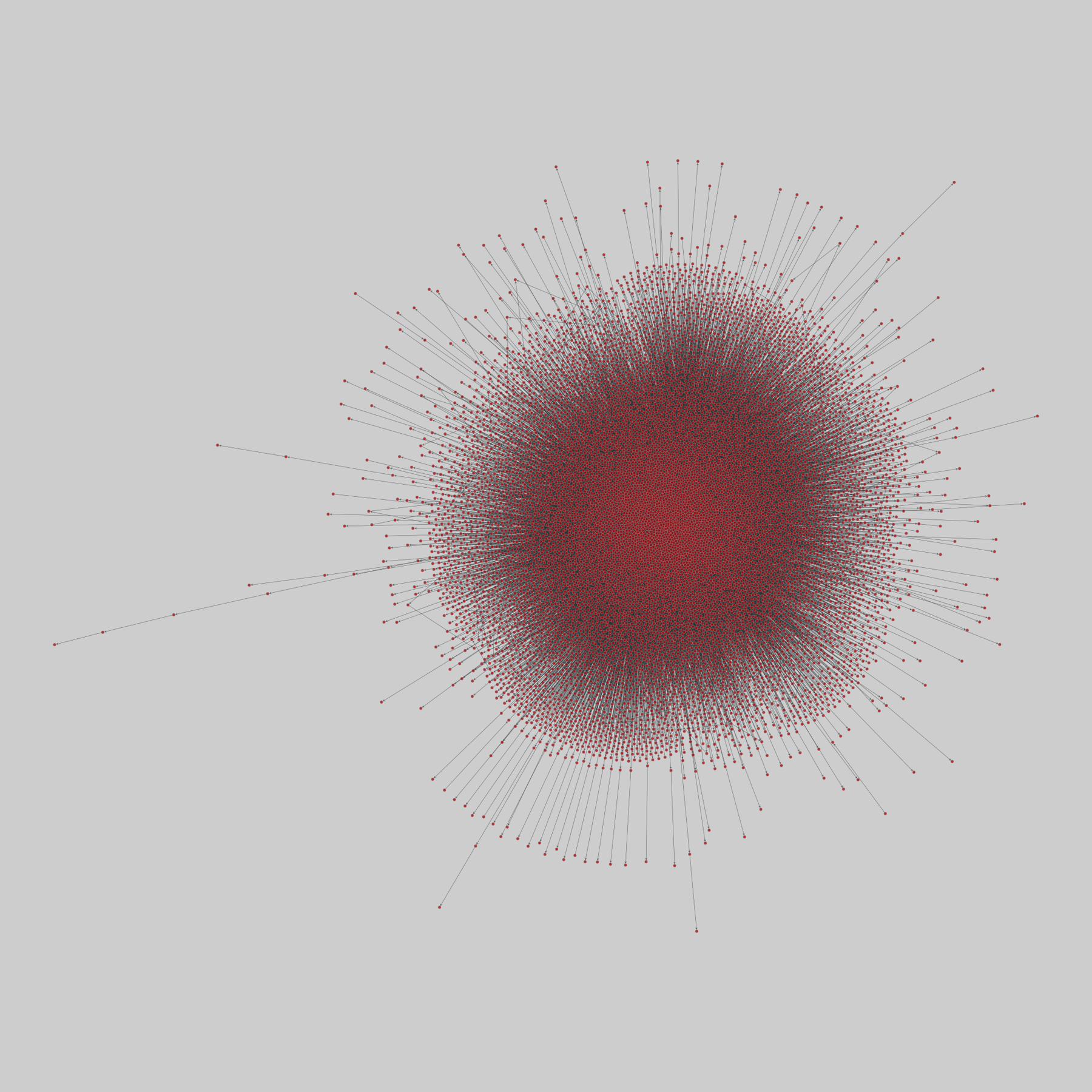
unicodelang: Languages spoken by country (2015)
A bipartite network of languages and the countries in which they are spoken, as estimated by Unicode. Edges are weighted by the proportion of the given country's population that is literate in a particular language.
This network has 868 nodes and 1255 edges.
Tags: Informational, Relatedness, Weighted
Neuroscientists Studied More Than 80,000 People and Found That Speaking Multiple Languages Might Slow Down Brain Aging
https://www.smithsonianmag.com/smart-news/neurosc…
"PHP is the lingua franca of affordable web hosting options; or, in other terms, the Toyota Corolla of programming languages: boring, solid, easy, and affordable. You can find, almost anywhere in the world, an affordable web hosting with the saint quadrinity of LAMP: Linux, Apache, MySQL, and PHP; an OS, a web server, a database server, and a scripting language, in an inexpensive package, enabling the masses to go further. Paraphrasing George Clooney, what else?"
Someone argued with me that using higher level programming languages is just like vibe-coding because "C has race conditions"
Some programming languages manage to absorb change, but withstand progress.
-- Epigrams in Programming, ACM SIGPLAN Sept. 1982
@… So many languages, so little time 🙁
@… So many languages, so little time 🙁
Wow, just noticed #ThingUmbrella reached 3700 stars on GitHub — I'm celebrating... 🤩🫠
Heartfelt thanks to all of you who've been helping along the way (in any shape & form) and been supporting this work for all these years and across different programming languages/camps! Merci beaucoup!!! Esp. big Thank You's to fellow fediverse people/supporters from various stages…
What the ~same message will have different lengths in different #languages:
English: a mint
German: eine Münzprägeanstalt
English: that goes without saying
Viennese: eh
There's a Ghidra pull request to add hd6303/6301 - this is looking much better for doing Epson HX-20 stuff;
Copy the Processors/MC6800/data/languages/*6303* into a standard Ghidra world and run 'ant' in the data directory, restart - and it works!
https://github.com/NationalSecurityA…
What’s really amazing about vibe-coding is how people are replacing programming languages which are strictly deterministic with human speech which is highly ambiguous and expect programming to be faster and better.
“Well only use it when you’re already an expert!”
None of the people starting their careers using this technology are experts yet, nor will the ever be.
And within some finite amount of time nether will you, the expert, be an expert anymore.
Isto é engraçado.
Aparentemente nós, os lusófonos, lemos a uma velocidade média de 181 palavras por minuto.
(mas é provšvel que quem lê regularmente tenha uma velocidade de leitura superior a isto... duvido que chegue Šs 200, mas provavelmente chegarš Šs 190)
https://irisreading.com/average…
unicodelang: Languages spoken by country (2015)
A bipartite network of languages and the countries in which they are spoken, as estimated by Unicode. Edges are weighted by the proportion of the given country's population that is literate in a particular language.
This network has 868 nodes and 1255 edges.
Tags: Informational, Relatedness, Weighted
International Conference on Globalisation in Languages, Education, Culture, and Communication(GLECC 2026) 28-30 July, 2026, Manchester, UK
https://ift.tt/TKHpszg
updated: Wednesday, November 19, 2025 - 3:08pmfull name / name of organization: GLECC Organising…
via Input 4 RELCFP
Amazon is testing an AI tool called Kindle Translate that automatically translates books into other languages, for authors that self-publish on the platform (Lawrence Bonk/Engadget)
https://www.engadget.com/ai/amazon-is-test
Proceedings Twentieth International Workshop on Logical Frameworks and Meta-Languages: Theory and Practice
Kaustuv Chaudhuri (Inria, France), Daniele Nantes-Sobrinho (Imperial College, UK)
https://arxiv.org/abs/2510.11199
These are three arguments for web dev serv. APIs, even if you have to take a critical look at them in detail:
»Speed Comparison: Benchmarking programming languages using the Leibniz formula for calculating π«
— 2025-12-12
📊 https://niklas-heer.github.io/speed-comparison/…
It has occurred to me that a lot of data processing/transformation which is entirely feasible without highly trained LLMs and neural nets and GPUs is being handed over to such monstrosities in part because no one wants to do the app design. Like the current scourge of web-scraper bots, which seem to be doing #NLG with ultra-simple languages constructed by examining working URLs. It's a large project…
First annoyance I've run into: standard bit shifting operations in Nim. It's not bad, but it took far too long to track down the right operator. In most languages, you're looking at the `>>` and `<<` operators, in Nim it's `shr` and `shl` which I totally wouldn't have guessed. However, got the initial register idea down.
```nim
type
Register = object
low: uint8 = 0
high: uint8 = 0
prime: uint16 = 0
proc swa…
"What color is your function?" is a wonderful title. It's so good, the title alone could win the Sundance Festival.
But that post is about a JavaScript-specific limitation (not applicable to other languages), and some wishful bikeshedding about syntax (which turns out to be a leaky abstraction that makes locking ambiguous, very problematic in low-level languages).
But *color* is so catchy. It's not well defined that post, but you can't have "color"…
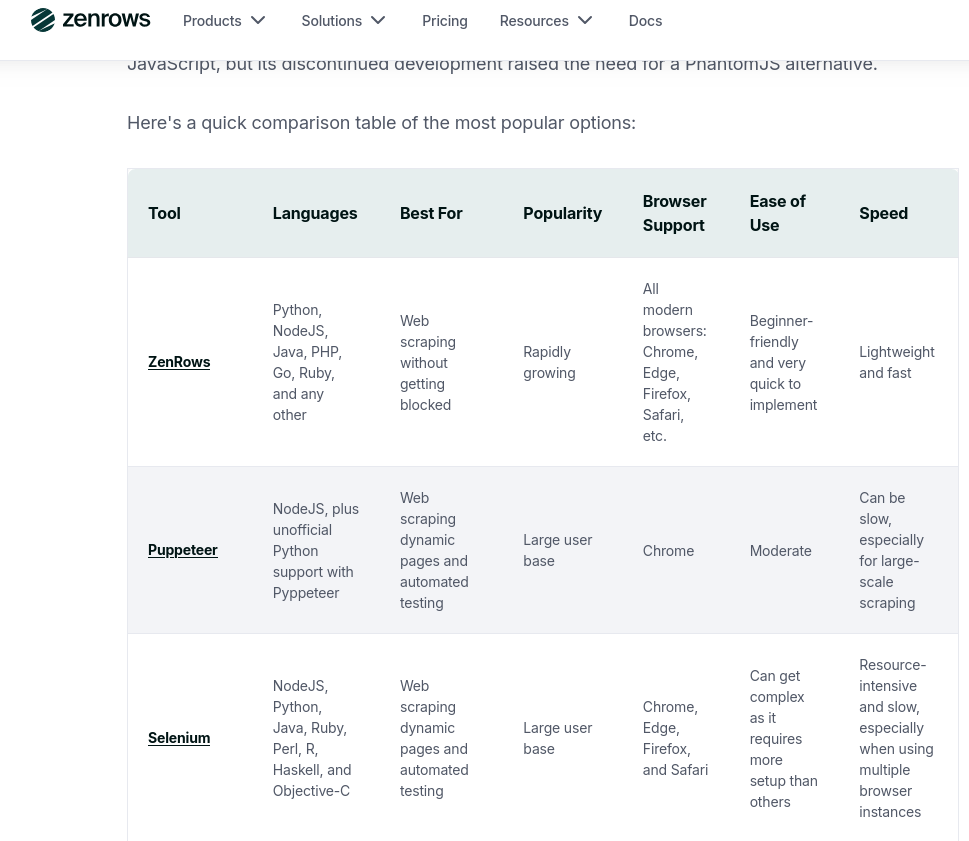
Looking for a phantomjs alternative, ran a search and ended up on a page with a seemingly good comparison of possibilities, until you realize the page is on zenrows.com domain. I don't think I'll take YOUR word for your product. Not sure what snakeoil they might be selling but feels overtly self-aggrandizing at least
unicodelang: Languages spoken by country (2015)
A bipartite network of languages and the countries in which they are spoken, as estimated by Unicode. Edges are weighted by the proportion of the given country's population that is literate in a particular language.
This network has 868 nodes and 1255 edges.
Tags: Informational, Relatedness, Weighted
Eyeballing Figure 1 of their response actually seems to support this: the three subregions in the Americas contain nearly 80 % of all polysynthetic languages. In each of them, the median population size lies below the global median. However, if we compare within each of these three regions, polysynthetic languages have a higher median L1_population size than non-polysynthetic ones. Might this pattern point towards a classic Simpson's paradox?
A negative global association arises because polysynth lang are concentrated in regions with smaller overall populations, even though within regions the relationsh is positive. Once we account for that structure—as our mixed logit models do—the supposed "global" negative effect reverses direction.
Oh good! Someone from the @… community can weigh in on the benefits.
Oh wait…
Anyway, sooner or later the time for computable reals will come. I'm still HODLing stock in continued fractions (and teaching them every year to my first-year students).
Which Word Orders Facilitate Length Generalization in LMs? An Investigation with GCG-Based Artificial Languages
Nadine El-Naggar, Tatsuki Kuribayashi, Ted Briscoe
https://arxiv.org/abs/2510.12722
How inaccurate AI translations of Wikipedia pages, which AI models use for training, may cause a doom spiral that further marginalizes vulnerable languages (Jacob Judah/MIT Technology Review)
https://www.technologyreview.com/2025/09/25/11240…
@… Regarding quotes, I'd add that in Germany and Austria, guillemets are an alternative to „…“ and are used like this: »…«
In Switzerland, only «…» are used for all national languages, but they are only spaced in French.
@… Regarding quotes, I'd add that in Germany and Austria, guillemets are an alternative to „…“ and are used like this: »…«
In Switzerland, only «…» are used for all national languages, but they are only spaced in French.
"Like herding cats" in the English world (and may be elsewhere).
"Like weighing frogs" in Kannada (and may be other languages in India).
#saying #English #Kannada #India #impossibleThings #coordination
Mixing languages can be confusing
#linguistics #languages #language
In #OOP, objects collaborate. The initial idea of collaboration, first found in Smalltalk, was for object A to send a message to object B. Languages designed later use method calling. In both cases, the same question stands: how does an object reference other objects to reach the desired results?
In this post, I tackle the problem of passing
@… on stage: Type Universes as Kripke Worlds
Paulette Koronkevich, William J. Bowman @… https://
"Speak proper English!" is one of the silliest things one could say.
Proper *English*? Of all languages? Come on.
Replaced article(s) found for cs.PL. https://arxiv.org/list/cs.PL/new
[1/1]:
- Incremental Computation: What Is the Essence?
Yanhong A. Liu
https://
unicodelang: Languages spoken by country (2015)
A bipartite network of languages and the countries in which they are spoken, as estimated by Unicode. Edges are weighted by the proportion of the given country's population that is literate in a particular language.
This network has 868 nodes and 1255 edges.
Tags: Informational, Relatedness, Weighted
Out now in PNAS: Statistical errors undermine claims about the evolution of #polysynthetic #languages by Alex Koplenig and me: #linguistics 🧶 coming up...


Both Quikscript and Shavian were essentially the results of a design competition,
sponsored--posthumously--by playwright George Bernard Shaw,
who laid out the terms in his will.
Shaw wanted someone to create an ideal phonetic alphabet for English that trumped Pitman shorthand.
British designer Ronald Kingsley Read, a finalist in the 1960s competition, designed both Quikscript and Shavian, the latter being named in Shaw's honor
A Comprehensive Evaluation of Multilingual Chain-of-Thought Reasoning: Performance, Consistency, and Faithfulness Across Languages
Raoyuan Zhao, Yihong Liu, Hinrich Sch\"utze, Michael A. Hedderich
https://arxiv.org/abs/2510.09555
Replaced article(s) found for cs.FL. https://arxiv.org/list/cs.FL/new
[1/1]:
- Can ChatGPT support software verification?
Christian Jan{\ss}en, Cedric Richter, Heike Wehrheim
Crosslisted article(s) found for cs.PL. https://arxiv.org/list/cs.PL/new
[1/1]:
- Tensor Logic: The Language of AI
Pedro Domingos
https://ar…
Google expands Google Translate's live speech translation from Pixel Buds to any headphones, supporting 70 languages, in beta on compatible Android phones (Stevie Bonifield/The Verge)
https://www.theverge.com/news/843483/google-translate-live-sp…
»Introduction to CSS if() Statements and Conditional Logic«
CSS will probably become logically structurable after a long time. It's not a programming language and that's why it's all the more exciting.
🖌️ https://markodenic.com/introduction-to
Finally, what Xia & Lindell call a "separation problem" is, in our view, a feature of our approach and not a bug.
If, e.g., all languages in a family are polysynthetic (or none are), that’s not a statistical artefact – it’s the signal. The outcome is well associated with genealogy, showing that family membership captures someth genuinely informative about the process. When the model finds that family explains a large share of the variance, that's not a failure–it's evidence that phylogenetic structure dominates the pattern.
So while Xia & Lindell insist that "autocorrelation due to relationships and distance cannot be captured in family or regional-level analyses", we see that as an empirical question – and we treated it as one.
The real test is whether a mixed model that explicitly represents phylogeny and geography performs worse than their alternative, where the entire shared history of languages and environments is effectively collapsed into a single dimension (an eigenvector).
In other words: we model relationships – Xia & Lindell summarise them into one number per language.
unicodelang: Languages spoken by country (2015)
A bipartite network of languages and the countries in which they are spoken, as estimated by Unicode. Edges are weighted by the proportion of the given country's population that is literate in a particular language.
This network has 868 nodes and 1255 edges.
Tags: Informational, Relatedness, Weighted
Crosslisted article(s) found for cs.FL. https://arxiv.org/list/cs.FL/new
[1/1]:
- Flavors of Quantifiers in Hyperlogics
Marek Chalupa, Thomas A. Henzinger, Ana Oliveira da Costa
from my link log —
Control structures in programming languages: from goto to algebraic effects.
http://xavierleroy.org/control-structures/
saved 2025-11-03
Tracing Multilingual Knowledge Acquisition Dynamics in Domain Adaptation: A Case Study of English-Japanese Biomedical Adaptation
Xin Zhao, Naoki Yoshinaga, Yuma Tsuta, Akiko Aizawa
https://arxiv.org/abs/2510.12115
Researchers find OpenAI's o1 can analyze languages like a human expert, including inferring the phonological rules of made-up languages without prior knowledge (Steve Nadis/Quanta Magazine)
https://www.quantamagazine.org/in-a-first-
unicodelang: Languages spoken by country (2015)
A bipartite network of languages and the countries in which they are spoken, as estimated by Unicode. Edges are weighted by the proportion of the given country's population that is literate in a particular language.
This network has 868 nodes and 1255 edges.
Tags: Informational, Relatedness, Weighted
DarTwin made precise by SysMLv2 -- An Experiment
{\O}ystein Haugen, Stefan Klikovits, Martin Arthur Andersen, Jonathan Beaulieu, Francis Bordeleau, Joachim Denil, Joost Mertens
https://arxiv.org/abs/2510.12478
[2025-10-15 Wed (UTC), 5 new articles found for cs.PL Programming Languages]
toXiv_bot_toot
unicodelang: Languages spoken by country (2015)
A bipartite network of languages and the countries in which they are spoken, as estimated by Unicode. Edges are weighted by the proportion of the given country's population that is literate in a particular language.
This network has 868 nodes and 1255 edges.
Tags: Informational, Relatedness, Weighted
Revisiting Metric Reliability for Fine-grained Evaluation of Machine Translation and Summarization in Indian Languages
Amir Hossein Yari, Kalmit Kulkarni, Ahmad Raza Khan, Fajri Koto
https://arxiv.org/abs/2510.07061
Replaced article(s) found for cs.FL. https://arxiv.org/list/cs.FL/new
[1/1]:
- Mathematical Approach in Automata and Automata Association
Sergio Henrique Maciel
h…
Samsung rolls out its Vision AI Companion, a generative AI-powered upgrade to its Bixby assistant, across its 2025 TV lineup, with support for 10 languages (Dominic Preston/The Verge)
https://www.theverge.com/news/818355/samsung-tvs-bixby-generative-ai-con…
Crosslisted article(s) found for cs.FL. https://arxiv.org/list/cs.FL/new
[1/1]:
- Abstract String Domain Defined with Word Equations as a Reduced Product (Extended Version)
Antonina Nepeivoda, Ilya Afanasyev
Meta introduces Omnilingual Automatic Speech Recognition, a suite of AI models providing automatic speech recognition capabilities for more than 1,600 languages (Carl Franzen/VentureBeat)
https://venturebeat.com/ai/meta-returns-to-open-source-ai…
Automatic Speech Recognition (ASR) for African Low-Resource Languages: A Systematic Literature Review
Sukairaj Hafiz Imam, Tadesse Destaw Belay, Kedir Yassin Husse, Ibrahim Said Ahmad, Idris Abdulmumin, Hadiza Ali Umar, Muhammad Yahuza Bello, Joyce Nakatumba-Nabende, Seid Muhie Yimam, Shamsuddeen Hassan Muhammad
https://arxiv.org/abs/2510.…
Languages of Words of Low Automatic Complexity Are Hard to Compute
Joey Chen, Bj{\o}rn Kjos-Hanssen, Ivan Koswara, Linus Richter, Frank Stephan
https://arxiv.org/abs/2510.07696 …
Pragyaan: Designing and Curating High-Quality Cultural Post-Training Datasets for Indian Languages
Neel Prabhanjan Rachamalla, Aravind Konakalla, Gautam Rajeev, Ashish Kulkarni, Chandra Khatri, Shubham Agarwal
https://arxiv.org/abs/2510.07000
unicodelang: Languages spoken by country (2015)
A bipartite network of languages and the countries in which they are spoken, as estimated by Unicode. Edges are weighted by the proportion of the given country's population that is literate in a particular language.
This network has 868 nodes and 1255 edges.
Tags: Informational, Relatedness, Weighted
[2025-10-15 Wed (UTC), 1 new article found for cs.FL Formal Languages and Automata Theory]
toXiv_bot_toot
word_adjacency: Word Adjacency Networks
Directed Networks of word adjacency in texts of several languages including English, French, Spanish and Japanese.
This network has 11586 nodes and 45129 edges.
Tags: Informational, Language, Unweighted
https://networks.skewed.de/net/word_ad
Replaced article(s) found for cs.FL. https://arxiv.org/list/cs.FL/new
[1/1]:
- Parameterized Verification of Timed Networks with Clock Invariants
\'Etienne Andr\'e, Swen Jacobs, Shyam Lal Karra, Ocan Sankur
wikipedia_link: Wikipedia links (2016)
Networks of hyperlinks among articles on Wikipedia, for all available languages. A directed edge (i,j) indicates that article i hyperlinks to j.
This network has 25250 nodes and 698864 edges.
Tags: Informational, Web graph, Unweighted
https://networks.skewed.de/net…
Crosslisted article(s) found for cs.FL. https://arxiv.org/list/cs.FL/new
[1/1]:
- Psi-Turing Machines: Bounded Introspection for Complexity Barriers and Oracle Separations
Rafig Huseynzade
unicodelang: Languages spoken by country (2015)
A bipartite network of languages and the countries in which they are spoken, as estimated by Unicode. Edges are weighted by the proportion of the given country's population that is literate in a particular language.
This network has 868 nodes and 1255 edges.
Tags: Informational, Relatedness, Weighted
Resource-sensitive but language-blind: Community size and not grammatical complexity better predicts the accuracy of Large Language Models in a novel Wug Test
Nikoleta Pantelidou, Evelina Leivada, Paolo Morosi
https://arxiv.org/abs/2510.12463
wikipedia_link: Wikipedia links (2016)
Networks of hyperlinks among articles on Wikipedia, for all available languages. A directed edge (i,j) indicates that article i hyperlinks to j.
This network has 9189 nodes and 176051 edges.
Tags: Informational, Web graph, Unweighted
https://networks.skewed.de/net…
The role of synthetic data in Multilingual, Multi-cultural AI systems: Lessons from Indic Languages
Pranjal A. Chitale, Varun Gumma, Sanchit Ahuja, Prashant Kodali, Manan Uppadhyay, Deepthi Sudharsan, Sunayana Sitaram
https://arxiv.org/abs/2509.21294
unicodelang: Languages spoken by country (2015)
A bipartite network of languages and the countries in which they are spoken, as estimated by Unicode. Edges are weighted by the proportion of the given country's population that is literate in a particular language.
This network has 868 nodes and 1255 edges.
Tags: Informational, Relatedness, Weighted
MENLO: From Preferences to Proficiency - Evaluating and Modeling Native-like Quality Across 47 Languages
Chenxi Whitehouse, Sebastian Ruder, Tony Lin, Oksana Kurylo, Haruka Takagi, Janice Lam, Nicol\`o Busetto, Denise Diaz
https://arxiv.org/abs/2509.26601
CorIL: Towards Enriching Indian Language to Indian Language Parallel Corpora and Machine Translation Systems
Soham Bhattacharjee, Mukund K Roy, Yathish Poojary, Bhargav Dave, Mihir Raj, Vandan Mujadia, Baban Gain, Pruthwik Mishra, Arafat Ahsan, Parameswari Krishnamurthy, Ashwath Rao, Gurpreet Singh Josan, Preeti Dubey, Aadil Amin Kak, Anna Rao Kulkarni, Narendra VG, Sunita Arora, Rakesh Balbantray, Prasenjit Majumdar, Karunesh K Arora, Asif Ekbal, Dipti Mishra Sharma
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.de