Experimental insights into data augmentation techniques for deep learning-based multimode fiber imaging: limitations and success
Jawaria Maqbool, M. Imran Cheema
https://arxiv.org/abs/2511.19072 https://arxiv.org/pdf/2511.19072 https://arxiv.org/html/2511.19072
arXiv:2511.19072v1 Announce Type: new
Abstract: Multimode fiber~(MMF) imaging using deep learning has high potential to produce compact, minimally invasive endoscopic systems. Nevertheless, it relies on large, diverse real-world medical data, whose availability is limited by privacy concerns and practical challenges. Although data augmentation has been extensively studied in various other deep learning tasks, it has not been systematically explored for MMF imaging. This work provides the first in-depth experimental and computational study on the efficacy and limitations of augmentation techniques in this field. We demonstrate that standard image transformations and conditional generative adversarial-based synthetic speckle generation fail to improve, or even deteriorate, reconstruction quality, as they neglect the complex modal interference and dispersion that results in speckle formation. To address this, we introduce a physical data augmentation method in which only organ images are digitally transformed, while their corresponding speckles are experimentally acquired via fiber. This approach preserves the physics of light-fiber interaction and enhances the reconstruction structural similarity index measure~(SSIM) by up to 17\%, forming a viable system for reliable MMF imaging under limited data conditions.
toXiv_bot_toot
Microsoft provided the FBI with the recovery keys to unlock encrypted data on the hard drives of three laptops as part of a federal investigation, Forbes reported on Friday.
Many modern Windows computers rely on full-disk encryption, called #BitLocker, which is enabled by default.
This type of technology should prevent anyone except the device owner from accessing the data if the computer is …
MOCLIP: A Foundation Model for Large-Scale Nanophotonic Inverse Design
S. Rodionov, A. Burguete-Lopez, M. Makarenko, Q. Wang, F. Getman, A. Fratalocchi
https://arxiv.org/abs/2511.18980 https://arxiv.org/pdf/2511.18980 https://arxiv.org/html/2511.18980
arXiv:2511.18980v1 Announce Type: new
Abstract: Foundation models (FM) are transforming artificial intelligence by enabling generalizable, data-efficient solutions across different domains for a broad range of applications. However, the lack of large and diverse datasets limits the development of FM in nanophotonics. This work presents MOCLIP (Metasurface Optics Contrastive Learning Pretrained), a nanophotonic foundation model that integrates metasurface geometry and spectra within a shared latent space. MOCLIP employs contrastive learning to align geometry and spectral representations using an experimentally acquired dataset with a sample density comparable to ImageNet-1K. The study demonstrates MOCLIP inverse design capabilities for high-throughput zero-shot prediction at a rate of 0.2 million samples per second, enabling the design of a full 4-inch wafer populated with high-density metasurfaces in minutes. It also shows generative latent-space optimization reaching 97 percent accuracy. Finally, we introduce an optical information storage concept that uses MOCLIP to achieve a density of 0.1 Gbit per square millimeter at the resolution limit, exceeding commercial optical media by a factor of six. These results position MOCLIP as a scalable and versatile platform for next-generation photonic design and data-driven applications.
toXiv_bot_toot
🎬 Rich actions with confirmation dialogs, onSuccess & onError callbacks
👁️ Conditional visibility based on data, auth, or complex logic
📦 Two packages: @.json-render/core (types, schemas) @.json-render/react (renderer, hooks)
🔧 Schema definition with #Zod for type-safe component props
📤 Export as standalone
You Only Train Once: Differentiable Subset Selection for Omics Data
Daphn\'e Chopard, Jorge da Silva Gon\c{c}alves, Irene Cannistraci, Thomas M. Sutter, Julia E. Vogt
https://arxiv.org/abs/2512.17678 https://arxiv.org/pdf/2512.17678 https://arxiv.org/html/2512.17678
arXiv:2512.17678v1 Announce Type: new
Abstract: Selecting compact and informative gene subsets from single-cell transcriptomic data is essential for biomarker discovery, improving interpretability, and cost-effective profiling. However, most existing feature selection approaches either operate as multi-stage pipelines or rely on post hoc feature attribution, making selection and prediction weakly coupled. In this work, we present YOTO (you only train once), an end-to-end framework that jointly identifies discrete gene subsets and performs prediction within a single differentiable architecture. In our model, the prediction task directly guides which genes are selected, while the learned subsets, in turn, shape the predictive representation. This closed feedback loop enables the model to iteratively refine both what it selects and how it predicts during training. Unlike existing approaches, YOTO enforces sparsity so that only the selected genes contribute to inference, eliminating the need to train additional downstream classifiers. Through a multi-task learning design, the model learns shared representations across related objectives, allowing partially labeled datasets to inform one another, and discovering gene subsets that generalize across tasks without additional training steps. We evaluate YOTO on two representative single-cell RNA-seq datasets, showing that it consistently outperforms state-of-the-art baselines. These results demonstrate that sparse, end-to-end, multi-task gene subset selection improves predictive performance and yields compact and meaningful gene subsets, advancing biomarker discovery and single-cell analysis.
toXiv_bot_toot
Optical kernel machine with programmable nonlinearity
SeungYun Han, Fei Xia, Sylvain Gigan, Bruno Loureiro, Hui Cao
https://arxiv.org/abs/2511.17880 https://arxiv.org/pdf/2511.17880 https://arxiv.org/html/2511.17880
arXiv:2511.17880v1 Announce Type: new
Abstract: Optical kernel machines offer high throughput and low latency. A nonlinear optical kernel can handle complex nonlinear data, but power consumption is typically high with the conventional nonlinear optical approach. To overcome this issue, we present an optical kernel with structural nonlinearity that can be continuously tuned at low power. It is implemented in a linear optical scattering cavity with a reconfigurable micro-mirror array. By tuning the degree of nonlinearity with multiple scattering, we vary the kernel sensitivity and information capacity. We further optimize the kernel nonlinearity to best approximate the parity functions from first order to fifth order for binary inputs. Our scheme offers potential applicability across photonic platforms, providing programmable kernels with high performance and low power consumption.
toXiv_bot_toot
#Ørsted will juristisch gegen den Stopp seines Offshore-Windparks #RevolutionWind vorgehen.
Das fünf Milliarden Dollar teure Projekt vor der US-Ostküste wurde kurz vor Fertigstellung durch die Regierung #Trump
High-precision luminescence cryothermometry strategy by using hyperfine structure
Marina N. Popova, Mosab Diab, Boris Z. Malkin
https://arxiv.org/abs/2511.19088 https://arxiv.org/pdf/2511.19088 https://arxiv.org/html/2511.19088
arXiv:2511.19088v1 Announce Type: new
Abstract: A novel, to the best of our knowledge, ultralow-temperature luminescence thermometry strategy is proposed, based on a measurement of relative intensities of hyperfine components in the spectra of Ho$^{3 }$ ions doped into a crystal. A $^{7}$LiYF$_4$:Ho$^{3 }$ crystal is chosen as an example. First, we show that temperatures in the range 10-35 K can be measured using the Boltzmann behavior of the populations of crystal-field levels separated by an energy interval of 23 cm$^{-1}$. Then we select the 6089 cm$^{-1}$ line of the holmium $^5I_5 \rightarrow ^5I_7$ transition, which has a well-resolved hyperfine structure and falls within the transparency window of optical fibers (telecommunication S band), to demonstrate the possibility of measuring temperatures below 3 K. The temperature $T$ is determined by a least-squares fit to the measured intensities of all eight hyperfine components using the dependence $I(\nu) = I_1 \exp(-b\nu)$, where $I_1$ and $b = a\nu \frac{\nu}{kT}$ are fitting parameters and a accounts for intensity variations due to mixing of wave functions of different crystal-field levels by the hyperfine interaction. In this method, the absolute and relative thermal sensitivities grow at $T$ approaching zero as $\frac{1}{T^2}$.and $\frac{1}{T}$, respectively. We theoretically considered the intensity distributions within hyperfine manifolds and compared the results with experimental data. Application of the method to experimentally measured relative intensities of hyperfine components of the 6089 cm$^{-1}$ PL line yielded $T = 3.7 \pm 0.2$ K. For a temperature of 1 K, an order of magnitude better accuracy is expected.
toXiv_bot_toot
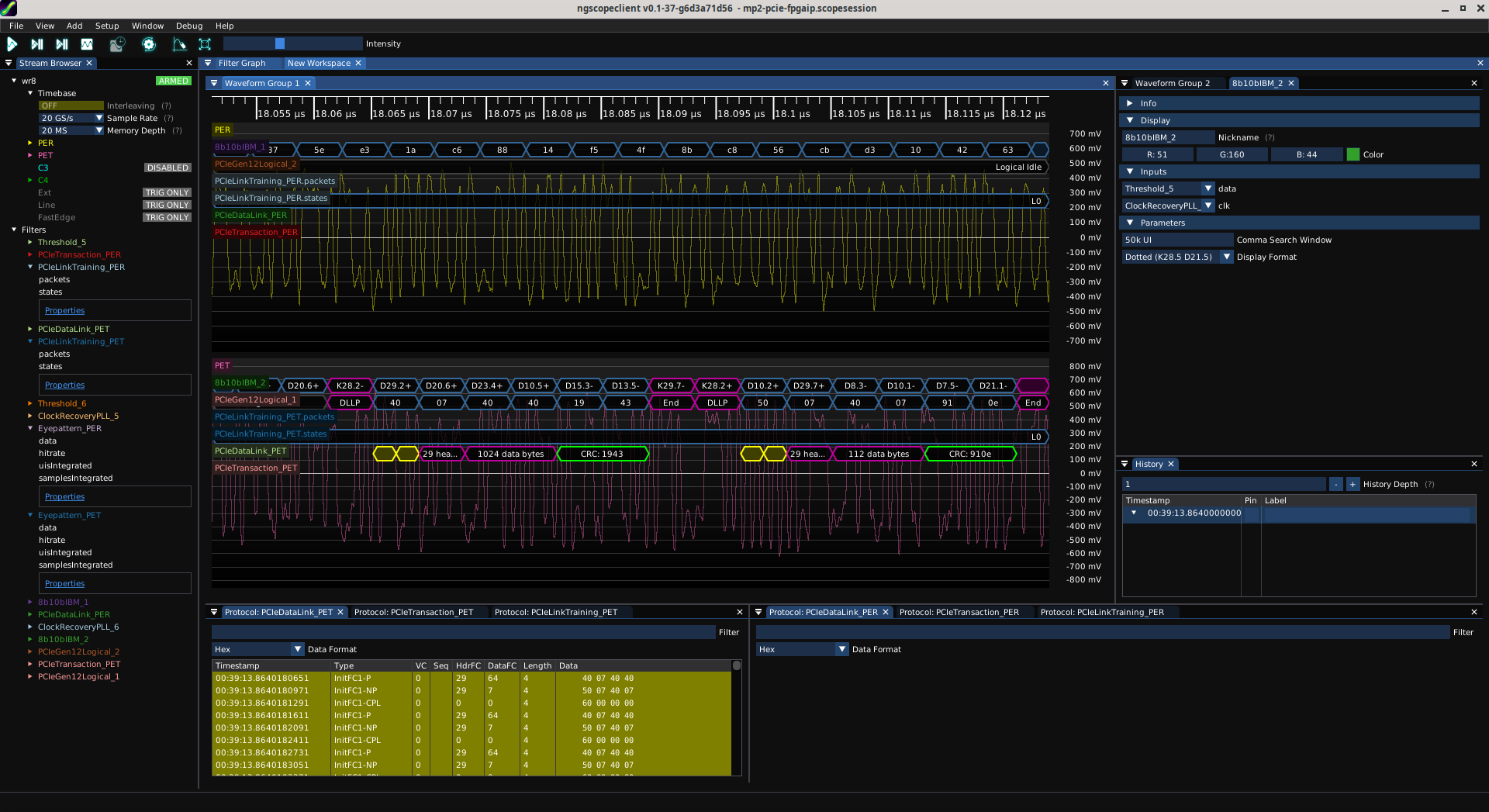
Well that took a bit longer than I hoped thanks to some derps on my part, but I'm parsing incoming PCIe DLLPs and validating their checksums.
Next step will be to figure out that a type 0x40 DLLP with payload 074040 is actually an InitFC1-P DLLP for virtual circuit 0 for 29 headers and 1024 data bytes.
And do something useful with that information.
Google has filed a lawsuit to protect its search results,
targeting a firm called SerpApi
that has turned Google’s 10 blue links into a business.
According to Google, SerpApi ignores established law and Google’s terms
to scrape and resell its search engine results pages (SERPs).
This is not the first action against SerpApi, but Google’s decision to go after a scraper could signal a new, more aggressive stance on protecting its search data.
#TIL
> The macros describing this structure live in <asm/ioctl.h> and are
> _IO(type,nr) and {_IOR,_IOW,_IOWR}(type,nr,size). They use
> sizeof(size) so that size is a misnomer here: this third argument
> is a data type.
>
> Note that the size bits are very unreliable: in lots of cases they
> are wrong, either because of buggy macros using
> sizeof(sizeof(struct)), or because of legacy values.
#Linux
Regularized Random Fourier Features and Finite Element Reconstruction for Operator Learning in Sobolev Space
Xinyue Yu, Hayden Schaeffer
https://arxiv.org/abs/2512.17884 https://arxiv.org/pdf/2512.17884 https://arxiv.org/html/2512.17884
arXiv:2512.17884v1 Announce Type: new
Abstract: Operator learning is a data-driven approximation of mappings between infinite-dimensional function spaces, such as the solution operators of partial differential equations. Kernel-based operator learning can offer accurate, theoretically justified approximations that require less training than standard methods. However, they can become computationally prohibitive for large training sets and can be sensitive to noise. We propose a regularized random Fourier feature (RRFF) approach, coupled with a finite element reconstruction map (RRFF-FEM), for learning operators from noisy data. The method uses random features drawn from multivariate Student's $t$ distributions, together with frequency-weighted Tikhonov regularization that suppresses high-frequency noise. We establish high-probability bounds on the extreme singular values of the associated random feature matrix and show that when the number of features $N$ scales like $m \log m$ with the number of training samples $m$, the system is well-conditioned, which yields estimation and generalization guarantees. Detailed numerical experiments on benchmark PDE problems, including advection, Burgers', Darcy flow, Helmholtz, Navier-Stokes, and structural mechanics, demonstrate that RRFF and RRFF-FEM are robust to noise and achieve improved performance with reduced training time compared to the unregularized random feature model, while maintaining competitive accuracy relative to kernel and neural operator tests.
toXiv_bot_toot
Spatially-informed transformers: Injecting geostatistical covariance biases into self-attention for spatio-temporal forecasting
Yuri Calleo
https://arxiv.org/abs/2512.17696 https://arxiv.org/pdf/2512.17696 https://arxiv.org/html/2512.17696
arXiv:2512.17696v1 Announce Type: new
Abstract: The modeling of high-dimensional spatio-temporal processes presents a fundamental dichotomy between the probabilistic rigor of classical geostatistics and the flexible, high-capacity representations of deep learning. While Gaussian processes offer theoretical consistency and exact uncertainty quantification, their prohibitive computational scaling renders them impractical for massive sensor networks. Conversely, modern transformer architectures excel at sequence modeling but inherently lack a geometric inductive bias, treating spatial sensors as permutation-invariant tokens without a native understanding of distance. In this work, we propose a spatially-informed transformer, a hybrid architecture that injects a geostatistical inductive bias directly into the self-attention mechanism via a learnable covariance kernel. By formally decomposing the attention structure into a stationary physical prior and a non-stationary data-driven residual, we impose a soft topological constraint that favors spatially proximal interactions while retaining the capacity to model complex dynamics. We demonstrate the phenomenon of ``Deep Variography'', where the network successfully recovers the true spatial decay parameters of the underlying process end-to-end via backpropagation. Extensive experiments on synthetic Gaussian random fields and real-world traffic benchmarks confirm that our method outperforms state-of-the-art graph neural networks. Furthermore, rigorous statistical validation confirms that the proposed method delivers not only superior predictive accuracy but also well-calibrated probabilistic forecasts, effectively bridging the gap between physics-aware modeling and data-driven learning.
toXiv_bot_toot
Einstein and Debye temperatures, electron-phonon coupling constant and a probable mechanism for ambient-pressure room-temperature superconductivity in intercalated graphite
E. F. Talantsev
https://arxiv.org/abs/2511.07460 https://arxiv.org/pdf/2511.07460 https://arxiv.org/html/2511.07460
arXiv:2511.07460v1 Announce Type: new
Abstract: Recently, Ksenofontov et al (arXiv:2510.03256) observed ambient pressure room-temperature superconductivity in graphite intercalated with lithium-based alloys with transition temperature (according to magnetization measurements) $T_c=330$ $K$. Here, I analyzed the reported temperature dependent resistivity data $\rho(T)$ in these graphite-intercalated samples and found that $\rho(T)$ is well described by the model of two series resistors, where each resistor is described as either an Einstein conductor or a Bloch-Gr\"uneisen conductor. Deduced Einstein and Debye temperatures are $\Theta_{E,1} \approx 250$ $K$ and $\Theta_{E,2} \approx 1,600$ $K$, and $\Theta_{D,1} \approx 300$ $K$ and $\Theta_{D,2} \approx 2,200$ $K$, respectively. Following the McMillan formalism, from the deduced $\Theta_{E,2}$ and $\Theta_{D,2}$, the electron-phonon coupling constant $\lambda_{e-ph} = 2.2 - 2.6$ was obtained. This value of $\lambda_{e-ph}$ is approximately equal to the value of $\lambda_{e-ph}$ in highly compressed superconducting hydrides. Based on this, I can propose that the observed room-temperature superconductivity in intercalated graphite is localized in nanoscale Sr-Ca-Li metallic flakes/particles, which adopt the phonon spectrum from the surrounding bulk graphite matrix, and as a result, conventional electron-phonon superconductivity arises in these nano-flakes/particles at room temperature. Experimental data reported by Ksenofontov et al (arXiv:2510.03256) on trapped magnetic flux decay in intercalated graphite samples supports the proposition.
toXiv_bot_toot
Determination of nuclear quadrupole moments of $^{25}$Mg, $^{87}$Sr, and $^{135,137}$Ba via configuration-interaction plus coupled-cluster approach
Yong-Bo Tang
https://arxiv.org/abs/2512.07603 https://arxiv.org/pdf/2512.07603 https://arxiv.org/html/2512.07603
arXiv:2512.07603v1 Announce Type: new
Abstract: Using the configuration-interaction plus coupled-cluster approach, we calculate the electric-field gradients $q$ for the low-lying states of alkaline-earth atoms, including magnesium (Mg), strontium (Sr), and barium (Ba). These low-lying states specifically include the $3s3p~^3\!P_{1,2}$ states of Mg; the $5s4d~^1\!D_{2}$ and $5s5p~^3\!P_{1,2}$ states of Sr; as well as the $6s5d~^3\!D_{1,2,3}$, $6s5d~^1\!D_{2}$, and $6s6p~^1\!P_{1}$ states of Ba. By combining the measured electric quadrupole hyperfine-structure constants of these states, we accurately determine the nuclear quadrupole moments of $^{25}$Mg, $^{87}$Sr, and $^{135,137}$Ba. These results are compared with the available data. The comparison shows that our nuclear quadrupole moment of $^{25}$Mg is in perfect agreement with the result from the mesonic X-ray experiment. However, there are approximately 10\% and 4\% differences between our results and the currently adopted values [Pyykk$\rm \ddot{o}$, Mol. Phys. 116, 1328(2018)] for the nuclear quadrupole moments of $^{87}$Sr and $^{135,137}$Ba respectively. Moreover, we also calculate the magnetic dipole hyperfine-structure constants of these states, and the calculated results exhibit good agreement with the measured data.
toXiv_bot_toot
Natural transformations between braiding functors in the Fukaya category
Yujin Tong
https://arxiv.org/abs/2511.10462 https://arxiv.org/pdf/2511.10462 https://arxiv.org/html/2511.10462
arXiv:2511.10462v1 Announce Type: new
Abstract: We study the space of $A_\infty$-natural transformations between braiding functors acting on the Fukaya category associated to the Coulomb branch $\mathcal{M}(\bullet,1)$ of the $\mathfrak{sl}_2$ quiver gauge theory. We compute all cohomologically distinct $A_\infty$-natural transformations $\mathrm{Nat}(\mathrm{id}, \mathrm{id})$ and $\mathrm{Nat}(\mathrm{id}, \beta_i^-)$, where $\beta_i^-$ denotes the negative braiding functor. Our computation is carried out in a diagrammatic framework compatible with the established embedding of the KLRW category into this Fukaya category. We then compute the Hochschild cohomology of the Fukaya category using an explicit projective resolution of the diagonal bimodule obtained via the Chouhy-Solotar reduction system, and use this to classify all cohomologically distinct natural transformations. These results determine the higher $A_\infty$-data encoded in the braiding functors and their natural transformations, and provide the first step toward a categorical formulation of braid cobordism actions on Fukaya categories.
toXiv_bot_toot
Measuring dissimilarity between convex cones by means of max-min angles
Welington de Oliveira, Valentina Sessa, David Sossa
https://arxiv.org/abs/2511.10483 https://arxiv.org/pdf/2511.10483 https://arxiv.org/html/2511.10483
arXiv:2511.10483v1 Announce Type: new
Abstract: This work introduces a novel dissimilarity measure between two convex cones, based on the max-min angle between them. We demonstrate that this measure is closely related to the Pompeiu-Hausdorff distance, a well-established metric for comparing compact sets. Furthermore, we examine cone configurations where the measure admits simplified or analytic forms. For the specific case of polyhedral cones, a nonconvex cutting-plane method is deployed to compute, at least approximately, the measure between them. Our approach builds on a tailored version of Kelley's cutting-plane algorithm, which involves solving a challenging master program per iteration. When this master program is solved locally, our method yields an angle that satisfies certain necessary optimality conditions of the underlying nonconvex optimization problem yielding the dissimilarity measure between the cones. As an application of the proposed mathematical and algorithmic framework, we address the image-set classification task under limited data conditions, a task that falls within the scope of the \emph{Few-Shot Learning} paradigm. In this context, image sets belonging to the same class are modeled as polyhedral cones, and our dissimilarity measure proves useful for understanding whether two image sets belong to the same class.
toXiv_bot_toot
Modeling, Segmenting and Statistics of Transient Spindles via Two-Dimensional Ornstein-Uhlenbeck Dynamics
C. Sun, D. Fettahoglu, D. Holcman
https://arxiv.org/abs/2512.10844 https://arxiv.org/pdf/2512.10844 https://arxiv.org/html/2512.10844
arXiv:2512.10844v1 Announce Type: new
Abstract: We develop here a stochastic framework for modeling and segmenting transient spindle- like oscillatory bursts in electroencephalogram (EEG) signals. At the modeling level, individ- ual spindles are represented as path realizations of a two-dimensional Ornstein{Uhlenbeck (OU) process with a stable focus, providing a low-dimensional stochastic dynamical sys- tem whose trajectories reproduce key morphological features of spindles, including their characteristic rise{decay amplitude envelopes. On the signal processing side, we propose a segmentation procedure based on Empirical Mode Decomposition (EMD) combined with the detection of a central extremum, which isolates single spindle events and yields a collection of oscillatory atoms. This construction enables a systematic statistical analysis of spindle features: we derive empirical laws for the distributions of amplitudes, inter-spindle intervals, and rise/decay durations, and show that these exhibit exponential tails consistent with the underlying OU dynamics. We further extend the model to a pair of weakly coupled OU processes with distinct natural frequencies, generating a stochastic mixture of slow, fast, and mixed spindles in random temporal order. The resulting framework provides a data- driven framework for the analysis of transient oscillations in EEG and, more generally, in nonstationary time series.
toXiv_bot_toot
Beyond Revenue and Welfare: Counterfactual Analysis of Spectrum Auctions with Application to Canada's 3800MHz Allocation
Sara Jalili Shani, Kris Joseph, Michael B. McNally, James R. Wright
https://arxiv.org/abs/2512.08106 https://arxiv.org/pdf/2512.08106 https://arxiv.org/html/2512.08106
arXiv:2512.08106v1 Announce Type: new
Abstract: Spectrum auctions are the primary mechanism through which governments allocate scarce radio frequencies, with outcomes that shape competition, coverage, and innovation in telecommunications markets. While traditional models of spectrum auctions often rely on strong equilibrium assumptions, we take a more parsimonious approach by modeling bidders as myopic and straightforward: in each round, firms simply demand the bundle that maximizes their utility given current prices. Despite its simplicity, this model proves effective in predicting the outcomes of Canada's 2023 auction of 3800 MHz spectrum licenses. Using detailed round-by-round bidding data, we estimate bidders' valuations through a linear programming framework and validate that our model reproduces key features of the observed allocation and price evolution. We then use these estimated valuations to simulate a counterfactual auction under an alternative mechanism that incentivizes deployment in rural and remote regions, aligning with one of the key objectives set out in the Canadian Telecommunications Act. The results show that the proposed mechanism substantially improves population coverage in underserved areas. These findings demonstrate that a behavioral model with minimal assumptions is sufficient to generate reliable counterfactual predictions, making it a practical tool for policymakers to evaluate how alternative auction designs may influence future outcomes. In particular, our study demonstrates a method for counterfactual mechanism design, providing a framework to evaluate how alternative auction rules could advance policy goals such as equitable deployment across Canada.
toXiv_bot_toot
Mitigating Forgetting in Low Rank Adaptation
Joanna Sliwa, Frank Schneider, Philipp Hennig, Jose Miguel Hernandez-Lobato
https://arxiv.org/abs/2512.17720 https://arxiv.org/pdf/2512.17720 https://arxiv.org/html/2512.17720
arXiv:2512.17720v1 Announce Type: new
Abstract: Parameter-efficient fine-tuning methods, such as Low-Rank Adaptation (LoRA), enable fast specialization of large pre-trained models to different downstream applications. However, this process often leads to catastrophic forgetting of the model's prior domain knowledge. We address this issue with LaLoRA, a weight-space regularization technique that applies a Laplace approximation to Low-Rank Adaptation. Our approach estimates the model's confidence in each parameter and constrains updates in high-curvature directions, preserving prior knowledge while enabling efficient target-domain learning. By applying the Laplace approximation only to the LoRA weights, the method remains lightweight. We evaluate LaLoRA by fine-tuning a Llama model for mathematical reasoning and demonstrate an improved learning-forgetting trade-off, which can be directly controlled via the method's regularization strength. We further explore different loss landscape curvature approximations for estimating parameter confidence, analyze the effect of the data used for the Laplace approximation, and study robustness across hyperparameters.
toXiv_bot_toot
One-clock synthesis problems
S{\l}awomir Lasota, Mathieu Lehaut, Julie Parreaux, Rados{\l}aw Pi\'orkowski
https://arxiv.org/abs/2601.04902 https://arxiv.org/pdf/2601.04902 https://arxiv.org/html/2601.04902
arXiv:2601.04902v1 Announce Type: new
Abstract: We study a generalisation of B\"uchi-Landweber games to the timed setting. The winning condition is specified by a non-deterministic timed automaton, and one of the players can elapse time. We perform a systematic study of synthesis problems in all variants of timed games, depending on which player's winning condition is specified, and which player's strategy (or controller, a finite-memory strategy) is sought. As our main result we prove ubiquitous undecidability in all the variants, both for strategy and controller synthesis, already for winning conditions specified by one-clock automata. This strengthens and generalises previously known undecidability results. We also fully characterise those cases where finite memory is sufficient to win, namely existence of a strategy implies existence of a controller. All our results are stated in the timed setting, while analogous results hold in the data setting where one-clock automata are replaced by one-register ones.
toXiv_bot_toot
Good Morning #Canada
Happy National Homemade Bread Day for all those with enough dough to celebrate. There's no data on how many of us make their own bread at home, but there are 1,321 bakery product manufacturing establishments and more than 1,406 retail bakeries in Canada. Canada annually ranks in the top 10 worldwide in wheat production, 6th or 7th, depending on the year, but we don't eat a lot of bread. #StatsCan says we consume approximately 30 kg per person yearly, which doesn't put us in the top 30 internationally - Turkey's citizens eat 6 times as much as us. We spend about 10% of our grocery bill on baked goods, and that has increased almost 30% over the past 5 years. Canada exports $5.2B in baked goods annually with $5B of that going to the U.S. market.
#CanadaIsAwesome #Sandwich
My favourite type of bread: Please boost for scientific significance.
Plain White (I leave my socks on too)
Bagels (Montreal preferred)
Sourdough (nothing to do with my personality)
French - loaf or baguette (I also support Bilingualism)
Italian - loaf, focaccia, calabrese (I'm also a pasta lover)
Easy Adaptation: An Efficient Task-Specific Knowledge Injection Method for Large Models in Resource-Constrained Environments
Dong Chen, Zhengqing Hu, Shixing Zhao, Yibo Guo
https://arxiv.org/abs/2512.17771 https://arxiv.org/pdf/2512.17771 https://arxiv.org/html/2512.17771
arXiv:2512.17771v1 Announce Type: new
Abstract: While the enormous parameter scale endows Large Models (LMs) with unparalleled performance, it also limits their adaptability across specific tasks. Parameter-Efficient Fine-Tuning (PEFT) has emerged as a critical approach for effectively adapting LMs to a diverse range of downstream tasks. However, existing PEFT methods face two primary challenges: (1) High resource cost. Although PEFT methods significantly reduce resource demands compared to full fine-tuning, it still requires substantial time and memory, making it impractical in resource-constrained environments. (2) Parameter dependency. PEFT methods heavily rely on updating a subset of parameters associated with LMs to incorporate task-specific knowledge. Yet, due to increasing competition in the LMs landscape, many companies have adopted closed-source policies for their leading models, offering access only via Application Programming Interface (APIs). Whereas, the expense is often cost-prohibitive and difficult to sustain, as the fine-tuning process of LMs is extremely slow. Even if small models perform far worse than LMs in general, they can achieve superior results on particular distributions while requiring only minimal resources. Motivated by this insight, we propose Easy Adaptation (EA), which designs Specific Small Models (SSMs) to complement the underfitted data distribution for LMs. Extensive experiments show that EA matches the performance of PEFT on diverse tasks without accessing LM parameters, and requires only minimal resources.
toXiv_bot_toot
State and Parameter Estimation for a Neural Model of Local Field Potentials
Daniele Avitabile, Gabriel J. Lord, Khadija Meddouni
https://arxiv.org/abs/2512.07842 https://arxiv.org/pdf/2512.07842 https://arxiv.org/html/2512.07842
arXiv:2512.07842v1 Announce Type: new
Abstract: The study of cortical dynamics during different states such as decision making, sleep and movement, is an important topic in Neuroscience. Modelling efforts aim to relate the neural rhythms present in cortical recordings to the underlying dynamics responsible for their emergence. We present an effort to characterize the neural activity from the cortex of a mouse during natural sleep, captured through local field potential measurements. Our approach relies on using a discretized Wilson--Cowan Amari neural field model for neural activity, along with a data assimilation method that allows the Bayesian joint estimation of the state and parameters. We demonstrate the feasibility of our approach on synthetic measurements before applying it to a dataset available in literature. Our findings suggest the potential of our approach to characterize the stimulus received by the cortex from other brain regions, while simultaneously inferring a state that aligns with the observed signal.
toXiv_bot_toot
Correlation of Rankings in Matching Markets
R\'emi Castera, Patrick Loiseau, Bary S. R. Pradelski
https://arxiv.org/abs/2512.05304 https://arxiv.org/pdf/2512.05304 https://arxiv.org/html/2512.05304
arXiv:2512.05304v1 Announce Type: new
Abstract: We study the role of correlation in matching markets, where multiple decision-makers simultaneously face selection problems from the same pool of candidates. We propose a model in which a candidate's priority scores across different decision-makers exhibit varying levels of correlation dependent on the candidate's sociodemographic group. Such differential correlation can arise in school choice due to the varying prevalence of selection criteria, in college admissions due to test-optional policies, or due to algorithmic monoculture, that is, when decision-makers rely on the same algorithms and data sets to evaluate candidates. We show that higher correlation for one of the groups generally improves the outcome for all groups, leading to higher efficiency. However, students from a given group are more likely to remain unmatched as their own correlation level increases. This implies that it is advantageous to belong to a low-correlation group. Finally, we extend the tie-breaking literature to multiple priority classes and intermediate levels of correlation. Overall, our results point to differential correlation as a previously overlooked systemic source of group inequalities in school, university, and job admissions.
toXiv_bot_toot
 @arXiv_physicsoptics_bot@mastoxiv.page
@arXiv_physicsoptics_bot@mastoxiv.page