@mszll@datasci.social
@mszll@datasci.social2026-05-04 16:17:39
Nice!
Urban Science Beyond Samples: Up-to-Date Street Network Models and Indicators for Every Urban Area in the World
https://arxiv.org/abs/2605.00108
@mszll@datasci.socialNice!
Urban Science Beyond Samples: Up-to-Date Street Network Models and Indicators for Every Urban Area in the World
https://arxiv.org/abs/2605.00108
 @Luc@dresden.network
@Luc@dresden.networkHübsches Projekt zur Reflexion künstlicher Intelligenz, Deepdive in Prompt Injection:
#artificialIntelligence
 @arXiv_quantph_bot@mastoxiv.page
@arXiv_quantph_bot@mastoxiv.pageSuper-Link Fragility in Asymmetric W-Class States under Quantum Noise
Sougata Bhattacharyya, Fatih Ozaydin, Sovik Roy
https://arxiv.org/abs/2606.12307 https://arxiv.org/pdf/2606.12307 https://arxiv.org/html/2606.12307
arXiv:2606.12307v1 Announce Type: new
Abstract: The asymmetric three-qubit W-class state $|\overline{W_3^L}\rangle$ defines an isosceles entanglement-network geometry, (a) two vertex-base (VB) links form stronger bipartite connections, (b) while the base-base (BB) link is weaker. This suggests that concentrating entanglement into a super-link may be advantageous for quantum-network tasks. Here, we show that this intuition is incomplete. We analytically compare the bipartite concurrence dynamics of the symmetric |W> state and the asymmetric $|\overline{W_3^L}\rangle$ state, which differ both in entanglement-network geometry and excitation sector under standard noise models. In the absence of noise, the concurrence hierarchy is C_{VB} > C_W > C_{BB}$. Under phase damping, this hierarchy is preserved for all noise strengths and no entanglement sudden death occurs. Under amplitude damping, however, the hierarchy is reordered. The symmetric |W> state becomes the most robust, while the base-base concurrence of $|\overline{W_3^L}\rangle$ vanishes at the finite threshold of parameter $\gamma$. We term this reordering as the \textit{Super-Link Fragility Effect}. The same structural asymmetry that produces a stronger vertex-base link also makes it more vulnerable to energy dissipation when coupled with multi-excitation amplitudes. Under depolarization, the asymmetry advantage is erased, with $C_W$ and $C_{VB}$ sharing the same sudden-death threshold for some value of the parameter p, while $C_{BB}$ disappears earlier at some other value of the parameter p. The generalized amplitude damping channel continuously connects the damping-dominated regime to the pure-excitation limit, where the initial hierarchy is restored. These results show that entanglement robustness in $W$-class resources is controlled not by initial concurrence alone, but by the joint structure of entanglement-network geometry, excitation sector, and noise symmetry.
toXiv_bot_toot
 @cdarwin@c.im
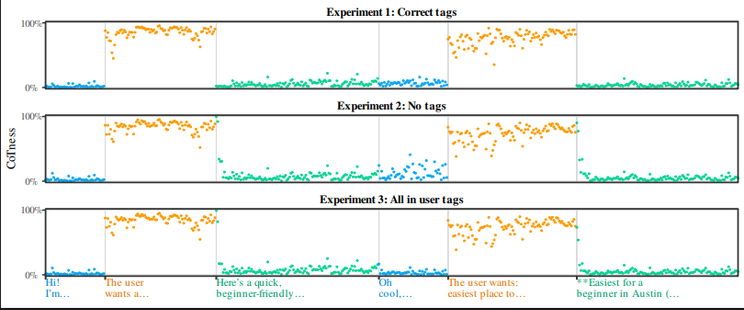
@cdarwin@c.imOn April 23, 2026, the White House released a memo warning that Chinese entities were running “industrial-scale” distillation campaigns against American frontier AI models,
leveraging “tens of thousands of proxy accounts” to evade detection.
In February 2026, Anthropic similarly reported on Chinese labs’ coordinated distillation attacks using
“a single proxy network managed more than 20,000 fraudulent accounts”.
Both cases see “proxy”
— the middlemen between …
 @arXiv_physicsgeoph_bot@mastoxiv.page
@arXiv_physicsgeoph_bot@mastoxiv.pageSeismic full waveform inversion via a physics-guided Fourier representation neural network
Gui Chen, Yang Liu, Haoran Zhang, Mi Zhang
https://arxiv.org/abs/2606.30126 https://arxiv.org/pdf/2606.30126 https://arxiv.org/html/2606.30126
arXiv:2606.30126v1 Announce Type: new
Abstract: Accurate subsurface velocity models are essential for seismic imaging, yet conventional full waveform inversion (FWI) often suffers from cycle skipping, noise sensitivity, and reliance on good initial models. We develop a physics-guided Fourier representation neural network (PGFRNN) for unsupervised acoustic FWI and simultaneous-source FWI (SSFWI), which embeds Fourier-transformed seismic data into a latent space and iteratively updates the velocity model using a softplus-approximated log-cosh (SALC) loss and a physics-guided optimizer. Numerical tests on the Overthrust model demonstrate that PGFRNN outperforms conventional L2- and SALC-loss-based FWI methods, achieving higher inversion accuracy and robustness to noise and challenging initial models.
toXiv_bot_toot
@mszll@datasci.socialNice!
Urban Science Beyond Samples: Up-to-Date Street Network Models and Indicators for Every Urban Area in the World
https://arxiv.org/abs/2605.00108
 @arXiv_physicscompph_bot@mastoxiv.page
@arXiv_physicscompph_bot@mastoxiv.pageFinite Element-Based Material Learning via Automatic Differentiation: Learning constitutive neural network models from full-field deformation data
Matthias Knipper, Chenyi Ji, Malte Brand, Kevin Linka
https://arxiv.org/abs/2606.05199
 @arXiv_physicsaoph_bot@mastoxiv.page
@arXiv_physicsaoph_bot@mastoxiv.pageVisibility nowcasting in South Korea: a machine learning approach to class imbalance and distribution shift
Bong Gyun Shin, Chan Sik Lee, Hyesun Suh
https://arxiv.org/abs/2605.21507 https://arxiv.org/pdf/2605.21507 https://arxiv.org/html/2605.21507
arXiv:2605.21507v1 Announce Type: new
Abstract: Atmospheric visibility is a critical variable for transportation safety and air quality management, however, accurate prediction remains challenging due to the complex interactions between meteorological conditions and air pollutants, as well as the rarity of low-visibility events. This study introduces a machine learning framework to nowcast visibility in six major South Korean cities. To handle the imbalance in the 2018-2020 training data, we applied the Synthetic Minority Over-sampling Technique with Nominal and Continuous (SMOTENC) and Conditional Tabular Generative Adversarial Network (CTGAN). An ensemble approach combining machine learning and deep learning models was then used and evaluated on a 2021 test dataset. The results revealed a marked decline in predictive performance in the test set compared to the cross-validation phase. This degradation was attributed to a distributional shift between training and testing periods, which was quantitatively confirmed by measuring the Wasserstein distance of the most influential feature identified by SHAP analysis. In general, this study presents a methodology that aims to simultaneously address the dual challenges of data imbalance and temporal distributional shifts, and emphasizes the necessity of accounting for evolving external environmental factors when implementing nowcasting models on time-series data.
toXiv_bot_toot
 @arXiv_physicsfludyn_bot@mastoxiv.page
@arXiv_physicsfludyn_bot@mastoxiv.pageReplaced article(s) found for physics.flu-dyn. https://arxiv.org/list/physics.flu-dyn/new
[1/1]:
- On the stability of an in-line formation of hydrodynamically interacting flapping plates
Monika Nitsche, Anand U. Oza, Michael Siegel
https://arxiv.org/abs/2410.04626 https://mastoxiv.page/@arXiv_physicsfludyn_bot/113270998236203403
- Side-wall wetting and linear stability of falling films
Hammam Mohamed, J\"orn Sesterhenn
https://arxiv.org/abs/2504.13300 https://mastoxiv.page/@arXiv_physicsfludyn_bot/114374794050144417
- An Omni-Temporal Theory for Hydrodynamic Dispersion and Reaction in Porous Media
Md Abdul Hamid, Kyle C. Smith
https://arxiv.org/abs/2505.06063 https://mastoxiv.page/@arXiv_physicsfludyn_bot/114493702701690116
- Confirming Wave Turbulence Predictions in Rotating Turbulence
Omri Shaltiel, Omri Gat, Eran Sharon
https://arxiv.org/abs/2510.25446 https://mastoxiv.page/@arXiv_physicsfludyn_bot/115462467154250733
- Using Physics Informed Neural Network (PINN) and Neural Network (NN) to Improve a $k-\omega$ Turb...
Lars Davidson
https://arxiv.org/abs/2511.12493 https://mastoxiv.page/@arXiv_physicsfludyn_bot/115570134553603649
- Oscillating Detonation of Liquid Ammonia
Wenhao Wang, Zongmin Hu, Peng Zhang
https://arxiv.org/abs/2511.14167 https://mastoxiv.page/@arXiv_physicsfludyn_bot/115575358542454196
- On the Poisson-Source Basis of Logarithmic Wall-Pressure-Variance Growth
Jonathan M. O. Massey, Joseph C. Klewicki, Beverley J. McKeon
https://arxiv.org/abs/2511.16776 https://mastoxiv.page/@arXiv_physicsfludyn_bot/115603689363840109
- Convolutional causal learning for aerodynamic flows
Ryo Koshikawa, Ryo Araki, Qiong Liu, Kai Fukami
https://arxiv.org/abs/2601.19104 https://mastoxiv.page/@arXiv_physicsfludyn_bot/115971839485449464
- Assessing engineering wake models against operational data: insights from the Lillgrund wind farm...
Siguenza-Alvarado, Harrison, Mohammadi, Vishwakarma, Bossanyi, Landberg, Bastankhah
https://arxiv.org/abs/2601.21035 https://mastoxiv.page/@arXiv_physicsfludyn_bot/115983015393462612
- Neural equilibria for long-term prediction of nonlinear conservation laws
Benitez, Hegazy, Guo, Dokmani\'c, Mahoney, de Hoop
https://arxiv.org/abs/2501.06933 https://mastoxiv.page/@arXiv_csLG_bot/113825452743912532
- Self-similar rupture of thin films of power-law fluid
Michael C Dallaston, Steven A Kedda, Scott W McCue
https://arxiv.org/abs/2509.05383 https://mastoxiv.page/@arXiv_condmatsoft_bot/115173629129170202
- Instability and self-propulsion of flexible autophoretic filaments
Ursy Makanga, Akhil Varma, Panayiota Katsamba
https://arxiv.org/abs/2509.10153 https://mastoxiv.page/@arXiv_condmatsoft_bot/115207443699020835
- Analytical response functions for a compressible thin fluid layer with odd viscosity
Abdallah Daddi-Moussa-Ider, Yuto Hosaka, Shigeyuki Komura
https://arxiv.org/abs/2602.18136 https://mastoxiv.page/@arXiv_condmatsoft_bot/116119064615788127
toXiv_bot_toot
@arXiv_physicsgeoph_bot@mastoxiv.pageTwo kinds of robustness are not the same: disentangling fault tolerance and low-SNR robustness in multi-domain event detection on real data
Isao Kurosawa
https://arxiv.org/abs/2606.29339 https://arxiv.org/pdf/2606.29339 https://arxiv.org/html/2606.29339
arXiv:2606.29339v1 Announce Type: new
Abstract: Reliable event detection underpins induced-seismicity monitoring for Carbon dioxide Capture and Storage (CCS) and geothermal operations, distributed acoustic sensing (DAS), and industrial condition monitoring. In each setting a detector must stay reliable both when sensors fail and when the signal is buried in noise. These two failure modes are routinely conflated, and architectural complexity is often credited with robustness it may not deserve. We assemble a unified binary event-detection benchmark from three physically distinct real sources -- Hi-net seismic waveforms, Utah FORGE 2024 borehole DAS, and MAFAULDA industrial vibration -- each mapped to a common 8-channel, 256-sample representation, and evaluate a fault-tolerant detector (CEPHALON) trained with per-sample sensor-dropout against standard detectors (a 1D convolutional network, a temporal convolutional network, and a compact Transformer) trained with an identical recipe. On clean data every model is near-perfect (AUC ~ 0.99). Under progressive sensor loss, simple models with sensor-dropout are already robust and CEPHALON holds no advantage. Under additive noise, however, CEPHALON degrades far more gracefully: at -2.5 dB its overall AUC is 0.939 versus 0.532-0.572 for the convolutional baselines. Same-architecture ablations isolate the cause: disabling internal redundancy at inference reduces the low-SNR advantage only modestly, whereas removing sensor-dropout training collapses it (0.899 to 0.603 at -5 dB). The training recipe is therefore the dominant cause and parallel redundancy only secondary. We release a complete, numbered, reproducible pipeline so that every figure can be regenerated.
toXiv_bot_toot
@arXiv_physicscompph_bot@mastoxiv.pageLSR-Net: Long-Short-Range Operator Learning for Pattern Dynamics on Manifolds
Qian Serena Hou, Zecheng Gan
https://arxiv.org/abs/2607.00750 https://arxiv.org/pdf/2607.00750 https://arxiv.org/html/2607.00750
arXiv:2607.00750v1 Announce Type: new
Abstract: We propose the Long-Short-Range Neural Network (LSR-Net), an extensible operator-learning framework for predicting pattern dynamics on planar domains, spherical surfaces, and general manifolds. The method decomposes the forward evolution operator into a long-range component, represented by a compact Fourier multiplier constructed via the Sum-of-Exponentials (SOE) approximation, and a short-range component adapted to the underlying geometry and its intrinsic symmetries. For general manifolds represented by irregularly sampled point clouds, the long-range component is implemented by Gaussian gridding onto an auxiliary regular grid, where the Fourier multiplier is efficiently applied in k-space using FFT and the result is interpolated back to the original sample points. We evaluate LSR-Net on several benchmark systems, including the Allen-Cahn, Cahn-Hilliard, Schnakenberg, and Turing systems, over planar domains, spherical surfaces, and a blob-shaped manifold. Numerical results demonstrate that LSR-Net consistently achieves higher accuracy and improved stability compared with baseline operator-learning models. In particular, for Allen-Cahn dynamics on the sphere, the RMSE is reduced by approximately three orders of magnitude compared with the Spherical Fourier Neural Operator (SFNO). Rotation and reflection equivariance tests further confirm that the learned operator is consistent with these geometric transformations. These results indicate that LSR-Net provides an effective and robust approach for learning pattern dynamics on complex geometries.
toXiv_bot_toot