I keep seeing Americans who want to do something about the state of our #politics, but feel like no action they can take will do enough to fix things, so it’s not worth trying.
It’s easy to feel nihilistic. So I’d like to propose an alternative - a 10% improvement approach to political change, of sorts.
It comes from my #PTSD treatment: the idea that no one approach, skill, or intervention can make the #trauma just go away instantaneously. So instead, us humans are left with 10% solutions - things that help a little bit, for some amount of time.
The key to healing is to develop an ongoing set of multiple different solutions that you rotate through based on what feels feasible on any given day / moment. Each one helps a bit. 10%, 5%, 1%. But eventually, you get to making big changes that felt impossible at the start.
The same works for political change and activism. Sure, going to any one protest, or calling your representative, or boycotting a brand, or changing one person’s mind, or donating to one fundraiser won’t fix the entire broken political regime. But it will help A LITTLE.
And if a lot of us continue to find ways to do things that help a little, it will end up doing a lot more.
A movement starts with a thousand little steps that don’t look like much on their own.
Take that little step. Then another.
#USPol #activism #socialChange
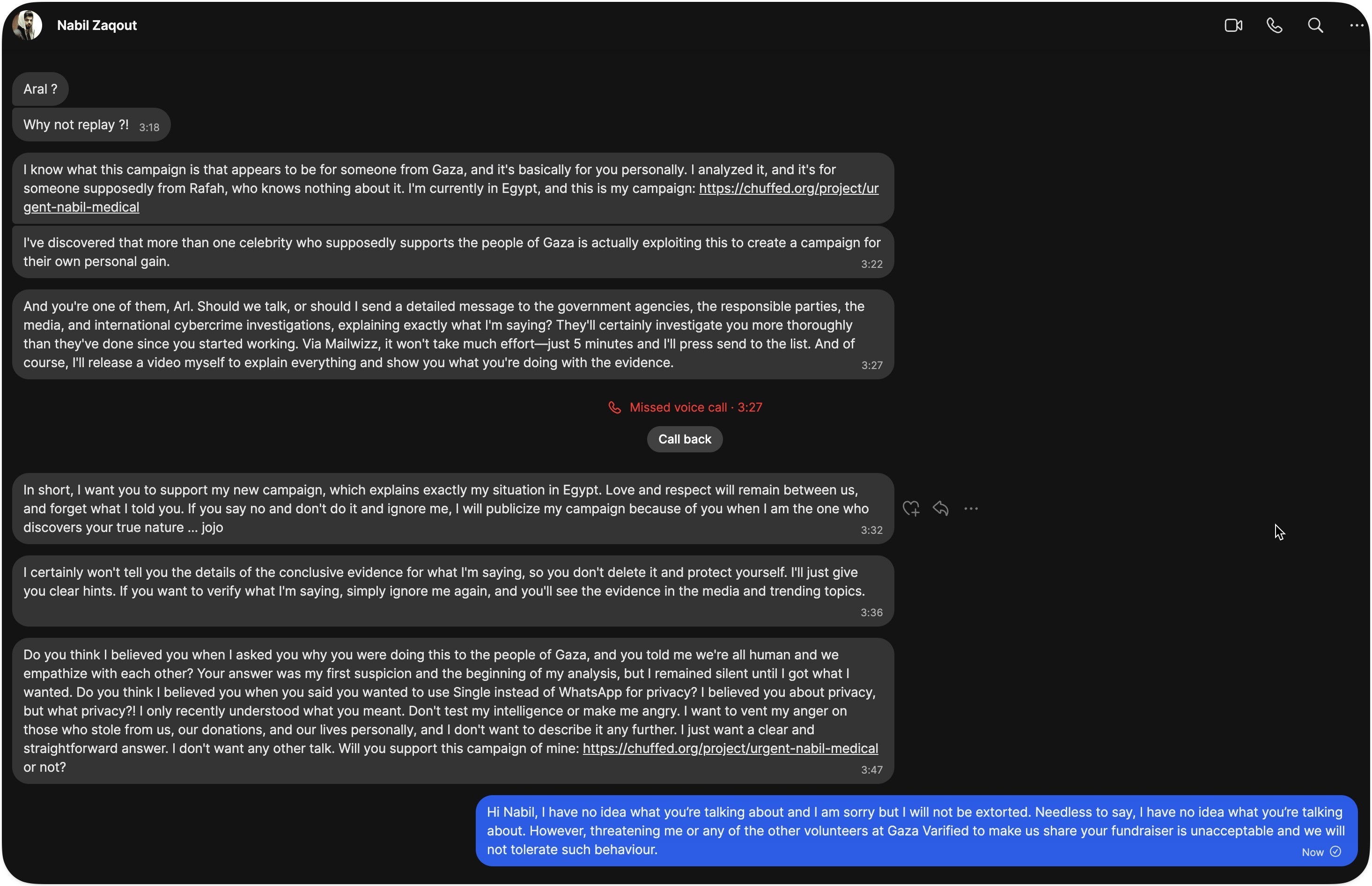
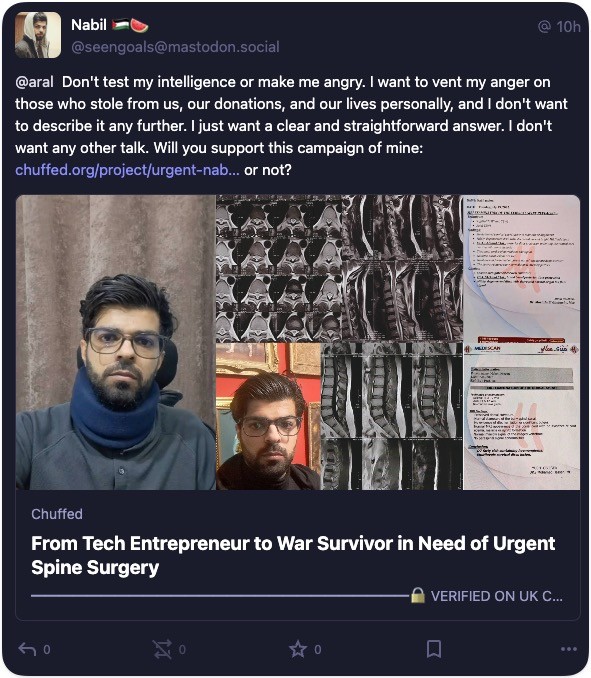
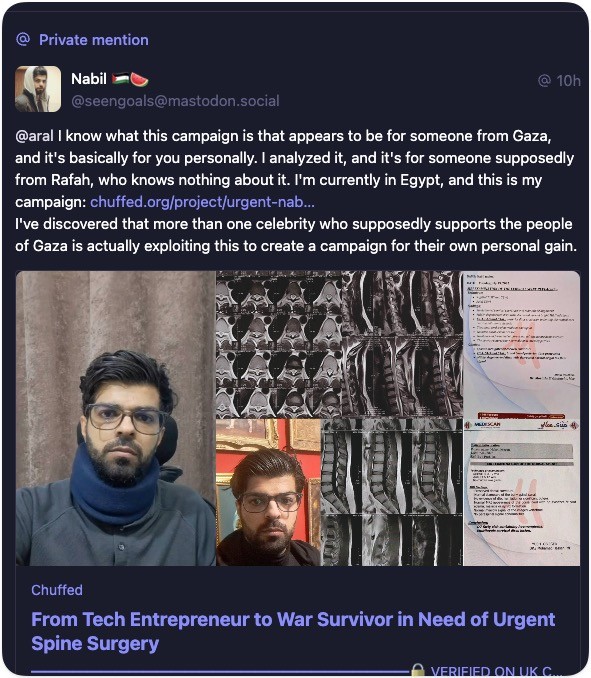
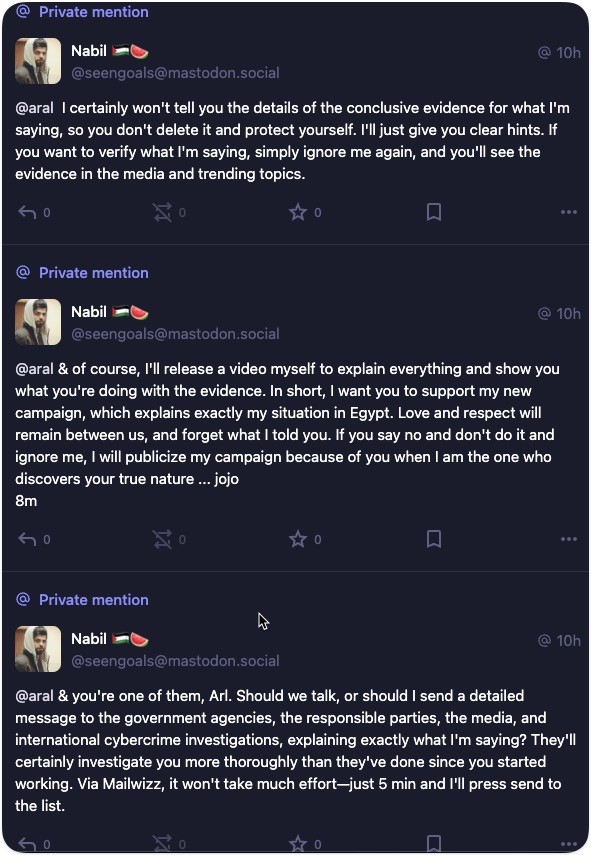
 @aral@mastodon.ar.al
@aral@mastodon.ar.al