 @cdarwin@c.im
@cdarwin@c.im2025-12-20 16:52:13
The most prominent American voice at the COP Climate Summit in Belém was that of the California governor, Gavin Newsom.
During the five days he spent in Brazil, Newsom described Donald Trump as an “invasive species”
and condemned his rollback of policies aimed at reducing emissions and expanding renewable energy.
Newsom, long considered a presidential hopeful, argued that,
as the US retreated, California would step up in its place as a
“stable, reliable” climat…
 @markhburton@mstdn.social
@markhburton@mstdn.social2025-11-11 14:35:35
Mapped: Big Food’s Routes to Influence at COP30 - DeSmog https://www.desmog.com/2025/11/10/mapped-big-foods-routes-to-influence-at-cop30/

 @andres4ny@social.ridetrans.it
@andres4ny@social.ridetrans.it2025-12-14 02:21:41
For #Caturday, a reminder that Widget remains available for adoption in the NYC metro area. She would prefer a calm house without kids (we are not a calm house). She's super affectionate! #CatsOfMastodon




 @mro@digitalcourage.social
@mro@digitalcourage.social2025-12-12 19:48:58
⭐ The Simple Habit That Saves My Evenings | alikhil | software engineering, kubernetes & self-hosting
https://alikhil.dev/posts/the-simple-habit-that-saves-my-evenings/
Spoiler alert:
Here are the two main ideas of it:
* Don’t overwork
*…
 @UP8@mastodon.social
@UP8@mastodon.social2025-12-01 13:10:09
🤦♂️ COP30 climate pledges favor unrealistic land-based carbon removal over emission cuts, says report
https://phys.org/news/2025-11-cop30-climate-pledges-favor-unrealistic.html

 @stefanlaser@social.tchncs.de
@stefanlaser@social.tchncs.de2025-11-06 19:46:40
A tiny side-project that I can hopefully pull through: reverse engineering an audio box for kids that works with proprietary “tokens.” Like a cassette player but rigid af. Use and dispose. #hackerspace #netz39
First stop, getting info about chips and pins. A cheap USB microcontroller it i…


 @patrikja@functional.cafe
@patrikja@functional.cafe2025-09-30 13:15:31
🌍 The climate crisis demands urgent action. But which actions are best?
Decision makers face tough trade-offs:
Policy A lowers emissions at home but increases reliance on imports.
Policy B cuts emissions long-term but raises unemployment short-term.
Policy C boosts jobs now but increases emissions in the near term.
None of these choices are simple. A policy that looks good locally may increase global emissions, or its effects may depend on what other countries d…
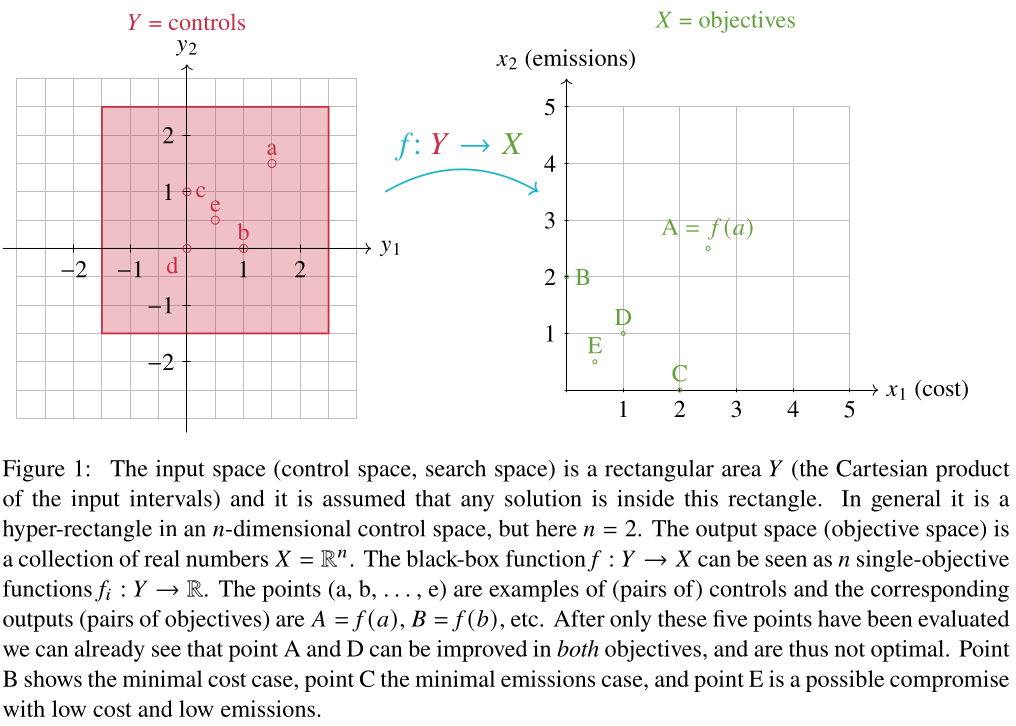
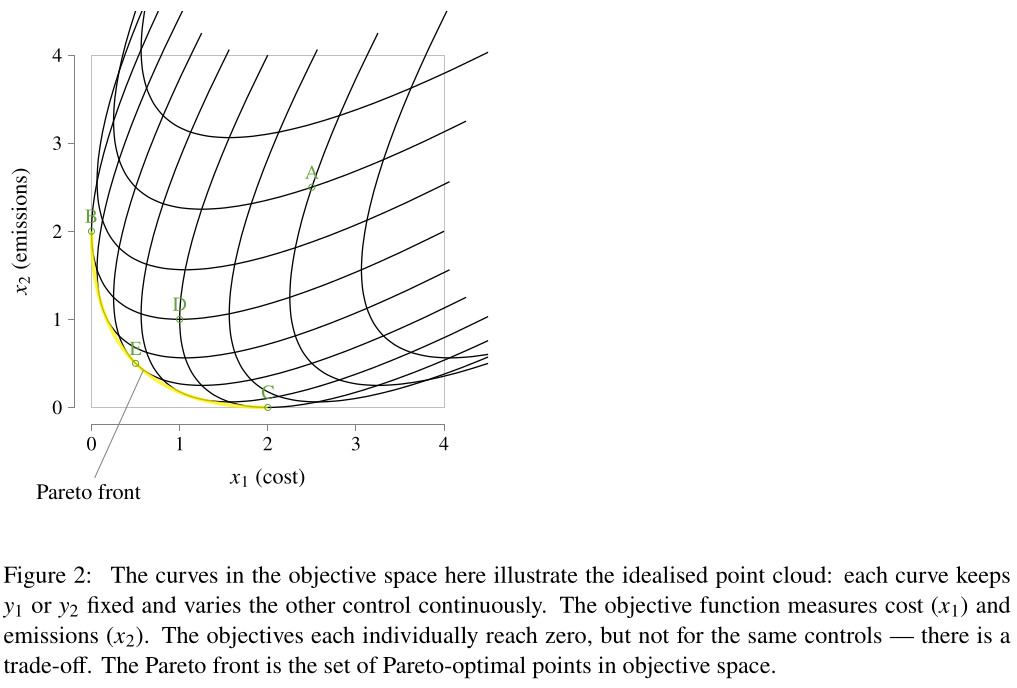
 @deprogrammaticaipsum@mas.to
@deprogrammaticaipsum@mas.to2025-11-30 17:14:51
"Technical communities provide software businesses with an audience, a test bed, and eventually, a customer pool for their products and services, but this only works if the products are good enough to begin with. This insight was clearly defined by Guy Kawasaki, arguably the person who invented the field of Developer Relations, during his tenure as Chief Evangelist at Apple from 1983 to 1987."

 @arXiv_astrophGA_bot@mastoxiv.page
@arXiv_astrophGA_bot@mastoxiv.page2025-10-10 09:14:59
Unified Spectrospatial Forward Models: Spatially Continuous Maps of Weak Emission Lines in the Rosette Nebula with SDSS-V LVM
Thomas Hilder, Andrew R. Casey, Julianne J. Dalcanton, Kathryn Kreckel, Amelia M. Stutz, Amrita Singh, Guillermo A. Blanc, Sebasti\'an F. S\'anchez, J. E. M\'endez-Delgado, Andrew K. Saydjari, Luciano Vargas-Herrera, Niv Drory, Dmitry Bizyaev, Jos\'e G. Fern\'andez-Trincado, Carlos G. Rom\'an-Z\'u\~niga, Juna A. Kollmeier, Evelyn J. J…
 @markhburton@mstdn.social
@markhburton@mstdn.social2025-10-29 14:22:50
"Due to [nuclear's] cost and complexity, it will not provide cheap or low-emission electricity in timeframe or scale that matters as climate change continues to broil an indifferent civilization."
The New Nuclear Fever, Debunked - resilience
https://www.resilience.org/stori…
