NeuroSketch: An Effective Framework for Neural Decoding via Systematic Architectural Optimization
Gaorui Zhang, Zhizhang Yuan, Jialan Yang, Junru Chen, Li Meng, Yang Yang
https://arxiv.org/abs/2512.09524 https://arxiv.org/pdf/2512.09524 https://arxiv.org/html/2512.09524
arXiv:2512.09524v1 Announce Type: new
Abstract: Neural decoding, a critical component of Brain-Computer Interface (BCI), has recently attracted increasing research interest. Previous research has focused on leveraging signal processing and deep learning methods to enhance neural decoding performance. However, the in-depth exploration of model architectures remains underexplored, despite its proven effectiveness in other tasks such as energy forecasting and image classification. In this study, we propose NeuroSketch, an effective framework for neural decoding via systematic architecture optimization. Starting with the basic architecture study, we find that CNN-2D outperforms other architectures in neural decoding tasks and explore its effectiveness from temporal and spatial perspectives. Building on this, we optimize the architecture from macro- to micro-level, achieving improvements in performance at each step. The exploration process and model validations take over 5,000 experiments spanning three distinct modalities (visual, auditory, and speech), three types of brain signals (EEG, SEEG, and ECoG), and eight diverse decoding tasks. Experimental results indicate that NeuroSketch achieves state-of-the-art (SOTA) performance across all evaluated datasets, positioning it as a powerful tool for neural decoding. Our code and scripts are available at https://github.com/Galaxy-Dawn/NeuroSketch.
toXiv_bot_toot
HTTP/1.1 must die: the desync endgame
Upstream HTTP/1.1 is inherently insecure and regularly exposes millions of websites to hostile takeover. Six years of attempted mitigations have hidden the issue, but failed to fix it.
🌐 https://portswigger.net/research/http1-must-die
Dimensionality reduction and width of deep neural networks based on topological degree theory
Xiao-Song Yang
https://arxiv.org/abs/2511.06821 https://arxiv.org/pdf/2511.06821 https://arxiv.org/html/2511.06821
arXiv:2511.06821v1 Announce Type: new
Abstract: In this paper we present a mathematical framework on linking of embeddings of compact topological spaces into Euclidean spaces and separability of linked embeddings under a specific class of dimension reduction maps. As applications of the established theory, we provide some fascinating insights into classification and approximation problems in deep learning theory in the setting of deep neural networks.
toXiv_bot_toot
Topological Structure of Infrared QCD
J. Gamboa
https://arxiv.org/abs/2511.07455 https://arxiv.org/pdf/2511.07455 https://arxiv.org/html/2511.07455
arXiv:2511.07455v1 Announce Type: new
Abstract: We investigate the infrared structure of QCD within the adiabatic approximation, where soft gluon configurations evolve slowly compared to the fermionic modes. In this formulation, the functional space of gauge connections replaces spacetime as the natural arena for the theory, and the long-distance behavior is encoded in quantized Berry phases associated with the infrared clouds. Our results suggest that the infrared sector of QCD exhibits features reminiscent of a \emph{topological phase}, similar to those encountered in condensed-matter systems, where topological protection replaces dynamical confinement at low energies. In this geometric framework, color-neutral composites such as quark--gluon and gluon--gluon clouds arise as topological bound states described by functional holonomies. Illustrative applications to hadronic excitations are discussed within this approach, including mesonic and baryonic examples. This perspective provides a unified picture of infrared dressing and topological quantization, establishing a natural bridge between non-Abelian gauge theory, adiabatic Berry phases, and the topology of the space of gauge configurations.
toXiv_bot_toot
Hamiltonian flow between standard module Lagrangians
Yujin Tong
https://arxiv.org/abs/2511.06431 https://arxiv.org/pdf/2511.06431 https://arxiv.org/html/2511.06431
arXiv:2511.06431v1 Announce Type: new
Abstract: In Aganagic's Fukaya category of the Coulomb branch of quiver gauge theory, the $T_\theta$-brane algebra gives a symplectic realization of the Khovanov-Lauda-Rouquier-Webster (KLRW) algebra, where each standard module is known to admit two Lagrangian realizations: the 'U'-shaped $T$-brane and the step $I$-brane. We show that the latter arises as the infinite-time limit of the Hamiltonian evolution of the former, thus serving as a generalized thimble. This provides a geometric realization of the categorical isomorphism previously established through holomorphic disc counting.
toXiv_bot_toot
Hey! @…, Reginé Gilbert, and @… gathered 36 authors to write about ethics in digital accessibility.
Chapters, authors (I’m one of them), pre-order:
had my head properly spun by SML at sultan room. bit less abstract than i was expecting, but maybe more magical, especially the imperceptible studio-like blend between jeremiah chiu's modular synth & booker stardrum's beats (& maybe sax & guitar loops?), building to over-the-top bubble-jazz grooves. #nyc #jazz
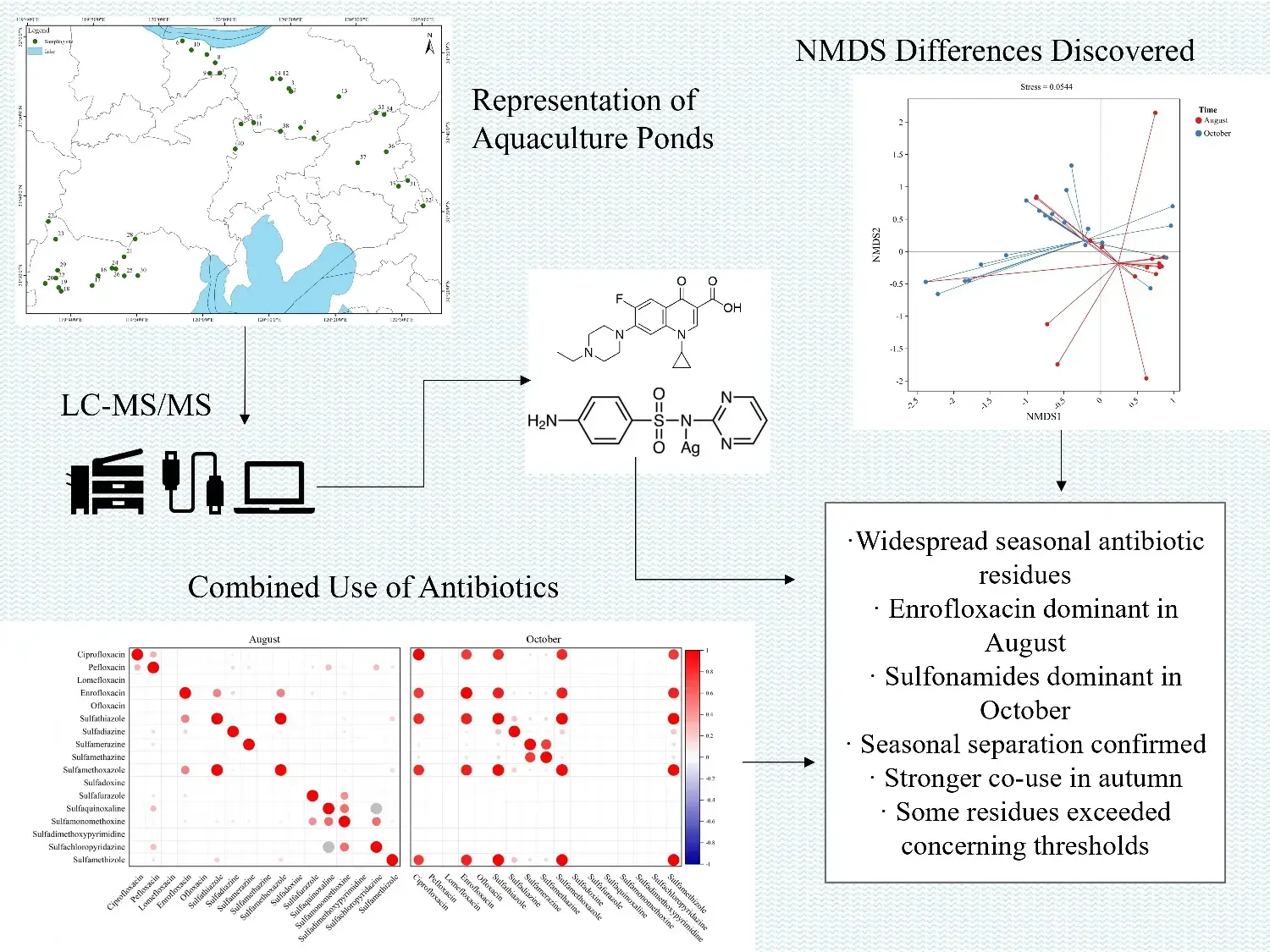
💊 Occurrence, Dominance, and Combined Use of Antibiotics in Aquaculture Ponds
#food
Comment on: "St\"{a}ckel and Eisenhart lifts, Haantjes geometry and Gravitation"
A. V. Tsiganov
https://arxiv.org/abs/2511.05765 https://arxiv.org/pdf/2511.05765 https://arxiv.org/html/2511.05765
arXiv:2511.05765v1 Announce Type: new
Abstract: One of the oldest methods for constructing integrable Hamiltonian systems, proposed by Jacobi, recently is being presented as a novel St\"{a}ckel lift construction related with Haantjes geometry. It may cause some confusion.
toXiv_bot_toot
The Theory of Strategic Evolution: Games with Endogenous Players and Strategic Replicators
Kevin Vallier
https://arxiv.org/abs/2512.07901 https://arxiv.org/pdf/2512.07901 https://arxiv.org/html/2512.07901
arXiv:2512.07901v1 Announce Type: new
Abstract: This paper develops the Theory of Strategic Evolution, a general model for systems in which the population of players, strategies, and institutional rules evolve together. The theory extends replicator dynamics to settings with endogenous players, multi level selection, innovation, constitutional change, and meta governance. The central mathematical object is a Poiesis stack: a hierarchy of strategic layers linked by cross level gain matrices. Under small gain conditions, the system admits a global Lyapunov function and satisfies selection, tracking, and stochastic stability results at every finite depth. We prove that the class is closed under block extension, innovation events, heterogeneous utilities, continuous strategy spaces, and constitutional evolution. The closure theorem shows that no new dynamics arise at higher levels and that unrestricted self modification cannot preserve Lyapunov structure. The theory unifies results from evolutionary game theory, institutional design, innovation dynamics, and constitutional political economy, providing a general mathematical model of long run strategic adaptation.
toXiv_bot_toot
Parallel Neuron Groups in the Drosophila Brain
Robert Worden
https://arxiv.org/abs/2512.10525 https://arxiv.org/pdf/2512.10525 https://arxiv.org/html/2512.10525
arXiv:2512.10525v1 Announce Type: new
Abstract: The full connectome of an adult Drosophila enables a search for novel neural structures in the insect brain. I describe a new neural structure, called a Parallel Neuron Group (PNG). Two neurons are called parallel if they share a significant number of input neurons and output neurons. Most pairs of neurons in the Drosophila brain have very small parallel match. There are about twenty larger groups of neurons for which any pair of neurons in the group has a high match. These are the parallel groups. Parallel groups contain only about 1000 out of the 65,000 neurons in the brain, and have distinctive properties. There are groups in the right mushroom bodies, the antennal lobes, the lobula, and in two central neuropils (GNG and EB). Most parallel groups do not have lateral symmetry. A group usually has one major input neuron, which inputs to all the neurons in the group, and a small number of major output neurons. The major input and output neurons are laterally asymmetric. Parallel neuron groups present puzzles, such as: what does a group do, that could not be done by one larger neuron? Do all neurons in a group fire in synchrony, or do they perform different functions? Why are they laterally asymmetric? These may merit further investigation.
toXiv_bot_toot
Physics is simple only when analyzed locally
Matteo Luca Ruggiero
https://arxiv.org/abs/2511.07447 https://arxiv.org/pdf/2511.07447 https://arxiv.org/html/2511.07447
arXiv:2511.07447v1 Announce Type: new
Abstract: The definition of a reference frame in General Relativity is achieved through the construction of a congruence of time-like world-lines. In this framework, splitting techniques enable us to express physical phenomena in analogy with Special Relativity, thereby realizing the local description in terms of Minkowski spacetime in accordance with the equivalence principle. This approach holds promise for elucidating the foundational principles of relativistic gravitational physics, as it illustrates how its 4-dimensional mathematical model manifests in practical measurement processes conducted in both space and time. In addition, we show how, within this framework, the Newtonian gravitational force naturally emerges as an effect of the non-geodesic path of the reference frame.
toXiv_bot_toot
Transitivities of maps of generalized topological spaces
M. R. Ahmadi Zand, N. Baimani
https://arxiv.org/abs/2511.06241 https://arxiv.org/pdf/2511.06241 https://arxiv.org/html/2511.06241
arXiv:2511.06241v1 Announce Type: new
Abstract: In this work, we present several new findings regarding the concepts of orbit-transitivity, strict orbit-transitivity, $\omega$-transitivity, and $\mu$-open-set transitivity for self-maps on generalized topological spaces.
Let $(X,\mu)$ denote a generalized topological space. A point $x \in X$ is said to be \textit{quasi-$\mu$-isolated} if there exists a $\mu$-open set $U$ such that $x \in U$ and $i_\mu(U \setminus c_\mu(\{x\})) = \emptyset$. We prove that $x$ is a quasi-$\mu$-isolated point of $X$ precisely when there exists a $\mu$-dense subset $D$ of $X$ for which $x$ is a $\mu_D$-isolated point of $D$. Moreover, in the case where $X$ has no quasi-$\mu$-isolated points, we establish that a map $f: X \to X$ is orbit-transitive (or strictly orbit-transitive) if and only if it is $\omega$-transitive.
toXiv_bot_toot
Closed-string mirror symmetry for dimer models
Dahye Cho, Hansol Hong, Hyeongjun Jin, Sangwook Lee
https://arxiv.org/abs/2511.06699 https://arxiv.org/pdf/2511.06699 https://arxiv.org/html/2511.06699
arXiv:2511.06699v1 Announce Type: new
Abstract: For all punctured Riemann surfaces arising as mirror curves of toric Calabi--Yau threefolds, we show that their symplectic cohomology is isomorphic to the compactly supported Hochschild cohomology of the noncommutative Landau--Ginzburg model defined on the NCCR of the associated toric Gorenstein singularities. This mirror correspondence is established by analyzing the closed-open map with boundaries on certain combinatorially defined immersed Lagrangians in the Riemann surface, yielding a ring isomorphism. We give a detailed examination of the properties of this isomorphism, emphasizing its relationship to the singularity structure.
toXiv_bot_toot
Atomic and molecular systems for radiation thermometry
Stephen P. Eckel, Eric B. Norrgard, Christopher Holloway, Nikunjkumar Prajapati, Noah Schlossberger, Matthew Simons
https://arxiv.org/abs/2512.08668 https://arxiv.org/pdf/2512.08668 https://arxiv.org/html/2512.08668
arXiv:2512.08668v1 Announce Type: new
Abstract: Atoms and simple molecules are excellent candidates for new standards and sensors because they are both all identical and their properties are determined by the immutable laws of quantum physics. Here, we introduce the concept of building a standard and sensor of radiative temperature using atoms and molecules. Such standards are based on precise measurement of the rate at which blackbody radiation (BBR) either excites or stimulates emission for a given atomic transition. We summarize the recent results of two experiments while detailing the rate equation models required for their interpretation. The cold atom thermometer (CAT) uses a gas of laser cooled $^{85}$Rb Rydberg atoms to probe the BBR spectrum near 130~GHz. This primary, {\it i.e.}, not traceable to a measurement of like kind, temperature measurement currently has a total uncertainty of approximately 1~\%, with clear paths toward improvement. The compact blackbody radiation atomic sensor (CoBRAS) uses a vapour of $^{85}$Rb and monitors fluorescence from states that are either populated by BBR or populated by spontaneous emission to measure the blackbody spectrum near 24.5~THz. The CoBRAS has an excellent relative precision of $u(T)\approx 0.13$~K, with a clear path toward implementing a primary
toXiv_bot_toot
The Third Visual Pathway for Social Perception
David Pitcher
https://arxiv.org/abs/2512.09351 https://arxiv.org/pdf/2512.09351 https://arxiv.org/html/2512.09351
arXiv:2512.09351v1 Announce Type: new
Abstract: Influential models of primate visual cortex describe two functionally distinct pathways: a ventral pathway for object recognition and the dorsal pathway for spatial and action processing. However, recent human and non-human primate research suggests the existence of a third visual pathway projecting from early visual cortex through the motion-selective area V5/MT into the superior temporal sulcus (STS). Here we integrate anatomical, neuroimaging, and neuropsychological evidence demonstrating that this pathway specializes in processing dynamic social cues such as facial expressions, eye gaze, and body movements. This third pathway supports social perception by computing the actions and intentions of other people. These findings enhance our understanding of visual cortical organization and highlight the STS's critical role in social cognition, suggesting that visual processing encompasses a dedicated neural circuit for interpreting socially relevant motion and behavior.
toXiv_bot_toot
Geometric Interpretation of the Redshift Evolution of H_0(z)
Seokcheon Lee
https://arxiv.org/abs/2511.07454 https://arxiv.org/pdf/2511.07454 https://arxiv.org/html/2511.07454
arXiv:2511.07454v1 Announce Type: new
Abstract: Recent analyses of the Master Type Ia supernova (SN Ia) sample have revealed a mild redshift dependence in the inferred local Hubble parameter, often expressed as tilde{H}_0(z) = H_0 (1 z)^{-\alpha}, where \alpha quantifies possible departures from the standard cosmological time dilation relation. In this work, we show that such an empirical scaling can be interpreted as a purely geometric effect arising from a small, gauge-dependent normalization of cosmic time within the Robertson-Walker metric. This interpretation naturally unifies the observed redshift evolution of tilde{H}_0(z) and the corresponding deviation in SN Ia light-curve durations under a single geometric time-normalization framework. We demonstrate that this mapping leaves all background distances--linked to the Hubble radius in the general-relativistic frame--unchanged, while the apparent evolution in SN Ia luminosity distances arises from the redshift dependence of the Chandrasekhar mass. The result provides a unified and observationally consistent explanation of the mild Hubble-tension trend as a manifestation of the geometric structure of cosmic time rather than a modification of the expansion dynamics.
toXiv_bot_toot
A new proof of Poincar\'e-Miranda theorem based on the classification of one-dimensional manifolds
Xiao-Song Yang
https://arxiv.org/abs/2511.06828 https://arxiv.org/pdf/2511.06828 https://arxiv.org/html/2511.06828
arXiv:2511.06828v1 Announce Type: new
Abstract: This note gives a new elementary proof of Poincar\'e-Miranda theorem based on Sard's theorem and the simple classification of one-dimensional manifolds.
toXiv_bot_toot
Deformation quantisation of exact shifted symplectic structures, with an application to vanishing cycles
J. P. Pridham
https://arxiv.org/abs/2511.07602 https://arxiv.org/pdf/2511.07602 https://arxiv.org/html/2511.07602
arXiv:2511.07602v1 Announce Type: new
Abstract: We extend the author's and CPTVV's correspondence between shifted symplectic and Poisson structures to establish a correspondence between exact shifted symplectic structures and non-degenerate shifted Poisson structures with formal derivation, a concept generalising constructions by De Wilde and Lecomte. Our formulation is sufficiently general to encompass derived algebraic, analytic and $\mathcal{C}^{\infty}$ stacks, as well as Lagrangians and non-commutative generalisations. We also show that non-degenerate shifted Poisson structures with formal derivation carry unique self-dual deformation quantisations in any setting where the latter can be formulated.
One application is that for (not necessarily exact) $0$-shifted symplectic structures in analytic and $\mathcal{C}^{\infty}$ settings, it follows that the author's earlier parametrisations of quantisations are in fact independent of any choice of associator, and generalise Fedosov's parametrisation of quantisations for classical manifolds.
Our main application is to complex $(-1)$-shifted symplectic structures, showing that our unique quantisation of the canonical exact structure, a sheaf of twisted $BD_0$-algebras with derivation, gives rise to BBDJS's perverse sheaf of vanishing cycles, equipped with its monodromy operator.
toXiv_bot_toot
Travelling wave solutions of equations in the Burgers Hierarchy
Amitava Choudhuri, Modhan Mohan Panja, Supriya Chatterjee, Benoy Talukdar
https://arxiv.org/abs/2511.06333 https://arxiv.org/pdf/2511.06333 https://arxiv.org/html/2511.06333
arXiv:2511.06333v1 Announce Type: new
Abstract: We emphasize that construction of travelling wave solutions for partial differential equations is a problem of considerable interest and thus introduce a simple algebraic method to generate such solutions for equations in the Burgers hierarchy. Our method based on a judicious use of the well known Cole-Hopf transformation is found to work satisfactorily for higher Burgers equations for which the direct method of integration is inapplicable. For Burgers equation we clearly demonstrate how does the diffusion term in the equation counteract the nonlinearity to result in a smooth wave. We envisage a similar study for higher equations in the Buggers hierarchy and establish that (i) as opposed to the solution of the Burgers equation, the purely nonlinear terms of these equations support smooth solutions and more interestingly (ii) the complete solutions of all higher-order equations are identical.
toXiv_bot_toot
Selling Privacy in Blockchain Transactions
Georgios Chionas, Olga Gorelkina, Piotr Krysta, Rida Laraki
https://arxiv.org/abs/2512.08096 https://arxiv.org/pdf/2512.08096 https://arxiv.org/html/2512.08096
arXiv:2512.08096v1 Announce Type: new
Abstract: We study methods to enhance privacy in blockchain transactions from an economic angle. We consider mechanisms for privacy-aware users whose utility depends not only on the outcome of the mechanism but also negatively on the exposure of their economic preferences. Specifically, we study two auction-theoretic settings with privacy-aware users. First, we analyze an order flow auction, where a user auctions off to specialized agents, called searchers, the right to execute her transaction while maintaining a degree of privacy. We examine how the degree of privacy affects the revenue of the auction and, broadly, the net utility of the privacy-aware user. In this new setting, we describe the optimal auction, which is a sealed-bid auction. Subsequently, we analyze a variant of a Dutch auction in which the user gradually decreases the price and the degree of privacy until the transaction is sold. We compare the revenue of this auction to that of the optimal one as a function of the number of communication rounds. Then, we introduce a two-sided market - a privacy marketplace - with multiple users selling their transactions under their privacy preferences to multiple searchers. We propose a posted-price mechanism for the two-sided market that guarantees constant approximation of the optimal social welfare while maintaining incentive compatibility (from both sides of the market) and budget balance. This work builds on the emerging line of research that attempts to improve the performance of economic mechanisms by appending cryptographic primitives to them.
toXiv_bot_toot
Meta-learning three-factor plasticity rules for structured credit assignment with sparse feedback
Dimitra Maoutsa
https://arxiv.org/abs/2512.09366 https://arxiv.org/pdf/2512.09366 https://arxiv.org/html/2512.09366
arXiv:2512.09366v1 Announce Type: new
Abstract: Biological neural networks learn complex behaviors from sparse, delayed feedback using local synaptic plasticity, yet the mechanisms enabling structured credit assignment remain elusive. In contrast, artificial recurrent networks solving similar tasks typically rely on biologically implausible global learning rules or hand-crafted local updates. The space of local plasticity rules capable of supporting learning from delayed reinforcement remains largely unexplored. Here, we present a meta-learning framework that discovers local learning rules for structured credit assignment in recurrent networks trained with sparse feedback. Our approach interleaves local neo-Hebbian-like updates during task execution with an outer loop that optimizes plasticity parameters via \textbf{tangent-propagation through learning}. The resulting three-factor learning rules enable long-timescale credit assignment using only local information and delayed rewards, offering new insights into biologically grounded mechanisms for learning in recurrent circuits.
toXiv_bot_toot
Mathematical basis, phase transitions and singularities of (3 1)-dimensional phi4 scalar field model
Zhidong Zhang
https://arxiv.org/abs/2511.07439 https://arxiv.org/pdf/2511.07439 https://arxiv.org/html/2511.07439
arXiv:2511.07439v1 Announce Type: new
Abstract: The lambda phi4 scalar field model that can be applied to interpret pion-pion scattering and properties of hadrons. In this work, the mathematical basis, phase transitions and singularities of a (3 1)-dimensional (i.e., (3 1)D) phi4 scalar field model are investigated. It is found that as a specific example of topological quantum field theories, the (3 1)D phi4 scalar field model must be set up on the Jordan-von Neumann-Wigner framework and dealt with the parameter space of complex time (or complex temperature). The use of the time average and the topologic Lorentz transformation representing Reidemeister moves ensure the integrability, which takes into account for the contributions of nontrivial topological structures to physical properties of the many-body interacting system. The ergodic hypothesis is violated at finite temperatures in the (3 1)D phi4 scalar field model. Because the quantum field theories with ultraviolet cutoff can be mapped to the models in statistical mechanics, the (3 1)D phi4 scalar field model with ultraviolet cutoff is studied by inspecting its relation with the three-dimensional (3D) Ising model. Furthermore, the direct relation between the coupling K in the 3D Ising model and the bare coupling lambda0 in the (3 1)D phi4 scalar field model is determined in the strong coupling limit. The results obtained in the present work can be utilized to investigate thermodynamic physical properties and critical phenomena of quantum (scalar) field theories.
toXiv_bot_toot
Higher-dimensional Heegaard Floer homology and the polynomial representation of double affine Hecke algebras
Yuan Gao, Eilon Reisin-Tzur, Yin Tian, Tianyu Yuan
https://arxiv.org/abs/2511.06436 https://arxiv.org/pdf/2511.06436 https://arxiv.org/html/2511.06436
arXiv:2511.06436v1 Announce Type: new
Abstract: We show that the higher-dimensional Heegaard Floer homology between tuples of cotangent fibers and the conormal bundle of a homotopically nontrivial simple closed curve on $T^2$ recovers the polynomial representation of double affine Hecke algebra of type A. We also give a topological interpretation of Cherednik's inner product on the polynomial representation.
toXiv_bot_toot
A cold beam of BaOH molecules using a water-vapour seeded neon gas
Ties Hendrik Fikkers, Nithesh Balasubramanian, Joost W. F. van Hofslot, Maarten C. Mooij, Hendrick L. Bethlem, Steven Hoekstra
https://arxiv.org/abs/2512.08402 https://arxiv.org/pdf/2512.08402 https://arxiv.org/html/2512.08402
arXiv:2512.08402v1 Announce Type: new
Abstract: In this paper we report on the production and characterization of a cold beam of BaOH molecules using a cryogenic buffer-gas beam source. BaOH is a highly suitable molecule for studies of the violation of fundamental symmetries, such as the search for the electron's electric dipole moment. BaOH molecules are synthesised inside the cold source through laser ablation of a barium metal target while water vapor is seeded into the neon buffer gas. The BaOH flux is significantly enhanced ($\sim$11 times) when laser-exciting the barium atoms inside the buffer-gas cell on the $^1\mathrm S_0 - ^3\mathrm P_1$ transition. A similar enhancement has been reported for other alkaline-earth(-like) monohydroxides. For typical source conditions, the molecular beam has an average velocity of $\approx180$ m/s and an intensity of $\sim 10^{9}$ molecules s$^{-1}$ in $N=1$, which is comparable to that of cryogenic BaF beams.
toXiv_bot_toot
Non-Gravitational Acceleration in 3I ATLAS: Constraints on Exotic Volatile Outgassing in Interstellar Comets
Florian Neukart
https://arxiv.org/abs/2511.07450 https://arxiv.org/pdf/2511.07450 https://arxiv.org/html/2511.07450
arXiv:2511.07450v1 Announce Type: new
Abstract: The interstellar comet 3I/ATLAS exhibited a measurable nongravitational acceleration similar in form to that of 1I/'Oumuamua but of smaller magnitude. Using thermophysical and Monte Carlo models, we show that this acceleration can be fully explained by anisotropic outgassing of conventional volatiles, primarily CO and CO2, under realistic surface and rotational conditions. The model includes diurnal and obliquity-averaged energy balance, empirical vapor-pressure relations, and collimated jet emission from localized active regions. Mixed CO-CO2 compositions reproduce both the magnitude and direction of the observed acceleration with physically plausible active fractions below one percent for nucleus radii between 0.5 and 3 km. Less volatile species such as NH3 and CH4 underproduce thrust at equilibrium temperatures near 1 AU. These results eliminate the need for nonphysical or exotic explanations and define thermophysical limits for natural acceleration mechanisms in interstellar comets.
toXiv_bot_toot
Modeling, Segmenting and Statistics of Transient Spindles via Two-Dimensional Ornstein-Uhlenbeck Dynamics
C. Sun, D. Fettahoglu, D. Holcman
https://arxiv.org/abs/2512.10844 https://arxiv.org/pdf/2512.10844 https://arxiv.org/html/2512.10844
arXiv:2512.10844v1 Announce Type: new
Abstract: We develop here a stochastic framework for modeling and segmenting transient spindle- like oscillatory bursts in electroencephalogram (EEG) signals. At the modeling level, individ- ual spindles are represented as path realizations of a two-dimensional Ornstein{Uhlenbeck (OU) process with a stable focus, providing a low-dimensional stochastic dynamical sys- tem whose trajectories reproduce key morphological features of spindles, including their characteristic rise{decay amplitude envelopes. On the signal processing side, we propose a segmentation procedure based on Empirical Mode Decomposition (EMD) combined with the detection of a central extremum, which isolates single spindle events and yields a collection of oscillatory atoms. This construction enables a systematic statistical analysis of spindle features: we derive empirical laws for the distributions of amplitudes, inter-spindle intervals, and rise/decay durations, and show that these exhibit exponential tails consistent with the underlying OU dynamics. We further extend the model to a pair of weakly coupled OU processes with distinct natural frequencies, generating a stochastic mixture of slow, fast, and mixed spindles in random temporal order. The resulting framework provides a data- driven framework for the analysis of transient oscillations in EEG and, more generally, in nonstationary time series.
toXiv_bot_toot
Infinite-dimensional Lagrange-Dirac systems with boundary energy flow II: Field theories with bundle-valued forms
Fran\c{c}ois Gay-Balmaz, \'Alvaro Rodr\'iguez Abella, Hiroaki Yoshimura
https://arxiv.org/abs/2511.05687 https://arxiv.org/pdf/2511.05687 https://arxiv.org/html/2511.05687
arXiv:2511.05687v1 Announce Type: new
Abstract: Part I of this paper introduced the infinite dimensional Lagrange--Dirac theory for physical systems on the space of differential forms over a smooth manifold with boundary. This approach is particularly well-suited for systems involving energy exchange through the boundary, as it is built upon a restricted dual space -a vector subspace of the topological dual of the configuration space- that captures information about both the interior dynamics and boundary interactions. Consequently, the resulting dynamical equations naturally incorporate boundary energy flow. In this second part, the theory is extended to encompass vector-bundle-valued differential forms and non-Abelian gauge theories. To account for two commonly used forms of energy flux and boundary power densities, we introduce two distinct but equivalent formulations of the restricted dual. The results are derived from both geometric and variational viewpoints and are illustrated through applications to matter and gauge field theories. The interaction between gauge and matter fields is also addressed, along with the associated boundary conditions, applied to the case of the Yang-Mills-Higgs equations.
toXiv_bot_toot
#WritersCoffeeClub
6. Do you make use of unconventional punctuation?
7. Talk about a character from another's work that's stuck with you.
8. How do you keep yourself motivated?
---
6. Not much. I love my em dashes tho.
7. I dunno. At some point it was Motoko Kusanagi. Sylvanas Windrunner. Before Blizzard butchered her in WoW.
Oh, and April Ryan and …
I used to use this "Mesh on demand" website to find articles relevant to a specific abstract - but it doesn't seem to work anymore, or maybe it's just me? Anyone else has been using it recently?
https://meshb.nlm.nih.gov/MeSHonDemand
You just paste an abstract and click search, it take some tim…
Multi-agent learning under uncertainty: Recurrence vs. concentration
Kyriakos Lotidis, Panayotis Mertikopoulos, Nicholas Bambos, Jose Blanchet
https://arxiv.org/abs/2512.08132 https://arxiv.org/pdf/2512.08132 https://arxiv.org/html/2512.08132
arXiv:2512.08132v1 Announce Type: new
Abstract: In this paper, we examine the convergence landscape of multi-agent learning under uncertainty. Specifically, we analyze two stochastic models of regularized learning in continuous games -- one in continuous and one in discrete time with the aim of characterizing the long-run behavior of the induced sequence of play. In stark contrast to deterministic, full-information models of learning (or models with a vanishing learning rate), we show that the resulting dynamics do not converge in general. In lieu of this, we ask instead which actions are played more often in the long run, and by how much. We show that, in strongly monotone games, the dynamics of regularized learning may wander away from equilibrium infinitely often, but they always return to its vicinity in finite time (which we estimate), and their long-run distribution is sharply concentrated around a neighborhood thereof. We quantify the degree of this concentration, and we show that these favorable properties may all break down if the underlying game is not strongly monotone -- underscoring in this way the limits of regularized learning in the presence of persistent randomness and uncertainty.
toXiv_bot_toot
Allometric scaling of brain activity explained by avalanche criticality
Tiago S. A. N. Sim\~oes, Jos\'e S. Andrade Jr., Hans J. Herrmann, Stefano Zapperi, Lucilla de Arcangelis
https://arxiv.org/abs/2512.10834 https://arxiv.org/pdf/2512.10834 https://arxiv.org/html/2512.10834
arXiv:2512.10834v1 Announce Type: new
Abstract: Allometric scaling laws, such as Kleiber's law for metabolic rate, highlight how efficiency emerges with size across living systems. The brain, with its characteristic sublinear scaling of activity, has long posed a puzzle: why do larger brains operate with disproportionately lower firing rates? Here we show that this economy of scale is a universal outcome of avalanche dynamics. We derive analytical scaling laws directly from avalanche statistics, establishing that any system governed by critical avalanches must exhibit sublinear activity-size relations. This theoretical prediction is then verified in integrate-and-fire neuronal networks at criticality and in classical self-organized criticality models, demonstrating that the effect is not model-specific but generic. The predicted exponents align with experimental observations across mammal species, bridging dynamical criticality with the allometry of brain metabolism. Our results reveal avalanche criticality as a fundamental mechanism underlying Kleiber-like scaling in the brain.
toXiv_bot_toot
Einstein and Debye temperatures, electron-phonon coupling constant and a probable mechanism for ambient-pressure room-temperature superconductivity in intercalated graphite
E. F. Talantsev
https://arxiv.org/abs/2511.07460 https://arxiv.org/pdf/2511.07460 https://arxiv.org/html/2511.07460
arXiv:2511.07460v1 Announce Type: new
Abstract: Recently, Ksenofontov et al (arXiv:2510.03256) observed ambient pressure room-temperature superconductivity in graphite intercalated with lithium-based alloys with transition temperature (according to magnetization measurements) $T_c=330$ $K$. Here, I analyzed the reported temperature dependent resistivity data $\rho(T)$ in these graphite-intercalated samples and found that $\rho(T)$ is well described by the model of two series resistors, where each resistor is described as either an Einstein conductor or a Bloch-Gr\"uneisen conductor. Deduced Einstein and Debye temperatures are $\Theta_{E,1} \approx 250$ $K$ and $\Theta_{E,2} \approx 1,600$ $K$, and $\Theta_{D,1} \approx 300$ $K$ and $\Theta_{D,2} \approx 2,200$ $K$, respectively. Following the McMillan formalism, from the deduced $\Theta_{E,2}$ and $\Theta_{D,2}$, the electron-phonon coupling constant $\lambda_{e-ph} = 2.2 - 2.6$ was obtained. This value of $\lambda_{e-ph}$ is approximately equal to the value of $\lambda_{e-ph}$ in highly compressed superconducting hydrides. Based on this, I can propose that the observed room-temperature superconductivity in intercalated graphite is localized in nanoscale Sr-Ca-Li metallic flakes/particles, which adopt the phonon spectrum from the surrounding bulk graphite matrix, and as a result, conventional electron-phonon superconductivity arises in these nano-flakes/particles at room temperature. Experimental data reported by Ksenofontov et al (arXiv:2510.03256) on trapped magnetic flux decay in intercalated graphite samples supports the proposition.
toXiv_bot_toot
Incoherent repumping scheme in the $^{88}$Sr$^{ }$ five-level manifold
Valentin Martimort, Sacha Guesne, Derwell Drapier, Vincent Tugaye, Lilay Gros-Desormeaux, Valentin Cambier, Albane Douillet, Luca Guidoni, Jean-Pierre Likforman
https://arxiv.org/abs/2512.08710 https://arxiv.org/pdf/2512.08710 https://arxiv.org/html/2512.08710
arXiv:2512.08710v1 Announce Type: new
Abstract: Laser-cooled trapped ions are at the heart of modern quantum technologies and their cooling dynamics often deviate from the simplified two-level atom model. Doppler cooling of the $^{88}$Sr$^{ }$ ion involves several electronic levels and repumping channels that strongly influence fluorescence.In this work, we study a repumping scheme for the $^{88}$Sr$^{ }$ ion by combining precision single-ion spectroscopy with comprehensive numerical modeling based on optical Bloch equations including 18 Zeeman sublevels. We show that, although the observed fluorescence spectra retain a Lorentzian lineshape, their width and amplitude cannot be explained by a two-level atom description. Moreover, we find the optimal repumping conditions for maximizing the photon scattering rate.
toXiv_bot_toot
Moody Urbanity - In and Out of the Shadow II 👤
情绪化城市 - 阴影的内外 II 👤
📷 Nikon FE
🎞️ ERA 100, expired 1993
#filmphotography #Photography #blackandwhite
chloe orin – Awaking
#abstract
Prefrontal scaling of reward prediction error readout gates reinforcement-derived adaptive behavior in primates
Tian Sang, Yichun Huang, Fangwei Zhong, Miao Wang, Shiqi Yu, Jiahui Li, Yuanjing Feng, Yizhou Wang, Kwok Sze Chai, Ravi S. Menon, Meiyun Wang, Fang Fang, Zheng Wang
https://arxiv.org/abs/2512.09761 https://arxiv.org/pdf/2512.09761 https://arxiv.org/html/2512.09761
arXiv:2512.09761v1 Announce Type: new
Abstract: Reinforcement learning (RL) enables adaptive behavior across species via reward prediction errors (RPEs), but the neural origins of species-specific adaptability remain unknown. Integrating RL modeling, transcriptomics, and neuroimaging during reversal learning, we discovered convergent RPE signatures - shared monoaminergic/synaptic gene upregulation and neuroanatomical representations, yet humans outperformed macaques behaviorally. Single-trial decoding showed RPEs guided choices similarly in both species, but humans disproportionately recruited dorsal anterior cingulate (dACC) and dorsolateral prefrontal cortex (dlPFC). Cross-species alignment uncovered that macaque prefrontal circuits encode human-like optimal RPEs yet fail to translate them into action. Adaptability scaled not with RPE encoding fidelity, but with the areal extent of dACC/dlPFC recruitment governing RPE-to-action transformation. These findings resolve an evolutionary puzzle: behavioral performance gaps arise from executive cortical readout efficiency, not encoding capacity.
toXiv_bot_toot
Artist #BoramieSao will be visiting campus on January 24. We're putting up her painting that's part of our collection AND borrowing its companion piece as part of the exhibition "We, Too, Are Made of Wonders." The two paintings are mirror images, one dark, one light. Read on to learn a little more about the artist and her work.
Rapid plasticity of default-mode local network architectures following adult-onset blindness https://www.sciencedirect.com/science/article/pii/S2211124725014925 "adult-onset blindness rapidly and selectively modifies the stable default-mode local network archite…
Warm Inflation with the Standard Model: #cosmology
Robust equilibria in continuous games: From strategic to dynamic robustness
Kyriakos Lotidis, Panayotis Mertikopoulos, Nicholas Bambos, Jose Blanchet
https://arxiv.org/abs/2512.08138 https://arxiv.org/pdf/2512.08138 https://arxiv.org/html/2512.08138
arXiv:2512.08138v1 Announce Type: new
Abstract: In this paper, we examine the robustness of Nash equilibria in continuous games, under both strategic and dynamic uncertainty. Starting with the former, we introduce the notion of a robust equilibrium as those equilibria that remain invariant to small -- but otherwise arbitrary -- perturbations to the game's payoff structure, and we provide a crisp geometric characterization thereof. Subsequently, we turn to the question of dynamic robustness, and we examine which equilibria may arise as stable limit points of the dynamics of "follow the regularized leader" (FTRL) in the presence of randomness and uncertainty. Despite their very distinct origins, we establish a structural correspondence between these two notions of robustness: strategic robustness implies dynamic robustness, and, conversely, the requirement of strategic robustness cannot be relaxed if dynamic robustness is to be maintained. Finally, we examine the rate of convergence to robust equilibria as a function of the underlying regularizer, and we show that entropically regularized learning converges at a geometric rate in games with affinely constrained action spaces.
toXiv_bot_toot
Extended Call for Papers: Consequential Play – Theology, Video Games, & Culture
https://ift.tt/n6IHTMq
CFP: Consequential Play – Theology, Religion and Video Games Volume Editor: Trevor B. Williams…
via Input 4 RELCFP
Generalized discrete integrable operator and integrable hierarchy
Huan Liu
https://arxiv.org/abs/2511.05046 https://arxiv.org/pdf/2511.05046 https://arxiv.org/html/2511.05046
arXiv:2511.05046v1 Announce Type: new
Abstract: We introduce and systematically develop two classes of discrete integrable operators: those with $2\times 2$ matrix kernels and those possessing general differential kernels, thereby generalizing the discrete analogue previously studied. A central finding is their inherent connection to higher-order pole solutions of integrable hierarchies, contrasting sharply with standard operators linked to simple poles. This work not only provides explicit resolvent formulas for matrix kernels and differential operator analogues but also offers discrete integrable structures that encode higher-order behaviour.
toXiv_bot_toot
Beyond Revenue and Welfare: Counterfactual Analysis of Spectrum Auctions with Application to Canada's 3800MHz Allocation
Sara Jalili Shani, Kris Joseph, Michael B. McNally, James R. Wright
https://arxiv.org/abs/2512.08106 https://arxiv.org/pdf/2512.08106 https://arxiv.org/html/2512.08106
arXiv:2512.08106v1 Announce Type: new
Abstract: Spectrum auctions are the primary mechanism through which governments allocate scarce radio frequencies, with outcomes that shape competition, coverage, and innovation in telecommunications markets. While traditional models of spectrum auctions often rely on strong equilibrium assumptions, we take a more parsimonious approach by modeling bidders as myopic and straightforward: in each round, firms simply demand the bundle that maximizes their utility given current prices. Despite its simplicity, this model proves effective in predicting the outcomes of Canada's 2023 auction of 3800 MHz spectrum licenses. Using detailed round-by-round bidding data, we estimate bidders' valuations through a linear programming framework and validate that our model reproduces key features of the observed allocation and price evolution. We then use these estimated valuations to simulate a counterfactual auction under an alternative mechanism that incentivizes deployment in rural and remote regions, aligning with one of the key objectives set out in the Canadian Telecommunications Act. The results show that the proposed mechanism substantially improves population coverage in underserved areas. These findings demonstrate that a behavioral model with minimal assumptions is sufficient to generate reliable counterfactual predictions, making it a practical tool for policymakers to evaluate how alternative auction designs may influence future outcomes. In particular, our study demonstrates a method for counterfactual mechanism design, providing a framework to evaluate how alternative auction rules could advance policy goals such as equitable deployment across Canada.
toXiv_bot_toot
When I gave the keynote at SIGCOMM earlier this year it was recorded and I finally got around to posting it on Peertube: https://peertube.roundpond.net/w/no4sPs4xUxgGwMQvwMJrim
Talk abstract:
The bridge is one of the most common metaphors used in networking, which is …
Heute in "Faszinierendes Weltall",
Vortragsreihe des Förderkreis Planetarium Göttingen e.V.,
immer Dienstags um 19.30 Uhr im ZHG der Universität Göttingen, Platz der Göttinger Sieben, Hörsaal 008:
"Fantastische Nordlichter - Die Aurora Borealis über Norwegen und Göttingen"
htt…
Bound and Resonant States of Muonic Few-Body Coulomb Systems: Extended Stochastic Variational Approach
Liang-Zhen Wen, Shi-Lin Zhu
https://arxiv.org/abs/2512.07323 https://arxiv.org/pdf/2512.07323 https://arxiv.org/html/2512.07323
arXiv:2512.07323v1 Announce Type: new
Abstract: We compute the bound and resonant states of hydrogen-like muonic ions ($\mu\mu p$, $\mu\mu d$, $\mu\mu t$) and three-body muonic molecular ions ($pp\mu$, $pd\mu$, $pt\mu$, $dd\mu$, $dt\mu$, $tt\mu$), and the four-body double-muonic hydrogen molecule ($\mu\mu pp$) using an extended stochastic variational method combined with complex scaling. The approach provides a unified treatment of bound and quasibound states and achieves an energy accuracy better than $0.1~\mathrm{eV}$ across all systems studied. Complete spectra below the corresponding $n=2$ atomic thresholds are obtained, including several previously unresolved shallow resonances in both three- and four-body sectors.
toXiv_bot_toot
@… I’m playing catch-up on your weekly updates (you no longer shows in my feed or alerts even though I follow you, which is hella annoying and I still have to debug) and think you were messing with me by generating the abstract of my Atlass post with an LLM.
If so, well done and I’m sorry I’m just seeing it.
If not, then I guess I need bet…
Before I go writing my own, is anyone aware of a python package for solving employee scheduling type problems? Perhaps backed by Google's OR-Tools?
They have all the math covered, but the interface is a bit unwieldy. So I'd like to use or write something that is written with the domain in mind, not abstract optimization.
#LazyWeb
Optical clocks with accuracy validated at the 19th digit
K. J. Arnold, M. D. K. Lee, Zhao Qi, Qichen Qin, Zhang Zhao, N. Jayjong, M. D. Barrett
https://arxiv.org/abs/2512.07346 https://arxiv.org/pdf/2512.07346 https://arxiv.org/html/2512.07346
arXiv:2512.07346v1 Announce Type: new
Abstract: We report a comprehensive evaluation of all known sources of systematic uncertainty for two independent $^{176}$Lu$^ $ single-ion optical references, finding total systematic uncertainty of $1.1\times10^{-19}$ and $1.4\times10^{-19}$ for the two individual systems and $9.6\times10^{-20}$ for the difference. Through direct comparison via correlation spectroscopy, we demonstrate a relative frequency agreement of $-2.4\pm(5.7)_\mathrm{stat}\pm(1.0)_\mathrm{sys}\times10^{-19}$, where `stat' and `sys' indicate the statistical and systematic uncertainty, respectively. The comparison uncertainty is statistically limited after approximately 200 hours of averaging with a measurement instability of $4.8\times10^{-16}(\tau/\mathrm{s})^{-1/2}$.
toXiv_bot_toot
Multi state neurons
Robert Worden
https://arxiv.org/abs/2512.08815 https://arxiv.org/pdf/2512.08815 https://arxiv.org/html/2512.08815
arXiv:2512.08815v1 Announce Type: new
Abstract: Neurons, as eukaryotic cells, have powerful internal computation capabilities. One neuron can have many distinct states, and brains can use this capability. Processes of neuron growth and maintenance use chemical signalling between cell bodies and synapses, ferrying chemical messengers over microtubules and actin fibres within cells. These processes are computations which, while slower than neural electrical signalling, could allow any neuron to change its state over intervals of seconds or minutes. Based on its state, a single neuron can selectively de-activate some of its synapses, sculpting a dynamic neural net from the static neural connections of the brain. Without this dynamic selection, the static neural networks in brains are too amorphous and dilute to do the computations of neural cognitive models. The use of multi-state neurons in animal brains is illustrated in hierarchical Bayesian object recognition. Multi-state neurons may support a design which is more efficient than two-state neurons, and scales better as object complexity increases. Brains could have evolved to use multi-state neurons. Multi-state neurons could be used in artificial neural networks, to use a kind of non-Hebbian learning which is faster and more focused and controllable than traditional neural net learning. This possibility has not yet been explored in computational models.
toXiv_bot_toot
Looking for inspiration in the new year? A chance to rediscover wonder and connect with nature? Our big spring semester exhibition, "We, Too, Are Made of Wonders," opens January 24 and takes inspiration from a poem by Ada Limón currently traveling to Jupiter on the Europa Clipper space probe.
https://lnkd.in/eDfgFdp5
The Communication Complexity of Combinatorial Auctions with Additional Succinct Bidders
Frederick V. Qiu, S. Matthew Weinberg, Qianfan Zhang
https://arxiv.org/abs/2512.06585 https://arxiv.org/pdf/2512.06585 https://arxiv.org/html/2512.06585
arXiv:2512.06585v1 Announce Type: new
Abstract: We study the communication complexity of welfare maximization in combinatorial auctions with bidders from either a standard valuation class (which require exponential communication to explicitly state, such as subadditive or XOS), or arbitrary succinct valuations (which can be fully described in polynomial communication, such as single-minded). Although succinct valuations can be efficiently communicated, we show that additional succinct bidders have a nontrivial impact on communication complexity of classical combinatorial auctions. Specifically, let $n$ be the number of subadditive/XOS bidders. We show that for SA $\cup$ SC (the union of subadditive and succinct valuations): (1) There is a polynomial communication $3$-approximation algorithm; (2) As $n \to \infty$, there is a matching $3$-hardness of approximation, which (a) is larger than the optimal approximation ratio of $2$ for SA, and (b) holds even for SA $\cup$ SM (the union of subadditive and single-minded valuations); and (3) For all $n \geq 3$, there is a constant separation between the optimal approximation ratios for SA $\cup$ SM and SA (and therefore between SA $\cup$ SC and SA as well). Similarly, we show that for XOS $\cup$ SC: (1) There is a polynomial communication $2$-approximation algorithm; (2) As $n \to \infty$, there is a matching $2$-hardness of approximation, which (a) is larger than the optimal approximation ratio of $e/(e-1)$ for XOS, and (b) holds even for XOS $\cup$ SM; and (3) For all $n \geq 2$, there is a constant separation between the optimal approximation ratios for XOS $\cup$ SM and XOS (and therefore between XOS $\cup$ SC and XOS as well).
toXiv_bot_toot
Learning visual to auditory sensory substitution reveals flexibility in image to sound mapping https://www.nature.com/articles/s41539-025-00385-4 The vOICe
"Mapping pixel position onto spectral-temporal acoustic axes appears flexible, rather than anchored to cross-modal co…
State and Parameter Estimation for a Neural Model of Local Field Potentials
Daniele Avitabile, Gabriel J. Lord, Khadija Meddouni
https://arxiv.org/abs/2512.07842 https://arxiv.org/pdf/2512.07842 https://arxiv.org/html/2512.07842
arXiv:2512.07842v1 Announce Type: new
Abstract: The study of cortical dynamics during different states such as decision making, sleep and movement, is an important topic in Neuroscience. Modelling efforts aim to relate the neural rhythms present in cortical recordings to the underlying dynamics responsible for their emergence. We present an effort to characterize the neural activity from the cortex of a mouse during natural sleep, captured through local field potential measurements. Our approach relies on using a discretized Wilson--Cowan Amari neural field model for neural activity, along with a data assimilation method that allows the Bayesian joint estimation of the state and parameters. We demonstrate the feasibility of our approach on synthetic measurements before applying it to a dataset available in literature. Our findings suggest the potential of our approach to characterize the stimulus received by the cortex from other brain regions, while simultaneously inferring a state that aligns with the observed signal.
toXiv_bot_toot
Signals of Bursts from the Very Early Universe / Positron signal from the early Univere [sic!]: #universe.
Thermal one-loop self-energy correction for hydrogen-like systems: relativistic approach
M. Reiter, D. Solovyev, A. Bobylev, D. Glazov, T. Zalialiutdinov
https://arxiv.org/abs/2512.06828 https://arxiv.org/pdf/2512.06828 https://arxiv.org/html/2512.06828
arXiv:2512.06828v1 Announce Type: new
Abstract: Within a fully relativistic framework, the one-loop self-energy correction for a bound electron is derived and extended to incorporate the effects of external thermal radiation. In a series of previous works, it was shown that in quantum electrodynamics at finite temperature (QED), the description of effects caused by blackbody radiation can be reduced to using the thermal part of the photon propagator. As a consequence of the non-relativistic approximation in the calculation of the thermal one-loop self-energy correction, well-known quantum-mechanical (QM) phenomena emerge at successive orders: the Stark effect arises at leading order in $\alpha Z$, the Zeeman effect appears in the next-to-leading non-relativistic correction, accompanied by diamagnetic contributions and their relativistic refinements, among other perturbative corrections. The fully relativistic approach used in this work for calculating the SE contribution allows for accurate calculations of the thermal shift of atomic levels, in which all these effects are automatically taken into account. The hydrogen atom serves as the basis for testing a fully relativistic approach to such calculations. Additionally, an analysis is presented of the behavior of the thermal shift caused by the thermal one-loop correction to the self-energy of a bound electron for hydrogen-like ions with an arbitrary nuclear charge $Z$. The significance of these calculations lies in their relevance to contemporary high-precision experiments, where thermal radiation constitutes one of the major contributions to the overall uncertainty budget.
toXiv_bot_toot
Moody Urbanity - Old & New VI 🔆
情绪化城市 - 新与旧 VI 🔆
📷 Zeiss Ikon Super Ikonta 533/16
🎞️ Ilford HP5 Plus 400, expired 1993
#filmphotography #Photography #blackandwhite
On a variation of selective separability using ideals
Debraj Chandra, Nur Alam, Dipika Roy
https://arxiv.org/abs/2511.04049 https://arxiv.org/pdf/2511.04049 https://arxiv.org/html/2511.04049
arXiv:2511.04049v1 Announce Type: new
Abstract: A space $X$ is H-separable (Bella et al., 2009) if for every sequence $(Y_n)$ of dense subspaces of $X$ there exists a sequence $(F_n)$ such that for each $n$ $F_n$ is a finite subset of $Y_n$ and every nonempty open set of $X$ intersects $F_n$ for all but finitely many $n$. In this paper, we introduce and study an ideal variant of H-separability, called $\mathcal{I}$-H-separability.
toXiv_bot_toot
Manifolds and Modules: How Function Develops in a Neural Foundation Model
Johannes Bertram, Luciano Dyballa, T. Anderson Keller, Savik Kinger, Steven W. Zucker
https://arxiv.org/abs/2512.07869 https://arxiv.org/pdf/2512.07869 https://arxiv.org/html/2512.07869
arXiv:2512.07869v1 Announce Type: new
Abstract: Foundation models have shown remarkable success in fitting biological visual systems; however, their black-box nature inherently limits their utility for under- standing brain function. Here, we peek inside a SOTA foundation model of neural activity (Wang et al., 2025) as a physiologist might, characterizing each 'neuron' based on its temporal response properties to parametric stimuli. We analyze how different stimuli are represented in neural activity space by building decoding man- ifolds, and we analyze how different neurons are represented in stimulus-response space by building neural encoding manifolds. We find that the different processing stages of the model (i.e., the feedforward encoder, recurrent, and readout modules) each exhibit qualitatively different representational structures in these manifolds. The recurrent module shows a jump in capabilities over the encoder module by 'pushing apart' the representations of different temporal stimulus patterns; while the readout module achieves biological fidelity by using numerous specialized feature maps rather than biologically plausible mechanisms. Overall, we present this work as a study of the inner workings of a prominent neural foundation model, gaining insights into the biological relevance of its internals through the novel analysis of its neurons' joint temporal response patterns.
toXiv_bot_toot
Zero Carbon V2X Tariffs for Non-Domestic Customers
Elisheva S Shamash, Zhong Fan
https://arxiv.org/abs/2512.07308 https://arxiv.org/pdf/2512.07308 https://arxiv.org/html/2512.07308
arXiv:2512.07308v1 Announce Type: new
Abstract: With the aim of meeting the worlds net-zero objectives, electricity trading through contractual agreements is becoming increasingly relevant in global and local energy markets. We develop contracts enabling efficient energy trading using Vehicle to Everything technology which can be applied to regulate energy markets and reduce costs and carbon emissions by using electric vehicles with bidirectional batteries to store energy during offpeak hours for export during peak hours. We introduce a contract based on the VCG mechanism which enables fleets of electric vehicles to export electricity to the grid efficiently throughout the day, where each electric vehicle has its energy consumption and exporting schedules and costs.
toXiv_bot_toot
Concrete sculpture in Cornell's Arboretum with a spectacular fall color tree behind it
#photo #photography #trees #fall
Determination of nuclear quadrupole moments of $^{25}$Mg, $^{87}$Sr, and $^{135,137}$Ba via configuration-interaction plus coupled-cluster approach
Yong-Bo Tang
https://arxiv.org/abs/2512.07603 https://arxiv.org/pdf/2512.07603 https://arxiv.org/html/2512.07603
arXiv:2512.07603v1 Announce Type: new
Abstract: Using the configuration-interaction plus coupled-cluster approach, we calculate the electric-field gradients $q$ for the low-lying states of alkaline-earth atoms, including magnesium (Mg), strontium (Sr), and barium (Ba). These low-lying states specifically include the $3s3p~^3\!P_{1,2}$ states of Mg; the $5s4d~^1\!D_{2}$ and $5s5p~^3\!P_{1,2}$ states of Sr; as well as the $6s5d~^3\!D_{1,2,3}$, $6s5d~^1\!D_{2}$, and $6s6p~^1\!P_{1}$ states of Ba. By combining the measured electric quadrupole hyperfine-structure constants of these states, we accurately determine the nuclear quadrupole moments of $^{25}$Mg, $^{87}$Sr, and $^{135,137}$Ba. These results are compared with the available data. The comparison shows that our nuclear quadrupole moment of $^{25}$Mg is in perfect agreement with the result from the mesonic X-ray experiment. However, there are approximately 10\% and 4\% differences between our results and the currently adopted values [Pyykk$\rm \ddot{o}$, Mol. Phys. 116, 1328(2018)] for the nuclear quadrupole moments of $^{87}$Sr and $^{135,137}$Ba respectively. Moreover, we also calculate the magnetic dipole hyperfine-structure constants of these states, and the calculated results exhibit good agreement with the measured data.
toXiv_bot_toot
Revised comment on the paper titled "The Origin of Quantum Mechanical Statistics: Insights from Research on Human Language
Miko{\l}aj Sienicki, Krzysztof Sienicki
https://arxiv.org/abs/2512.07881 https://arxiv.org/pdf/2512.07881 https://arxiv.org/html/2512.07881
arXiv:2512.07881v1 Announce Type: new
Abstract: This short note comments on \citet{Aerts2024Origin}, which proposes that ranked word frequencies in texts should be read through the lens of Bose--Einstein (BE) statistics and even used to illuminate the origin of quantum statistics in physics. The core message here is modest: the paper offers an interesting analogy and an eye-catching fit, but several key steps mix physical claims with definitions and curve-fitting choices. We highlight three such points: (i) a normalization issue that is presented as "bosonic enhancement", (ii) an identification of rank with energy that makes the BE fit only weakly diagnostic of an underlying mechanism, and (iii) a baseline comparison that is too weak to support an ontological conclusion. We also briefly flag a few additional concerns (interpretation drift, parameter semantics, and reproducibility).
toXiv_bot_toot
Strategic Experimentation with Private Payoffs
J\'er\^ome Renault, Eilon Solan, Nicolas Vieille
https://arxiv.org/abs/2512.06180 https://arxiv.org/pdf/2512.06180 https://arxiv.org/html/2512.06180
arXiv:2512.06180v1 Announce Type: new
Abstract: We study a strategic experimentation game with exponential bandits, in which experiment outcomes are private. The equilibrium amount of experimentation is always higher than in the benchmark case where experiment outcomes are publicly observed. In addition, for pure equilibria, the equilibrium amount of experimentation is at least socially optimal, and possibly higher. We provide a tight bound on the degree of over-experimentation. The analysis rests on a new form of encouragement effect, according to which a player may hide the absence of a success to encourage future experimentation by the other player, which incentivizes current experimentation.
toXiv_bot_toot
On a variation of selective separability: S-separability
Debraj Chandra, Nur Alam, Dipika Roy
https://arxiv.org/abs/2511.04059 https://arxiv.org/pdf/2511.04059 https://arxiv.org/html/2511.04059
arXiv:2511.04059v1 Announce Type: new
Abstract: A space $X$ is M-separable (selectively separable) (Scheepers, 1999; Bella et al., 2009) if for every sequence $(Y_n)$ of dense subspaces of $X$ there exists a sequence $(F_n)$ such that for each $n$ $F_n$ is a finite subset of $Y_n$ and $\cup_{n\in \mathbb{N}} F_n$ is dense in $X$. In this paper, we introduce and study a strengthening of M-separability situated between H- and M-separability, which we call S-separability: for every sequence $(Y_n)$ of dense subspaces of $X$ there exists a sequence $(F_n)$ such that for each $n$ $F_n$ is a finite subset of $Y_n$ and for each finite family $\mathcal F$ of nonempty open sets of $X$ some $n$ satisfies $U\cap F_n\neq\emptyset$ for all $U\in \mathcal F$.
toXiv_bot_toot
Extended Call for Papers: Consequential Play – Theology, Video Games, & Culture
https://ift.tt/CEl472r
CFP: Consequential Play – Theology, Religion and Video Games Volume Editor: Trevor B. Williams…
via Input 4 RELCFP
Learning Paths to Multi-Sector Equilibrium: Belief Dynamics Under Uncertain Returns to Scale
Stefano Nasini, Rabia Nessah, Bertrand Wigniolle
https://arxiv.org/abs/2512.07013 https://arxiv.org/pdf/2512.07013 https://arxiv.org/html/2512.07013
arXiv:2512.07013v1 Announce Type: new
Abstract: This paper explores the dynamics of learning in a multi-sector general equilibrium model where firms operate under incomplete information about their production returns to scale. Firms iteratively update their beliefs using maximum a-posteriori estimation, derived from observed production outcomes, to refine their knowledge of their returns to scale. The implications of these learning dynamics for market equilibrium and the conditions under which firms can effectively learn their true returns to scale are the key objects of this study. Our results shed light on how idiosyncratic shocks influence the learning process and demonstrate that input decisions encode all pertinent information for belief updates. Additionally, we show that a long-memory (path-dependent) learning which keeps track of all past estimations ends up having a worse performance than a short-memory (path-independent) approach.
toXiv_bot_toot
Certain results on selection principles associated with bornological structure in topological spaces
Debraj Chandra, Subhankar Das, Nur Alam
https://arxiv.org/abs/2511.04038 https://arxiv.org/pdf/2511.04038 https://arxiv.org/html/2511.04038
arXiv:2511.04038v1 Announce Type: new
Abstract: We study selection principles related to bornological covers in a topological space $X$ following the work of Aurichi et al., 2019, where selection principles have been investigated in the function space $C_\mathfrak{B}(X)$ endowed with the topology $\tau_\mathfrak{B}$ of uniform convergence on bornology $\mathfrak{B}$. We show equivalences among certain selection principles and present some game theoretic observations involving bornological covers. We investigate selection principles on the product space $X^n$ equipped with the product bornolgy $\mathfrak{B}^n$, $n\in \omega$. Considering the cardinal invariants such as the unbounding number ($\mathfrak{b}$), dominating numbers ($\mathfrak{d}$), pseudointersection numbers ($\mathfrak{p}$) etc., we establish connections between the cardinality of base of a bornology with certain selection principles. Finally, we investigate some variations of the tightness properties of $C_\mathfrak{B}(X)$ and present their characterizations in terms of selective bornological covering properties of $X$.
toXiv_bot_toot
Analysis of collision shift assessments in ion-based clocks
M. D. Barrett, K. J. Arnold
https://arxiv.org/abs/2512.05474 https://arxiv.org/pdf/2512.05474 https://arxiv.org/html/2512.05474
arXiv:2512.05474v1 Announce Type: new
Abstract: We consider back-ground gas collision shifts in ion-based clocks. We give both a classical and quantum description of a collision between an ion and a polarizable particle with a simple hard-sphere repulsion. Both descriptions give consistent results, which shows that a collision shift bound is determined by the classical Langevin collision rate reduced by a readily calculated factor describing the decoupling of the clock laser from the ion due to the recoil motion. We also show that the result holds when using a more general Lennard-Jones potential to describe the interaction between the ion and its collision partner. This leads to a simple bound for the collision shift applicable to any single ion clock without resorting to large-scale Monte-Carlo simulations or determination of molecular potential energy curves describing the collision. It also provides a relatively straightforward means to measure the relevant collision rate.
toXiv_bot_toot
Two-Dimensional Finite-Gap Schrodinger Operators as Limits of Two-Dimensional Integrable Difference Operators
P. A. Leonchik, G. S. Mauleshova, A. E. Mironov
https://arxiv.org/abs/2511.03805 https://arxiv.org/pdf/2511.03805 https://arxiv.org/html/2511.03805
arXiv:2511.03805v1 Announce Type: new
Abstract: In this paper we study two-dimensional discrete operators whose eigenfunctions at zero energy level are given by rational functions on spectral curves. We extend discrete operators to difference operators and show that two-dimensional finite-gap Schrodinger operators at fixed energy level can be obtained from difference operators by passage to the limit.
toXiv_bot_toot
Microwave electrometry with quantum-limited resolutions in a Rydberg atom array
Yao-Wen Zhang, De-Sheng Xiang, Ren Liao, Hao-Xiang Liu, Biao Xu, Peng Zhou, Yijia Zhou, Kuan Zhang, Lin Li
https://arxiv.org/abs/2512.05413 https://arxiv.org/pdf/2512.05413 https://arxiv.org/html/2512.05413
arXiv:2512.05413v1 Announce Type: new
Abstract: Microwave (MW) field sensing is foundational to modern technology, yet its evolution, reliant on classical antennas, is constrained by fundamental physical limits on field, temporal, and spatial resolutions. Here, we demonstrate an MW electrometry that simultaneously surpasses these constraints by using individual Rydberg atoms in an optical tweezer array as coherent sensors. This approach achieves a field sensitivity within 13% of the standard quantum limit, a response time that exceeds the Chu limit by more than 11 orders of magnitude, and in-situ near-field mapping with {\lambda}/3000 spatial resolution. This work establishes Rydberg-atom arrays as a powerful platform that unites quantum-limited sensitivity, nanosecond-scale response time, and sub-micrometer resolution, opening new avenues in quantum metrology and precision electromagnetic field imaging.
toXiv_bot_toot
Evaluation of lipid nanoparticles as vehicles for optogenetic delivery in primary cortical neurons #optogenetics, gene therapy without viruses;
Urban Mirage II 👁️🗨️
城市幻境 II 👁️🗨️
📷 Nikon F4E
🎞️ Ilford HP5 Plus 400, expired 1993
#filmphotography #Photography #blackandwhite
Correlation of Rankings in Matching Markets
R\'emi Castera, Patrick Loiseau, Bary S. R. Pradelski
https://arxiv.org/abs/2512.05304 https://arxiv.org/pdf/2512.05304 https://arxiv.org/html/2512.05304
arXiv:2512.05304v1 Announce Type: new
Abstract: We study the role of correlation in matching markets, where multiple decision-makers simultaneously face selection problems from the same pool of candidates. We propose a model in which a candidate's priority scores across different decision-makers exhibit varying levels of correlation dependent on the candidate's sociodemographic group. Such differential correlation can arise in school choice due to the varying prevalence of selection criteria, in college admissions due to test-optional policies, or due to algorithmic monoculture, that is, when decision-makers rely on the same algorithms and data sets to evaluate candidates. We show that higher correlation for one of the groups generally improves the outcome for all groups, leading to higher efficiency. However, students from a given group are more likely to remain unmatched as their own correlation level increases. This implies that it is advantageous to belong to a low-correlation group. Finally, we extend the tie-breaking literature to multiple priority classes and intermediate levels of correlation. Overall, our results point to differential correlation as a previously overlooked systemic source of group inequalities in school, university, and job admissions.
toXiv_bot_toot
Nuclear spin quenching of the $^2S_{1/2}\rightarrow {^2}F_{7/2} $ electric octupole transition in $^{173}$Yb$^ $
Jialiang Yu, Anand Prakash, Clara Zyskind, Ikbal A. Biswas, Rattakorn Kaewuam, Piyaphat Phoonthong, Tanja E. Mehlst\"aubler
https://arxiv.org/abs/2512.05872 https://arxiv.org/pdf/2512.05872 https://arxiv.org/html/2512.05872
arXiv:2512.05872v1 Announce Type: new
Abstract: We report the coherent excitation of the highly forbidden $^2S_{1/2} \rightarrow {^2}F_{7/2}$ clock transition in the odd isotope $^{173}\mathrm{Yb}^ $ with nuclear spin $I = 5/2$, and reveal the hyperfine-state-dependent, nuclear spin induced quenching of this transition. The inferred lifetime of the $F_e = 4$ hyperfine state is one order of magnitude shorter than the unperturbed ${^2}F_{7/2}$ clock state of $^{171}\mathrm{Yb}^ $. This reduced lifetime lowers the required optical power for coherent excitation of the clock transition, thereby reducing the AC Stark shift caused by the clock laser. Using a 3-ion Coulomb crystal, we experimentally demonstrate an approximately 20-fold suppression of the AC Stark shift, a critical improvement for the scalability of future multi-ion $\mathrm{Yb}^ $ clocks. Furthermore, we report the $|^2S_{1/2},F_g=3\rangle~\rightarrow~|^2F_{7/2},F_e=6\rangle$ unquenched reference transition frequency as $642.11917656354(43)$ THz, along with the measured hyperfine splitting and calculated quadratic Zeeman sensitivities of the ${^2}F_{7/2}$ clock state. Our results pave the way toward multi-ion optical clocks and quantum computers based on $^{173}\mathrm{Yb}^ $.
toXiv_bot_toot
I never got far from the wood stove today but a few days ago I spotted this snag covered with fungi near the high spot in Shindagin Hollow State Forest
#photo #photography #forest
Robust forecast aggregation via additional queries
Rafael Frongillo, Mary Monroe, Eric Neyman, Bo Waggoner
https://arxiv.org/abs/2512.05271 https://arxiv.org/pdf/2512.05271 https://arxiv.org/html/2512.05271
arXiv:2512.05271v1 Announce Type: new
Abstract: We study the problem of robust forecast aggregation: combining expert forecasts with provable accuracy guarantees compared to the best possible aggregation of the underlying information. Prior work shows strong impossibility results, e.g. that even under natural assumptions, no aggregation of the experts' individual forecasts can outperform simply following a random expert (Neyman and Roughgarden, 2022).
In this paper, we introduce a more general framework that allows the principal to elicit richer information from experts through structured queries. Our framework ensures that experts will truthfully report their underlying beliefs, and also enables us to define notions of complexity over the difficulty of asking these queries. Under a general model of independent but overlapping expert signals, we show that optimal aggregation is achievable in the worst case with each complexity measure bounded above by the number of agents $n$. We further establish tight tradeoffs between accuracy and query complexity: aggregation error decreases linearly with the number of queries, and vanishes when the "order of reasoning" and number of agents relevant to a query is $\omega(\sqrt{n})$. These results demonstrate that modest extensions to the space of expert queries dramatically strengthen the power of robust forecast aggregation. We therefore expect that our new query framework will open up a fruitful line of research in this area.
toXiv_bot_toot
Strategyproof Tournament Rules for Teams with a Constant Degree of Selfishness
David Pennock, Daniel Schoepflin, Kangning Wang
https://arxiv.org/abs/2512.05235 https://arxiv.org/pdf/2512.05235 https://arxiv.org/html/2512.05235
arXiv:2512.05235v1 Announce Type: new
Abstract: We revisit the well-studied problem of designing fair and manipulation-resistant tournament rules. In this problem, we seek a mechanism that (probabilistically) identifies the winner of a tournament after observing round-robin play among $n$ teams in a league. Such a mechanism should satisfy the natural properties of monotonicity and Condorcet consistency. Moreover, from the league's perspective, the winner-determination tournament rule should be strategyproof, meaning that no team can do better by losing a game on purpose.
Past work considered settings in which each team is fully selfish, caring only about its own probability of winning, and settings in which each team is fully selfless, caring only about the total winning probability of itself and the team to which it deliberately loses. More recently, researchers considered a mixture of these two settings with a parameter $\lambda$. Intermediate selfishness $\lambda$ means that a team will not lose on purpose unless its pair gains at least $\lambda s$ winning probability, where $s$ is the individual team's sacrifice from its own winning probability. All of the dozens of previously known tournament rules require $\lambda = \Omega(n)$ to be strategyproof, and it has been an open problem to find such a rule with the smallest $\lambda$.
In this work, we make significant progress by designing a tournament rule that is strategyproof with $\lambda = 11$. Along the way, we propose a new notion of multiplicative pairwise non-manipulability that ensures that two teams cannot manipulate the outcome of a game to increase the sum of their winning probabilities by more than a multiplicative factor $\delta$ and provide a rule which is multiplicatively pairwise non-manipulable for $\delta = 3.5$.
toXiv_bot_toot
On Dynamic Programming Theory for Leader-Follower Stochastic Games
Jilles Steeve Dibangoye, Thibaut Le Marre, Ocan Sankur, Fran\c{c}ois Schwarzentruber
https://arxiv.org/abs/2512.05667 https://arxiv.org/pdf/2512.05667 https://arxiv.org/html/2512.05667
arXiv:2512.05667v1 Announce Type: new
Abstract: Leader-follower general-sum stochastic games (LF-GSSGs) model sequential decision-making under asymmetric commitment, where a leader commits to a policy and a follower best responds, yielding a strong Stackelberg equilibrium (SSE) with leader-favourable tie-breaking. This paper introduces a dynamic programming (DP) framework that applies Bellman recursion over credible sets-state abstractions formally representing all rational follower best responses under partial leader commitments-to compute SSEs. We first prove that any LF-GSSG admits a lossless reduction to a Markov decision process (MDP) over credible sets. We further establish that synthesising an optimal memoryless deterministic leader policy is NP-hard, motivating the development of {\epsilon}-optimal DP algorithms with provable guarantees on leader exploitability. Experiments on standard mixed-motive benchmarks-including security games, resource allocation, and adversarial planning-demonstrate empirical gains in leader value and runtime scalability over state-of-the-art methods.
toXiv_bot_toot
Invariant Price of Anarchy: a Metric for Welfarist Traffic Control
Ilia Shilov, Mingjia He, Heinrich H. Nax, Emilio Frazzoli, Gioele Zardini, Saverio Bolognani
https://arxiv.org/abs/2512.05843 https://arxiv.org/pdf/2512.05843 https://arxiv.org/html/2512.05843
arXiv:2512.05843v1 Announce Type: new
Abstract: The Price of Anarchy (PoA) is a standard metric for quantifying inefficiency in socio-technical systems, widely used to guide policies like traffic tolling. Conventional PoA analysis relies on exact numerical costs. However, in many settings, costs represent agents' preferences and may be defined only up to possibly arbitrary scaling and shifting, representing informational and modeling ambiguities. We observe that while such transformations preserve equilibrium and optimal outcomes, they change the PoA value. To resolve this issue, we rely on results from Social Choice Theory and define the Invariant PoA. By connecting admissible transformations to degrees of comparability of agents' costs, we derive the specific social welfare functions which ensure that efficiency evaluations do not depend on arbitrary rescalings or translations of individual costs. Case studies on a toy example and the Zurich network demonstrate that identical tolling strategies can lead to substantially different efficiency estimates depending on the assumed comparability. Our framework thus demonstrates that explicit axiomatic foundations are necessary in order to define efficiency metrics and to appropriately guide policy in large-scale infrastructure design robustly and effectively.
toXiv_bot_toot
Exploring vibronic dynamics near a sloped conical intersection with trapped Rydberg ions
Abdessamad Belfakir, Weibin Li
https://arxiv.org/abs/2512.04941 https://arxiv.org/pdf/2512.04941 https://arxiv.org/html/2512.04941
arXiv:2512.04941v1 Announce Type: new
Abstract: We study spin-phonon coupled dynamics in the vicinity of a sloped conical intersection created by laser coupling the electronic (spin) and vibrational degrees of freedom of a pair of trapped Rydberg ions. We show that the shape of the potential energy surfaces can be engineered and controlled by exploiting the sideband transitions of the crystal vibration and dipole-dipole interactions between Rydberg ions in the Lamb-Dicke regime. Using the sideband transition, we realize a sloped conical intersection whose cone axis is only tilted along one spatial axis. When the phonon wavepacket is located in the potential minimum of the lower potential surface, the spin and phonon dynamics are largely frozen owing to the geometric phase effect. When starting from the upper potential surface, the electronic and phonon states tunnel to the lower potential surface, leading to a partial revival of the initial state. In contrast, the dynamics drastically change when the initial wavepackets are away from the conical intersection. The initial state is revived, and is almost entirely irrelevant to whether it is from the lower or upper potential surface. Complete Rabi oscillations of the adiabatic states are found when the wavepacket is initialized on the upper potential surface. The dynamics occur on the microsecond and nanometer scales, implying that Rydberg ions provide a platform for simulating nonadiabatic processes in the vicinity of a sloped conical intersection.
toXiv_bot_toot
 @arXiv_qbioNC_bot@mastoxiv.page
@arXiv_qbioNC_bot@mastoxiv.page