@fanf@mendeddrum.org
@fanf@mendeddrum.org2026-06-25 11:42:01
from my link log —
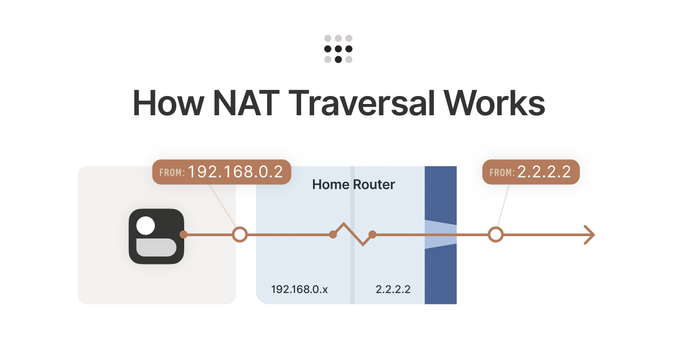
How NAT traversal works.
https://tailscale.com/blog/how-nat-traversal-works/
saved 2020-08-21 https://dot…
@fanf@mendeddrum.orgfrom my link log —
How NAT traversal works.
https://tailscale.com/blog/how-nat-traversal-works/
saved 2020-08-21 https://dot…
@fanf@mendeddrum.orgRE: https://mastodon.social/@appassionato/116635660928832452
this core flow change is interesting but it doesn’t correspond to any significant change in LoD
it happened about 10 years before the LoD abruptly dropped in about 2020
(and ther…
 @cdarwin@c.im
@cdarwin@c.imDemocrats and voting rights groups say Donald Trump’s primetime speech
making unverified claims of Chinese interference in the 2020 election
is the clearest sign yet that the president is laying the groundwork to tamper with the results of November’s midterms.
The upcoming elections to decide the balance of power in Congress and many state legislatures
will be a major test of Trump’s appeal to voters two years after he resoundingly beat the Democratic candidate Kamala…
 @scott@carfree.city
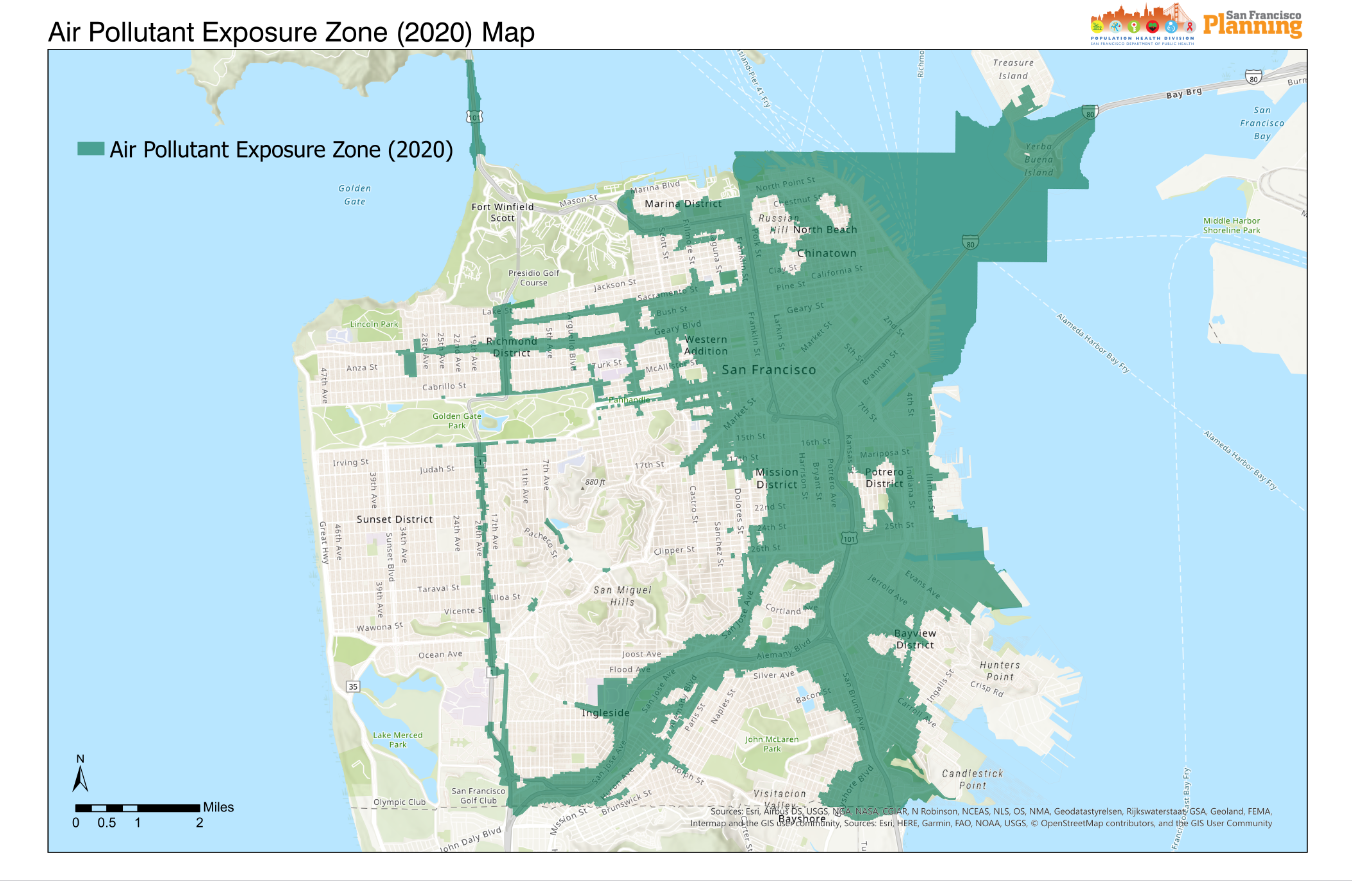
@scott@carfree.cityI live in a part of San Francisco called the APE Zone.
 @theodric@social.linux.pizza
@theodric@social.linux.pizza @datascience@genomic.social
@datascience@genomic.social{testthat} is great for automatic testing. Here are some tricks for the heavy user: #rstats
 @outer@mas.to
@outer@mas.to[Bill/David Carradine:]
What Kent wears, the glasses, the business suit... that's the costume that Superman wears to blend in with us. Clark Kent is how Superman views us. And what are the characteristics of Clark Kent? He's weak, he's unsure of himself, he's a coward. Clark Kent is Superman's critique on the whole human race.
--Kill Bill: Vol. 2 (2004). Screenplay by Quentin Tarantino.
(From "The New Yale Book of Quotations”, Fred R. Shapiro, 2020)
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.depsi: Plant Photosystem I excitation energy transfer network (2020)
Weighted directed network of the light-harvesting Photosystem Ι (PSI) of the plant Pisum sativum. The nodes represent chromophores with different identities (i.e. chlorophyll a, chlorophyll b, β-carotene and derivates, lutein, violaxanthin), while edges represent FRET transfer between chromophores. The link directionality connecting nodes in the PSI network depends on the energy levels of the connected chromophores. The…
 @cdarwin@c.im
@cdarwin@c.imBetween 2020 and 2024, no cervical cancer deaths were recorded in women aged 20 to 24
- the first time that had happened over a five-year period.
Without vaccination, around 23 deaths would have been expected.
"It's incredible to think that a single jab can almost eliminate a particular type of cancer,"
said Prof Peter Sasieni, the lead researcher at Queen Mary University of London.
 @tinoeberl@mastodon.online
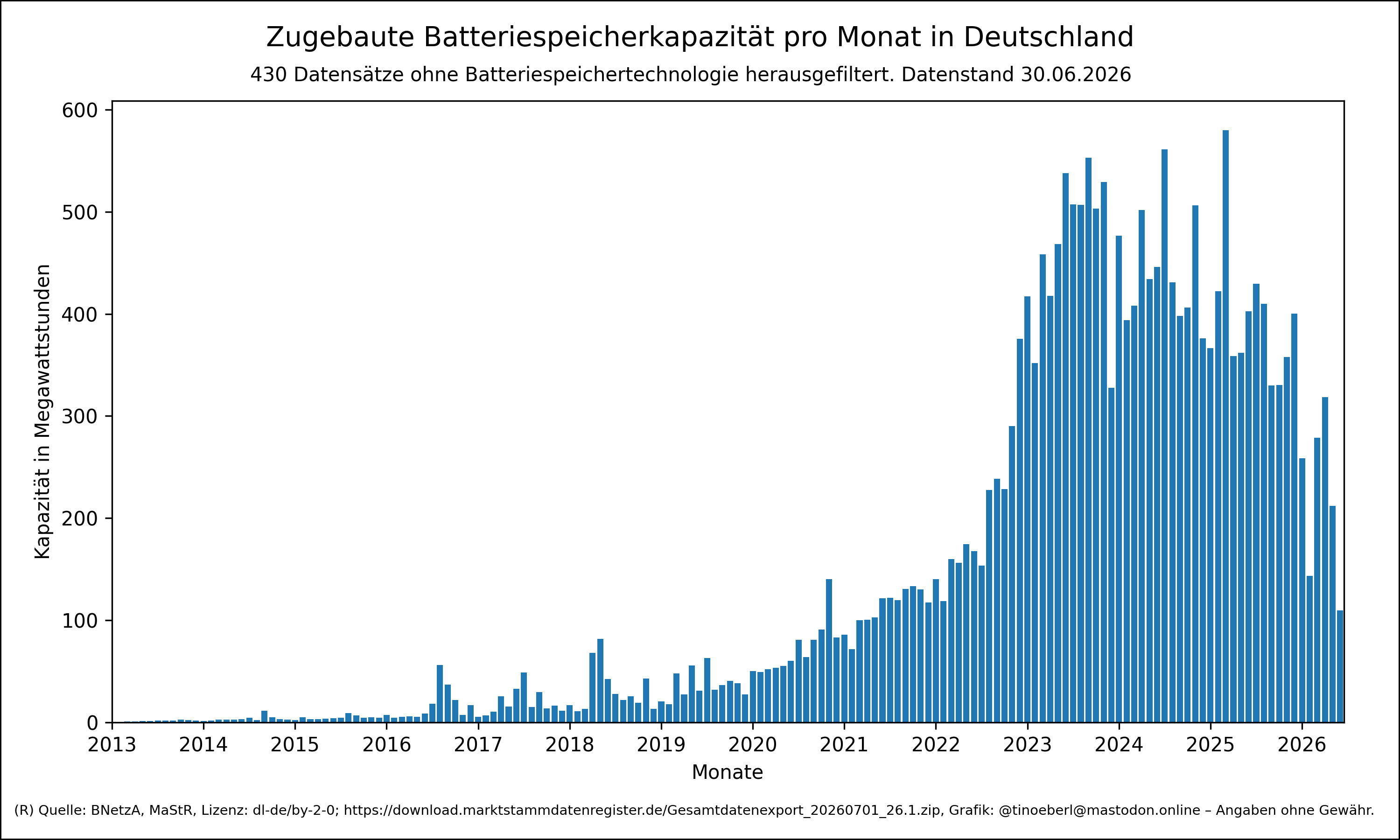
@tinoeberl@mastodon.onlineZugebaute #Batteriespeicherkapazität pro Monat in #Deutschland mit Stand vom 30.06.2026.
430 Datensätze ohne #Batteriespeichertechnologie herausgefil…
 @fanf@mendeddrum.org
@fanf@mendeddrum.orgfrom my link log —
Files are fraught with peril.
https://danluu.com/deconstruct-files/
saved 2020-01-06 https://dotat.at/:/2FDEV.html
 @roelgrif@mstdn.social
@roelgrif@mstdn.socialDraadje met vragen die m.i. aan Van Dissel gesteld hadden moeten worden vandaag bij de #pec.
Heeft het RIVM onjuiste of gebrekkige dan wel misleidende informatie verstrekt aan het publiek in februari en maart 2020?
1/n
@cdarwin@c.imGovernor Josh Shapiro here.
Take it from the guy who took Donald Trump and his allies to court 43 times after the 2020 election
- and won 43 times:
Trump can say whatever he wants.
He can sign his name to anything he wants.
He doesn't control our elections.
𝗛𝗲 𝗱𝗼𝗲𝘀𝗻'𝘁 𝗰𝗼𝗻𝘁𝗿𝗼𝗹 𝗼𝘂𝗿 𝗱𝗲𝗺𝗼𝗰𝗿𝗮𝗰𝘆.
Here's the problem:
Right now, the Governor's office is the very last line of defense against a far-right takeover of the most important b…
@fanf@mendeddrum.orgfrom my link log —
How io_uring and eBPF will revolutionize programming in Linux.
https://www.scylladb.com/2020/05/05/how-io_uring-and-ebpf-will-revolutionize-programming-in-linux/
saved 2020-11-26
@fanf@mendeddrum.orgfrom my link log —
What made the 1960s CDC6600 supercomputer fast?
https://cpldcpu.wordpress.com/2020/02/14/what-made-the-cdc6600-fast/
saved 2020-02-15 …
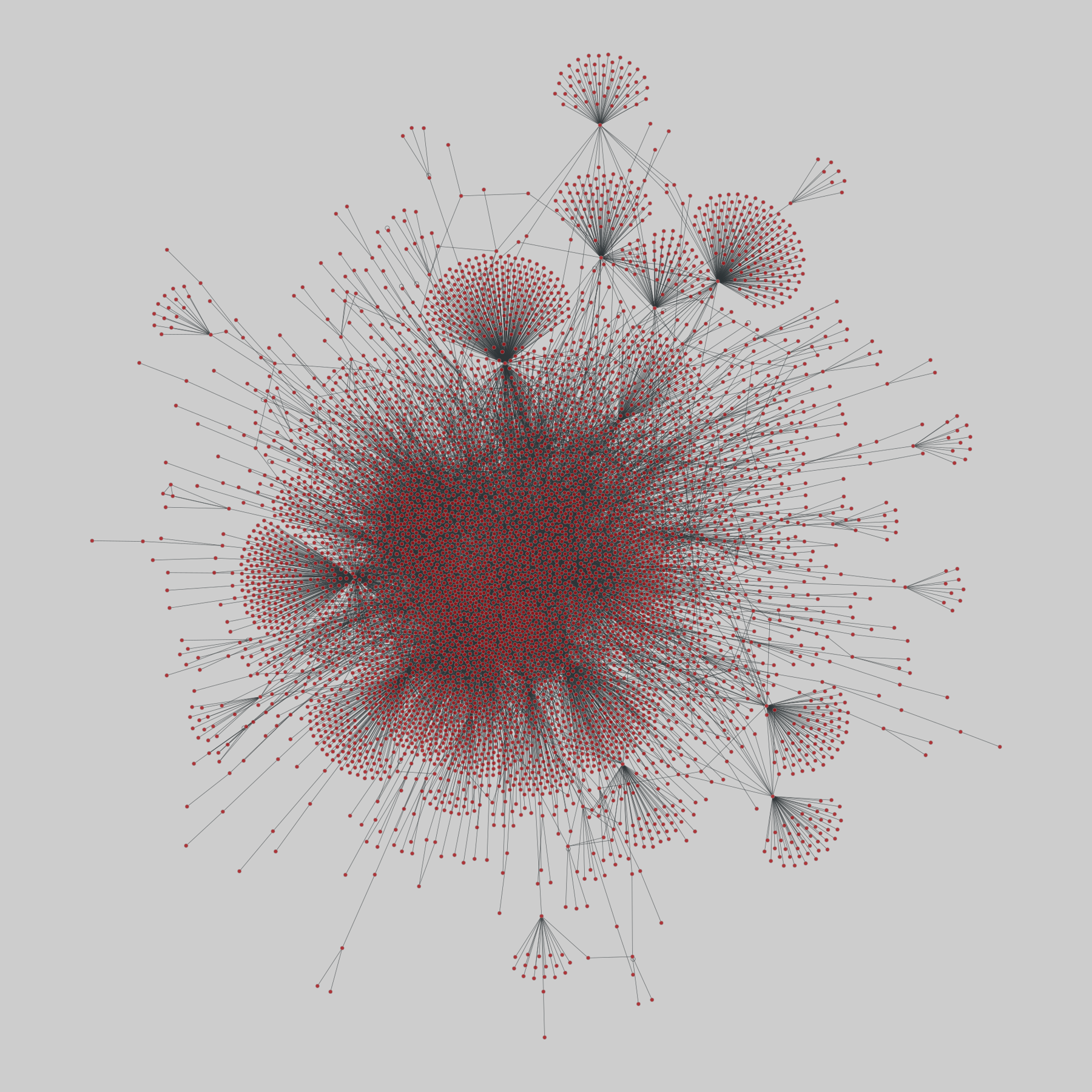
@netzschleuder@social.skewed.demist: MIST protein interaction database (2020)
The Molecular Interaction Search Tool (MIST) is a comprehensive resource of molecular interactions, assembled from severla primary sources. MIST currently supports several species, including:.
This network has 7050 nodes and 14969 edges.
Tags: Biological, Protein interactions, Unweighted
htt…
 @fanf@mendeddrum.org
@fanf@mendeddrum.orgfrom my link log —
Examining ARM vs x86 memory models with Rust.
https://www.nickwilcox.com/blog/arm_vs_x86_memory_model/
saved 2020-06-27 ht…
@fanf@mendeddrum.orgfrom my link log —
Write tracking for Nim.
https://nim-lang.org/blog/2020/09/01/write-tracking.html
saved 2020-09-02 https://
@fanf@mendeddrum.orgfrom my link log —
Lezer: a parser system in JavaScript.
https://lezer.codemirror.net/
saved 2020-10-21 https://dotat.at/:/VL4WJ.html
@fanf@mendeddrum.orgfrom my link log —
GNU Recutils: a database management system using human-readable text files.
https://labs.tomasino.org/gnu-recutils/
saved 2020-01-26 https://
@fanf@mendeddrum.orgfrom my link log —
New features in gnuplot 5.4.
https://lwn.net/SubscriberLink/826456/2ea90dd464e104d5/
saved 2020-07-23 https://
@fanf@mendeddrum.orgfrom my link log —
MLIR: a compiler infrastructure for the end of Moore's Law.
https://arxiv.org/abs/2002.11054
saved 2020-02-27 https://dotat.at/:…
@fanf@mendeddrum.orgfrom my link log —
What is the Scudo hardened allocator? (used by LLVM sanitizers and Android)
http://expertmiami.blogspot.com/2019/05/what-is-scudo-hardened-allocator_10.html
saved 2020-07-01
@fanf@mendeddrum.orgfrom my link log —
Packaging a Rust project for Debian.
https://blog.hackeriet.no/packaging-a-rust-project-for-debian/
saved 2020-02-01
@fanf@mendeddrum.orgfrom my link log —
Journeying into XDP implementing DNS RRL.
https://labs.ripe.net/Members/tom_carpay/journeying-into-xdp-part-1-augmenting-dns
saved 2020-10-23
@fanf@mendeddrum.orgfrom my link log —
T1: a programming language for constrained environments, derived from BearSSL.
https://t1lang.github.io/
saved 2020-01-11 https://dotat.at/…