Two research papers describe how Google's Co-Scientist and nonprofit FutureHouse's AI tools can succeed at drug-retargeting tasks by forming hypotheses (John Timmer/Ars Technica)
https://arstechnica.com/science/2026/05/two-…
Google unveils Continue On, a new feature in Android 17 that will let users move tasks between Android devices, similar to Apple's Handoff feature (Ben Schoon/9to5Google)
https://9to5google.com/2026/05/19/android-17s-…
Cohere releases Command A , a sparse MoE open model built for agentic tasks, with 218B total and 25B active parameters, its first under the Apache 2.0 license (Carl Franzen/VentureBeat)
https://venturebeat.com/technology/c…
Immensely satisfying to get both tasks 2 and 3, which have stubbornly remained on my to-do list, both ticked off today.
Replaced article(s) found for cs.LG. https://arxiv.org/list/cs.LG/new
[5/11]:
- Diffuse AI Control on Fuzzy Tasks
Mikhail Terekhov, Caglar Gulcehre, Vivek Hebbar, Joe Benton
Q&A with Google SVP James Manyika on AI's ability to automate tasks versus occupations, his optimism about the labor market despite AI-driven layoffs, and more (Casey Newton/Platformer)
https://www.platformer.news/james-manyika-google-ai-jobs-io-2026/
Wrote a little intro post to my Fisk AI project, why, who for etc
Local friendly, privacy friendly, strong guardrails, doing just what you give it the ability to do etc
Hopefully a AI Harness for sceptics or just for better outcomes for those tasks you wish to do repeatedly.
Minimal dependencies, quick to get going, easy to configure.
Also the easiest possible way to do build MCP servers for other AI Agents
AI made it easy to start work.
It did not make it easy to finish it.
Daily Pull Request contexts per developer are up 67.4%.
Work restarts, tasks that return to in-progress after moving to another stage, are up 13.8%.
26% more in-progress tasks show no activity for seven or more days:
i.e. work was started, claimed capacity, and then stalled.
The developer productivity picture that AI tools present at the individual level is one of acceleration.
The w…
Alibaba's T-Head unveils the Zhenwu M890 AI chip for training and inference, saying it is particularly suited for agentic tasks, and plans annual upgrades (Luz Ding/Bloomberg)
https://www.bloomberg.com/news/articles/2026-05-20/a…
There should be more discussion about the costs of AI related to their actual added value in organisations. It is great to have an enormously capable model like Fable5, but is it worth it, can't we do the same tasks or parts of those tasks with much cheaper models?
https://artificialanalysis.ai/#price
The incredible analytical work of John Burn Murdoch @… along with some other colleagues is one of the main reasons I subscribe to the FT. It's rather expensive but absolutely worth it.
https://fediscience.org/@Ruth_Mottram/116582689708855765
Ruth_Mottram - This is a fascinating and beautifully illustrated analysis, exploring convincingly why birth rates are crashing basically everywhere and while there are certain many factors, the smoking gun is actually a smartphone.
So what to do about it? I think I agree with the conclusions, housing and financial support is one element, equality between sexes in household tasks certainly another, but finally, perhaps our job as parents is to inculcate the habit of socialising with others into our kids, especially when they get to the teenage years.
Why birth rates are falling everywhere all at once - a limited 🎁 https://giftarticle.ft.com/giftarticle/actions/redeem/8bf630d4-6e20-42c7-bb33-e98dd6a01571
My latest podcast is all about #SelfCare and the benefits of looking to do less, not more.
Self-care often implies doing additional activities. And this can feel difficult or even overwhelming!
But we can also take care of ourselves by stripping out commitments, tasks and roles.
Ep 216 of My Pocket Psych is available wherever you get your podcasts, or via worklifepsych…
Gritt, which is developing an AI system that helps build infrastructure like solar panels, emerges from stealth with a $26M Series A and $34M in total funding (Tim Fernholz/TechCrunch)
https://techcrunch.com/2026/07/21/grit
Work is super-busy right now with a lot of projects going on...
Do you know what will *not* help?
AI.
Do you know what will help?
Focusing and prioritizing tasks. Getting shit done. Doing high-quality work we can be proud of.
#NoAI #FuckAI
I somewhat agree with @… on his recent AI statement.
LLMs for programming tasks are useful - for the time being.
Are they economically viable? Probably not.
Are they sustainable? Hell no.
Are they copyright infringement? Most likely.
But this is not what Torvalds is talking about. This guy just wants to make his Kernel better.…
New on #blog: pkgbump: from a dumb tool to an irreplaceable helper
#Gentoo developer. It shouldn’t then be surprising that it is the one most asking for some kind of automation, and that the #pkgbump script would be one of the first scripts to become a part of the mgorny-dev-scripts package.
Today’s pkgbump have come a long way from the trivial script of its first iteration. The most recent versions finally feature the feature I desired for a long time: version manipulation. This also made it possible for the script to become a complete version bumping tool rather than just a part of a larger workflow. In this post, I’d like to shortly tell the story behind the changes, and demonstrate the new options.
"""
#packaging
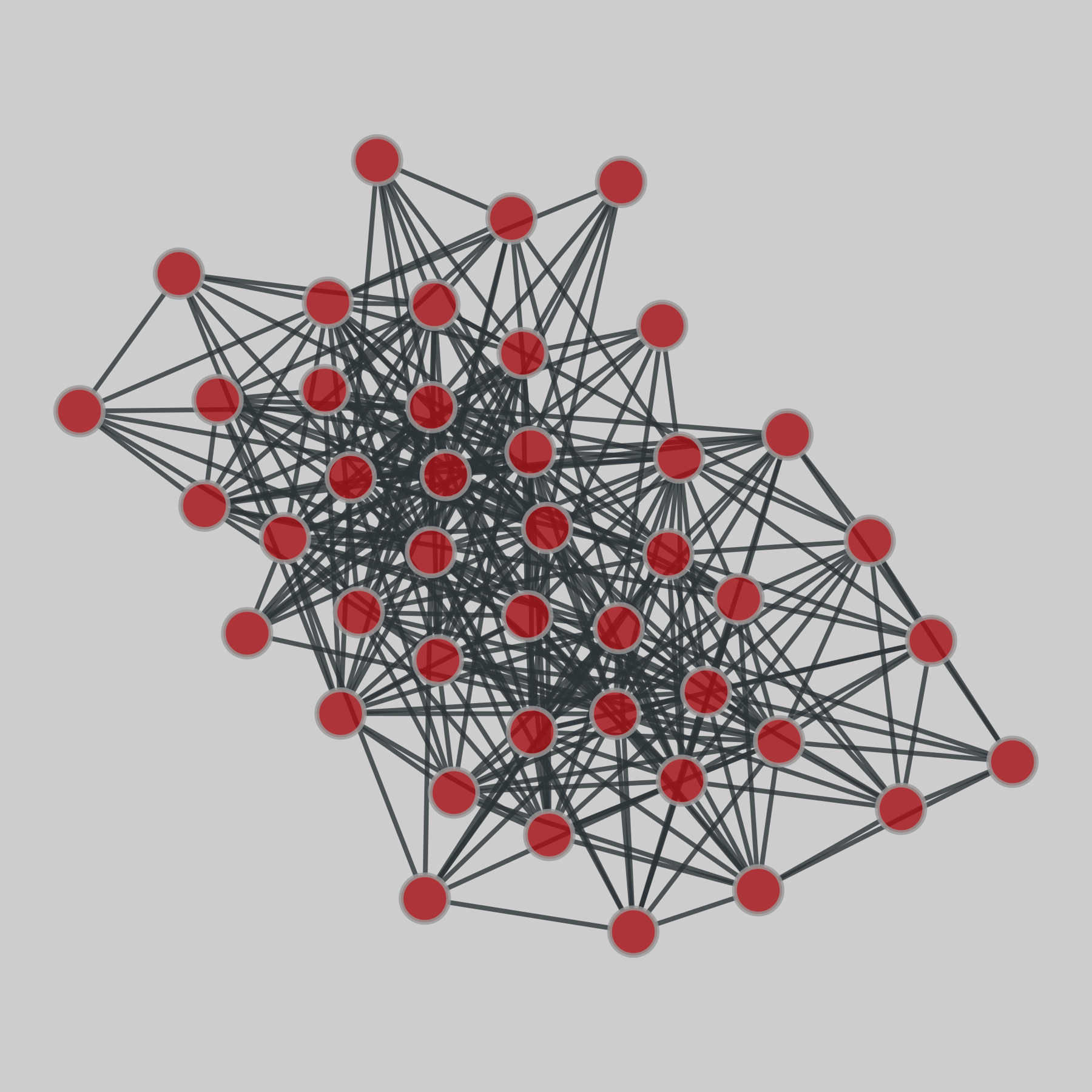
windsurfers: Windsurfers network (1986)
A network of interpersonal contacts among windsurfers in southern California during the Fall of 1986. The edge weights indicate the perception of social affiliations majored by the tasks in which each individual was asked to sort cards with other surfer’s name in the order of closeness.
This network has 43 nodes and 336 edges.
Tags: Social, Offline, Weighted
I sure love how the past few days, all "10 minute quick tasks" became hours-long troubleshooting and fixing tasks...
Cursor releases Composer 2.5, saying it's better at sustained work on long-running tasks and follows complex instructions more reliably; it's built on Kimi K2.5 (Cursor)
https://cursor.com/blog/composer-2-5
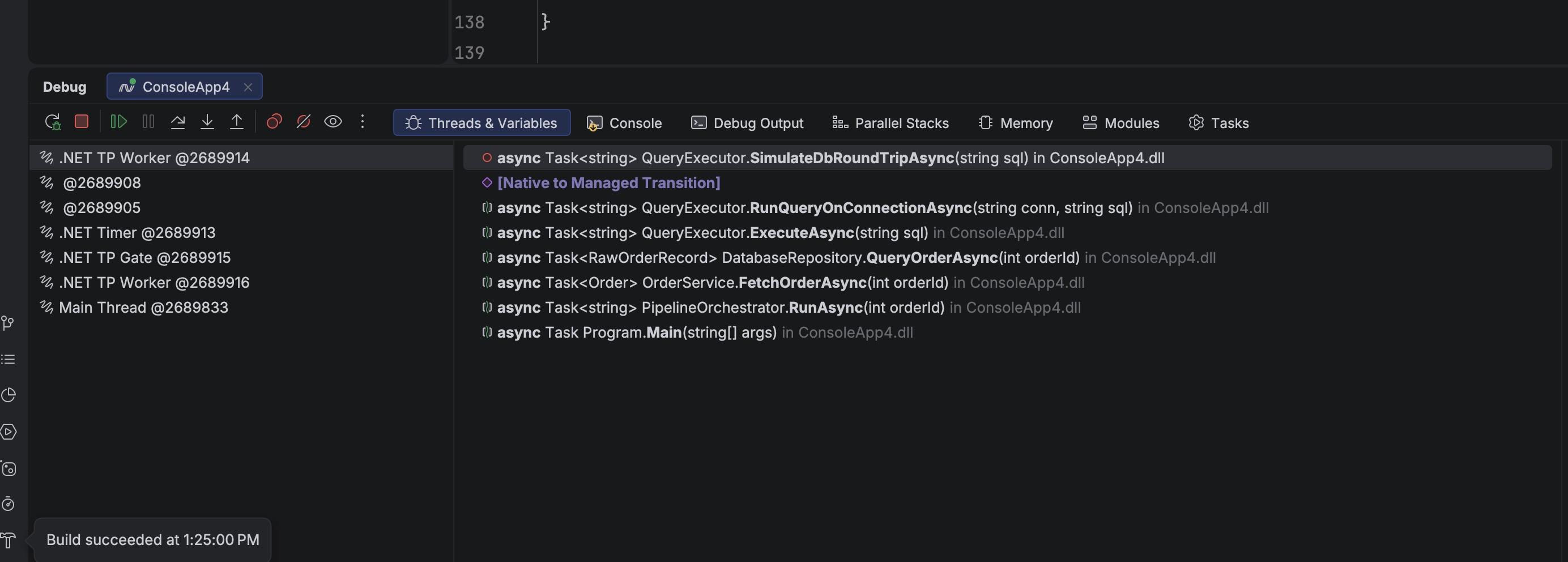
It might not look like much, but #JetBrains Rider just released (EAP6) a debugger update that displays asynchronous Tasks in a way that makes them feel like synchronous code. Thank goodness!
#dotnet #async
from my link log —
An overview of language features and implementation tasks that contribute towards the goal of adding dependent types to Haskell.
https://ghc.serokell.io/dh
saved 2026-07-15
It‘s always amazing how KPI fail to improve the performance they are expected to improve.
Amazon staff use AI tool for unnecessary tasks to inflate usage scores https://www.ft.com/content/8ee0d3ef-9548-422d-8ff1-ebd48ad4b2ca
RE: https://hachyderm.io/@thomasfuchs/116726575162112584
And even for the most optimal of use cases, code generation, which gives an LLM every possible advantage (huge amounts of self-similar training data with millions of iterations of the same problems and solutions, strictly deterministic symbol sequences in highly simplified languages), LLMs are starting to approach local maxima; they’re even regressing when context windows get too large (so more capable hardware doesn’t help).
I still strongly believe that they’re useless for 99% of tasks they’re marketed for and for the rest (like coding) there will be locally run solutions that are affordable.
¯\_(ツ)_/¯
Do you have dreams that turned into tasks?
Things you wanted that became things you "should" do?
Sometimes what we want gets wrapped in shame. It sits too long. Then it feels like failure instead of desire.
But the want was there first. The shame came later.
New post explores how desires become energy leaks and what to do about it.
Essentially, we seem to know that super intelligence can't exist due to computability constraints. (You can't build any computer big or powerful enough to actually be the AGI god they're trying to create.) But I don't know if we have any idea what the limit is before that.
LLMs (and SLMs) are very efficient at very specific tasks, far better than humans. But they are not better for a lot of tasks. It may just always be prohibitively expensive to use LLMs for certain tasks.
We've already run in to training ceilings where additional training decreases performance. We've run in to security problems (like guard rails basically can't ever actually exist because there are infinitely many ways around them, and those ways can literally just be solved for. See https://llm-attacks.org/)
📋 #Kanban board moves tasks through BACKLOG − INBOX − ACTIVE − DONE with real-time agent feedback, plus Routines for cron-style recurring tasks and persistent per-project Memory
Factotum formally means a person who does many different tasks, often as an assistant.
Charles Bukowski wrote a book titled "Factotum" about a man who was adrift in a haze of self-indulgence and purposeless existence, taking any odd job that was convenient.
I consider the state of being a factotum as the opposite of living a "full" life, and I am circling around the difference between fully devoting one's focus towards a personal passion rather than a seri…
RE: https://mamot.fr/@pluralistic/116732569585675070
Cory's latest leans in the direction of the thing that has been annoying me lately: companies and governments pushing what were previously internal admin tasks out onto their customers and citizens thro…
I bit my tongue as long as I could but there came a point I had to blurt out "we can delegate tasks but not responsibility". 😒
#delegation #responsibility #frustration
Bounded Priority-Aware Locking for Real-Time Kernels
Shriram Raja, Richard West
https://arxiv.org/abs/2605.27620 https://arxiv.org/pdf/2605.27620 https://arxiv.org/html/2605.27620
arXiv:2605.27620v1 Announce Type: new
Abstract: A real-time multicore system requires delay bounds on access to shared resources. These resources include the kernel, which has potentially many non-preemptible critical sections guarded by one or more different synchronization primitives. While primitives such as FIFO locks bound the waiting time to enter a critical section, they do not distinguish the importance of individual tasks competing for shared resource access. To address this, we consider a priority-aware spinlock, which reduces the average delay of more important tasks while maintaining a worst-case bound on lock waiting time. We propose a Batched Priority Lock (BPL) that first groups waiting tasks based on the order of their lock requests, and then determines the next lock holder according to priority within the waiting group. We compare BPL to alternative lock approaches, showing that the average waiting time is reduced for higher priority tasks, in simulations up to 64 cores, and for a working implementation on an 8-core machine with a real RTOS. BPL is a compromise between strict priority and FIFO ordering. While strict priorities may lead to starvation and, hence, unbounded lock acquisition delays, BPL has the same waiting bound as FIFO, but with benefits to higher priority tasks. Although its complexity is greater than that of a simple spinlock, its common case execution overhead is shown to be inexpensive in a working system. We believe this is an acceptable cost in systems that require predictability.
toXiv_bot_toot
#today I have been at our TTK Energy Group meeting where we all seemed to have major announcements! Now I am home and doing some #QA work on a course for Surrey uni, and I have a HUGE pile of other work chores/tasks to try to work though somehow...
Execs are confused: we forced you to use all these powerful AI tools and yet our profits aren't 10x! What gives?
Individual productivity is always downstream of strategy. And the same "more, faster!" attitude that creates incremental improvements in delivery speed means that leaders rush through strategy formation.
If the tasks don't add up to anything meaningful, no amount of model improvements will help you.
Nvidia researchers unveil ENPIRE, an agent harness framework that develops robotic self-improvement strategies for physical tasks with minimal human supervision (Jeremy Hsu/Ars Technica)
https://arstechnica.com/ai/2026/06/ai-coding-agents-can-auton…
For some reason Hannan Fry is optimistic AI will get better at this (but then maybe her job depends on it?). Personally I think mathematicians have better things to do.
'Brit mathematician lets AI agent loose with credit card – cue password leaks, CAPTCHA chaos and more
British mathematician Professor Hannah Fry has shared a cautionary experiment involving an AI agent, a set of tasks, and a bank card number Fry's team gave it "to show us what it could do."'
The general pattern that the research points to is that many people don’t use the time they save using AI to do less; they use the time to take on new tasks.
A shoutout to the systems engineers that made Microsoft Windows so fragile, that a single file browser (explorer.exe) freezing causes my Edge downloads to pause, and closing the frozen file browser closes all my file browsers.
My ADHD brain needed those open file browsers so I could keep track of all my in-progress tasks. How do I resume now? Yeah, I suppose I could come up with a better system than that.
Remember to delegate some key cognitive tasks to an LLM today
📦 Structured concurrency — control coroutine lifetime with the Scope sandbox and manage groups of coroutines via TaskGroup.
🗄️ PDO Pool: connection pooling built right into PDO with automatic connection management for maximum performance.
🔄 Channels & ThreadPool for data exchange between coroutines. Buffered and unbuffered channels for producer/consumer patterns, cross-thread via ThreadChannel, and parallel CPU tasks via Thread and ThreadPool.
Trump’s well-documented ability to destroy everything he touches has come for what should have been the easiest of tasks:
making the 250th anniversary of the signing of the Declaration of Independence fun.
If there is one thing the world’s oldest democracy is good at, it’s throwing Independence Day parties,
hosting outdoor concerts, and filling out state fairs with charmingly schlocky entertainment and ice cream stands.
Producing the Great American State Fair in Was…
windsurfers: Windsurfers network (1986)
A network of interpersonal contacts among windsurfers in southern California during the Fall of 1986. The edge weights indicate the perception of social affiliations majored by the tasks in which each individual was asked to sort cards with other surfer’s name in the order of closeness.
This network has 43 nodes and 336 edges.
Tags: Social, Offline, Weighted
It's so sad. With 📆 CalDAV we have a really nice open protocol for syncing events, todos and notes. The protocol, which is technically more of a file format (iCalendar) even supports quite complex reccurence rules and even things like recurring tasks.
Unfortunately, client (and server) applications usually only implement a subset of what's possible.
Know some good ones? Let me know!
#CalDAV
Bunkerhill Health, which uses AI agents for hospital tasks like managing wait times, raised a $25M Series B led by Khosla, bringing its total funding to $55M (Allie Garfinkle/Fortune)
https://fortune.com/2026/07/16/bunkerhill-health-raises-…
I know I'm in a ridiculously privileged situation to be able to moan about this, but work has really felt like **work** recently. Endless marking, paper revisions, reviewing, and admin. It seems that all of the crap tasks have basically bunched together in the last couple of weeks.
It's amazing how bad I am at estimating how long simple tasks* will take.
I had a nearly finished manuscript. I just needed to tidy a few things in it and then upload for review
Two hours tops I told my family.
5.5 hours later...
#AcademicChatter
Zhipu launches GLM-5.2, says it markedly improves coding and agentic tasks, with strong long-horizon capabilities and a 1M context window, under an MIT license (Z.ai)
https://z.ai/blog/glm-5.2
Google I/O showed how the industry has seized upon LLMs as the "future" of software. But that couldn't be further from the truth! It is an intensification of the old way. The same features as before, only MORE and FASTER.
It's the same mediocre vision execs have had for 40 years: give customers more tasks to do on your platform, sell them tools to solve the problems you created.
But the conditions that made this business model possible are collapsing.
🎧 My latest podcast is all about the dangers of over-identifying with the tasks you manage to complete, and with your perceptions of productivity overall. Task lists can inspire us or they can stress us out. I explain the difference and what you can do about it.
👉🏻 Ep 215 of 'My Pocket Psych' is available wherever you get your podcasts or direct from
Why can't this company stop lying for once ???? 😡 🤬 🤮
website: From today through June 22, Fable 5 is included on Pro, Max, Team, and seat-based Enterprise plans at **** no extra cost ****
inside #claude code cli:
> Fable 5 · Most capable for your hardest and longest-running tasks · Uses your limits **** ~2× faster than Opus *****
Poetic, which aims to use AI to automate tasks like financial compliance, emerges from stealth with $50M in funding from OpenAI and others at a $500M valuation (Paayal Zaveri/Bloomberg)
https://www.bloomberg.com/news/articles/20
It's taken me most of the day, but I am finally down to fewer than 250 emails in my inbox. Loads of different tasks dealt with too - I guess I should go to bed now, but I also really need to finish this paper now...
#AcademicChatter
OpenRouter debuts Fusion, a tool for prompting multiple AI models in parallel, claiming it can achieve "Fable-level intelligence at half the price" (Brian Thomas/OpenRouter Blog)
https://openrouter.ai/blog/announcements/fusion-beats-frontier/
Muse Spark 1.1 costs $1.25 per 1M input tokens and $4.25 per 1M output tokens; Alexandr Wang says coding and agentic tasks were key focuses (Ina Fried/Axios)
https://www.axios.com/2026/07/09/meta-ai-spark-model-update-developer
@… Such a good way of looking at it. We're the decision-makers, we need to remember to decide what to focus on and how to evaluate a day. And not all tasks are equally impactful or meaningful. Or even necessary.
I often remind clients: the question isn't "Was I productive today?". It's "Given everything that happened today,…
🧩 Rich plugin ecosystem: hundreds of plugins run tasks anywhere — local, SSH, #Docker, #Kubernetes or serverless task runners — and code in any language including #Python, Node.js, R, Go and S…
SpaceXAI launches Grok 4.5, its first model built in partnership with Cursor, designed to "handle difficult, long-running" legal, finance, and coding tasks (Carmen Arroyo/Bloomberg)
https://www.bloomberg.com/news/articles/20
🎛️ #CTRLNODE is an #opensource remote orchestration platform for #AIcodingagents. Install the Bridge binary on any machine — laptop, VPS, CI box — and dispatch tasks, schedule routin…
Rivian CEO RJ Scaringe's Mind Robotics, which is building AI-powered robots for manufacturing tasks, raised $400M, source says at a $3.4B valuation (Sean McLain/Wall Street Journal)
https://www.wsj.com/business/autos/rivian-
🛡️ Structure & resilience: namespaces, labels, subflows, retries, timeouts, error handling, conditional branching, backfills, plus parallel and sequential tasks designed to scale to millions of workflows with high availability
Sources: some Amazon employees are using in-house OpenClaw-like tool MeshClaw for unnecessary tasks to inflate AI token use after Amazon set weekly AI targets (Financial Times)
https://www.ft.com/content/8ee0d3ef-9548-422d-8ff1-ebd48ad4b2ca
Google DeepMind details a Gemini-powered mouse pointer that understands what it is pointing at, allowing users to perform tasks without using text-heavy prompts (Google DeepMind)
https://deepmind.google/blog/ai-pointer/
Jeff Bezos' Prometheus, which is building AI models for physical tasks, raised a $12B Series B at a $41B valuation, following a $6.2B Series A (Dan Primack/Axios)
https://www.axios.com/2026/06/11/prometheus-bezos-industrial-ai
As AI commoditizes benchmarkable work, an organization's lasting moats lie in tasks that are verifiable through its private data and judgment (Sarah Guo)
https://saranormous.substack.com/p/the-untrainable
Cybersecurity researchers complain that Claude Fable's guardrails are too strict, rejecting "innocuous tasks" like reading blog posts or performing code reviews (Lorenzo Franceschi-Bicchierai/TechCrunch)
https://techcrunch.com/2026/06/10/cybe
OpenAI says it found widespread task issues in SWE-Bench Pro, estimates ~30% of tasks are broken, and retracts its earlier recommendation to adopt the benchmark (OpenAI)
https://openai.com/index/separating-signal-from-noise-coding-evaluations
Xiaomi open sources MiMo-V2.5 and MiMo-V2.5-Pro under the MIT License, saying both models are among the most efficient available for agentic "claw" tasks (Carl Franzen/VentureBeat)
https://venturebeat.com/ai/open-source…
Internal documents: Amazon is working on an Alexa project, codenamed Moonraker, to handle more complex, multistep tasks, projecting $100M in GPU costs in 2026 (Eugene Kim/Business Insider)
https://www.businessinsider.com/amazon-moonraker-project-alexa-agen…
As wealth managers confront an AI reckoning, the tech is, for now, easing their workloads by picking up routine tasks, freeing up more time to advise clients (Bloomberg)
Sources: Apple plans to let users choose from multiple third-party AI models to perform tasks like generating and editing text and images in iOS 27 (Mark Gurman/Bloomberg)
https://www.bloomberg.com/news/articles/20
Enzo Health, whose AI tools help home health and hospice agencies automate tasks like patient intake and documentation review, raised a $20M Series A led by N47 (Brock E.W. Turner/Axios)
https://www.axios.com/pro/health-tech-deals/2026/05/04/e…
Robotics startup Generalist, which released its GEN-1 model to complete short physical tasks in April, raised $400M led by Radical Ventures at a $2B valuation (Dina Bass/Bloomberg)
https://www.bloomberg.com/news/articles/202…
Amazon unveils its next-gen Proteus warehouse robot, adding AI-powered language capabilities to let workers assign tasks, rolling out in Europe in H1 2027 (Robert Hart/The Verge)
https://www.theverge.com/ai-artificial-intelligence/942…
Anthropic unveils 10 new AI agents for the financial sector, including for drafting pitch decks, reviewing financial statements, and escalating compliance cases (Shirin Ghaffary/Bloomberg)
https://www.bloomberg.com/news/articles/20
OpenAI unveils new Codex plugins for tasks related to public equity investment, banking and sales, and other roles, and plans to integrate Codex into ChatGPT (Shirin Ghaffary/Bloomberg)
https://www.bloomberg.com/news/articles/20
Microsoft announces Scout, an always-on AI agent built on OpenClaw, appearing as a contact within Microsoft Teams to automate scheduling and more (Reece Rogers/Wired)
https://www.wired.com/story/meet-microsoft-scout-your-ai-coworker-that-never-logs-off/…
Triomics, which is building an AI-powered platform to help oncologists automate data-heavy tasks, raised a $22M Series B, following a $15M Series A in 2024 (Marina Temkin/TechCrunch)
https://techcrunch.com/2026/05/27/triomics-nabs-22m-to-b…
Sources: Amazon has shut down an internal leaderboard that tracked employees' use of AI tools after workers tried to boost their scores with needless tasks (Rafe Rosner-Uddin/Financial Times)
https://www.ft.com/content/b1a62a7f-6df5-4c90-94ce-64ce9c9961b6
…
A growing number of execs are creating AI digital twins to manage tasks; Reid Hoffman says "Reid AI" has delivered 75 addresses and presentations since 2024 (Joann S. Lublin/Wall Street Journal)
https://www.wsj.com/tech/ai/ai-agents-work
As China's working-age population shrinks, a consensus is emerging that it must deploy embodied AI robots into as many tasks as possible, as soon as possible (Financial Times)
OpenAI releases ChatGPT for Clinicians, a tool for medical tasks like documentation and research, free for verified physicians, pharmacists, and more in the US (OpenAI)
https://openai.com/index/making-chatgpt-better-for-clinicians
OpenRouter raised $113M led by CapitalG, a source says at a $1.3B valuation, and now processes 25T tokens across 400 models weekly, up from 5T six months ago (Michael J. de la Merced/New York Times)
https://www.nytimes.com/2026/05/26/business/dealb…
OpenAI announces workspace agents in ChatGPT, letting teams create Codex-powered shared agents for complex tasks, and says they are "an evolution of GPTs" (OpenAI)
https://openai.com/index/introducing-workspace-agents-in-chatgpt/
OpenAI unveils GPT 5.5, intended to be better at completing work without much direction, saying the model "kind of figures it out, deals with ambiguity" (Rachel Metz/Bloomberg)
https://www.bloomberg.com/news/articles/20
 @Techmeme@techhub.social
@Techmeme@techhub.social