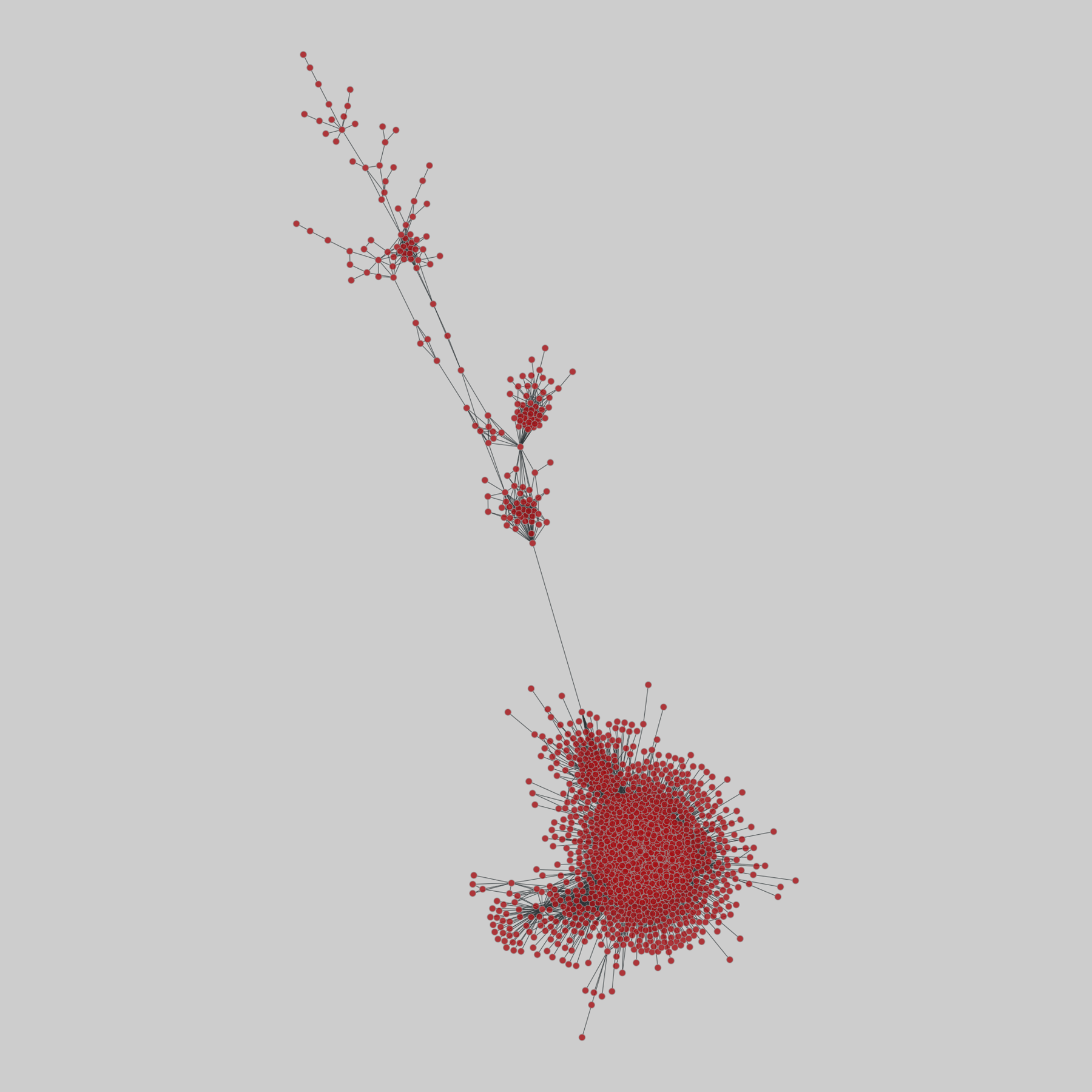
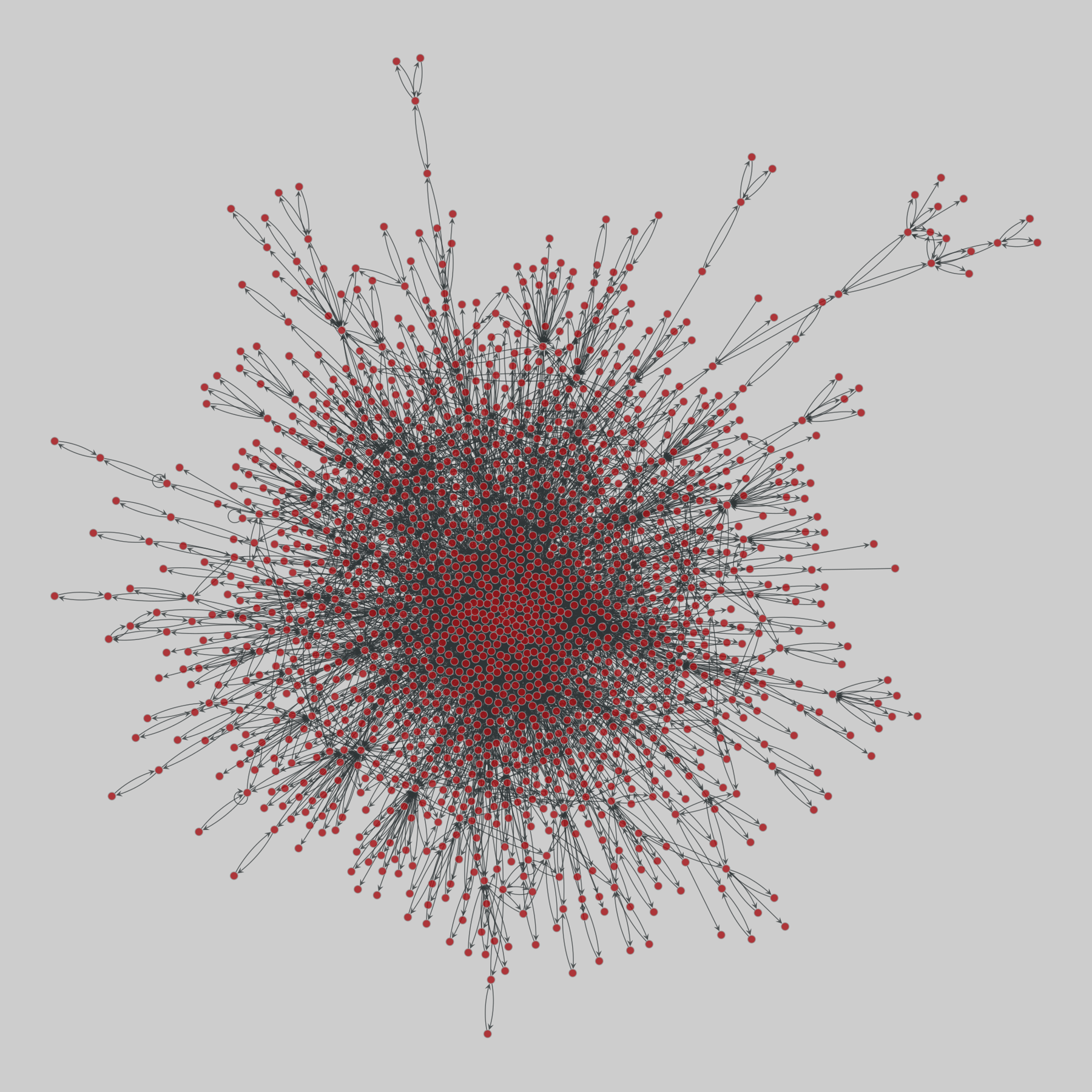
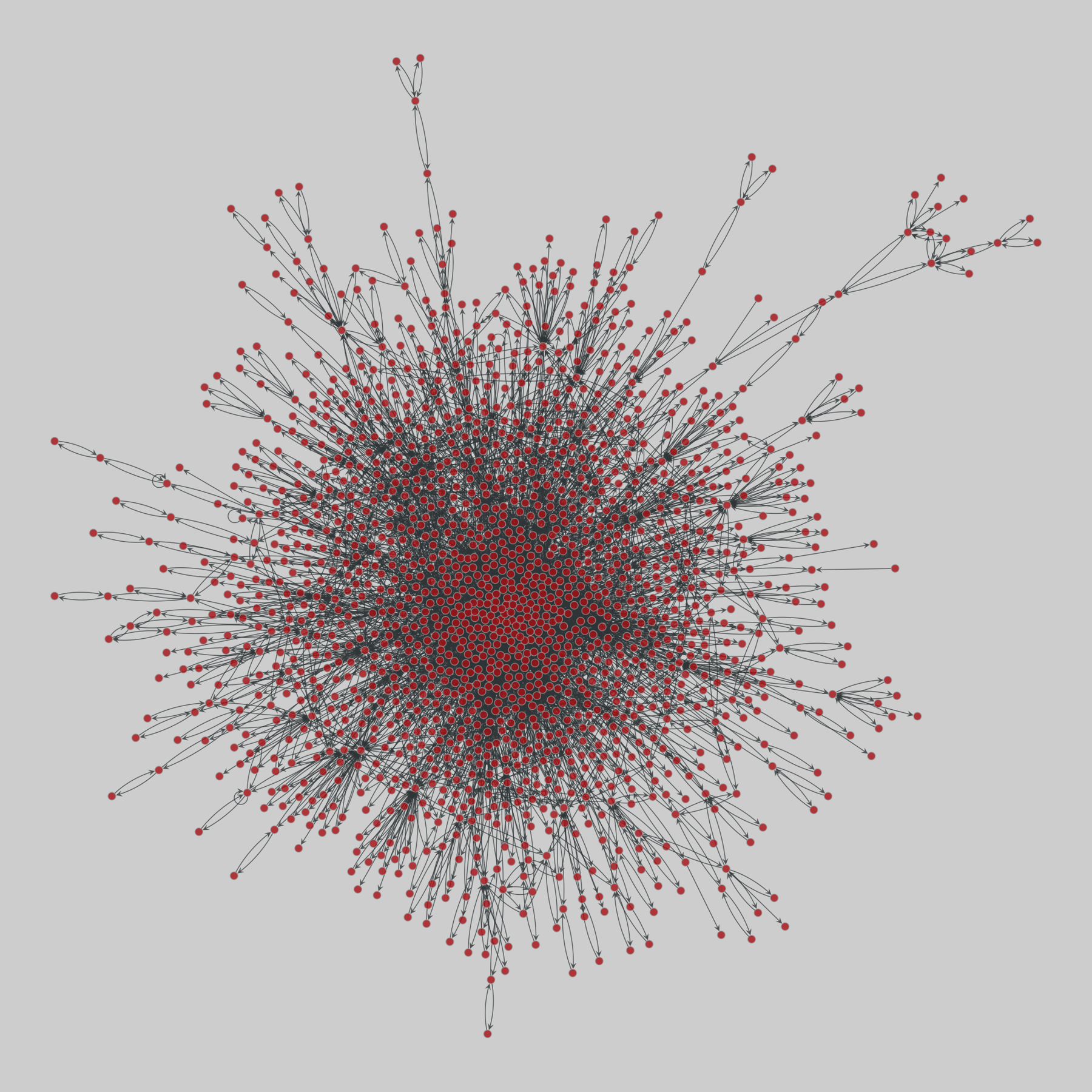
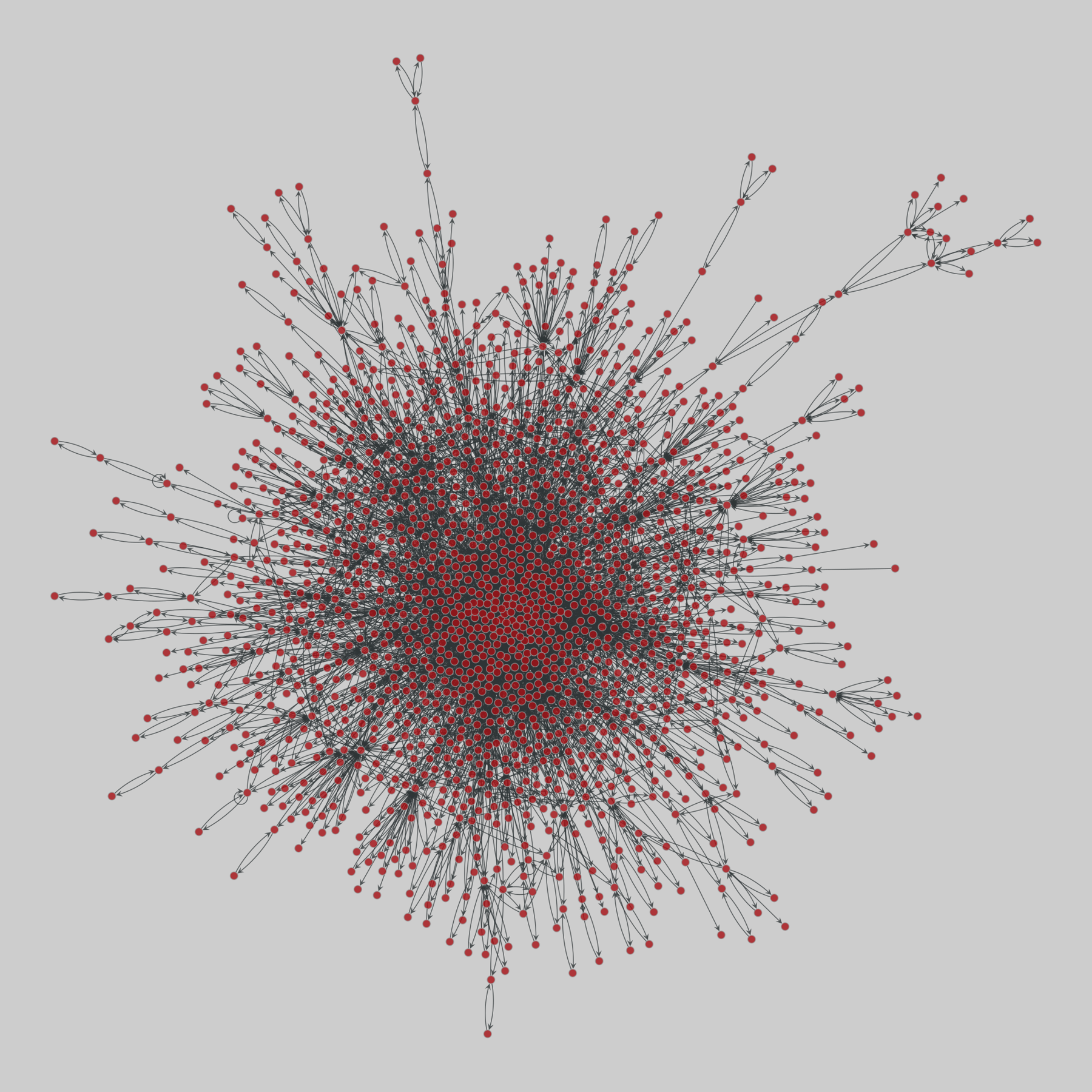
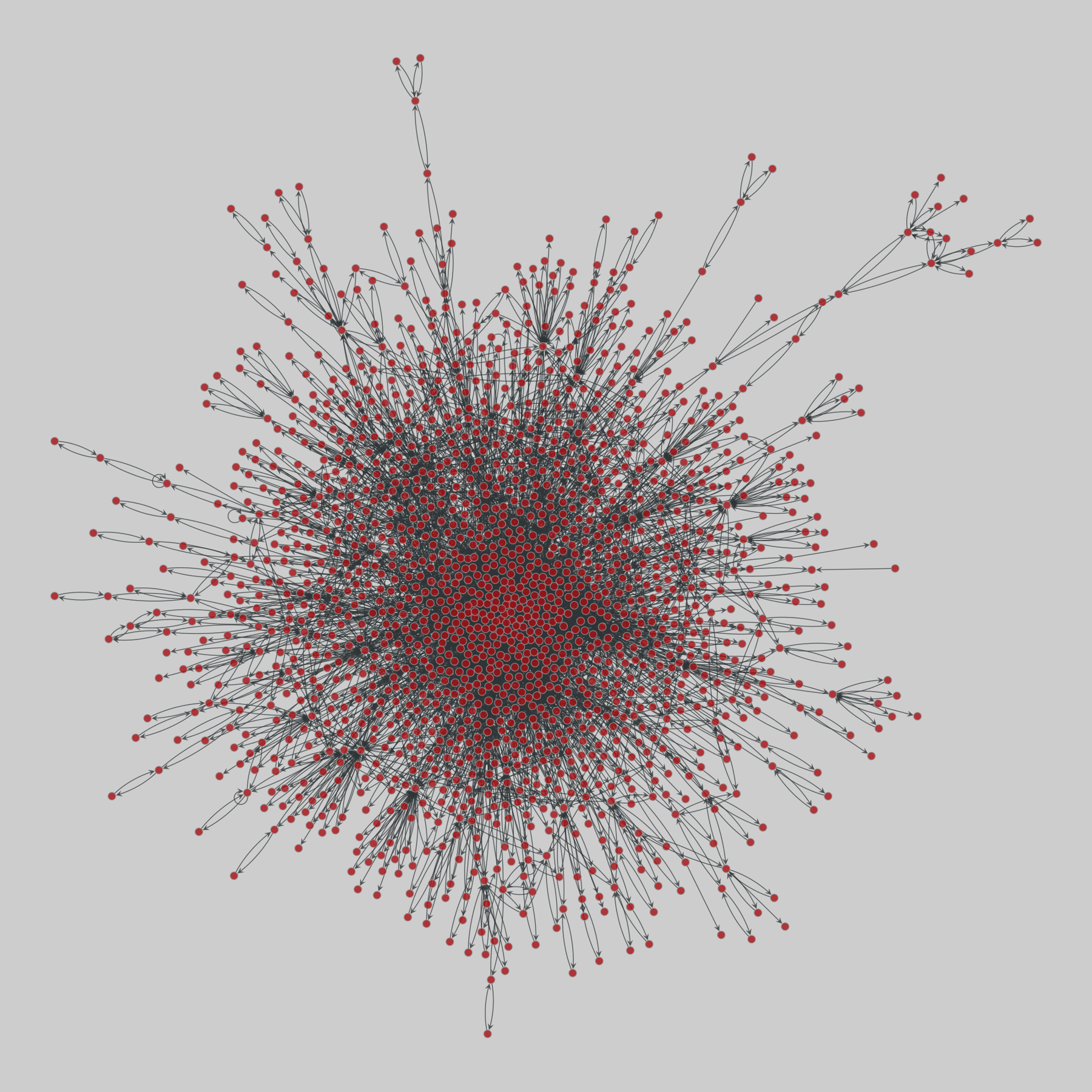
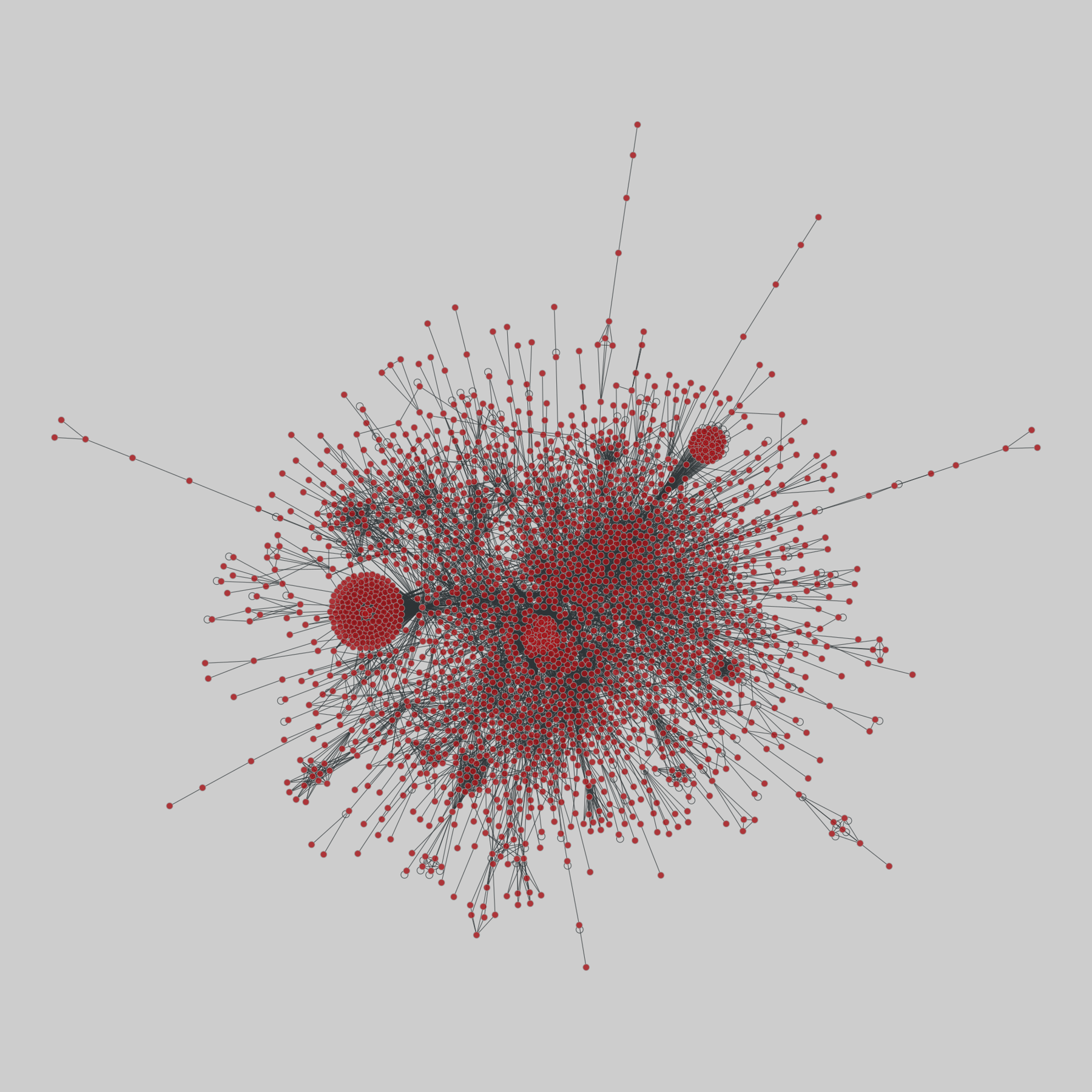
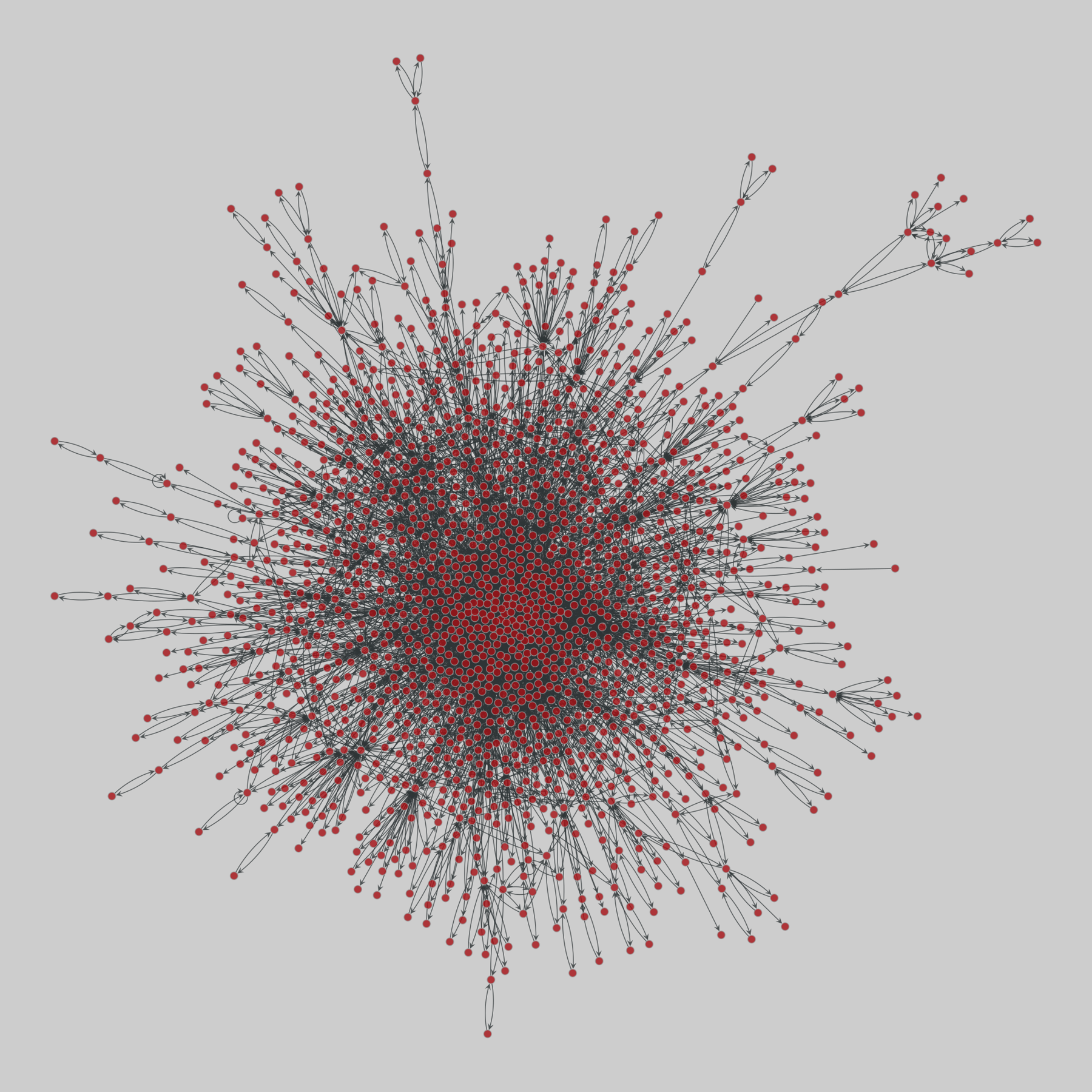
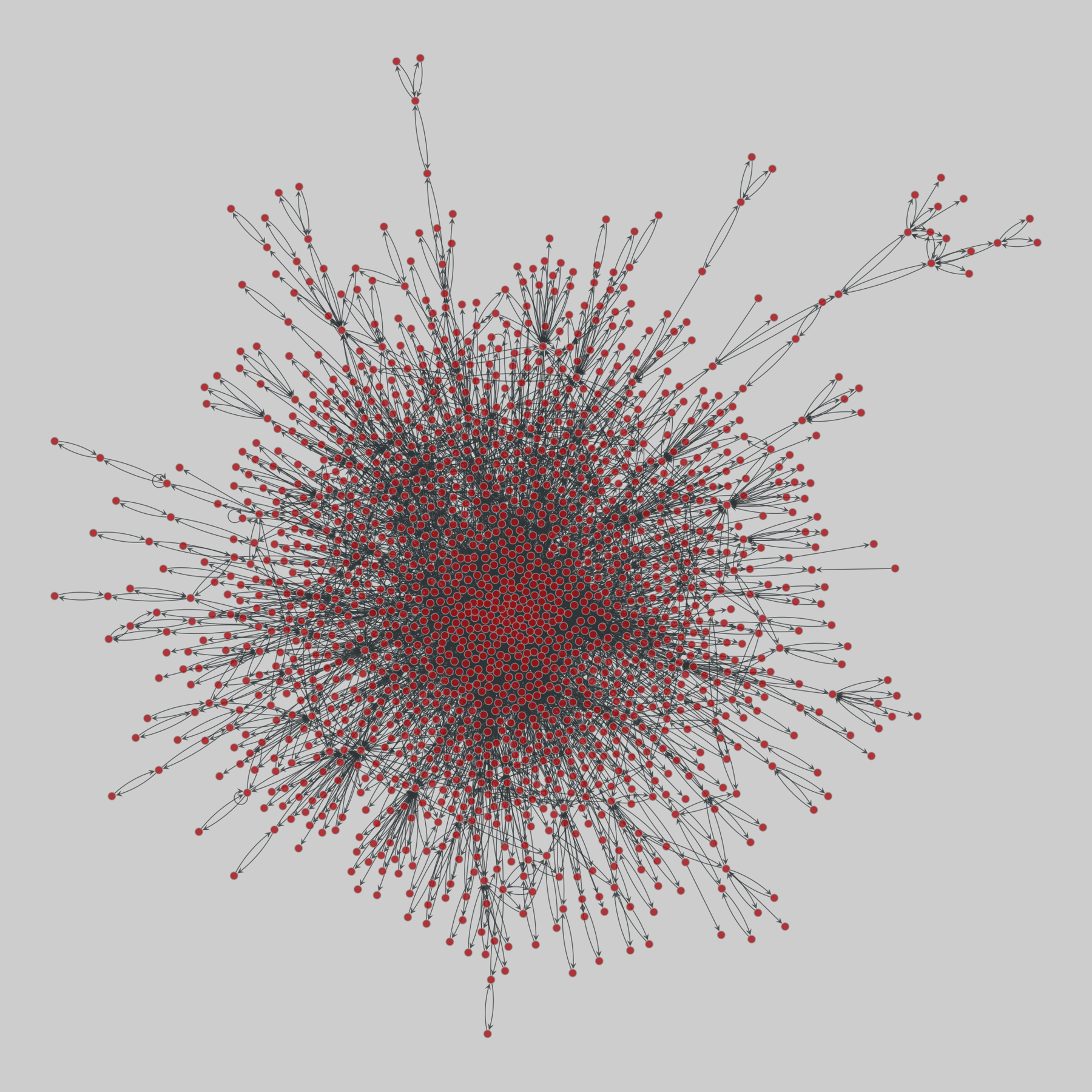
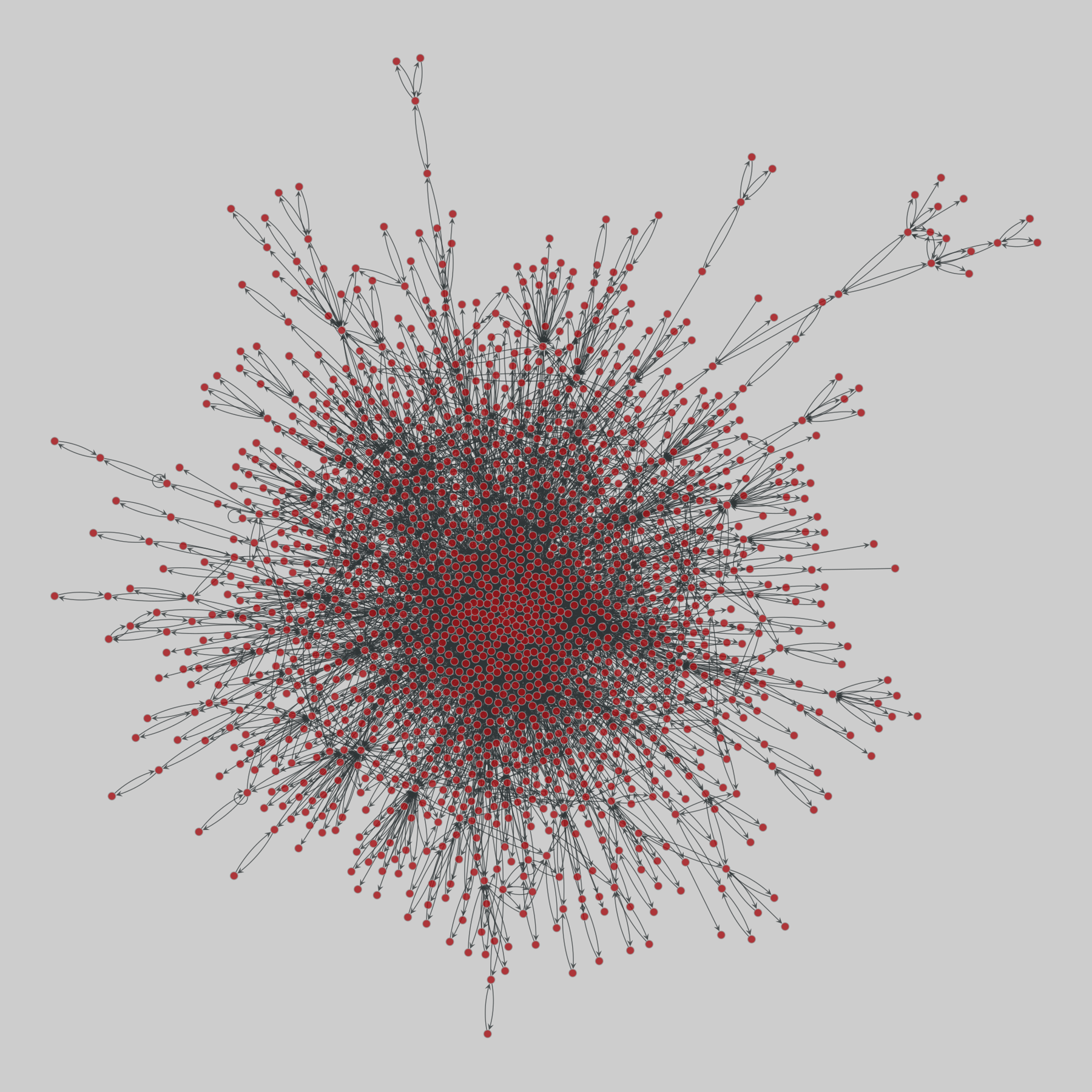
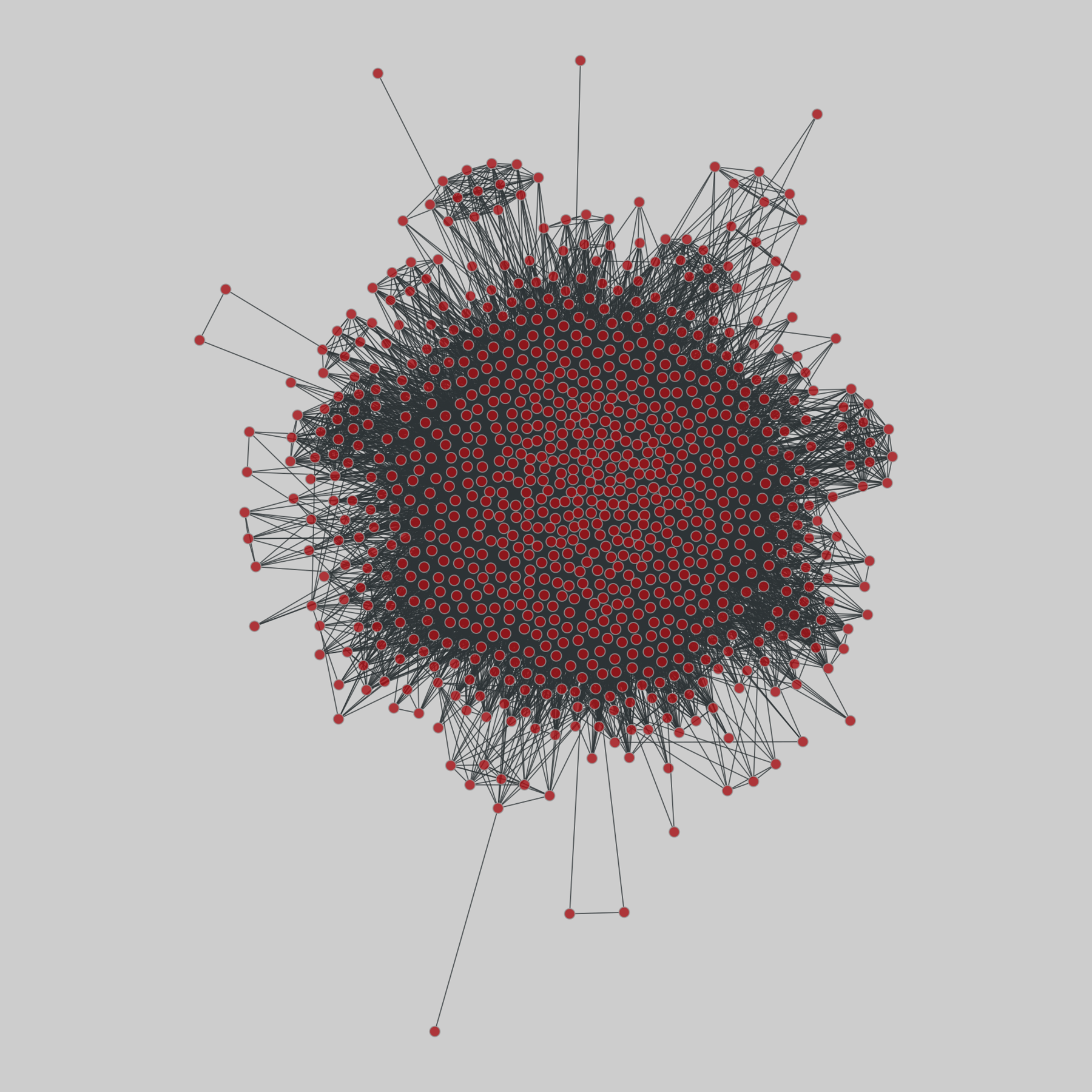
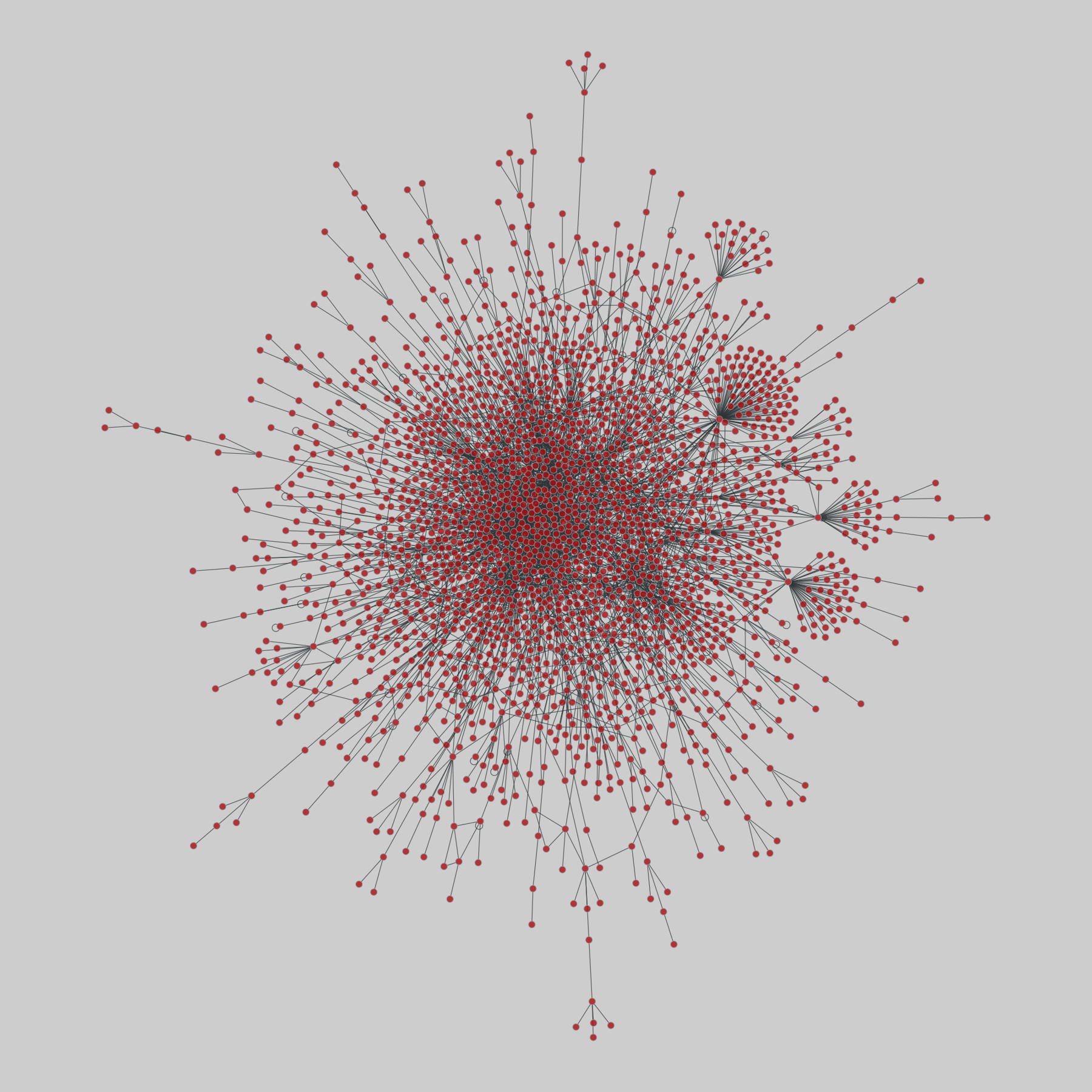
celegans_interactomes: C. elegans interactomes (2009)
Ten networks of protein-protein interactions in Caenorhabditis elegans (nematode), from yeast two-hybrid experiments, biological process maps, literature curation, orthologous interactions, and genetic interactions. The WI8 network combines WI2004, WI2007 and BPmaps, while the Integrated Network combines data from all sources.
This network has 2436 nodes and 136930 edges.
Tags: Biological, Protein interactions, Unweighte…
Burner accounts on social media sites can increasingly be analyzed to identify the pseudonymous users who post to them using
AI in research that has far-reaching consequences for privacy on the Internet, researchers said.
The finding, from a recently published research paper, is based on results of experiments correlating specific individuals with accounts or posts across more than one social media platform.
The success rate was far greater than existing classical deanonymiz…
:git: #TIL Put the line
**/*__gitignore__*
in your ~/.gitignore_global file to ignore any file or directory whose name contains __gitignore__ anywhere in the path.
This handy little glob trick allows you to quickly create a space for temporary files, ad-hoc-experiments or other "stuff" you want to keep out of version control (and also out of you versioned repo-specific…
I was explaining to GF last night about all the science that #NASA does above & beyond just shooting stuff into space. Things like "how do you get x ppl to live in a confined space for years without going insane or killing each other". One of the things that experiments like #BioSphere (despite not bein…
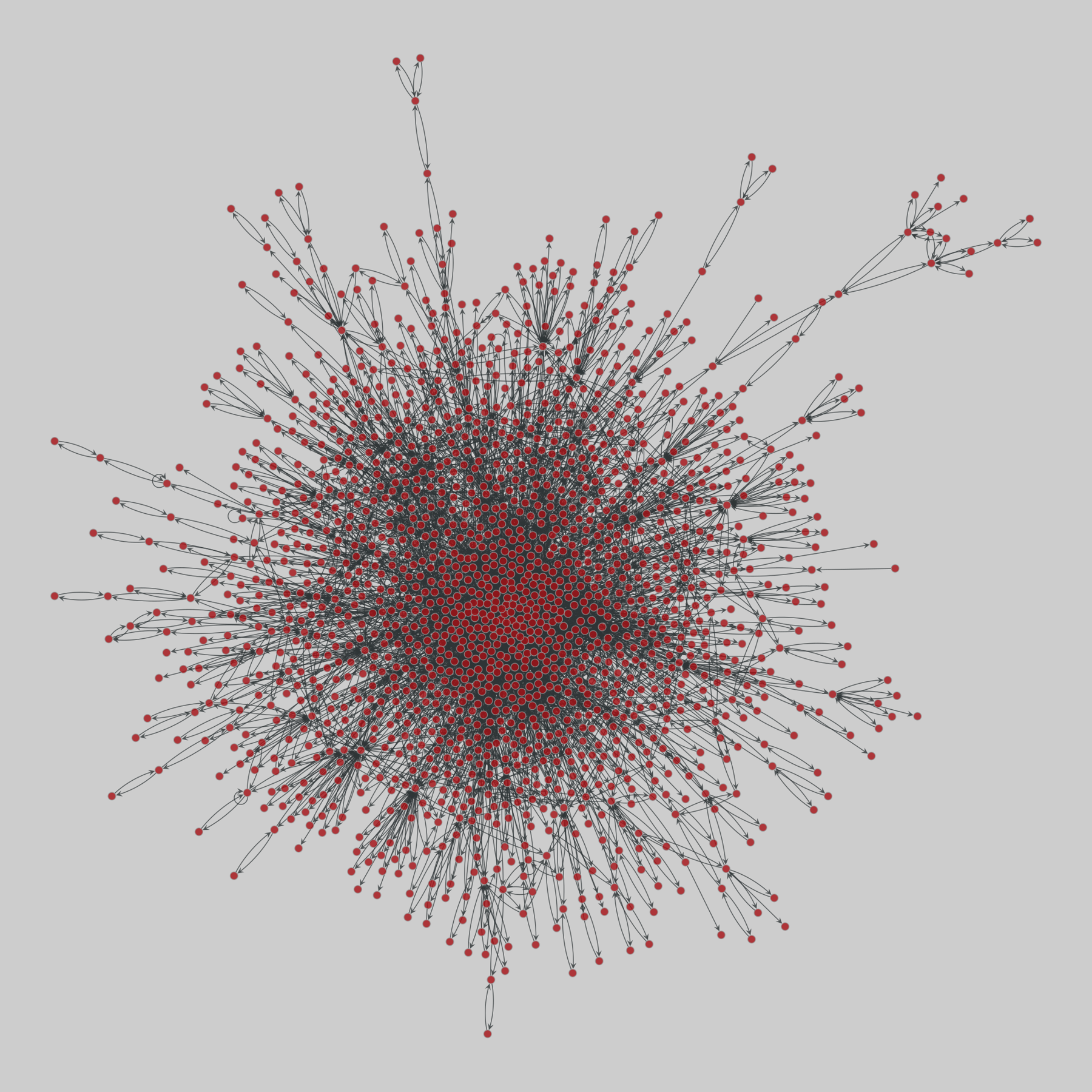
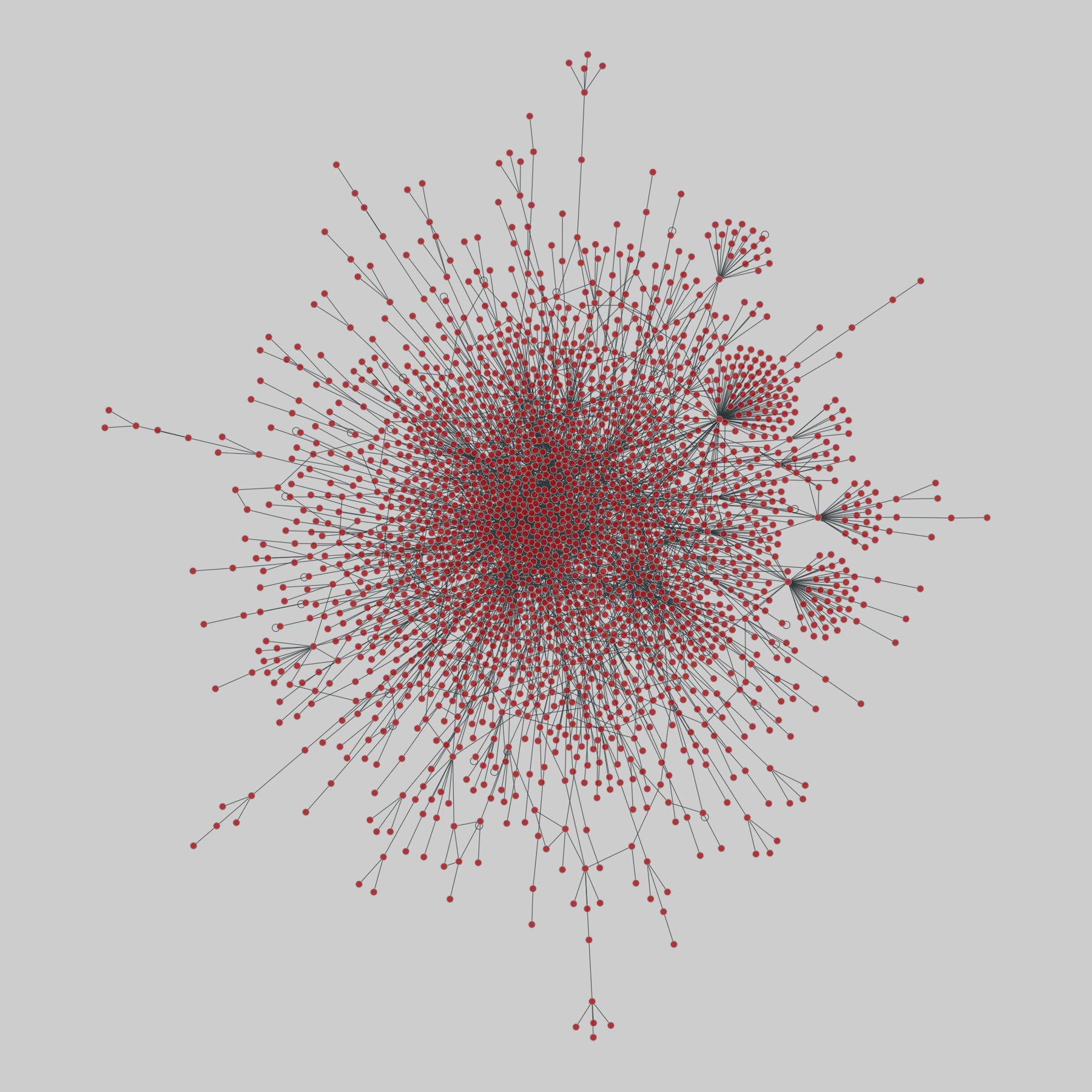
interactome_stelzl: Stelzl human interactome (2005)
A network of human proteins and their binding interactions. Nodes represent proteins and an edge represents an interaction between two proteins, as inferred via high-throughput Y2H experiments using bait and prey methodology.
This network has 1706 nodes and 6207 edges.
Tags: Biological, Protein interactions, Unweighted
An excerpt from the book The Infinity Machine details how DeepMind's early governance battles with Google changed Demis Hassabis from an idealist into a realist (Sebastian Mallaby/Colossus)
https://colossus.com/article/project-mario-demis-hassabis-deepmind-mal…
Last night, I sauteed green beans in sesame oil with garlic, ginger, and chili paste. It was fantastic
Other fun recent cooking experiments:
★ grilled cheese with "Vampire Slayer" garlic cheddar cheese and garam masala
★ curried red lentils from fresh turmeric, ginger, and garlic
★ chicken with sherry shitake mushroom cream sauce
★ chicken pasta with lemon caper mushroom sauce
★ chocolate pudding with chocolate peppermint liqueur made into a mousse w…
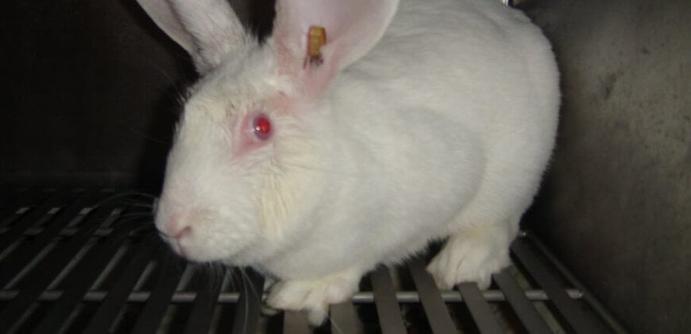
Baboon babies suffer in horrible UMB experiments #wildlife
A talk full of fun experiments and nerdy rabbit holes by @… at #btconf, dragging the web out of the browser and into oscilloscopes, laser projectors, and (where legal) flamethrowers. And all of that with the not-a-programming-language – CSS 🤩🔥
Experimental study of turbulent thermal diffusion of inertial particles in a convective turbulence forced by oscillating grids
E. Elmakies, O. Shildkrot, N. Kleeorin, A. Levy, I. Rogachevskii
https://arxiv.org/abs/2602.22008 https://arxiv.org/pdf/2602.22008 https://arxiv.org/html/2602.22008
arXiv:2602.22008v1 Announce Type: new
Abstract: We investigate the phenomenon of turbulent thermal diffusion of inertial solid particles in laboratory experiments with convective turbulence forced by one or two oscillating grids in the air flow. Turbulent thermal diffusion causes a non-diffusive contribution to turbulent flux of particles described in terms of an effective pumping velocity directed opposite to the gradient of the mean fluid temperature. For inertial particles, this effective pumping velocity depends on the Stokes and Reynolds numbers. In the experiments, fluid velocity and spatial distribution of inertial particles are measured using Particle Image Velocimetry system, and the temperature field is measured in many locations by a temperature probe equipped with 12 thermocouples. Measurements of temperature and particle number density spatial distributions have demonstrated formation of large-scale clusters of inertial particles in the vicinity of the mean temperature minimum due to turbulent thermal diffusion. In the experiments, the effective pumping velocity resulting in formation of large-scale clusters of inertial particles (having the diameter $10 \mu m$) is in 2.5 times larger than that for non-inertial particles (having the diameter $0.7 \mu m$). This is in an agreement with the theoretical predictions.
toXiv_bot_toot
Juo Collab
Through filmed conversations, rehearsal sessions and creative experiments, new work is developed in real time, original work is discussed and workshopped, culminating in a live performance...
Great Australian Pods Podcast Directory: https://www.greataustralianpods.com/juo-co
Please call on Monash University to immediately end animal experiments and commit to ethical, human-relevant research, and in calling on those who funded, approved, and published these experiments to cease doing so in the future. https://act.pcrm.org/cf0kueCL-Em8DolD0UFgLQ2
There’s also knowledge that is not derived from scientific experiments or observation.
For example, the very fundamentals of mathematics are literally just agreed upon statements taken to be true.
(This is referred to as an axiomatic system, a type of deductive logical structure; also very popular in computer science!).
This is conCERNing...
https://home.cern/news/press-release/experiments/base-experiment-cern-succeeds-transporting-antimatter
And it raises some questions:
- what orange-black UN number do you put on that truck?
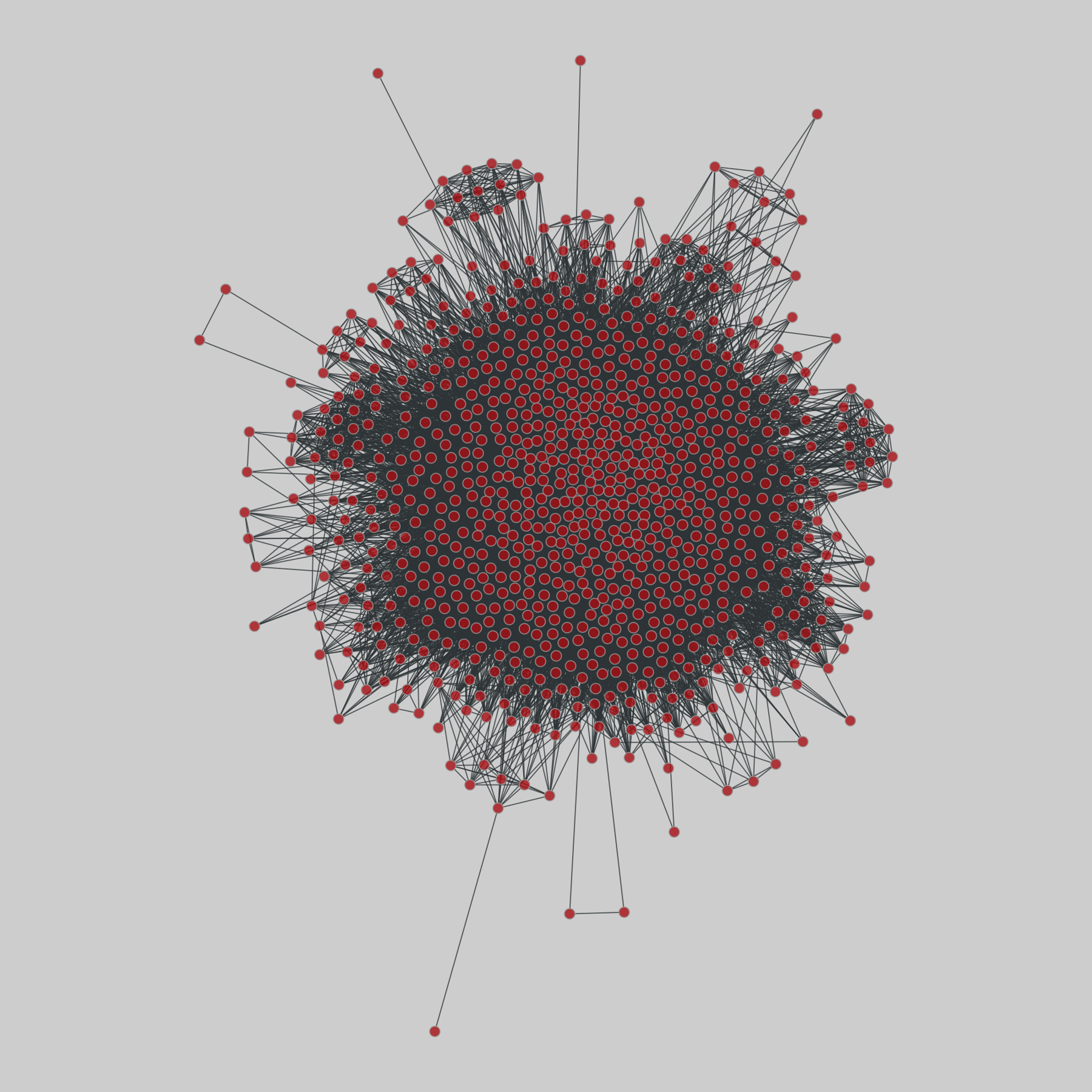
celegans_interactomes: C. elegans interactomes (2009)
Ten networks of protein-protein interactions in Caenorhabditis elegans (nematode), from yeast two-hybrid experiments, biological process maps, literature curation, orthologous interactions, and genetic interactions. The WI8 network combines WI2004, WI2007 and BPmaps, while the Integrated Network combines data from all sources.
This network has 2724 nodes and 14322 edges.
Tags: Biological, Protein interactions, Unweighted…
GraphWalker: Agentic Knowledge Graph Question Answering via Synthetic Trajectory Curriculum
Shuwen Xu, Yao Xu, Jiaxiang Liu, Chenhao Yuan, Wenshuo Peng, Jun Zhao, Kang Liu
https://arxiv.org/abs/2603.28533 https://arxiv.org/pdf/2603.28533 https://arxiv.org/html/2603.28533
arXiv:2603.28533v1 Announce Type: new
Abstract: Agentic knowledge graph question answering (KGQA) requires an agent to iteratively interact with knowledge graphs (KGs), posing challenges in both training data scarcity and reasoning generalization. Specifically, existing approaches often restrict agent exploration: prompting-based methods lack autonomous navigation training, while current training pipelines usually confine reasoning to predefined trajectories. To this end, this paper proposes \textit{GraphWalker}, a novel agentic KGQA framework that addresses these challenges through \textit{Automated Trajectory Synthesis} and \textit{Stage-wise Fine-tuning}. GraphWalker adopts a two-stage SFT training paradigm: First, the agent is trained on structurally diverse trajectories synthesized from constrained random-walk paths, establishing a broad exploration prior over the KG; Second, the agent is further fine-tuned on a small set of expert trajectories to develop reflection and error recovery capabilities. Extensive experiments demonstrate that our stage-wise SFT paradigm unlocks a higher performance ceiling for a lightweight reinforcement learning (RL) stage, enabling GraphWalker to achieve state-of-the-art performance on CWQ and WebQSP. Additional results on GrailQA and our constructed GraphWalkerBench confirm that GraphWalker enhances generalization to out-of-distribution reasoning paths. The code is publicly available at https://github.com/XuShuwenn/GraphWalker
toXiv_bot_toot
Drifting Chords – Flavigula Sketches and Experiments, Flavigula
https://faircamp.thurk.org/drifting-chords/
Replaced article(s) found for physics.atom-ph. https://arxiv.org/list/physics.atom-ph/new
[1/1]:
- Efficient water-cooled Bitter-type electromagnet for Zeeman slowing in cold-atom experiments
Rishav Koirala, Ben A. Olsen
The experiments, process adjustments and elimination of environmental factors shall continue until the desired results are obtained (and morale improves again... 😅)
Also, Kallitype chemistry is a wondrous/finicky beast and reproduction requires strict discipline, cleanliness and detailed log keeping of pretty much any aspect... The main difference between these two prints is that the red one involved spraying/misting the paper with distilled water 15 mins prior to coating the emulsion.…
Extreme (Rogue) Waves: From Theory to Experiments in Ultracold Gases and Beyond
A. Chabchoub, P. Engels, P. G. Kevrekidis, S. I. Mistakidis, G. C. Katsimiga, M. E. Mossman, S. Mossman
https://arxiv.org/abs/2603.25908
🚀 One week left to apply for my postdoc position in emoji semantics! Join us for:
🔬 linguistic experiments
🔍 semantic theory
🤝 interdisciplinary collaboration
🧑💼 developing your own research agenda
💻 digital communication
🤩 a wonderful team
💪 a supportive supervisor
#bochum #emoji #linguistics @… @…
https://jobs.ruhr-uni-bochum.de/jobposting/f5001c40d914e7ce325557bfe526aa88415f75bb0
Restoring missing low scattering angle data in two-dimensional diffraction patterns of isolated molecules
Yanwei Xiong, Martin Centurion
https://arxiv.org/abs/2603.24334 https://arxiv.org/pdf/2603.24334 https://arxiv.org/html/2603.24334
arXiv:2603.24334v1 Announce Type: new
Abstract: Anisotropic two-dimensional diffraction signals contain more information than the conventional isotropic signals for both gas phase ultrafast electron and X-ray diffraction experiments and are common in typical time-resolved diffraction experiments due to the use of linearly polarized lasers to excite the sample that imprints spatial anisotropy on the molecules. We report an iterative algorithm to restore the missing data at low scattering angles in a two-dimensional diffraction signal, which is essential to obtain real-space representation. The iterative algorithm transforms two-dimensional signals back and forth between the momentum transfer domain and the real space domain through Fourier and Abel transforms and apply real space constraints to retrieve missing signal at low scattering angles. The algorithm only requires an approximate a-priori knowledge of the shortest and longest internuclear distances in the molecule. We demonstrated successful retrieval of the missing signal in simulated patterns and in experimentally measured diffraction patterns from laser-induced alignment of trifluoroiodomethane molecules.
toXiv_bot_toot
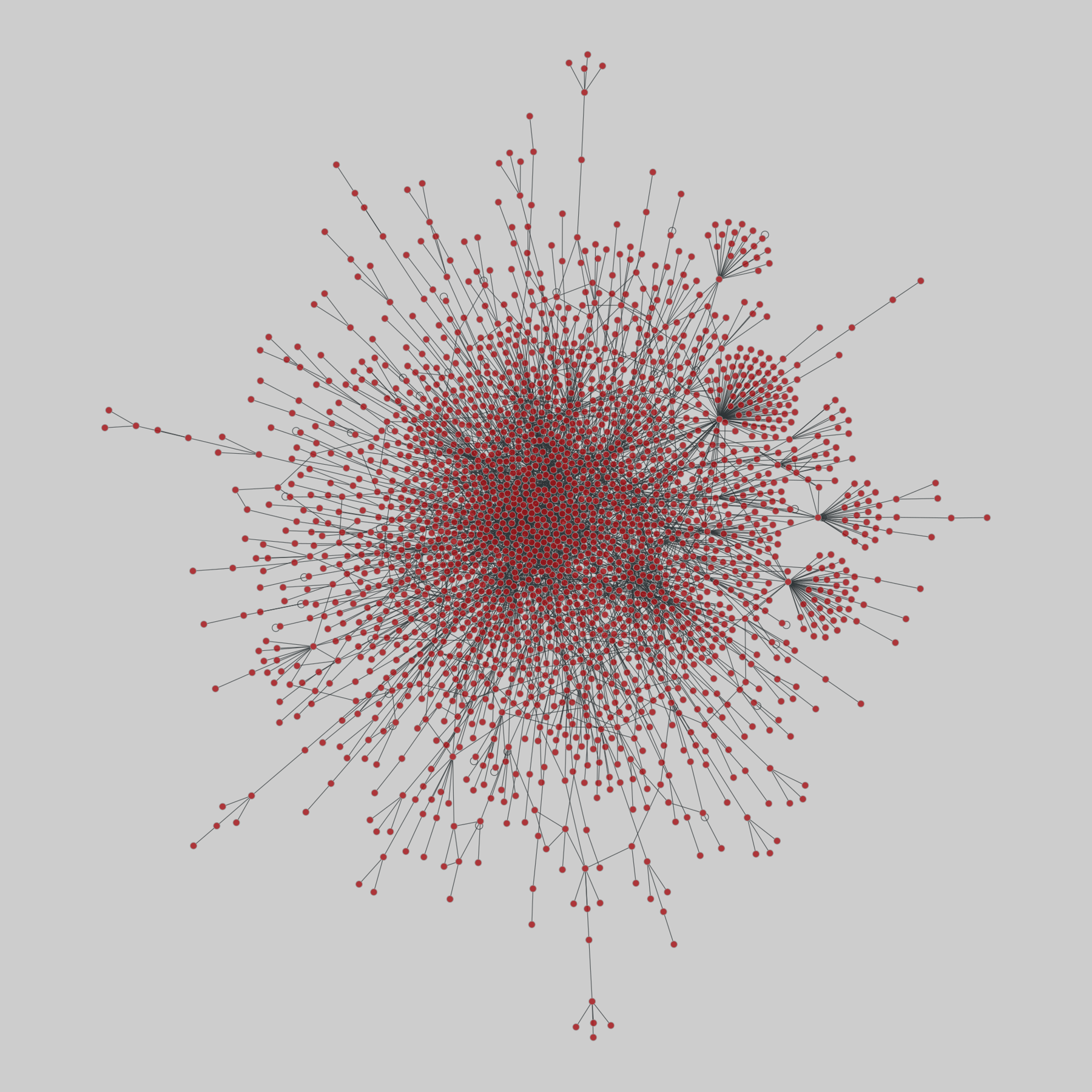
interactome_stelzl: Stelzl human interactome (2005)
A network of human proteins and their binding interactions. Nodes represent proteins and an edge represents an interaction between two proteins, as inferred via high-throughput Y2H experiments using bait and prey methodology.
This network has 1706 nodes and 6207 edges.
Tags: Biological, Protein interactions, Unweighted
Tomorrow: Admitted PhD student visit day.
Me, today: Getting Claude to write code to get Claude to run experiments to test a conjecture I've had, yeeting cash at it so I can run more in parallel, but trying to stay in Tier 1 so this doesn't goes beyond fun money.
What a world.
Integrative neurocybernetic modeling in the era of large-scale neuroscience
Il Memming Park, Ayesha Vermani, Gonzalo G. de Polavieja, Juan \'Alvaro Gallego, Kathleen Esfahany, Shreya Saxena, Michael Orger, Auke Ijspeert, Matthew Dowling, Daniel McNamee, Srinivas C. Turaga, Zachary Mainen, Joseph J. Paton, Alfonso Renart
https://arxiv.org/abs/2604.23903 https://arxiv.org/pdf/2604.23903 https://arxiv.org/html/2604.23903
arXiv:2604.23903v1 Announce Type: new
Abstract: Large-scale neuroscience is generating rich datasets across animals, brain areas and behavioral contexts, yet our modeling efforts remains fragmented across isolated experiments. We argue that understanding behavior requires integrative neurocybernetic models: understandable dynamical models that capture the closed-loop coupling of brain, body and environment, treat the brain as a controller pursuing latent objectives, represent structured variation across scales, and scale to heterogeneous datasets. Such models shift the goal from predicting neural recordings in isolation to inferring the organizing principles that govern neural and behavioral dynamics. We outline a practical route toward this goal by combining nonlinear state-space models and meta-dynamical extensions with scalable inference, knowledge distillation, mixed open- and closed-loop training, and connectomics-informed architectures. By pooling complementary constraints from recordings, behavior, perturbations and anatomy, integrative neurocybernetic models can provide statistical amplification, few-shot generalization, and mechanistic insight into shared dynamical structure, individual variation, and the control objectives that govern behavior. This agenda offers a model-centric path from fragmented data to a mechanistic science of how brains produce behavior.
toXiv_bot_toot
Bikelution: Federated Gradient-Boosting for Scalable Shared Micro-Mobility Demand Forecasting
Antonios Tziorvas, Andreas Tritsarolis, Yannis Theodoridis
https://arxiv.org/abs/2602.20671 https://arxiv.org/pdf/2602.20671 https://arxiv.org/html/2602.20671
arXiv:2602.20671v1 Announce Type: new
Abstract: The rapid growth of dockless bike-sharing systems has generated massive spatio-temporal datasets useful for fleet allocation, congestion reduction, and sustainable mobility. Bike demand, however, depends on several external factors, making traditional time-series models insufficient. Centralized Machine Learning (CML) yields high-accuracy forecasts but raises privacy and bandwidth issues when data are distributed across edge devices. To overcome these limitations, we propose Bikelution, an efficient Federated Learning (FL) solution based on gradient-boosted trees that preserves privacy while delivering accurate mid-term demand forecasts up to six hours ahead. Experiments on three real-world BSS datasets show that Bikelution is comparable to its CML-based variant and outperforms the current state-of-the-art. The results highlight the feasibility of privacy-aware demand forecasting and outline the trade-offs between FL and CML approaches.
toXiv_bot_toot
Training data generation for context-dependent rubric-based short answer grading
Pavel \v{S}indel\'a\v{r}, D\'avid Slivka, Christopher Bouma, Filip Pr\'a\v{s}il, Ond\v{r}ej Bojar
https://arxiv.org/abs/2603.28537 https://arxiv.org/pdf/2603.28537 https://arxiv.org/html/2603.28537
arXiv:2603.28537v1 Announce Type: new
Abstract: Every 4 years, the PISA test is administered by the OECD to test the knowledge of teenage students worldwide and allow for comparisons of educational systems. However, having to avoid language differences and annotator bias makes the grading of student answers challenging. For these reasons, it would be interesting to compare methods of automatic student answer grading. To train some of these methods, which require machine learning, or to compute parameters or select hyperparameters for those that do not, a large amount of domain-specific data is needed. In this work, we explore a small number of methods for creating a large-scale training dataset using only a relatively small confidential dataset as a reference, leveraging a set of very simple derived text formats to preserve confidentiality. Using these methods, we successfully created three surrogate datasets that are, at the very least, superficially more similar to the reference dataset than purely the result of prompt-based generation. Early experiments suggest one of these approaches might also lead to improved model training.
toXiv_bot_toot
Ultrasound-based approach to delivering potent drugs into cancer cells shows promise in benchtop experiments
https://phys.org/news/2026-03-ultrasound-based-approach-potent-drugs.html
Interesting discourse elsewhere (not really important what) is showing that people do not know the difference between science and the scientific method.
So as a PSA, science is a systematic endeavor to gain knowledge.
The scientific method (as the name implies), is a practical way to pursue science; with observation, theories and experiments. (There’s other ways, too.)
More experiments with @… 8.1.
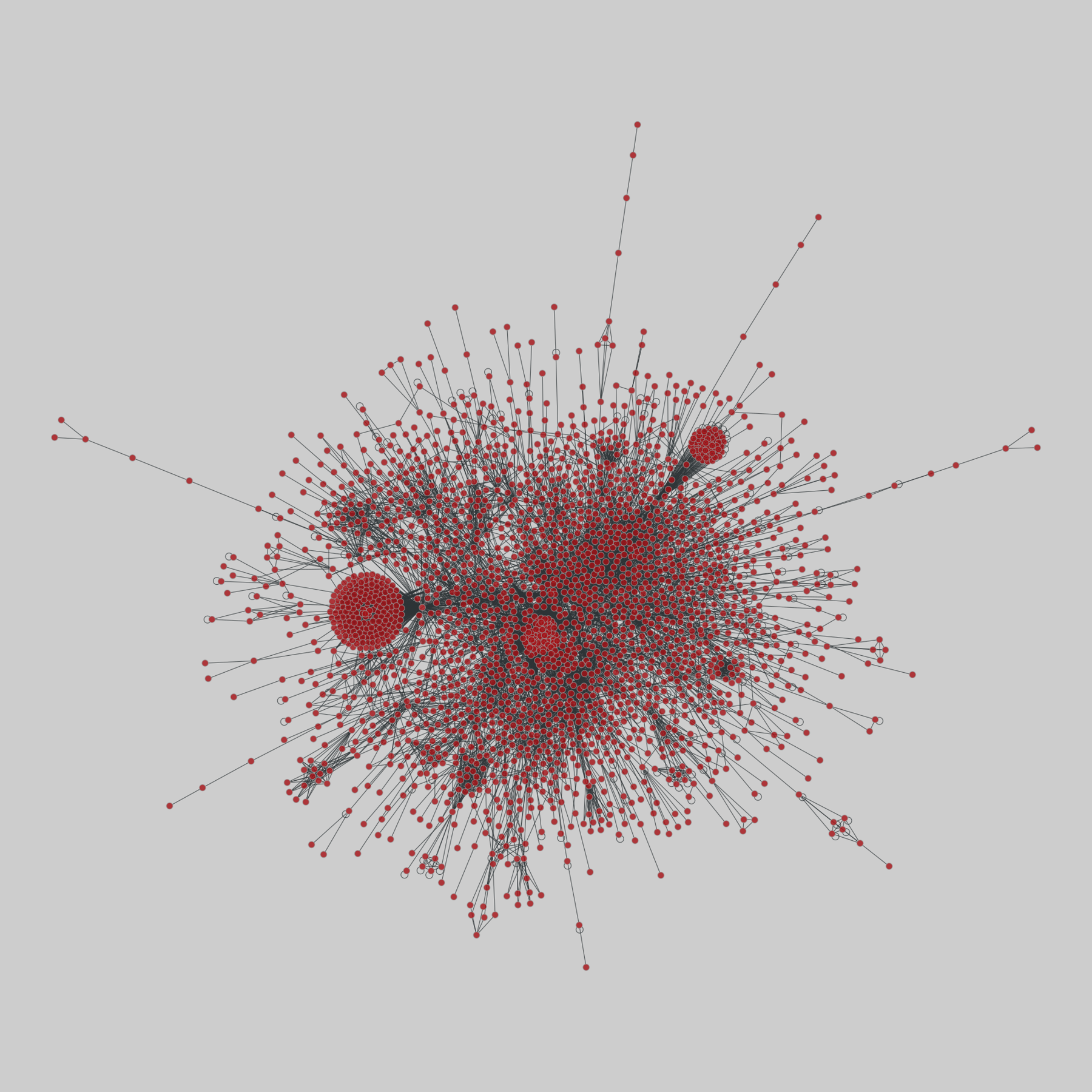
interactome_stelzl: Stelzl human interactome (2005)
A network of human proteins and their binding interactions. Nodes represent proteins and an edge represents an interaction between two proteins, as inferred via high-throughput Y2H experiments using bait and prey methodology.
This network has 1706 nodes and 6207 edges.
Tags: Biological, Protein interactions, Unweighted
"Emergent Introspective Awareness in Large Language Models" published by an Anthropic researcher 2025-10.
fails to demonstrate introspection. it does call out the difference between "real" introspection and "confabulated" introspection, but the experiments are indistinguishable from activation steering. if you manipulate an LLM state so it's likely to emit tokens about dogs, and then prompt it "do you detect the thought I injected?" of course…
Acoustic Signatures of Pinch-Off Cavities During Water-Entry
Zirui Liu, Tongtong Ding, Mingyue Kuang, Zimeng Li, Junyi Zhao, A-Man Zhang, Shuai Li
https://arxiv.org/abs/2602.22761 https://arxiv.org/pdf/2602.22761 https://arxiv.org/html/2602.22761
arXiv:2602.22761v1 Announce Type: new
Abstract: This study experimentally, numerically, and theoretically investigates the cavity/bubble dynamics and radiated acoustics during the water entry of a centimeter-scale cylindrical projectile with a conical nose. Experiments were conducted in a laboratory tank, employing synchronized high-speed imaging and hydrophone measurements to characterize the cavity closure modes and their resultant acoustic signatures across a range of Froude numbers. The acoustic signal features a weak radiated signal upon impact, followed by significant pressure oscillations spanning more than 20 cycles in the flow field after cavity elongation and pinch-off. A numerical model based on the Finite Volume Method (FVM) successfully captures these physical processes. Subsequently, a semi-theoretical model that incorporates the projectile's boundary effect is developed from potential flow theory. The model not only yields a dominant cavity oscillation frequency that agrees well with experimental data, but also reveals that the boundary effect leads to a cavity oscillation frequency markedly higher than the Minnaert frequency of an equivalent-volume ellipsoidal bubble containing an internal rigid core. The dominant cavity frequency falls nearly linearly with Fr, governed by nose geometry and projectile inertia. This study clarifies the underlying physics connecting cavity dynamics during water entry to underwater acoustic radiation.
toXiv_bot_toot
Democratizing AI: A Comparative Study in Deep Learning Efficiency and Future Trends in Computational Processing
Lisan Al Amin, Md Ismail Hossain, Rupak Kumar Das, Mahbubul Islam, Saddam Mukta, Abdulaziz Tabbakh
https://arxiv.org/abs/2603.20920 https://arxiv.org/pdf/2603.20920 https://arxiv.org/html/2603.20920
arXiv:2603.20920v1 Announce Type: new
Abstract: The exponential growth in data has intensified the demand for computational power to train large-scale deep learning models. However, the rapid growth in model size and complexity raises concerns about equal and fair access to computational resources, particularly under increasing energy and infrastructure constraints. GPUs have emerged as essential for accelerating such workloads. This study benchmarks four deep learning models (Conv6, VGG16, ResNet18, CycleGAN) using TensorFlow and PyTorch on Intel Xeon CPUs and NVIDIA Tesla T4 GPUs. Our experiments demonstrate that, on average, GPU training achieves speedups ranging from 11x to 246x depending on model complexity, with lightweight models (Conv6) showing the highest acceleration (246x), mid-sized models (VGG16, ResNet18) achieving 51-116x speedups, and complex generative models (CycleGAN) reaching 11x improvements compared to CPU training. Additionally, in our PyTorch vs. TensorFlow comparison, we observed that TensorFlow's kernel-fusion optimizations reduce inference latency by approximately 15%. We also analyze GPU memory usage trends and projecting requirements through 2025 using polynomial regression. Our findings highlight that while GPUs are essential for sustaining AI's growth, democratized and shared access to GPU resources is critical for enabling research innovation across institutions with limited computational budgets.
toXiv_bot_toot
Free for orgs under $5M revenue/funding — startups, side projects, experiments. Larger orgs need a commercial license.
🐰 Try it out:
🌐 https://directus.io
📚 https://docs.d…
interactome_stelzl: Stelzl human interactome (2005)
A network of human proteins and their binding interactions. Nodes represent proteins and an edge represents an interaction between two proteins, as inferred via high-throughput Y2H experiments using bait and prey methodology.
This network has 1706 nodes and 6207 edges.
Tags: Biological, Protein interactions, Unweighted
CAGE: An Internal Source Scanning Cryostat for HPGe Characterization
G. Othman, C. Wiseman, T. H. Burritt, J. A. Detwiler, M. P. Held, R. Henning, T. Mathew, D. Peterson, W. Pettus, G. Song, T. D. Van Wechel
https://arxiv.org/abs/2602.06289 https://arxiv.org/pdf/2602.06289 https://arxiv.org/html/2602.06289
arXiv:2602.06289v1 Announce Type: new
Abstract: The success of current and future-generation neutrinoless double beta decay experiments relies on the ability to eliminate or reduce extraneous backgrounds. In addition to constructing experiments using radiopure materials and handling in underground laboratories, it is necessary to understand and reduce known backgrounds in data analysis. The Large Enriched Germanium Experiment for Neutrinoless double beta Decay is searching for this decay using 76Ge-enriched high-purity germanium detectors submerged in an active liquid argon veto. A significant background in LEGEND is surface events from shallowly-impinging radiation on detector surfaces. In this paper we introduce the Collimated Alphas, Gammas, and Electrons (CAGE) scanning system, an internal-source scanning vacuum cryostat, designed to perform studies of surface events on sensitive surfaces of HPGe in a surface-lab. CAGE features a collimated radionuclide source inside a movable infrared shield that is able to perform precision scans of detector surfaces by utilizing three independent motor stages for source positioning. This allows detailed studies of pulse shapes as a function of source position and incident angle, where defining features can be extracted and exploited for removing surface backgrounds in data analysis in LEGEND. In this paper, we describe CAGE and demonstrate its performance with a commissioning run with 241Am. The commissioning run was completed with the source at normal incidence, and we estimate a beam spot precision of 3.1 mm, which includes positioning uncertainties and the beam-spot size. Using the 59.5 keV gamma population from 241Am, we show that low-energy photon events near the passivated surface feature risetimes that increase with radial distance from the detector center. We suggest a specific metric that can be used to discriminate low-energy gamma backgrounds in LEGEND with similar characteristics.
toXiv_bot_toot
Estimation of Confidence Bounds in Binary Classification using Wilson Score Kernel Density Estimation
Thorbj{\o}rn Mosekj{\ae}r Iversen, Zebin Duan, Frederik Hagelskj{\ae}r
https://arxiv.org/abs/2602.20947 https://arxiv.org/pdf/2602.20947 https://arxiv.org/html/2602.20947
arXiv:2602.20947v1 Announce Type: new
Abstract: The performance and ease of use of deep learning-based binary classifiers have improved significantly in recent years. This has opened up the potential for automating critical inspection tasks, which have traditionally only been trusted to be done manually. However, the application of binary classifiers in critical operations depends on the estimation of reliable confidence bounds such that system performance can be ensured up to a given statistical significance. We present Wilson Score Kernel Density Classification, which is a novel kernel-based method for estimating confidence bounds in binary classification. The core of our method is the Wilson Score Kernel Density Estimator, which is a function estimator for estimating confidence bounds in Binomial experiments with conditionally varying success probabilities. Our method is evaluated in the context of selective classification on four different datasets, illustrating its use as a classification head of any feature extractor, including vision foundation models. Our proposed method shows similar performance to Gaussian Process Classification, but at a lower computational complexity.
toXiv_bot_toot
New Challenges in Plasma Accelerators: Final Focusing for Wakefield Colliders
Keegan Downham (University of California, Santa Barbara, SLAC National Accelerator Laboratory), Spencer Gessner (SLAC National Accelerator Laboratory), Lewis Kennedy (CERN), Rogelio Tom\'as (CERN), Andrei Seryi (Old Dominion University)
https://arxiv.org/abs/2602.15777 https://arxiv.org/pdf/2602.15777 https://arxiv.org/html/2602.15777
arXiv:2602.15777v1 Announce Type: new
Abstract: The focusing of particle beams for collider experiments is crucial for maximizing the luminosity and thus the discovery potential of these machines. In recent years, plasma wakefield acceleration has emerged as a leading candidate for achieving higher energy collisions with smaller facility footprints due to the large accelerating gradients in the plasma. This higher beam energy poses significant challenges for the final focusing system of the collider. Here, we discuss the various challenges of final focusing for TeV-scale plasma accelerators and propose possible solutions. Finally, we present the first design of a final focusing system for a 10 TeV linear wakefield collider, evaluate its performance, and discuss its shortcomings as well as improvements for future designs.
toXiv_bot_toot
Some experiments with Midjourney 8.1. Very nice. It has a bit of madness to it, like 5.1 did. What's up with the dinosaur sculptures in the fourth image?
A minimal wake-vortex model explains formation flight of flapping birds
Olivia Pomerenk, Kenneth S. Breuer
https://arxiv.org/abs/2602.22043 https://arxiv.org/pdf/2602.22043 https://arxiv.org/html/2602.22043
arXiv:2602.22043v1 Announce Type: new
Abstract: Collective patterns of motion emerge across biological taxa: insects swarm, fish school, and birds flock. In particular, large migratory birds form strikingly ordered V-shaped formations, which experiments and direct numerical simulations have demonstrated provide substantial energetic benefits during long-distance flight. However, the precise aerodynamic and morphological mechanisms underlying these benefits remain unclear. In this work, we develop a reduced-order model of the wake-vortex interactions between two flapping birds flying in tandem. The model retains essential unsteady flapping dynamics while remaining computationally tractable. By optimizing over a six-dimensional state space, which comprises the follower's three-dimensional relative position and three independent flapping parameters, we identify the energetically optimal leader-follower configuration of northern bald ibises. The predicted optimum agrees quantitatively with live-bird measurements. Because of its simplicity, the model allows for direct interrogation of the physical mechanisms responsible for this optimum. In particular, it isolates precisely how the follower's wing kinematics interact with the leader's wake to enhance aerodynamic efficiency. The model predicts an 11% reduction in total mechanical power for a follower in formation flight -- consistent with experimental estimates -- and shows that this saving arises from reductions in both induced and profile power, dominated by decreased profile power enabled primarily through reduced flapping amplitude and, secondarily, reduced upstroke flexion. These results provide a mechanistic explanation for the structure of V-formations and offer new insight into the aerodynamic principles governing collective flight.
toXiv_bot_toot
Fine tuning the Lego spectrometer more.
Using a maglite as the source eliminates the need for a separate collimating lens.
I also switched away from the very flaky variable slit made of a sliding brick that wouldn't stay in place if you looked at it wrong.
After some failed experiments with aluminum foil, I discovered that the round tree trunk Duplo brick was a tiny bit smaller than a nominal square 2x2 brick. When placed next to a square brick and locked in place with …
A profile of Anthropic and its key executives like Chris Olah, and a look at Project Vend, an internal "Claudius" experiment to run the office vending machine (Gideon Lewis-Kraus/New Yorker)
https://www.newyorker.com/magazine/2026/02
PIME: Prototype-based Interpretable MCTS-Enhanced Brain Network Analysis for Disorder Diagnosis
Kunyu Zhang, Yanwu Yang, Jing Zhang, Xiangjie Shi, Shujian Yu
https://arxiv.org/abs/2602.21046 https://arxiv.org/pdf/2602.21046 https://arxiv.org/html/2602.21046
arXiv:2602.21046v1 Announce Type: new
Abstract: Recent deep learning methods for fMRI-based diagnosis have achieved promising accuracy by modeling functional connectivity networks. However, standard approaches often struggle with noisy interactions, and conventional post-hoc attribution methods may lack reliability, potentially highlighting dataset-specific artifacts. To address these challenges, we introduce PIME, an interpretable framework that bridges intrinsic interpretability with minimal-sufficient subgraph optimization by integrating prototype-based classification and consistency training with structural perturbations during learning. This encourages a structured latent space and enables Monte Carlo Tree Search (MCTS) under a prototype-consistent objective to extract compact minimal-sufficient explanatory subgraphs post-training. Experiments on three benchmark fMRI datasets demonstrate that PIME achieves state-of-the-art performance. Furthermore, by constraining the search space via learned prototypes, PIME identifies critical brain regions that are consistent with established neuroimaging findings. Stability analysis shows 90% reproducibility and consistent explanations across atlases.
toXiv_bot_toot
interactome_stelzl: Stelzl human interactome (2005)
A network of human proteins and their binding interactions. Nodes represent proteins and an edge represents an interaction between two proteins, as inferred via high-throughput Y2H experiments using bait and prey methodology.
This network has 1706 nodes and 6207 edges.
Tags: Biological, Protein interactions, Unweighted
Replaced article(s) found for physics.atom-ph. https://arxiv.org/list/physics.atom-ph/new
[1/1]:
- Design and implementation of a modular laser system for AMO experiments
Theophilo, Thomas, Croft, Lekhai, Owens, Smith, Muralidharan, Deans
Robust Multiagent Collaboration Through Weighted Max-Min T-Joins
Sharareh Alipour
https://arxiv.org/abs/2602.07720 https://arxiv.org/pdf/2602.07720 https://arxiv.org/html/2602.07720
arXiv:2602.07720v1 Announce Type: new
Abstract: Many multiagent tasks -- such as reviewer assignment, coalition formation, or fair resource allocation -- require selecting a group of agents such that collaboration remains effective even in the worst case. The \emph{weighted max-min $T$-join problem} formalizes this challenge by seeking a subset of vertices whose minimum-weight matching is maximized, thereby ensuring robust outcomes against unfavorable pairings.
We advance the study of this problem in several directions. First, we design an algorithm that computes an upper bound for the \emph{weighted max-min $2k$-matching problem}, where the chosen set must contain exactly $2k$ vertices. Building on this bound, we develop a general algorithm with a \emph{$2 \ln n$-approximation guarantee} that runs in $O(n^4)$ time. Second, using ear decompositions, we propose another upper bound for the weighted max-min $T$-join cost. We also show that the problem can be solved exactly when edge weights belong to $\{1,2\}$.
Finally, we evaluate our methods on real collaboration datasets. Experiments show that the lower bounds from our approximation algorithm and the upper bounds from the ear decomposition method are consistently close, yielding empirically small constant-factor approximations. Overall, our results highlight both the theoretical significance and practical value of weighted max-min $T$-joins as a framework for fair and robust group formation in multiagent systems.
toXiv_bot_toot
“How may the compulsive programmer be distinguished from a merely dedicated, hard-working professional programmer? First, by the fact that the ordinary professional programmer addresses himself to the problem to be solved, whereas the compulsive programmer sees the problem mainly as an opportunity to interact with the computer. The ordinary computer programmer will usually discuss both his substantive and his technical programming problem with others. He will generally do lengthy preparatory work, such as writing and flow diagramming, before beginning work with the computer itself. His sessions with the computer may be comparatively short. He may even let others do the actual console work. He develops his program slowly and systematically. When something doesn't work, he may spend considerable time away from the computer, framing careful hypotheses to account for the malfunction and designing crucial experiments to test them. Again, he may leave the actual running of the computer to others. He is able, while waiting for results from the computer, to attend to other aspects of his work, such as documenting what he has already done. When he has finally composed the program he set out to produce, he is able to complete a sensible description of it and to turn his attention to other things. The professional regards programming as a means toward an end, not as an end in itself. His satisfaction comes from having solved a substantive problem, not from having bent a computer to his will.”
—Joseph Weizenbaum, Computer Power and Human Reason, 1976
celegans_interactomes: C. elegans interactomes (2009)
Ten networks of protein-protein interactions in Caenorhabditis elegans (nematode), from yeast two-hybrid experiments, biological process maps, literature curation, orthologous interactions, and genetic interactions. The WI8 network combines WI2004, WI2007 and BPmaps, while the Integrated Network combines data from all sources.
This network has 2724 nodes and 14322 edges.
Tags: Biological, Protein interactions, Unweighted…
Learning from Trials and Errors: Reflective Test-Time Planning for Embodied LLMs
Yining Hong, Huang Huang, Manling Li, Li Fei-Fei, Jiajun Wu, Yejin Choi
https://arxiv.org/abs/2602.21198 https://arxiv.org/pdf/2602.21198 https://arxiv.org/html/2602.21198
arXiv:2602.21198v1 Announce Type: new
Abstract: Embodied LLMs endow robots with high-level task reasoning, but they cannot reflect on what went wrong or why, turning deployment into a sequence of independent trials where mistakes repeat rather than accumulate into experience. Drawing upon human reflective practitioners, we introduce Reflective Test-Time Planning, which integrates two modes of reflection: \textit{reflection-in-action}, where the agent uses test-time scaling to generate and score multiple candidate actions using internal reflections before execution; and \textit{reflection-on-action}, which uses test-time training to update both its internal reflection model and its action policy based on external reflections after execution. We also include retrospective reflection, allowing the agent to re-evaluate earlier decisions and perform model updates with hindsight for proper long-horizon credit assignment. Experiments on our newly-designed Long-Horizon Household benchmark and MuJoCo Cupboard Fitting benchmark show significant gains over baseline models, with ablative studies validating the complementary roles of reflection-in-action and reflection-on-action. Qualitative analyses, including real-robot trials, highlight behavioral correction through reflection.
toXiv_bot_toot
Research across 1,372 participants and 9K trials details "cognitive surrender", where most subjects had minimal AI skepticism and accepted faulty AI reasoning (Kyle Orland/Ars Technica)
https://arstechnica.com/ai/2026/04/res
Does Order Matter : Connecting The Law of Robustness to Robust Generalization
Himadri Mandal, Vishnu Varadarajan, Jaee Ponde, Aritra Das, Mihir More, Debayan Gupta
https://arxiv.org/abs/2602.20971 https://arxiv.org/pdf/2602.20971 https://arxiv.org/html/2602.20971
arXiv:2602.20971v1 Announce Type: new
Abstract: Bubeck and Sellke (2021) pose as an open problem the connection between the law of robustness and robust generalization. The law of robustness states that overparameterization is necessary for models to interpolate robustly; in particular, robust interpolation requires the learned function to be Lipschitz. Robust generalization asks whether small robust training loss implies small robust test loss. We resolve this problem by explicitly connecting the two for arbitrary data distributions. Specifically, we introduce a nontrivial notion of robust generalization error and convert it into a lower bound on the expected Rademacher complexity of the induced robust loss class. Our bounds recover the $\Omega(n^{1/d})$ regime of Wu et al.\ (2023) and show that, up to constants, robust generalization does not change the order of the Lipschitz constant required for smooth interpolation. We conduct experiments to probe the predicted scaling with dataset size and model capacity, testing whether empirical behavior aligns more closely with the predictions of Bubeck and Sellke (2021) or Wu et al.\ (2023). For MNIST, we find that the lower-bound Lipschitz constant scales on the order predicted by Wu et al.\ (2023). Informally, to obtain low robust generalization error, the Lipschitz constant must lie in a range that we bound, and the allowable perturbation radius is linked to the Lipschitz scale.
toXiv_bot_toot
celegans_interactomes: C. elegans interactomes (2009)
Ten networks of protein-protein interactions in Caenorhabditis elegans (nematode), from yeast two-hybrid experiments, biological process maps, literature curation, orthologous interactions, and genetic interactions. The WI8 network combines WI2004, WI2007 and BPmaps, while the Integrated Network combines data from all sources.
This network has 2528 nodes and 3864 edges.
Tags: Biological, Protein interactions, Unweighted
Scaling Vision Transformers: Evaluating DeepSpeed for Image-Centric Workloads
Huy Trinh, Rebecca Ma, Zeqi Yu, Tahsin Reza
https://arxiv.org/abs/2602.21081 https://arxiv.org/pdf/2602.21081 https://arxiv.org/html/2602.21081
arXiv:2602.21081v1 Announce Type: new
Abstract: Vision Transformers (ViTs) have demonstrated remarkable potential in image processing tasks by utilizing self-attention mechanisms to capture global relationships within data. However, their scalability is hindered by significant computational and memory demands, especially for large-scale models with many parameters. This study aims to leverage DeepSpeed, a highly efficient distributed training framework that is commonly used for language models, to enhance the scalability and performance of ViTs. We evaluate intra- and inter-node training efficiency across multiple GPU configurations on various datasets like CIFAR-10 and CIFAR-100, exploring the impact of distributed data parallelism on training speed, communication overhead, and overall scalability (strong and weak scaling). By systematically varying software parameters, such as batch size and gradient accumulation, we identify key factors influencing performance of distributed training. The experiments in this study provide a foundational basis for applying DeepSpeed to image-related tasks. Future work will extend these investigations to deepen our understanding of DeepSpeed's limitations and explore strategies for optimizing distributed training pipelines for Vision Transformers.
toXiv_bot_toot
The aftermath of the first successful flight - 2.5 seconds, 12.5 meters high - of a liquid-fueled #rocket 100 years ago #OTD as photographed by Robert H. #Goddard himself in Auburn, Mass. The flight itself was neither filmed nor photographed but there is plentiful other material about the history-making experiments available, linked from https://skyweek.wordpress.com/2026/03/12/allgemeines-live-blog-ab-dem-12-marz-2026/#Mar16 (much of it just gone up).
Localized Dynamics-Aware Domain Adaption for Off-Dynamics Offline Reinforcement Learning
Zhangjie Xia, Yu Yang, Pan Xu
https://arxiv.org/abs/2602.21072 https://arxiv.org/pdf/2602.21072 https://arxiv.org/html/2602.21072
arXiv:2602.21072v1 Announce Type: new
Abstract: Off-dynamics offline reinforcement learning (RL) aims to learn a policy for a target domain using limited target data and abundant source data collected under different transition dynamics. Existing methods typically address dynamics mismatch either globally over the state space or via pointwise data filtering; these approaches can miss localized cross-domain similarities or incur high computational cost. We propose Localized Dynamics-Aware Domain Adaptation (LoDADA), which exploits localized dynamics mismatch to better reuse source data. LoDADA clusters transitions from source and target datasets and estimates cluster-level dynamics discrepancy via domain discrimination. Source transitions from clusters with small discrepancy are retained, while those from clusters with large discrepancy are filtered out. This yields a fine-grained and scalable data selection strategy that avoids overly coarse global assumptions and expensive per-sample filtering. We provide theoretical insights and extensive experiments across environments with diverse global and local dynamics shifts. Results show that LoDADA consistently outperforms state-of-the-art off-dynamics offline RL methods by better leveraging localized distribution mismatch.
toXiv_bot_toot
Design and implementation of a modular laser system for AMO experiments
Klara Theophilo, Scott J Thomas, Georgina Croft, Yashna N D Lekhai, Alexander Owens, Daisy R H Smith, Silpa Muralidharan, Cameron Deans
https://arxiv.org/abs/2603.17697
SELAUR: Self Evolving LLM Agent via Uncertainty-aware Rewards
Dengjia Zhang, Xiaoou Liu, Lu Cheng, Yaqing Wang, Kenton Murray, Hua Wei
https://arxiv.org/abs/2602.21158 https://arxiv.org/pdf/2602.21158 https://arxiv.org/html/2602.21158
arXiv:2602.21158v1 Announce Type: new
Abstract: Large language models (LLMs) are increasingly deployed as multi-step decision-making agents, where effective reward design is essential for guiding learning. Although recent work explores various forms of reward shaping and step-level credit assignment, a key signal remains largely overlooked: the intrinsic uncertainty of LLMs. Uncertainty reflects model confidence, reveals where exploration is needed, and offers valuable learning cues even in failed trajectories. We introduce SELAUR: Self Evolving LLM Agent via Uncertainty-aware Rewards, a reinforcement learning framework that incorporates uncertainty directly into the reward design. SELAUR integrates entropy-, least-confidence-, and margin-based metrics into a combined token-level uncertainty estimate, providing dense confidence-aligned supervision, and employs a failure-aware reward reshaping mechanism that injects these uncertainty signals into step- and trajectory-level rewards to improve exploration efficiency and learning stability. Experiments on two benchmarks, ALFWorld and WebShop, show that our method consistently improves success rates over strong baselines. Ablation studies further demonstrate how uncertainty signals enhance exploration and robustness.
toXiv_bot_toot
celegans_interactomes: C. elegans interactomes (2009)
Ten networks of protein-protein interactions in Caenorhabditis elegans (nematode), from yeast two-hybrid experiments, biological process maps, literature curation, orthologous interactions, and genetic interactions. The WI8 network combines WI2004, WI2007 and BPmaps, while the Integrated Network combines data from all sources.
This network has 912 nodes and 22738 edges.
Tags: Biological, Protein interactions, Unweighted
ZOR filters: fast and smaller than fuse filters
Antoine Limasset
https://arxiv.org/abs/2602.03525 https://arxiv.org/pdf/2602.03525 https://arxiv.org/html/2602.03525
arXiv:2602.03525v1 Announce Type: new
Abstract: Probabilistic membership filters support fast approximate membership queries with a controlled false-positive probability $\varepsilon$ and are widely used across storage, analytics, networking, and bioinformatics \cite{chang2008bigtable,dayan2018optimalbloom,broder2004network,harris2020improved,marchet2023scalable,chikhi2025logan,hernandez2025reindeer2}. In the static setting, state-of-the-art designs such as XOR and fuse filters achieve low overhead and very fast queries, but their peeling-based construction succeeds only with high probability, which complicates deterministic builds \cite{graf2020xor,graf2022binary,ulrich2023taxor}.
We introduce \emph{ZOR filters}, a deterministic continuation of XOR/fuse filters that guarantees construction termination while preserving the same XOR-based query mechanism. ZOR replaces restart-on-failure with deterministic peeling that abandons a small fraction of keys, and restores false-positive-only semantics by storing the remainder in a compact auxiliary structure. In our experiments, the abandoned fraction drops below $1\%$ for moderate arity (e.g., $N\ge 5$), so the auxiliary handles a negligible fraction of keys. As a result, ZOR filters can achieve overhead within $1\%$ of the information-theoretic lower bound $\log_2(1/\varepsilon)$ while retaining fuse-like query performance; the additional cost is concentrated on negative queries due to the auxiliary check. Our current prototype builds several-fold slower than highly optimized fuse builders because it maintains explicit incidence information during deterministic peeling; closing this optimisation gap is an engineering target.
toXiv_bot_toot
From Isolation to Integration: Building an Adaptive Expert Forest for Pre-Trained Model-based Class-Incremental Learning
Ruiqi Liu, Boyu Diao, Hangda Liu, Zhulin An, Fei Wang, Yongjun Xu
https://arxiv.org/abs/2602.20911 https://arxiv.org/pdf/2602.20911 https://arxiv.org/html/2602.20911
arXiv:2602.20911v1 Announce Type: new
Abstract: Class-Incremental Learning (CIL) requires models to learn new classes without forgetting old ones. A common method is to freeze a pre-trained model and train a new, lightweight adapter for each task. While this prevents forgetting, it treats the learned knowledge as a simple, unstructured collection and fails to use the relationships between tasks. To this end, we propose the Semantic-guided Adaptive Expert Forest (SAEF), a new method that organizes adapters into a structured hierarchy for better knowledge sharing. SAEF first groups tasks into conceptual clusters based on their semantic relationships. Then, within each cluster, it builds a balanced expert tree by creating new adapters from merging the adapters of similar tasks. At inference time, SAEF finds and activates a set of relevant experts from the forest for any given input. The final prediction is made by combining the outputs of these activated experts, weighted by how confident each expert is. Experiments on several benchmark datasets show that SAEF achieves SOTA performance.
toXiv_bot_toot
celegans_interactomes: C. elegans interactomes (2009)
Ten networks of protein-protein interactions in Caenorhabditis elegans (nematode), from yeast two-hybrid experiments, biological process maps, literature curation, orthologous interactions, and genetic interactions. The WI8 network combines WI2004, WI2007 and BPmaps, while the Integrated Network combines data from all sources.
This network has 431 nodes and 438 edges.
Tags: Biological, Protein interactions, Unweighted
T1: One-to-One Channel-Head Binding for Multivariate Time-Series Imputation
Dongik Park, Hyunwoo Ryu, Suahn Bae, Keondo Park, Hyung-Sin Kim
https://arxiv.org/abs/2602.21043 https://arxiv.org/pdf/2602.21043 https://arxiv.org/html/2602.21043
arXiv:2602.21043v1 Announce Type: new
Abstract: Imputing missing values in multivariate time series remains challenging, especially under diverse missing patterns and heavy missingness. Existing methods suffer from suboptimal performance as corrupted temporal features hinder effective cross-variable information transfer, amplifying reconstruction errors. Robust imputation requires both extracting temporal patterns from sparse observations within each variable and selectively transferring information across variables--yet current approaches excel at one while compromising the other. We introduce T1 (Time series imputation with 1-to-1 channel-head binding), a CNN-Transformer hybrid architecture that achieves robust imputation through Channel-Head Binding--a mechanism creating one-to-one correspondence between CNN channels and attention heads. This design enables selective information transfer: when missingness corrupts certain temporal patterns, their corresponding attention pathways adaptively down-weight based on remaining observable patterns while preserving reliable cross-variable connections through unaffected channels. Experiments on 11 benchmark datasets demonstrate that T1 achieves state-of-the-art performance, reducing MSE by 46% on average compared to the second-best baseline, with particularly strong gains under extreme sparsity (70% missing ratio). The model generalizes to unseen missing patterns without retraining and uses a consistent hyperparameter configuration across all datasets. The code is available at https://github.com/Oppenheimerdinger/T1.
toXiv_bot_toot
celegans_interactomes: C. elegans interactomes (2009)
Ten networks of protein-protein interactions in Caenorhabditis elegans (nematode), from yeast two-hybrid experiments, biological process maps, literature curation, orthologous interactions, and genetic interactions. The WI8 network combines WI2004, WI2007 and BPmaps, while the Integrated Network combines data from all sources.
This network has 431 nodes and 438 edges.
Tags: Biological, Protein interactions, Unweighted
Exploring the Impact of Parameter Update Magnitude on Forgetting and Generalization of Continual Learning
JinLi He, Liang Bai, Xian Yang
https://arxiv.org/abs/2602.20796 https://arxiv.org/pdf/2602.20796 https://arxiv.org/html/2602.20796
arXiv:2602.20796v1 Announce Type: new
Abstract: The magnitude of parameter updates are considered a key factor in continual learning. However, most existing studies focus on designing diverse update strategies, while a theoretical understanding of the underlying mechanisms remains limited. Therefore, we characterize model's forgetting from the perspective of parameter update magnitude and formalize it as knowledge degradation induced by task-specific drift in the parameter space, which has not been fully captured in previous studies due to their assumption of a unified parameter space. By deriving the optimal parameter update magnitude that minimizes forgetting, we unify two representative update paradigms, frozen training and initialized training, within an optimization framework for constrained parameter updates. Our theoretical results further reveals that sequence tasks with small parameter distances exhibit better generalization and less forgetting under frozen training rather than initialized training. These theoretical insights inspire a novel hybrid parameter update strategy that adaptively adjusts update magnitude based on gradient directions. Experiments on deep neural networks demonstrate that this hybrid approach outperforms standard training strategies, providing new theoretical perspectives and practical inspiration for designing efficient and scalable continual learning algorithms.
toXiv_bot_toot
Deep unfolding of MCMC kernels: scalable, modular & explainable GANs for high-dimensional posterior sampling
Jonathan Spence, Tob\'ias I. Liaudat, Konstantinos Zygalakis, Marcelo Pereyra
https://arxiv.org/abs/2602.20758 https://arxiv.org/pdf/2602.20758 https://arxiv.org/html/2602.20758
arXiv:2602.20758v1 Announce Type: new
Abstract: Markov chain Monte Carlo (MCMC) methods are fundamental to Bayesian computation, but can be computationally intensive, especially in high-dimensional settings. Push-forward generative models, such as generative adversarial networks (GANs), variational auto-encoders and normalising flows offer a computationally efficient alternative for posterior sampling. However, push-forward models are opaque as they lack the modularity of Bayes Theorem, leading to poor generalisation with respect to changes in the likelihood function. In this work, we introduce a novel approach to GAN architecture design by applying deep unfolding to Langevin MCMC algorithms. This paradigm maps fixed-step iterative algorithms onto modular neural networks, yielding architectures that are both flexible and amenable to interpretation. Crucially, our design allows key model parameters to be specified at inference time, offering robustness to changes in the likelihood parameters. We train these unfolded samplers end-to-end using a supervised regularized Wasserstein GAN framework for posterior sampling. Through extensive Bayesian imaging experiments, we demonstrate that our proposed approach achieves high sampling accuracy and excellent computational efficiency, while retaining the physics consistency, adaptability and interpretability of classical MCMC strategies.
toXiv_bot_toot
celegans_interactomes: C. elegans interactomes (2009)
Ten networks of protein-protein interactions in Caenorhabditis elegans (nematode), from yeast two-hybrid experiments, biological process maps, literature curation, orthologous interactions, and genetic interactions. The WI8 network combines WI2004, WI2007 and BPmaps, while the Integrated Network combines data from all sources.
This network has 2528 nodes and 3864 edges.
Tags: Biological, Protein interactions, Unweighted
Why Pass@k Optimization Can Degrade Pass@1: Prompt Interference in LLM Post-training
Anas Barakat, Souradip Chakraborty, Khushbu Pahwa, Amrit Singh Bedi
https://arxiv.org/abs/2602.21189 https://arxiv.org/pdf/2602.21189 https://arxiv.org/html/2602.21189
arXiv:2602.21189v1 Announce Type: new
Abstract: Pass@k is a widely used performance metric for verifiable large language model tasks, including mathematical reasoning, code generation, and short-answer reasoning. It defines success if any of $k$ independently sampled solutions passes a verifier. This multi-sample inference metric has motivated inference-aware fine-tuning methods that directly optimize pass@$k$. However, prior work reports a recurring trade-off: pass@k improves while pass@1 degrades under such methods. This trade-off is practically important because pass@1 often remains a hard operational constraint due to latency and cost budgets, imperfect verifier coverage, and the need for a reliable single-shot fallback. We study the origin of this trade-off and provide a theoretical characterization of when pass@k policy optimization can reduce pass@1 through gradient conflict induced by prompt interference. We show that pass@$k$ policy gradients can conflict with pass@1 gradients because pass@$k$ optimization implicitly reweights prompts toward low-success prompts; when these prompts are what we term negatively interfering, their upweighting can rotate the pass@k update direction away from the pass@1 direction. We illustrate our theoretical findings with large language model experiments on verifiable mathematical reasoning tasks.
toXiv_bot_toot
celegans_interactomes: C. elegans interactomes (2009)
Ten networks of protein-protein interactions in Caenorhabditis elegans (nematode), from yeast two-hybrid experiments, biological process maps, literature curation, orthologous interactions, and genetic interactions. The WI8 network combines WI2004, WI2007 and BPmaps, while the Integrated Network combines data from all sources.
This network has 537 nodes and 554 edges.
Tags: Biological, Protein interactions, Unweighted
ProxyFL: A Proxy-Guided Framework for Federated Semi-Supervised Learning
Duowen Chen, Yan Wang
https://arxiv.org/abs/2602.21078 https://arxiv.org/pdf/2602.21078 https://arxiv.org/html/2602.21078
arXiv:2602.21078v1 Announce Type: new
Abstract: Federated Semi-Supervised Learning (FSSL) aims to collaboratively train a global model across clients by leveraging partially-annotated local data in a privacy-preserving manner. In FSSL, data heterogeneity is a challenging issue, which exists both across clients and within clients. External heterogeneity refers to the data distribution discrepancy across different clients, while internal heterogeneity represents the mismatch between labeled and unlabeled data within clients. Most FSSL methods typically design fixed or dynamic parameter aggregation strategies to collect client knowledge on the server (external) and / or filter out low-confidence unlabeled samples to reduce mistakes in local client (internal). But, the former is hard to precisely fit the ideal global distribution via direct weights, and the latter results in fewer data participation into FL training. To this end, we propose a proxy-guided framework called ProxyFL that focuses on simultaneously mitigating external and internal heterogeneity via a unified proxy. I.e., we consider the learnable weights of classifier as proxy to simulate the category distribution both locally and globally. For external, we explicitly optimize global proxy against outliers instead of direct weights; for internal, we re-include the discarded samples into training by a positive-negative proxy pool to mitigate the impact of potentially-incorrect pseudo-labels. Insight experiments & theoretical analysis show our significant performance and convergence in FSSL.
toXiv_bot_toot
Commissioning of a fast fine-step electron-energy-scan system for electron-ion crossed-beams experiments
B. Michel D\"ohring, Alexander Borovik Jr., Kurt Huber, Alfred M\"uller, Stefan Schippers
https://arxiv.org/abs/2603.09393
WeirNet: A Large-Scale 3D CFD Benchmark for Geometric Surrogate Modeling of Piano Key Weirs
Lisa L\"uddecke, Michael Hohmann, Sebastian Eilermann, Jan Tillmann-Mumm, Pezhman Pourabdollah, Mario Oertel, Oliver Niggemann
https://arxiv.org/abs/2602.20714 https://arxiv.org/pdf/2602.20714 https://arxiv.org/html/2602.20714
arXiv:2602.20714v1 Announce Type: new
Abstract: Reliable prediction of hydraulic performance is challenging for Piano Key Weir (PKW) design because discharge capacity depends on three-dimensional geometry and operating conditions. Surrogate models can accelerate hydraulic-structure design, but progress is limited by scarce large, well-documented datasets that jointly capture geometric variation, operating conditions, and functional performance. This study presents WeirNet, a large 3D CFD benchmark dataset for geometric surrogate modeling of PKWs. WeirNet contains 3,794 parametric, feasibility-constrained rectangular and trapezoidal PKW geometries, each scheduled at 19 discharge conditions using a consistent free-surface OpenFOAM workflow, resulting in 71,387 completed simulations that form the benchmark and with complete discharge coefficient labels. The dataset is released as multiple modalities compact parametric descriptors, watertight surface meshes and high-resolution point clouds together with standardized tasks and in-distribution and out-of-distribution splits. Representative surrogate families are benchmarked for discharge coefficient prediction. Tree-based regressors on parametric descriptors achieve the best overall accuracy, while point- and mesh-based models remain competitive and offer parameterization-agnostic inference. All surrogates evaluate in milliseconds per sample, providing orders-of-magnitude speedups over CFD runtimes. Out-of-distribution results identify geometry shift as the dominant failure mode compared to unseen discharge values, and data-efficiency experiments show diminishing returns beyond roughly 60% of the training data. By publicly releasing the dataset together with simulation setups and evaluation pipelines, WeirNet establishes a reproducible framework for data-driven hydraulic modeling and enables faster exploration of PKW designs during the early stages of hydraulic planning.
toXiv_bot_toot
celegans_interactomes: C. elegans interactomes (2009)
Ten networks of protein-protein interactions in Caenorhabditis elegans (nematode), from yeast two-hybrid experiments, biological process maps, literature curation, orthologous interactions, and genetic interactions. The WI8 network combines WI2004, WI2007 and BPmaps, while the Integrated Network combines data from all sources.
This network has 759 nodes and 1593 edges.
Tags: Biological, Protein interactions, Unweighted…
UrbanFM: Scaling Urban Spatio-Temporal Foundation Models
Wei Chen, Yuqian Wu, Junle Chen, Xiaofang Zhou, Yuxuan Liang
https://arxiv.org/abs/2602.20677 https://arxiv.org/pdf/2602.20677 https://arxiv.org/html/2602.20677
arXiv:2602.20677v1 Announce Type: new
Abstract: Urban systems, as dynamic complex systems, continuously generate spatio-temporal data streams that encode the fundamental laws of human mobility and city evolution. While AI for Science has witnessed the transformative power of foundation models in disciplines like genomics and meteorology, urban computing remains fragmented due to "scenario-specific" models, which are overfitted to specific regions or tasks, hindering their generalizability. To bridge this gap and advance spatio-temporal foundation models for urban systems, we adopt scaling as the central perspective and systematically investigate two key questions: what to scale and how to scale. Grounded in first-principles analysis, we identify three critical dimensions: heterogeneity, correlation, and dynamics, aligning these principles with the fundamental scientific properties of urban spatio-temporal data. Specifically, to address heterogeneity through data scaling, we construct WorldST. This billion-scale corpus standardizes diverse physical signals, such as traffic flow and speed, from over 100 global cities into a unified data format. To enable computation scaling for modeling correlations, we introduce the MiniST unit, a novel split mechanism that discretizes continuous spatio-temporal fields into learnable computational units to unify representations of grid-based and sensor-based observations. Finally, addressing dynamics via architecture scaling, we propose UrbanFM, a minimalist self-attention architecture designed with limited inductive biases to autonomously learn dynamic spatio-temporal dependencies from massive data. Furthermore, we establish EvalST, the largest-scale urban spatio-temporal benchmark to date. Extensive experiments demonstrate that UrbanFM achieves remarkable zero-shot generalization across unseen cities and tasks, marking a pivotal first step toward large-scale urban spatio-temporal foundation models.
toXiv_bot_toot
Fantastic 2.5 year postdoc working on 🤩emojis🤩 ! Are you a #linguist with experience in running experiments in formal semantics & pragmatics? Please come join our lab and the @… visual communication research cluster!
Apply by April 28 - or contact me with questions. #emojis #linguistics #job @… #academicChatter
https://jobs.ruhr-uni-bochum.de/jobposting/f5001c40d914e7ce325557bfe526aa88415f75bb0
interactome_stelzl: Stelzl human interactome (2005)
A network of human proteins and their binding interactions. Nodes represent proteins and an edge represents an interaction between two proteins, as inferred via high-throughput Y2H experiments using bait and prey methodology.
This network has 1706 nodes and 6207 edges.
Tags: Biological, Protein interactions, Unweighted
In situ magnetic-field stabilization for quantum-gas experiments
E. Gvozdiovas, A. Vald\'es-Curiel, Q. -Y. Liang, E. D. Mercado-Gutierrez, A. M. Pi\~neiro, J. Tao, D. Trypogeorgos, M. Zhao, I. B. Spielman
https://arxiv.org/abs/2603.06988
interactome_stelzl: Stelzl human interactome (2005)
A network of human proteins and their binding interactions. Nodes represent proteins and an edge represents an interaction between two proteins, as inferred via high-throughput Y2H experiments using bait and prey methodology.
This network has 1706 nodes and 6207 edges.
Tags: Biological, Protein interactions, Unweighted
interactome_stelzl: Stelzl human interactome (2005)
A network of human proteins and their binding interactions. Nodes represent proteins and an edge represents an interaction between two proteins, as inferred via high-throughput Y2H experiments using bait and prey methodology.
This network has 1706 nodes and 6207 edges.
Tags: Biological, Protein interactions, Unweighted
celegans_interactomes: C. elegans interactomes (2009)
Ten networks of protein-protein interactions in Caenorhabditis elegans (nematode), from yeast two-hybrid experiments, biological process maps, literature curation, orthologous interactions, and genetic interactions. The WI8 network combines WI2004, WI2007 and BPmaps, while the Integrated Network combines data from all sources.
This network has 912 nodes and 22738 edges.
Tags: Biological, Protein interactions, Unweighted
celegans_interactomes: C. elegans interactomes (2009)
Ten networks of protein-protein interactions in Caenorhabditis elegans (nematode), from yeast two-hybrid experiments, biological process maps, literature curation, orthologous interactions, and genetic interactions. The WI8 network combines WI2004, WI2007 and BPmaps, while the Integrated Network combines data from all sources.
This network has 537 nodes and 554 edges.
Tags: Biological, Protein interactions, Unweighted
celegans_interactomes: C. elegans interactomes (2009)
Ten networks of protein-protein interactions in Caenorhabditis elegans (nematode), from yeast two-hybrid experiments, biological process maps, literature curation, orthologous interactions, and genetic interactions. The WI8 network combines WI2004, WI2007 and BPmaps, while the Integrated Network combines data from all sources.
This network has 2528 nodes and 3864 edges.
Tags: Biological, Protein interactions, Unweighted
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.de