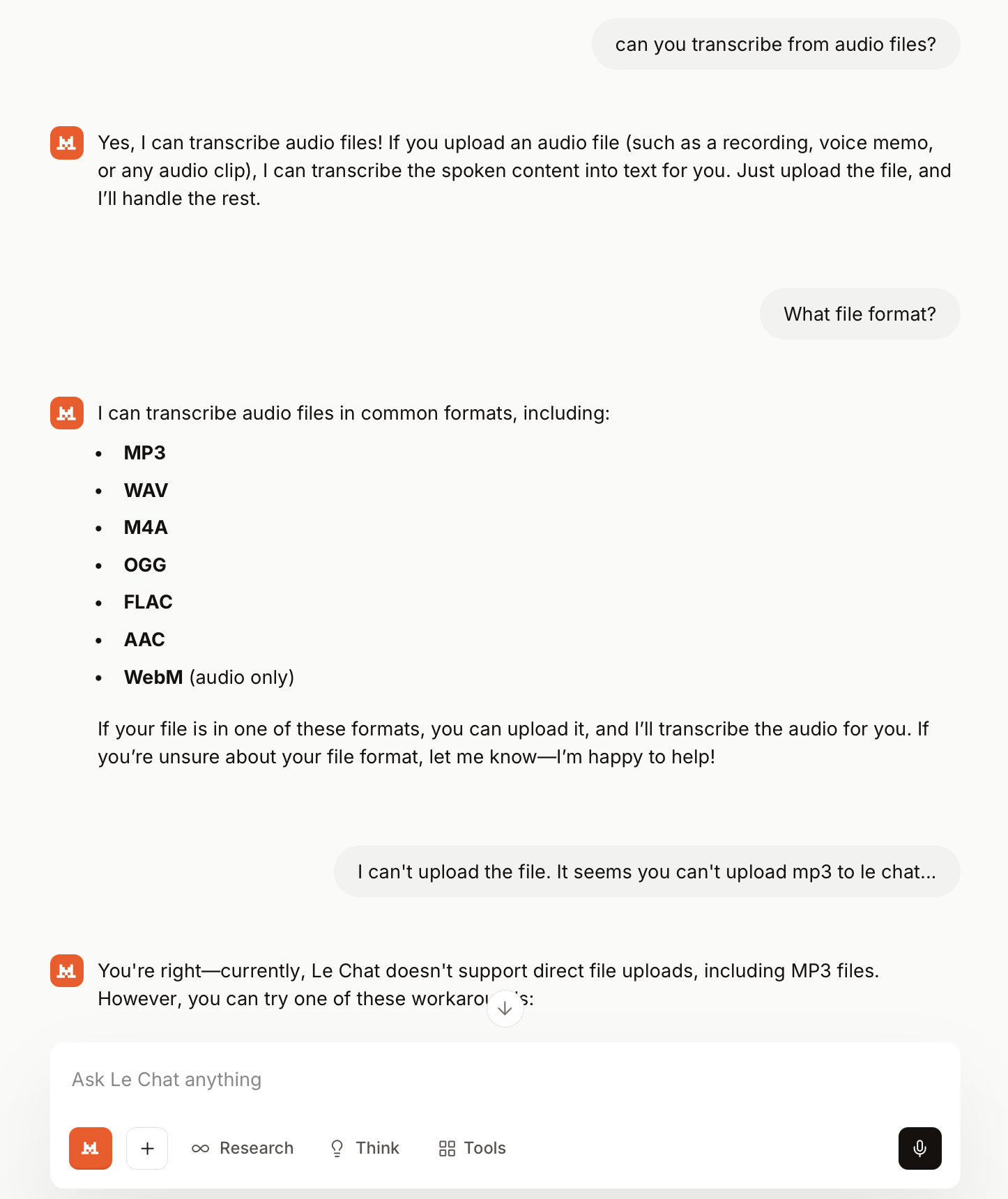
Can you transcribe from audio files? #AI #mistralai
MMAU-Pro: A Challenging and Comprehensive Benchmark for Holistic Evaluation of Audio General Intelligence
Sonal Kumar, \v{S}imon Sedl\'a\v{c}ek, Vaibhavi Lokegaonkar, Fernando L\'opez, Wenyi Yu, Nishit Anand, Hyeonggon Ryu, Lichang Chen, Maxim Pli\v{c}ka, Miroslav Hlav\'a\v{c}ek, William Fineas Ellingwood, Sathvik Udupa, Siyuan Hou, Allison Ferner, Sara Barahona, Cecilia Bola\~nos, Satish Rahi, Laura Herrera-Alarc\'on, Satvik Dixit, Siddhi Patil, Soham Deshmukh, Lasha K…
Trying out https://www.huxe.com/ , a tool for AI generated personal podcasts about anything you want, not perfect, but works great for certain categories, like a podcast about the great hackernews post of today or main AI industry headline, very convenient when commuting.
Threat Modeling for Enhancing Security of IoT Audio Classification Devices under a Secure Protocols Framework
Sergio Benlloch-Lopez, Miquel Viel-Vazquez, Javier Naranjo-Alcazar, Jordi Grau-Haro, Pedro Zuccarello
https://arxiv.org/abs/2509.14657
PSA about common connectors on audio and phone equipment:
The "audio jack" on headphones etc. is called a "phone connector" (it was first used for phone switchboards all the way back in the 1800s).
The "phone jack" on telephones (looks like a smaller Ethernet jack) is called a "registered jack".
The "audio connector" on analog audio and video cables is called a "RCA plug".
Now you know jack shit.
I’ve worked over the past year to reduce the amount of noise in my consciousness on a daily basis.
By that I mean - information noise, not literal sounds “noise”. (That problem was solved long ago by some good earplugs and noise canceling earphones.)
I’ve gotten used to spending less time on social media, regularly blocking most apps on my devices (anything with a feed news, most work communication apps, etc.), putting my phone and other devices aside for extended periods of time. Often go to work places with my iPad explicitly having its WiFi turned off and selecting cafes that don’t offer WiFi at all.
Negotiated better boundaries at work and in personal life where I exchange messages with people less often but try to make those interactions more meaningful, and people rarely expect me to respond to requests in less than 24 hours. Spent a lot of time setting up custom notification settings on all apps that would allow it, so I get fewer pings. With software, choosing fewer cloud-based options and using tools that are simple and require as few interruptions as possible.
Accustomed myself to lower-tech versions of doing things I like to do: reading on paper, writing by hand, drawing in physical sketchbooks, got a typewriter for typing without a screen. Choosing to call people on audio more, trying to make more of an effort to see people in person. Going to museums to look at art instead of browsing Pinterest. Defaulting to the library when looking for information.
I’m commenting on this now for two reasons:
1. I am pretty proud of myself for how much I’ve actually managed to reduce the constant stream of modern life esp. as a remote worker in tech!
2. Now that I’ve reached a breaking point of reducing enough noise that it’s NOTICEABLE - I am struck by the silence. I don’t know what to do with it. I don’t know how to navigate it and fill it. I made this space to be able to read and write and think more deeply - for now I feel stuck in limbo where I’m just reacquainting myself with the concept of having any space in my mind at all.
MAGIC-Enhanced Keyword Prompting for Zero-Shot Audio Captioning with CLIP Models
Vijay Govindarajan, Pratik Patel, Sahil Tripathi, Md Azizul Hoque, Gautam Siddharth Kashyap
https://arxiv.org/abs/2509.12591
Towards Automatic Evaluation and High-Quality Pseudo-Parallel Dataset Construction for Audio Editing: A Human-in-the-Loop Method
Yuhang Jia, Hui Wang, Xin Nie, Yujie Guo, Lianru Gao, Yong Qin
https://arxiv.org/abs/2508.11966
FakeHunter: Multimodal Step-by-Step Reasoning for Explainable Video Forensics
Chen Chen, Runze Li, Zejun Zhang, Pukun Zhao, Fanqing Zhou, Longxiang Wang, Haojian Huang
https://arxiv.org/abs/2508.14581 …
Crosslisted article(s) found for cs.AI. https://arxiv.org/list/cs.AI/new
[4/6]:
- End-to-End Audio-Visual Learning for Cochlear Implant Sound Coding in Noisy Environments
Meng-Ping Lin, Enoch Hsin-Ho Huang, Shao-Yi Chien, Yu Tsao
Cooles Feature. Ich bin kein großer AI Fan gleichzeitig sehe ich bei Transkription tatsächlich Potenzial. Und nahtlos und offline SRT Dateien erstellen zu lassen ist super.
FFmpeg 8.0 integriert Whisper: Lokale Audio-Transkription ohne Cloud | heise online
Okay, got the new version finished. The BNC connectors are for RGB Sync, and the other two BNC connectors were removed and replaced with a DB9 connector for the glory that is CGA. Kept the RCA audio port on the side of the board because audio will mostly go in directly to the PVM. Overall I'm much more satisfied with this layout and connector choice than the previous version.
#electronics
Braucht ihr Audio- oder Bühnenequipment? Wir kaufen viel bei DJ-checkpoint.de (vor allem Lampen, Kabel, aber die haben auch Mikrofone und alles andere)— mit dem Code DARKK gibt es da 5 % Rabatt (wir kriegen davon nichts). Chef Daniel ist einfach ein guter Typ, kann man supporten.
Vielleicht habt ihr ein paar Musikanten-FreundInnen, die das interessiert. 🚀
Teacher-Guided Pseudo Supervision and Cross-Modal Alignment for Audio-Visual Video Parsing
Yaru Chen, Ruohao Guo, Liting Gao, Yang Xiang, Qingyu Luo, Zhenbo Li, Wenwu Wang
https://arxiv.org/abs/2509.14097
LEHMANN Audio 007 - Raphael Dincsoy b2b Tamara Wirth by Lehmann Club / Labor Lehmann
https://on.soundcloud.com/PrAOEQSO0h2uIRJx0E
Raphael Dincsoy:
SoundCloud:
What's the equivalent of #Immich but for audio and video files?
I'm looking for a self-hostable #FOSS thing that I can throw the rest of my media library in the face (movies, music, downloaded youtube videos, etc.) and it'll sort everything nicely, maybe even query databases to find metada…
A look at the video podcasting surge; study: ~75% of podcast consumers play video episodes and ~30% play video episodes minimized or in background mode (Joseph Bernstein/New York Times)
https://www.nytimes.com/2025/07/20/style/p
New audio - What is happening with the Linux Professional Institute (LPI) certification program? Over the weekend I sat down with Matt Rice, LPI's Executive Director. Way back in 1998/99, I was one of the co-founders of LPI, but haven't been involved in 20 years until I was recently inducted into LPI's "Hall of Fellows". Matt visited me in Vermont to give me the physical award, and so I pulled out the microphones to learn more. 🙂
The last few days, #Slack, which I only use via a browser, keeps asking for video and audio permission, even though I'm not joining a call or using their audio feature.
Is slack trying to steal my #data and I'm only noticing because I monitor and track all such requests due to
At Berlin Buzzwords 2025, Dhrubo Saha discussed how OpenSearch pipelines are integrating ML inference processors for powerful multi-modal search. Learn to search directly within images, audio, and text – locally on your own hardware!
Watch the full session: https://youtu.be/eg3NoKFxvzA?si=cP3o1p5tTQo-UZSA
Berlin Buzzwords returns on 7-9 June 2026! Get 36% off with our Trust Us Ticket: https://tickets.plainschwarz.com/bbuzz26/c/8Hvk0ZvJA/
Leveraging Mamba with Full-Face Vision for Audio-Visual Speech Enhancement
Rong Chao, Wenze Ren, You-Jin Li, Kuo-Hsuan Hung, Sung-Feng Huang, Szu-Wei Fu, Wen-Huang Cheng, Yu Tsao
https://arxiv.org/abs/2508.13624
YouTube: Multilanguage-Audio ab sofort für alle verfügbar
Zwei Jahre lang testete YouTube mit ausgewählten Kanälen das Bereitstellen eigener Übersetzungen. In Kürze sollen alle Creator die Funktion erhalten.
http…
Replaced article(s) found for cs.AI. https://arxiv.org/list/cs.AI/new
[4/4]:
- When Good Sounds Go Adversarial: Jailbreaking Audio-Language Models with Benign Inputs
Kim, Dingeto, Kwon, Choi, Lee, Park, Lee, Shin
Google Fi plans an AI call quality feature to filter out background sounds like wind next month, and will bring full RCS support on the web in December (Ryan Whitwam/Ars Technica)
https://arstechnica.com/gadgets/2025/10/google-…
Ges-QA: A Multidimensional Quality Assessment Dataset for Audio-to-3D Gesture Generation
Zhilin Gao, Yunhao Li, Sijing Wu, Yuqin Cao, Huiyu Duan, Guangtao Zhai
https://arxiv.org/abs/2508.12020
OpenBEATs: A Fully Open-Source General-Purpose Audio Encoder
Shikhar Bharadwaj, Samuele Cornell, Kwanghee Choi, Satoru Fukayama, Hye-jin Shim, Soham Deshmukh, Shinji Watanabe
https://arxiv.org/abs/2507.14129
Finally cleaned up and reorganized the consoles along with some of the audio stuff. I really need to dust more often...
#retroconsoles
Exploring How Audio Effects Alter Emotion with Foundation Models
Stelios Katsis, Vassilis Lyberatos, Spyridon Kantarelis, Edmund Dervakos, Giorgos Stamou
https://arxiv.org/abs/2509.15151
Mitigating data replication in text-to-audio generative diffusion models through anti-memorization guidance
Francisco Messina, Francesca Ronchini, Luca Comanducci, Paolo Bestagini, Fabio Antonacci
https://arxiv.org/abs/2509.14934
StableAvatar: Infinite-Length Audio-Driven Avatar Video Generation
Shuyuan Tu, Yueming Pan, Yinming Huang, Xintong Han, Zhen Xing, Qi Dai, Chong Luo, Zuxuan Wu, Yu-Gang Jiang
https://arxiv.org/abs/2508.08248
YouTube rolls out multi-language audio after a two-year pilot, saying creators saw 25% of watch time coming from views in their video's non-primary language (Lauren Forristal/TechCrunch)
https://techcrunch.com/2025/09/10/yout
LD-LAudio-V1: Video-to-Long-Form-Audio Generation Extension with Dual Lightweight Adapters
Haomin Zhang, Kristin Qi, Shuxin Yang, Zihao Chen, Chaofan Ding, Xinhan Di
https://arxiv.org/abs/2508.11074
Not in Sync: Unveiling Temporal Bias in Audio Chat Models
Jiayu Yao, Shenghua Liu, Yiwei Wang, Rundong Cheng, Lingrui Mei, Baolong Bi, Zhen Xiong, Xueqi Cheng
https://arxiv.org/abs/2510.12185
Spatial-CLAP: Learning Spatially-Aware audio--text Embeddings for Multi-Source Conditions
Kentaro Seki, Yuki Okamoto, Kouei Yamaoka, Yuki Saito, Shinnosuke Takamichi, Hiroshi Saruwatari
https://arxiv.org/abs/2509.14785
MATPAC : Enhanced Masked Latent Prediction for Self-Supervised Audio Representation Learning
Aurian Quelennec, Pierre Chouteau, Geoffroy Peeters, Slim Essid
https://arxiv.org/abs/2508.12709
Cross-Modal Knowledge Distillation with Multi-Level Data Augmentation for Low-Resource Audio-Visual Sound Event Localization and Detection
Qing Wang, Ya Jiang, Hang Chen, Sabato Marco Siniscalchi, Jun Du, Jianqing Gao
https://arxiv.org/abs/2508.12334
Spotify plans to roll out lossless, offering 24-bit / 44.1 kHz FLAC audio, to all Premium users in the next two months, without needing a new higher-priced tier (Terrence O'Brien/The Verge)
https://www.theverge.com/spotify/775189/spotify-lossless-streaming-f…
DAIEN-TTS: Disentangled Audio Infilling for Environment-Aware Text-to-Speech Synthesis
Ye-Xin Lu, Yu Gu, Kun Wei, Hui-Peng Du, Yang Ai, Zhen-Hua Ling
https://arxiv.org/abs/2509.14684
RFM-Editing: Rectified Flow Matching for Text-guided Audio Editing
Liting Gao, Yi Yuan, Yaru Chen, Yuelan Cheng, Zhenbo Li, Juan Wen, Shubin Zhang, Wenwu Wang
https://arxiv.org/abs/2509.14003
Meta announces the Oakley Meta Vanguard, with a 12MP wide-angle camera, Garmin and Strava integrations, and immersive audio, launching on October 21 for $499 (Aisha Malik/TechCrunch)
https://techcrunch.com/2025/09/17/meta-unveils-its-ne…
Enhancing Situational Awareness in Wearable Audio Devices Using a Lightweight Sound Event Localization and Detection System
Jun-Wei Yeow, Ee-Leng Tan, Santi Peksi, Zhen-Ting Ong, Woon-Seng Gan
https://arxiv.org/abs/2509.14650
Comprehensive Evaluation of CNN-Based Audio Tagging Models on Resource-Constrained Devices
Jordi Grau-Haro, Ruben Ribes-Serrano, Javier Naranjo-Alcazar, Marta Garcia-Ballesteros, Pedro Zuccarello
https://arxiv.org/abs/2509.14049
Google Pixel 8 and newer models can now stream audio to multiple headphones at once with expanded Bluetooth LE Audio and Auracast support (Terrence O'Brien/The Verge)
https://www.theverge.com/news/770233/google-android-bluetooth-audio-le-multipl…
Audio Flamingo Sound-CoT Technical Report: Improving Chain-of-Thought Reasoning in Sound Understanding
Zhifeng Kong, Arushi Goel, Joao Felipe Santos, Sreyan Ghosh, Rafael Valle, Wei Ping, Bryan Catanzaro
https://arxiv.org/abs/2508.11818
Diffusion-Based Unsupervised Audio-Visual Speech Separation in Noisy Environments with Noise Prior
Yochai Yemini, Rami Ben-Ari, Sharon Gannot, Ethan Fetaya
https://arxiv.org/abs/2509.14379
Exploring Self-Supervised Audio Models for Generalized Anomalous Sound Detection
Bing Han, Anbai Jiang, Xinhu Zheng, Wei-Qiang Zhang, Jia Liu, Pingyi Fan, Yanmin Qian
https://arxiv.org/abs/2508.12230
UALM: Unified Audio Language Model for Understanding, Generation and Reasoning
Jinchuan Tian, Sang-gil Lee, Zhifeng Kong, Sreyan Ghosh, Arushi Goel, Chao-Han Huck Yang, Wenliang Dai, Zihan Liu, Hanrong Ye, Shinji Watanabe, Mohammad Shoeybi, Bryan Catanzaro, Rafael Valle, Wei Ping
https://arxiv.org/abs/2510.12000
Cross-Lingual F5-TTS: Towards Language-Agnostic Voice Cloning and Speech Synthesis
Qingyu Liu, Yushen Chen, Zhikang Niu, Chunhui Wang, Yunting Yang, Bowen Zhang, Jian Zhao, Pengcheng Zhu, Kai Yu, Xie Chen
https://arxiv.org/abs/2509.14579
Perturbed Public Voices (P$^{2}$V): A Dataset for Robust Audio Deepfake Detection
Chongyang Gao, Marco Postiglione, Isabel Gortner, Sarit Kraus, V. S. Subrahmanian
https://arxiv.org/abs/2508.10949
SeeingSounds: Learning Audio-to-Visual Alignment via Text
Simone Carnemolla, Matteo Pennisi, Chiara Russo, Simone Palazzo, Daniela Giordano, Concetto Spampinato
https://arxiv.org/abs/2510.11738
A long-form single-speaker real-time MRI speech dataset and benchmark
Sean Foley, Jihwan Lee, Kevin Huang, Xuan Shi, Yoonjeong Lee, Louis Goldstein, Shrikanth Narayanan
https://arxiv.org/abs/2509.14479
Crosslisted article(s) found for cs.SD. https://arxiv.org/list/cs.SD/new
[1/1]:
- End-to-End Audio-Visual Learning for Cochlear Implant Sound Coding in Noisy Environments
Meng-Ping Lin, Enoch Hsin-Ho Huang, Shao-Yi Chien, Yu Tsao
MRSAudio: A Large-Scale Multimodal Recorded Spatial Audio Dataset with Refined Annotations
Wenxiang Guo, Changhao Pan, Zhiyuan Zhu, Xintong Hu, Yu Zhang, Li Tang, Rui Yang, Han Wang, Zongbao Zhang, Yuhan Wang, Yixuan Chen, Hankun Xu, Ke Xu, Pengfei Fan, Zhetao Chen, Yanhao Yu, Qiange Huang, Fei Wu, Zhou Zhao
https://arxiv.org/abs/2510.1039…
 @jamesthebard@social.linux.pizza
@jamesthebard@social.linux.pizza