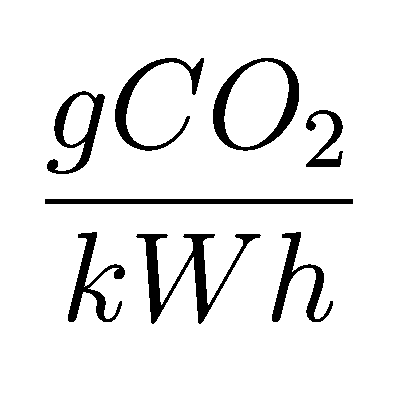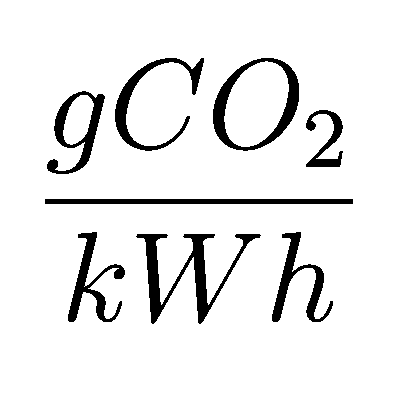@FandaSin@social.linux.pizza
@FandaSin@social.linux.pizza2026-02-06 08:15:54
@…
Good moning.👋
Friday is here!😊
@FandaSin@social.linux.pizza@…
Good moning.👋
Friday is here!😊
 @hllizi@hespere.de
@hllizi@hespere.deKompromißorientierte politische Systeme stellen vermutlich eine echte Hürde für große politische Entwürfe dar, in denen bestimmte Folgen einer Maßnahme durch andere Maßnahmen, möglicherweise in ganz anderen Ressorts, aufgegangen werden sollen, um eine gute Entwicklung im Ganzen zu erzielen. Stattdessen gibt es dann manche Maßnahmen und andere fallen dem Kompromiß zum Opfer, sodaß die Folgen der ersteren unkontrolliert herumwuchern.
 @ellie@ellieayla.net
@ellie@ellieayla.net18006. Heckin wow.
#pwhl
 @rigo@mamot.fr
@rigo@mamot.frNomination des Directeurs de l’audiovisuel par le président, c’est exactement ce que la loi fondamentale allemande de 1949 a interdit. Et pour cause. Comment M. Alloncle peut-on être aussi mauvais en histoire. Ou c’est voulu pour tuer la démocratie ?
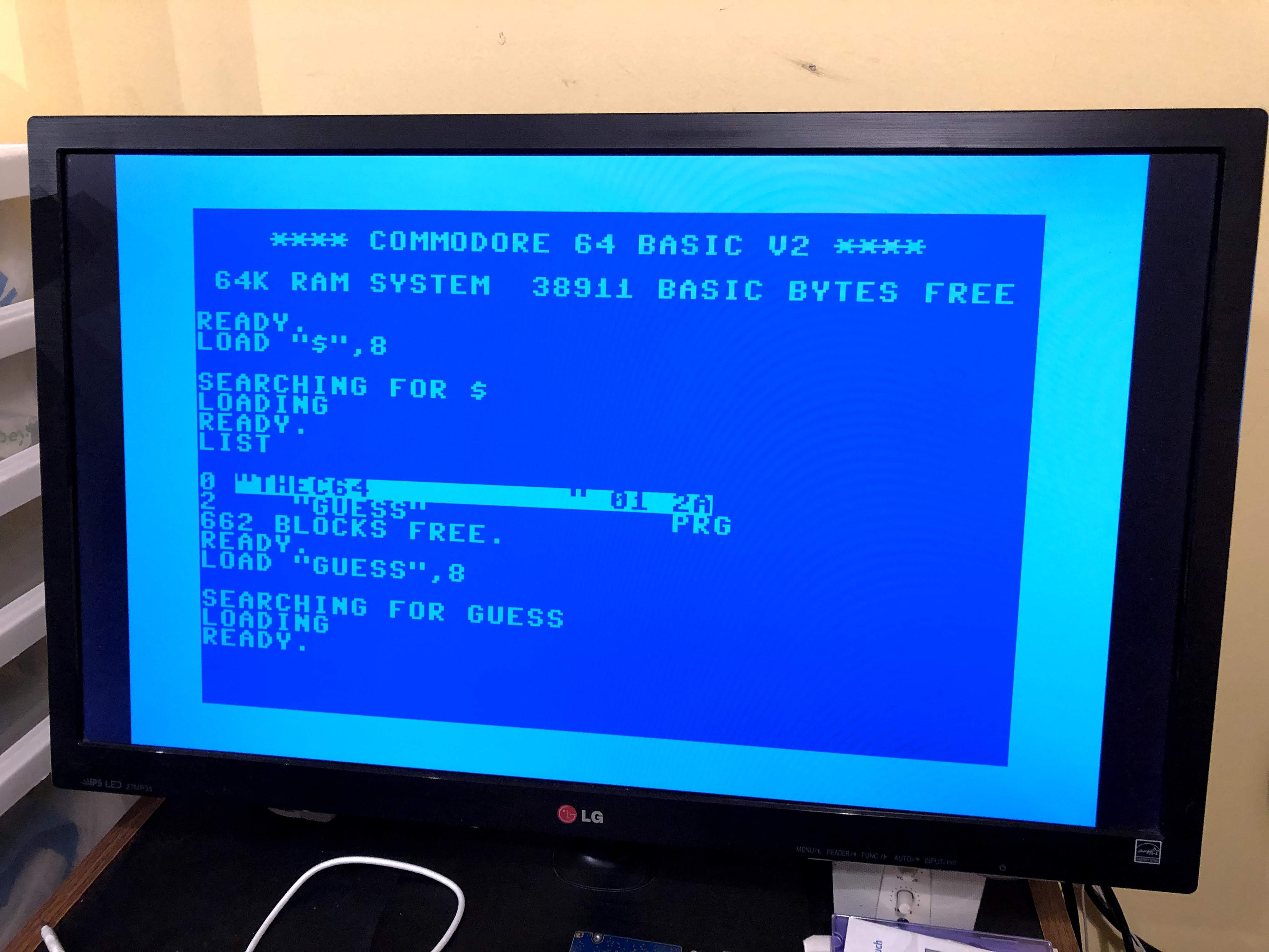
@FandaSin@social.linux.pizzaWonna feel old?
I.T. Crowd is 20 years old!🥳
 @hllizi@hespere.de
@hllizi@hespere.deTrump's whole presidency spells "I want to be couped away and court martialed" in 30 feet letters.
@ellie@ellieayla.netEven with everything going on, we still need people to collect seeds, and to plant them. Even if that's all we can do. That's still a thing we can do.
 @malik@Mastodon.Social
@malik@Mastodon.SocialFrau Reiche, AUFWACHEN.

 @markhburton@mstdn.social
@markhburton@mstdn.socialCurrent non-fiction reading.
Well I like a challenge.
Shaikh's achievement is very impressive.

 @adlerweb@social.adlerweb.info
@adlerweb@social.adlerweb.infoDie Lötkurse hier auf der #eh23 sind auch außerhalb des SEC top.
 @hllizi@hespere.de
@hllizi@hespere.deErklär's dem Deutschen mit ner Autometapher.
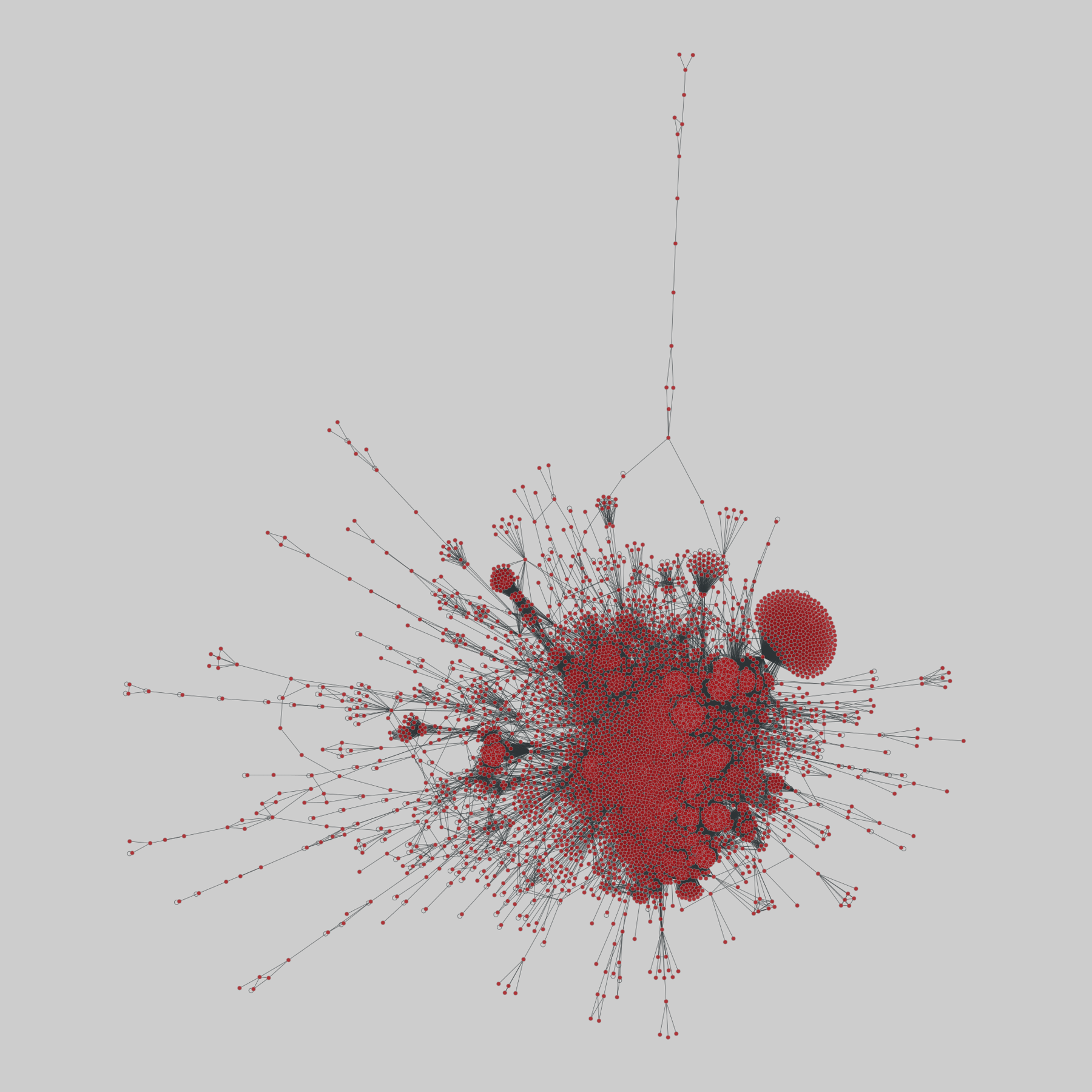
 @netzschleuder@social.skewed.de
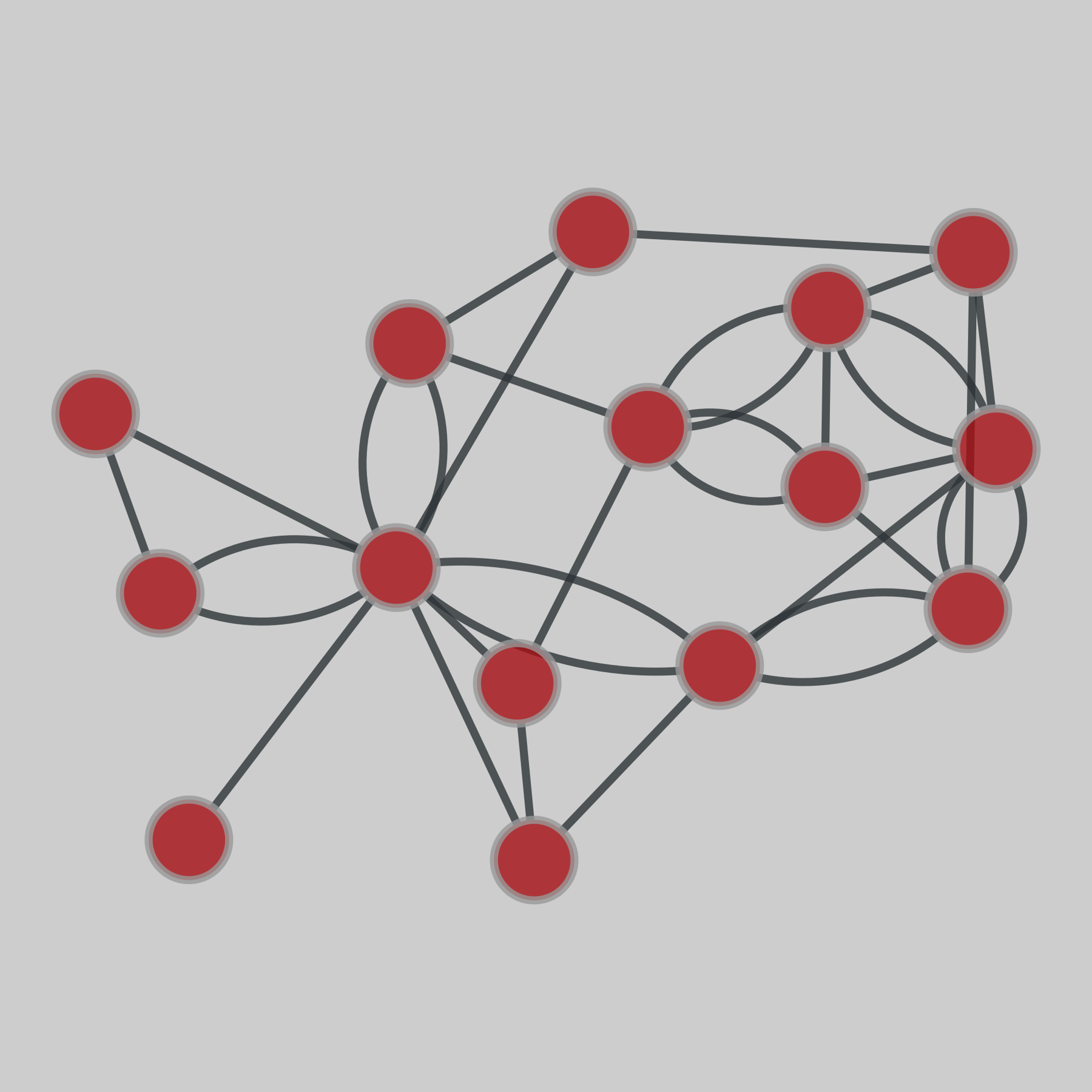
@netzschleuder@social.skewed.deflorentine_families: Padgett Florentine families
Multiplex network with 2 edge types representing marriage alliances and business relationships between Florentine families during the Italian Renaissance. Data hosted by Manlio De Domenico.
This network has 16 nodes and 35 edges.
Tags: Social, Relationships, Multilayer, Unweighted
…
 @adrianco@mastodon.social
@adrianco@mastodon.socialWe had a lovely #CarsAndCoffee at #Seaside near #Monterey this morning. I forgot to take pictures other than one of a Mini but my friend took this Jaguar F-Type V8S and I went in the Lotus Elise …


 @hllizi@hespere.de
@hllizi@hespere.de"Ich mein', der Kanzler hat auch deutlich gesagt, daß er gegen Gewalt ist" meinte die Justizministerin im TV, als sie gefragt wurde, ob sie seine Äußerungen deplatziert fand.
Sorry, aber es ist schon auch einfach saulustig.
 @scott@carfree.city @hllizi@hespere.de
@scott@carfree.city @hllizi@hespere.deFrüher konnte man die Infrastruktur noch mit gravierenden Fehlentscheidungen ruinieren und sich dabei darauf verlassen, daß es erst Jahre oder Jahrzehnte später auffallen würde, wenn man längst nicht mehr in öffentlicher Verantwortungslosigkeit war. Mittlerweile passieren die Dinge dafür viel zu schnell, aber die CDU macht weiter, als wäre nichts, und gibt dabei ein interessantes Bild ab.
 @laxsill@social.spejset.org
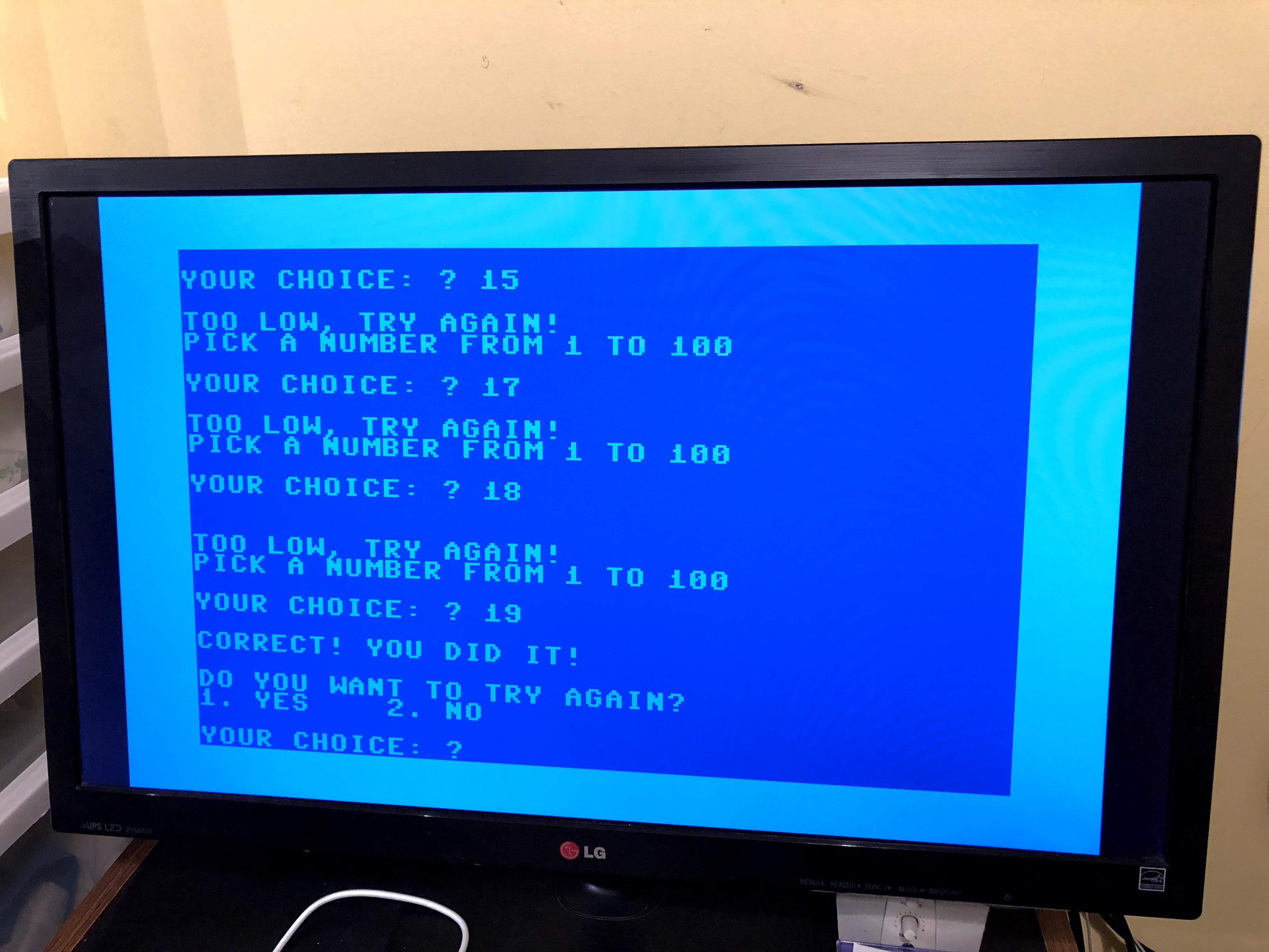
@laxsill@social.spejset.orgI solved today's #TiledWords puzzle!
🥣 “Bowl”
🕒 5 minutes, 33 seconds
💡 0/3 reveals used
∗️ 55 moves used
https://tiledwords.com/puzzles/2026-05-04
 @beeb@hachyderm.io @ellie@ellieayla.net
@beeb@hachyderm.io @ellie@ellieayla.netDo I want to implement a spreadsheet reference graph? Or just use something off-the-shelf?
https://lord.io/spreadsheets/
 @pdmckone@mstdn.ca
@pdmckone@mstdn.caI must mend my ways
Stop swearing at holey socks
Good gosh darn 'em all.
#dailyhaikuprompt - mend
#haiku
#poem

 @gardenscorpion@osna.social
@gardenscorpion@osna.socialEs gibt "neue" Infos zum folgenden Thema 👇🏻
#osnabruck
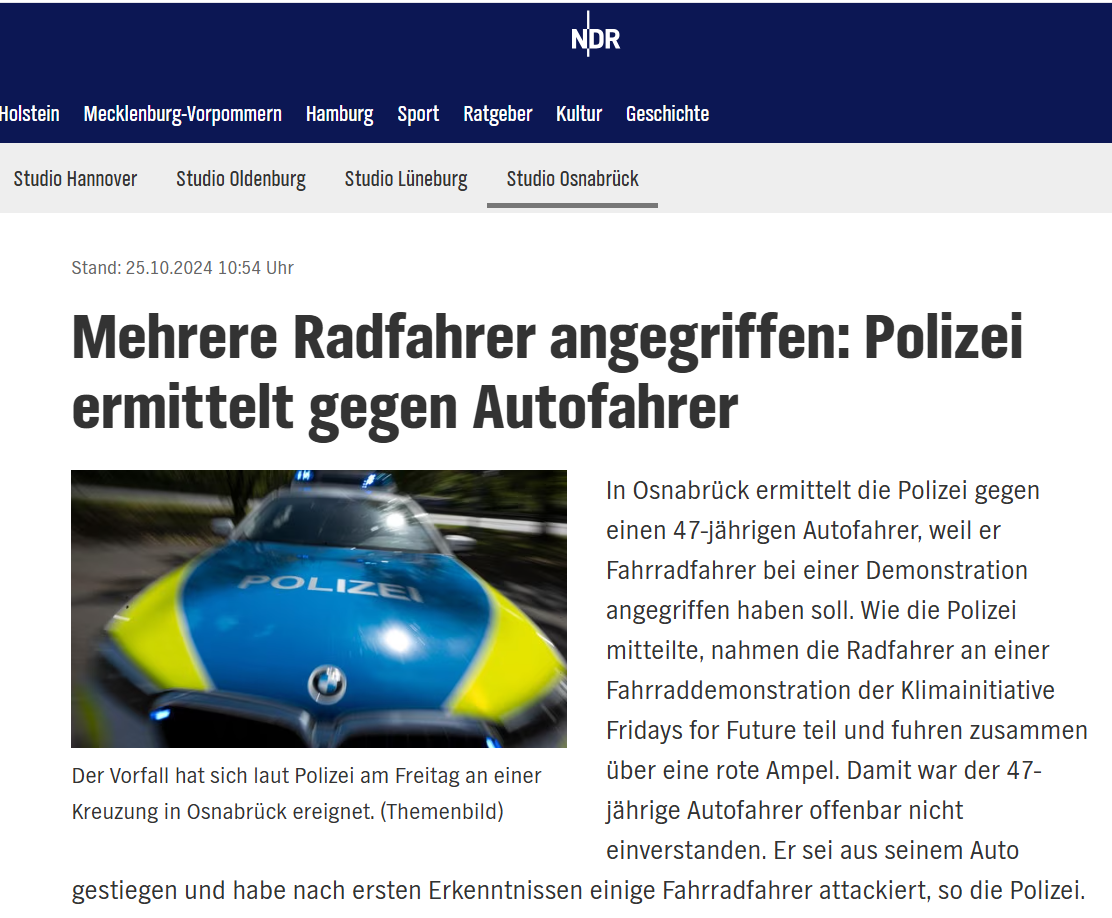
 @EarthOrgUK@mastodon.energy
@EarthOrgUK@mastodon.energy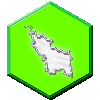 @wischekurier@mastodon.social
@wischekurier@mastodon.socialaktuelles #Wetter #Behrendorf #Wische 05-04-2026 07:45
Temperatur: (min: 6,5C) 10,7C (max: 10,7C)
Feuchte: 89%
Luftdruck: 1009,1 hPa (schnell fallend)
Windrichtung: 191 Grad
Wi…

 @carloshr@lile.cl
@carloshr@lile.clAudioslave
#Audioslave #CD #NowPlaying
 @netzschleuder@social.skewed.de
@netzschleuder@social.skewed.dedbpedia_all: DBpedia network (v3.6)
A network among all entries in DBpedia, a project that extracts structured information from Wikipedia. Nodes represent entities in DBpedia and an edge connects two entities based on DBpedia's notion of their relatedness. The data is extracted from the version 3.6 of the database.
This network has 3966924 nodes and 13820853 edges.
Tags: Informational, Relatedness, Unweighted, Multigraph
 @adrianco@mastodon.social
@adrianco@mastodon.socialTrack day at Laguna Seca today. First time for the Taycan, although I’ve driven the track many times over the years. The biggest brakes I’ve ever seen on a car (10 piston ceramic) are going to get a workout…

 @ellie@ellieayla.net
@ellie@ellieayla.netSandra Abstreiter was amazing tonight!
#montrealvictoire #phwl #hockey
 @kamasystems@social.linux.pizza
@kamasystems@social.linux.pizzaAmsterdam – de Pijp
#kamafotos
 @ellie@ellieayla.net
@ellie@ellieayla.net17114 fans. Heck yeah.
#ottawacharge
 @hippyjo@c.im
@hippyjo@c.imUkraine update: Integrating with European defense demonstrates the power of technology and cooperation vs Russian cruelty and disinformation.
Bypass the paywall with this friend link: https://medium.com/@g…
@hllizi@hespere.deJetzt sitz ich hier in Oberndorf am Neckar und bade in Hephaistos' stinkendem Odem.
 @aral@mastodon.ar.al
@aral@mastodon.ar.al🥳 New Kitten¹ Release
• Added: Database table event introspection.
Use the new `__showEventsOnTable()` introspection API call on the global `kitten` object to have events on that table logged out to the console.
Full change log: https://codeberg.org/kitten/app/src/br
 @maxheadroom@hub.uckermark.social
@maxheadroom@hub.uckermark.socialIt's quite ok. A bit crowded meanwhile. Last time I've been here in 2000. There were almost no people back the. #Beijing #ForbiddenCity



 @EarthOrgUK@mastodon.energy
@EarthOrgUK@mastodon.energyOn G83-Lite: Solar Nanogeneration For Everyone (2009) - Learn how plug-in solar curtain linings could trim your home power bill and footprint... #solar #balconySolar #plugInSolar
@hllizi@hespere.deGestern Let's Dance geschaut aber Birthing von SWANS dazu gehört, kann empfehlen.
 @UP8@mastodon.social
@UP8@mastodon.socialKitsunekamen envies this little droid for his ability to draw people out, he's here with the 501st Legion which is licensed to use Star Wars characters such as that stormtrooper standing guard
#photo #photography

 @benthos@mastodon.sdf.org @wischekurier@mastodon.social
@benthos@mastodon.sdf.org @wischekurier@mastodon.socialaktuelles #Wetter #Behrendorf #Wische 05-05-2026 15:25
Temperatur: (min: 12,3C) 13,8C (max: 15,6C)
Feuchte: 95%
Luftdruck: 1008,9 hPa (gleichbleibend)
Windrichtung: 351 Grad
Wi…
 @rigo@mamot.fr
@rigo@mamot.frWenn der Staat sich selbst nicht mehr an gesprochenes Recht hält und die Langsamkeit des Instanzenzugs nutzt um in der ersten Instanz als rechtswidrig eingestuftes Verhalten fortzusetzen, wie kann dieser Staat dann von den Bürgern erwarten, dass die sich noch an irgendwas halten. Nachteil des Bürgers ist, dass er bestraft werden kann, der Staat nicht, der Minister aber wohl. Vielleicht ist das die nächste Etappe: Aus dem Ministerium in den Knast. Claude Guéant zeigt, wie es geht!
 @RenkeSiems@openbiblio.social
@RenkeSiems@openbiblio.socialDa braucht man wohl keine externen Wissenschaftsfeinde mehr, wenn Professor*innen das mindestens genauso gut können. Personalisierte Leistungskontrolle bundesweit, als Datenbank schön filterbar, wer sich mit den Themen beschäftigt, die man nicht haben will, wer mit den "falschen" Personen und Einrichtungen kooperiert usw. Und frei zugänglich heißt: alle Kräfte des hybriden Kriegs können darauf zugreifen, autoritäre Regimes und Hassgruppen können sich Listen von Zielpersonen erstell…

 @cameo007@rheinneckar.social
@cameo007@rheinneckar.social @tomww@mastodon.social
@tomww@mastodon.socialDer eine Nachbar stinkt wieder mit in den Augen beißenden Rauchabgasen das Wohngebiet voll. Der muss einen teerversauten Kamin haben...
Leider stinkt es nicht in seinem eigenen Haus danach.
Ich bin so froh über den Aktivkohlefilter in der Hauslüftung.
#Holzofengate
 @dkomaran@social.linux.pizza
@dkomaran@social.linux.pizza @xtaran@chaos.social
@xtaran@chaos.socialUnfreundlichster #Veloständer seit langem. Und auch noch die Sorte #Felgenquetscher.
Most unfriendly #bikerack for ages. And even the type that bends rims.

 @EarthOrgUK@mastodon.energy
@EarthOrgUK@mastodon.energy96gCO2/kWh National Grid CO2 intensity is HIGH wrt last 24h so don't run anything that can wait! #CO2
@rigo@mamot.frChristian Lindner als Pferde - äh - Autohändler. Das passt.
 @sean@scoat.es
@sean@scoat.esThink about how expensive Uber has become. Now look at this chart (sorry; borrowed it from Reddit; assuming it’s not completely wrong), and draw the simplest conclusion about how much this LLM stuff is going to cost when you’re not getting a handout to subsidize it.
Heck, if a straight line is too hard for you, just ask the LLM.
 @LaChasseuse@mastodon.scot
@LaChasseuse@mastodon.scotIndeed.
 @EarthOrgUK@mastodon.energy
@EarthOrgUK@mastodon.energy67gCO2/kWh National Grid CO2 intensity so-so wrt last 24h so don't run big appliances now if you can wait. #CO2
@adrianco@mastodon.socialFirst cygnets of the year at #Abbotsbury #Swannery in #Dorset today. Male swan was displaying, defending the family. There are about 400 swans and over 100 nests there right now.



 @gardenscorpion@osna.social
@gardenscorpion@osna.socialLektion in #osnabruck|er „#Demokratie“: Ignoriert die Verwaltung den Bürgerwillen, darfst du als Bürger... gar nichts.
Laut Gericht darf nur der Stadtrat klagen. Also jene, die das Scheitern bloß „zur Kenntnis nehmen“, sollen sich selbst verklagen? Genial! Für Stadien & Prestige sind Million…
@EarthOrgUK@mastodon.energy @tomww@mastodon.socialIch hab das Kinderzimmer ausgeräumt.
 @aral@mastodon.ar.al
@aral@mastodon.ar.al🥳 New Kitten¹ Release
• Adds Kitten Introspection API
I’ll record a video this week demonstrating it.
In the meanwhile, check out the change log for details:
https://codeberg.org/kitten/app/src/branch/main/CHANGELOG.md#2026-03-29
En…
@adrianco@mastodon.social @ellie@ellieayla.netDubois is on fire!
#montrealvictoire #pwhl
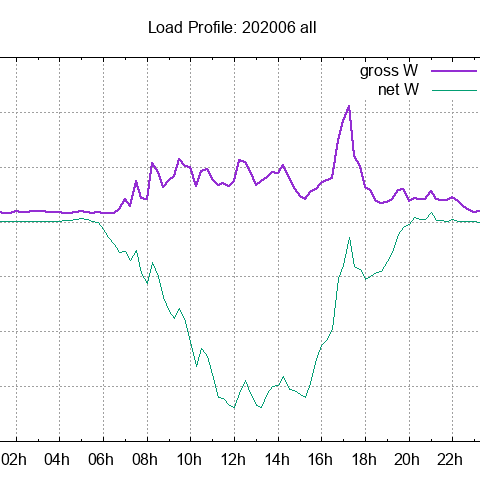
@EarthOrgUK@mastodon.energyElectricity use and load profiles for 16WW for March up until yesterday to exclude the BST change:
https://www.earth.org.uk/electricity-profiles.html#2026-03
@EarthOrgUK@mastodon.energyOn the IKEA SMAKLIG Built-in Induction Hob: Review - Is an induction hob better than cooking with gas? How about health and carbon? #induction #cutCarbon #airQuality -
@ellie@ellieayla.netEid Mubarak.
@wischekurier@mastodon.socialaktuelles #Wetter #Behrendorf #Wische 03-05-2026 14:00
Temperatur: (min: 9,1C) 26,3C (max: 27,4C)
Feuchte: 40%
Luftdruck: 1010,5 hPa (langsam fallend)
Windrichtung: N/A Grad
 @EarthOrgUK@mastodon.energy
@EarthOrgUK@mastodon.energy109gCO2/kWh National Grid CO2 intensity so-so wrt last 24h so don't run big appliances now if you can wait. #CO2
@netzschleuder@social.skewed.dereactome: Joshi-Tope human protein interactome (2005)
A network of human proteins and their binding interactions, extracted from Reactome project. Nodes represent proteins and an edge represents a binding interaction between two proteins.
This network has 6327 nodes and 147547 edges.
Tags: Biological, Protein interactions, Unweighted
https:/…
 @tomww@mastodon.social
@tomww@mastodon.socialRE: https://mastodon.green/@christineburns/116226711414607454
Ich hoffe sehr, dass die letzen 30 Minuten genügend US-Bürger vor den kommenden Wahlen aufwecken.
@EarthOrgUK@mastodon.energy94gCO2/kWh National Grid CO2 intensity is HIGH wrt last 24h so don't run anything that can wait! #CO2
@adrianco@mastodon.social @EarthOrgUK@mastodon.energyOn Website Technicals (2026-03) - Tech updates: EOM, Mastodon share button, bug fixes, low, RSS sadness, routing snafu... - https://www.earth.org.uk/note-on-site-technicals-106.html
@ellie@ellieayla.netGood thing we kicked our oil addiction, eh?
From: @…
https://wandering.shop/@cstross/116297408127872028
@rigo@mamot.frCloudflare is blocking @… in their "are you human" test for whatever reason 🙄 Firefox works on the same resource. Test is
https://www.researchgate.n…
@EarthOrgUK@mastodon.energy57gCO2/kWh National Grid CO2 intensity so-so wrt last 24h so don't run big appliances now if you can wait. #CO2
@adrianco@mastodon.social#photography #FlowersOfMastodon Kangaroo Paw flowering today in #Monterey county.
 @EarthOrgUK@mastodon.energy @ellie@ellieayla.net
@EarthOrgUK@mastodon.energy @ellie@ellieayla.netplease install our arbitrary remote code execution app, really, it's like the cloud (nee butt) but new & shiny & there's so much investment, just use our mega automated automation to unlock 100% of copy/paste from stackoverflow, it's so much faster than plagiarizing by hand, we promise it's not a total scam to keep oil extraction happening a bit longer, pretty please, you don't want to be left behind, please don't call it slop, if this con works I can make get another yacht, please??
#fuckai
@EarthOrgUK@mastodon.energy86gCO2/kWh National Grid CO2 intensity so-so wrt last 24h so don't run big appliances now if you can wait. #CO2
@EarthOrgUK@mastodon.energyOn Setting Up a Raspberry Pi 3 Off-grid Server (2018) - RPi3B upgrade for more speed and space... #frugal #offGrid - https://www.
@rigo@mamot.frIn Frankreich wurden mehrere Vorstandsmitglieder des Lafarge Konzerns (Zement/Beton) wegen Finanzierung des Terrorismus und Verletzung von Sanktionen zu mehrjährigen Haftstrafen verurteilt. Sie hatten 5,4Mio€ an den islamischen Staat gezahlt, damit die syrische Zementfabrik weiter laufen konnte. Von dem Geld hatte der IS u.a. die Attentate von Paris in 2015 finanziert.
@EarthOrgUK@mastodon.energyOn the IKEA SMAKLIG Built-in Induction Hob: Review - Is an induction hob better than cooking with gas? How about health and carbon? #induction #cutCarbon #airQuality -
@EarthOrgUK@mastodon.energy @rigo@mamot.frRE: https://mastodon.social/@skeptator/116391715835331117
Die Sprache von corporately owned social media um Trauer auszudrücken. Die Schäden durch Facebook, Tiktok & co zu beseitigen wird Jahrzehnte dauern. Der Kampf gegen soziale Umweltverschmutzung…
@EarthOrgUK@mastodon.energy74gCO2/kWh National Grid CO2 intensity so-so wrt last 24h so don't run big appliances now if you can wait. #CO2
@EarthOrgUK@mastodon.energy58gCO2/kWh National Grid CO2 intensity so-so wrt last 24h so don't run big appliances now if you can wait. #CO2
@rigo@mamot.fr @EarthOrgUK@mastodon.energy @EarthOrgUK@mastodon.energy60gCO2/kWh National Grid CO2 intensity so-so wrt last 24h so don't run big appliances now if you can wait. #CO2
@EarthOrgUK@mastodon.energy123gCO2/kWh National Grid CO2 intensity is HIGH wrt last 24h so don't run anything that can wait! #CO2
@EarthOrgUK@mastodon.energy162gCO2/kWh National Grid CO2 intensity so-so wrt last 24h so don't run big appliances now if you can wait. #CO2
@EarthOrgUK@mastodon.energyOn Spacetherm Aerogel Thermal Insulation - Learn about the highest-performing robust wall insulation for where space is at a premium: small homes in expensive cities. #aerogel #IWI #insulation -
@EarthOrgUK@mastodon.energy @EarthOrgUK@mastodon.energy @EarthOrgUK@mastodon.energy113gCO2/kWh National Grid CO2 intensity so-so wrt last 24h so don't run big appliances now if you can wait. #CO2
@EarthOrgUK@mastodon.energy90gCO2/kWh National Grid CO2 intensity is HIGH wrt last 24h so don't run anything that can wait! #CO2
@EarthOrgUK@mastodon.energy82gCO2/kWh National Grid CO2 intensity so-so wrt last 24h so don't run big appliances now if you can wait. #CO2
@EarthOrgUK@mastodon.energy87gCO2/kWh National Grid CO2 intensity is HIGH wrt last 24h so don't run anything that can wait! #CO2
@EarthOrgUK@mastodon.energy88gCO2/kWh National Grid CO2 intensity so-so wrt last 24h so don't run big appliances now if you can wait. #CO2
@EarthOrgUK@mastodon.energyOn Website Technicals (2026-03) - Tech updates: EOM, Mastodon share button, bug fixes, low, RSS sadness, routing snafu. - https://www.earth.org.uk/note-on-site-technicals-106.html
@EarthOrgUK@mastodon.energy149gCO2/kWh National Grid CO2 intensity is HIGH wrt last 24h so don't run anything that can wait! #CO2
@EarthOrgUK@mastodon.energy140gCO2/kWh National Grid CO2 intensity so-so wrt last 24h so don't run big appliances now if you can wait. #CO2
@EarthOrgUK@mastodon.energy @EarthOrgUK@mastodon.energy @EarthOrgUK@mastodon.energy @EarthOrgUK@mastodon.energy57gCO2/kWh National Grid CO2 intensity so-so wrt last 24h so don't run big appliances now if you can wait. #CO2