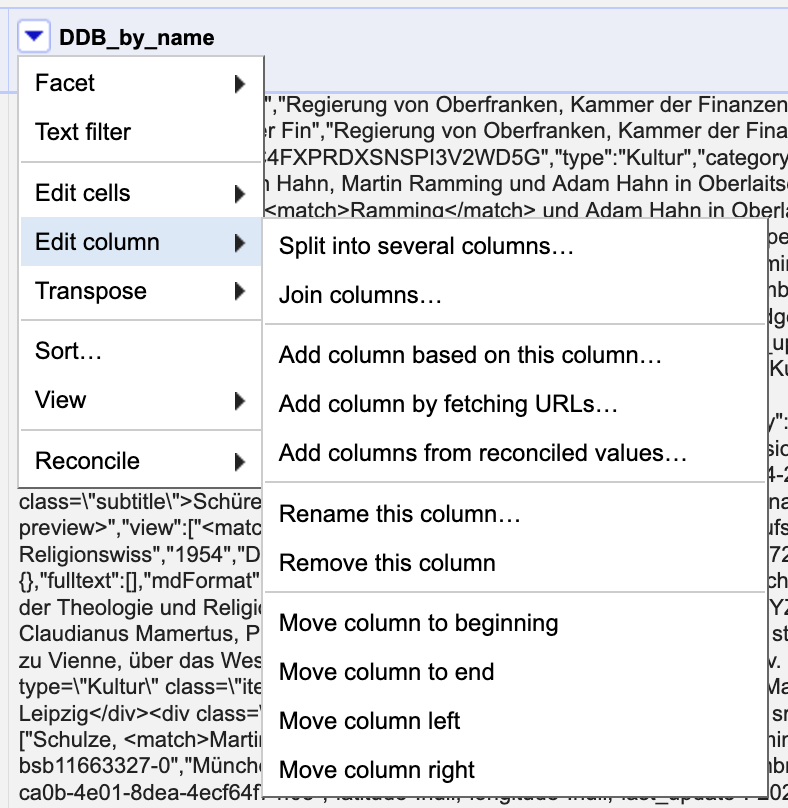
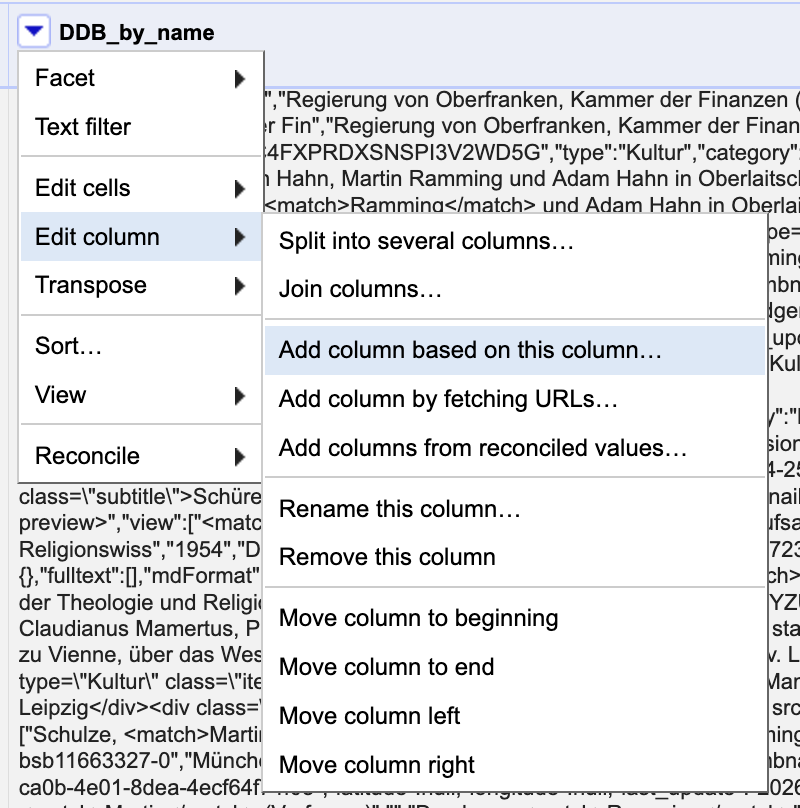
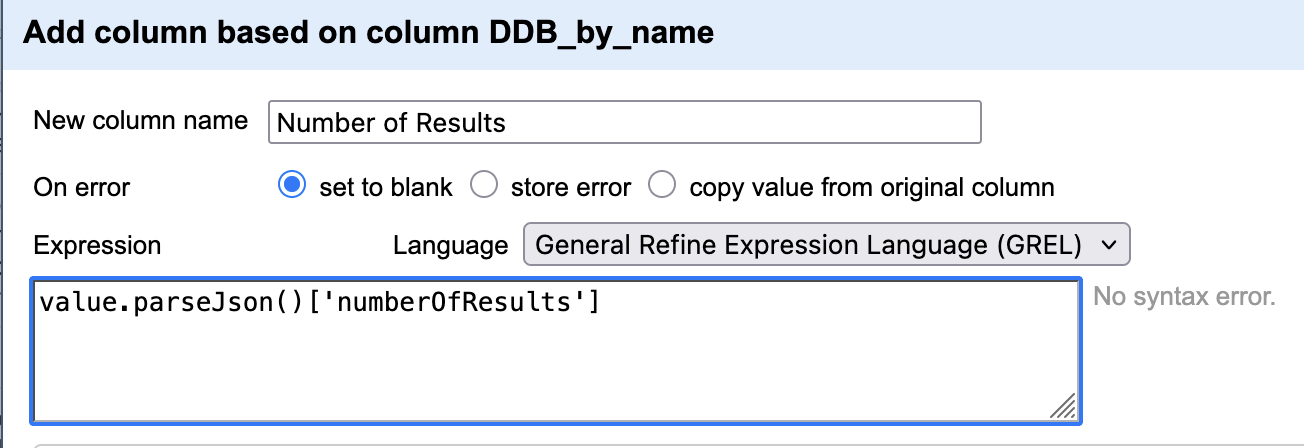
@rasterweb@mastodon.social
@rasterweb@mastodon.social2026-02-19 03:24:36
Did you miss one of the Web414 meetings in 2007? Looks like we recorded them!
#mke
@rasterweb@mastodon.socialDid you miss one of the Web414 meetings in 2007? Looks like we recorded them!
#mke
 @bourgwick@heads.social
@bourgwick@heads.social @seav@en.osm.town
@seav@en.osm.townDone mapping all 25 #barangays of Minalabac, Camarines Sur, #Philippines 🇵🇭 in #OpenStreetMap, creating/updating their #Wikidata
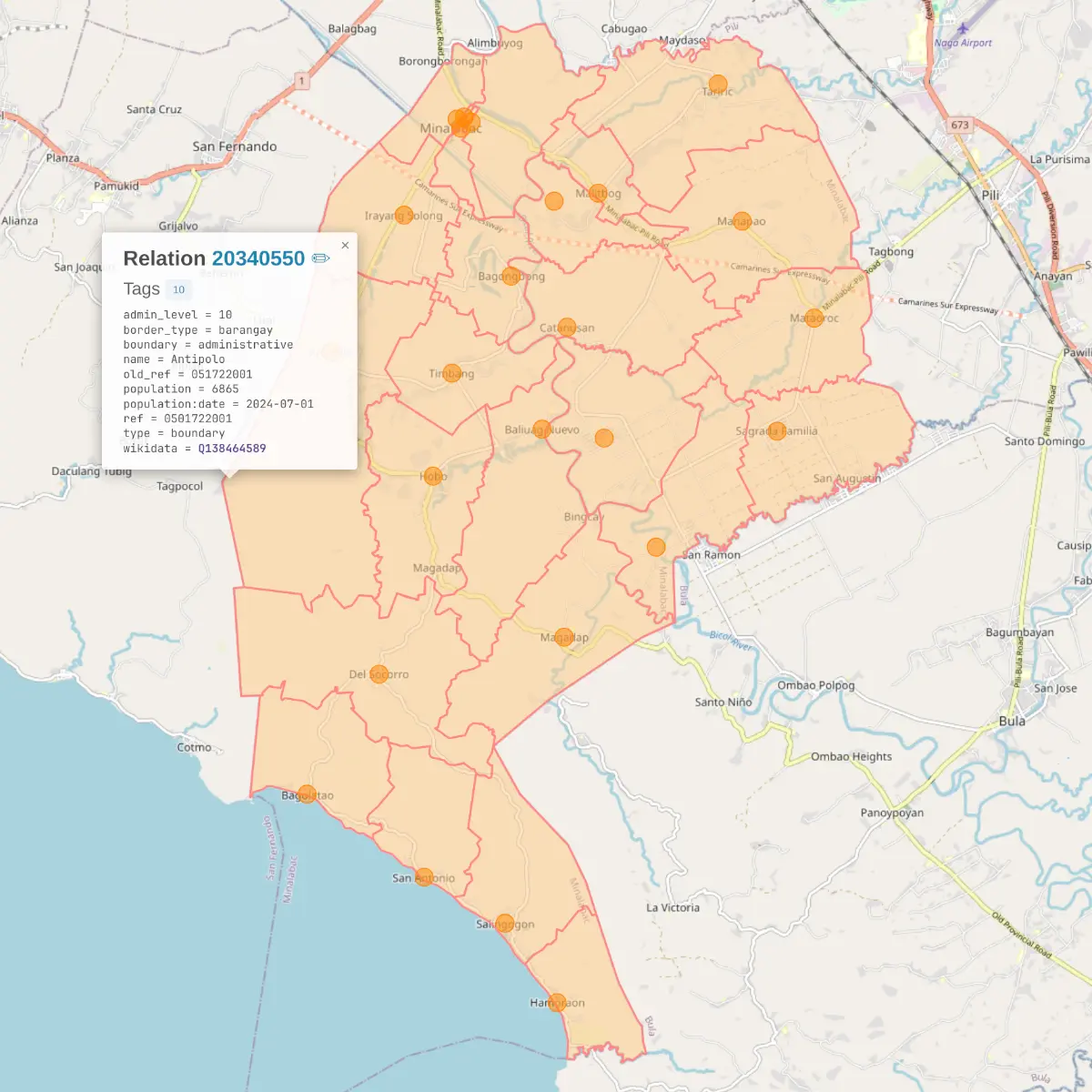
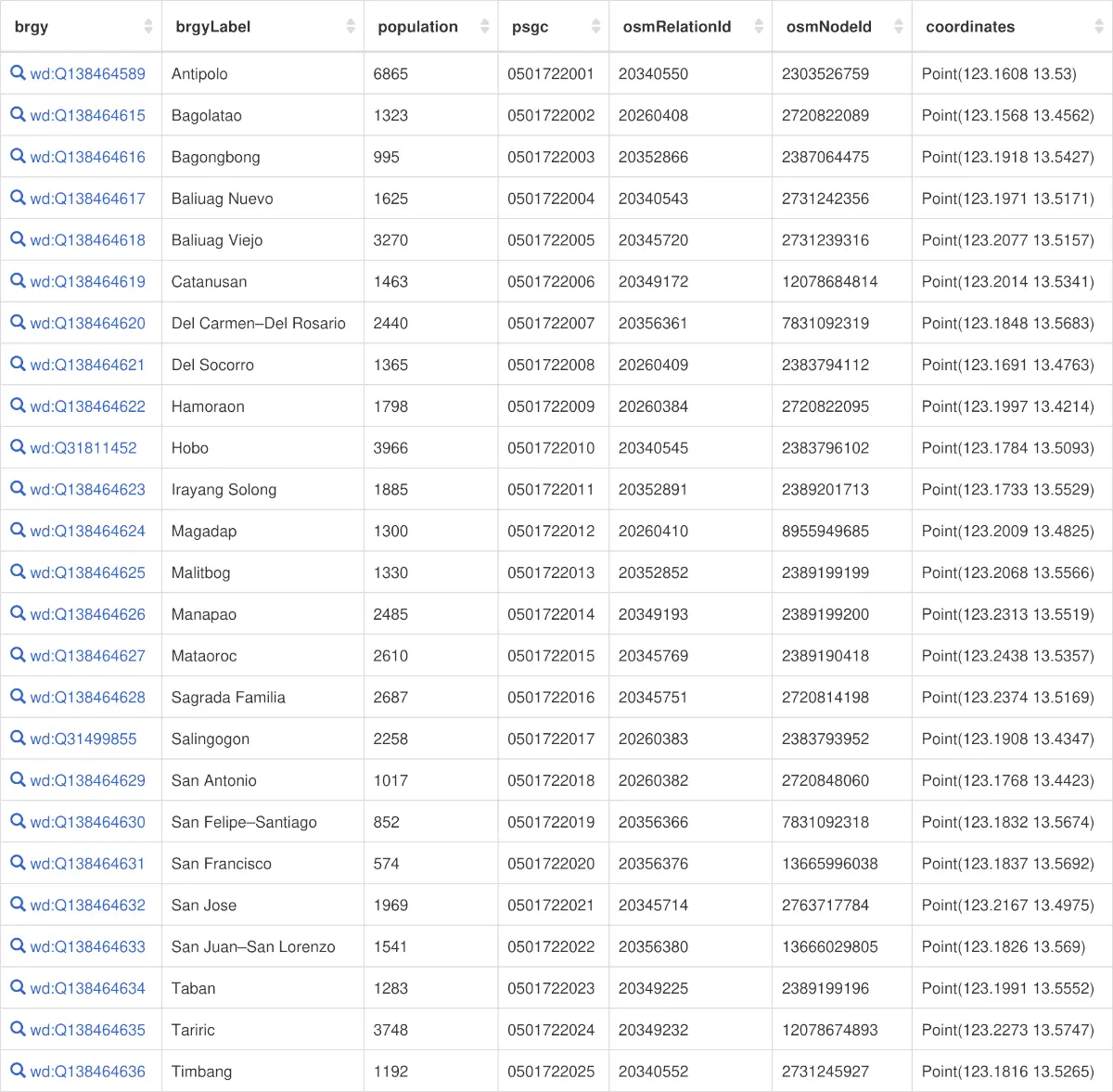
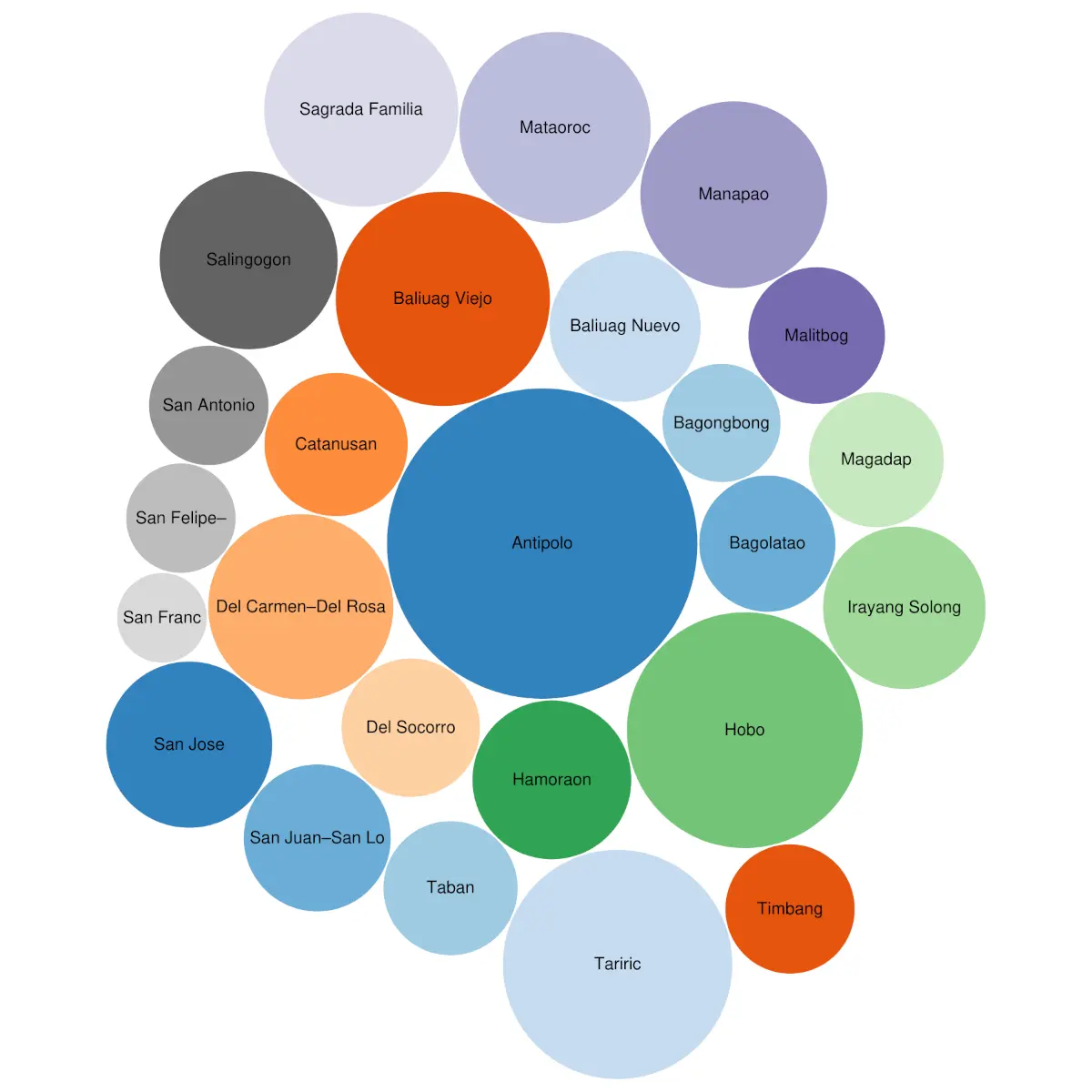
 @mlawton@mstdn.social
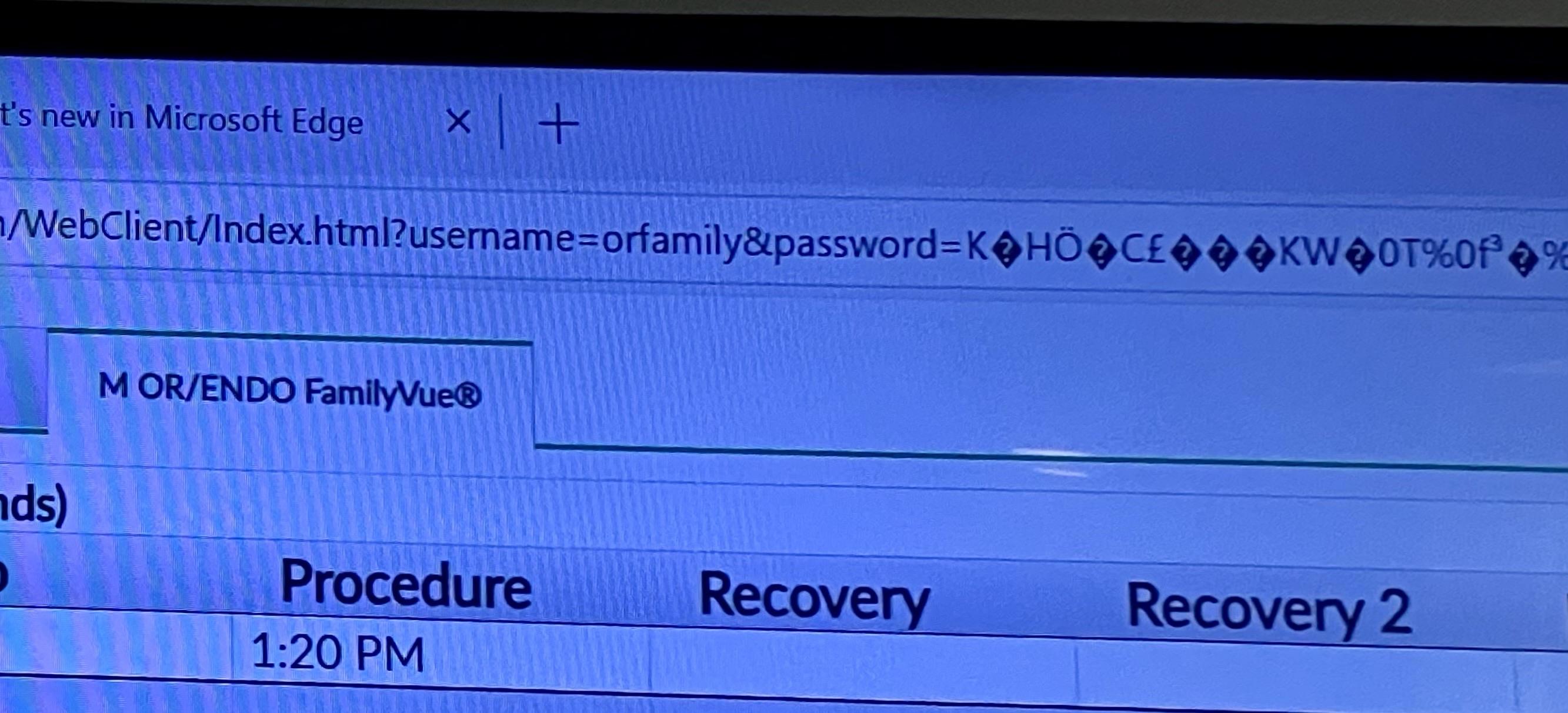
@mlawton@mstdn.socialThis makes me so twitchy. This patient status page, served over HTTP and not HTTPS, has the credentials as query parameters. Such shocking op sec in a healthcare environment, both as a deployed solution and a commercial product.
We know the username, have a head start on the password (with a good idea of the encoding), and the presence of a “user privileges” tab [not pictured] suggests the account has more permissions than necessary.
Dear god. 🤦
 @toxi@mastodon.thi.ng
@toxi@mastodon.thi.ngtl;dr Using https://thi.ng/column-store to accelerate tag intersection queries by a factor of 880x...
Working on the static website generator/export plugin for my personal knowledge tool has been one of the main projects this past month. A key part of this setup is tagging, not just simple flat keywords/cate…
 @fanf@mendeddrum.org
@fanf@mendeddrum.orgfrom my link log —
JSONata: a JSON query and transformation language.
https://jsonata.org/
saved 2026-02-09 https://dotat.at/:/CEJOA.html
 @Marwe@troet.cafe
@Marwe@troet.cafeDiese zweiteilige Doku enthält einige Knaller:
Putins Netzwerk in Europa
Das konkrete Truppenangebot in Divisionsstärke für den bewaffneten Kampf von Separatisten in Europa war mir neu.
https://mediathekviewweb.de/#query=Putins Netzwerk in Europa
 @karlauerbach@sfba.social
@karlauerbach@sfba.socialGeneral query: are you anticipating the return of 1974 gas lines and perhaps even/odd gasoline filling days?
(I am.)
By-the-way, when that was happening I would go fill my car at midnight - a time when it was ambiguous whether the day was an even one or an odd one.
 @keen456@infosec.exchange
@keen456@infosec.exchange@… Have you seen this story? https://www.phoronix.com/news/ATI-R300-Occlusion-Query-Fix Developer in Czechia working on fixing up R300…
 @arXiv_csOS_bot@mastoxiv.page
@arXiv_csOS_bot@mastoxiv.pageProphetKV: User-Query-Driven Selective Recomputation for Efficient KV Cache Reuse in Retrieval-Augmented Generation
Shihao Wang, Jiahao Chen, Yanqi Pan, Hao Huang, Yichen Hao, Xiangyu Zou, Wen Xia, Wentao Zhang, Haitao Wang, Junhong Li, Chongyang Qiu, Pengfei Wang
https://arxiv.org/abs/2602.02579 https://arxiv.org/pdf/2602.02579 https://arxiv.org/html/2602.02579
arXiv:2602.02579v1 Announce Type: new
Abstract: The prefill stage of long-context Retrieval-Augmented Generation (RAG) is severely bottlenecked by computational overhead. To mitigate this, recent methods assemble pre-calculated KV caches of retrieved RAG documents (by a user query) and reprocess selected tokens to recover cross-attention between these pre-calculated KV caches. However, we identify a fundamental "crowding-out effect" in current token selection criteria: globally salient but user-query-irrelevant tokens saturate the limited recomputation budget, displacing the tokens truly essential for answering the user query and degrading inference accuracy.
We propose ProphetKV, a user-query-driven KV Cache reuse method for RAG scenarios. ProphetKV dynamically prioritizes tokens based on their semantic relevance to the user query and employs a dual-stage recomputation pipeline to fuse layer-wise attention metrics into a high-utility set. By ensuring the recomputation budget is dedicated to bridging the informational gap between retrieved context and the user query, ProphetKV achieves high-fidelity attention recovery with minimal overhead. Our extensive evaluation results show that ProphetKV retains 96%-101% of full-prefill accuracy with only a 20% recomputation ratio, while achieving accuracy improvements of 8.8%-24.9% on RULER and 18.6%-50.9% on LongBench over the state-of-the-art approaches (e.g., CacheBlend, EPIC, and KVShare).
toXiv_bot_toot
 @alejandrobdn@social.linux.pizza
@alejandrobdn@social.linux.pizzaTrend in the volume of new questions on StackOverflow https://data.stackexchange.com/stackoverflow/query/1926661
 @niqdanger@social.linux.pizza
@niqdanger@social.linux.pizzaIf you didn't know about this collection of shows, check it out. Aadam Jacobs collection at the Internet Archive. Seeing he was Chicago based I took the chance to search and sure enough, he has a few Troubled Hubble shows. Amazing. https://archive.org/details/@aadam_jac
 @grahamperrin@bsd.cafe
@grahamperrin@bsd.cafe @khalidabuhakmeh@mastodon.social
@khalidabuhakmeh@mastodon.socialReading an article about how to optimize EF Queries. Honestly, step #0 should be to actually measure your query performance so that you have a baseline.
I've made the sin of just applying techniques without first measuring, and you can just end up making things worse, like waaaaaaaaay worse.
Folks, seriously, add some telemetry as the first step, then tackle each query one at a time.
 @philip@mastodon.mallegolhansen.com
@philip@mastodon.mallegolhansen.comTonight I made a daiquiri.
And then I realized, the way it’s spelled looks a lot like a portmanteau of daj (Polish: Give) and query.
So maybe every time someone gives you a SQL query, that’s actually a daiquiri.
 @kidehen@mastodon.social
@kidehen@mastodon.socialLive SPARQL Query Page Links:
[1] https://tinyurl.com/Query-Definition
[2] https://tinyurl.com/Query-Solution-Page

 @roland@devdilettante.com
@roland@devdilettante.comanyquery works :-) on any CSV file on the internet, nice complement to datasette me thinks :-) e.g. to query thunderbird desktop february 2026 questions:
`anyquery> SELECT * FROM read_csv('https://raw.githubuse…
 @michabbb@social.vivaldi.net
@michabbb@social.vivaldi.net🔧 Cost-based query optimizer with full EXPLAIN / EXPLAIN ANALYZE support and table statistics via ANALYZE
📦 100 built-in functions across string, math, date/time, JSON and aggregate categories – batteries fully included
🛠️ Simple integration via Cargo with a single dependency: stoolap = "0.1" – plus a CLI tool for REPL or direct query execution
 @Techmeme@techhub.social
@Techmeme@techhub.socialSources: Apple is testing letting Siri process multiple requests in a single query in iOS 27, and explored a Grammarly-like keyboard that expands autocorrect (Mark Gurman/Bloomberg)
https://www.bloomberg.com/news/articles/202…
 @datascience@genomic.social
@datascience@genomic.socialDo you have a long running calculation freezing up your shiny app? {callr} or {crew} might help: https://discindo.org/post/asynchronous-execution-in-shiny/
 @simon_brooke@mastodon.scot
@simon_brooke@mastodon.scot @shanmukhateja@social.linux.pizza
@shanmukhateja@social.linux.pizzaHey @… can I request attention towards:
https://bugs.kde.org/show_bug.cgi?id=515271
I like
 @gadgetboy@gadgetboy.social
@gadgetboy@gadgetboy.socialI found a solid iOS client for using my LM Studio-hosted models.
The Web Agent is interesting - launches Google in an in-app browser, parses the SERP, and delivers the results of your query back in the chat window - all while you watch what it's doing.
Qwen 3.5 35b performs well with these tasks, even if it's a little slow for interactive tasks on my hardware.
Find the app here:
 @stefan@gardenstate.social
@stefan@gardenstate.socialAnyone know a reason to not find accounts that use a signup IP that is a known Tor exit node as a signal of being a bot?
I'm looking at IPs by doing: Query: <reversed-ip>.dnsel.torproject.org − resolves to 127.0.0.2 if it's a Tor exit.
#mastoadmin
 @daniel@social.telemetrydeck.com
@daniel@social.telemetrydeck.comWe asked 6 Druid Historical Calculation servers if they could calculate 5 years of data at once for a very complicated multi-stage query. Their answer will surprise you!
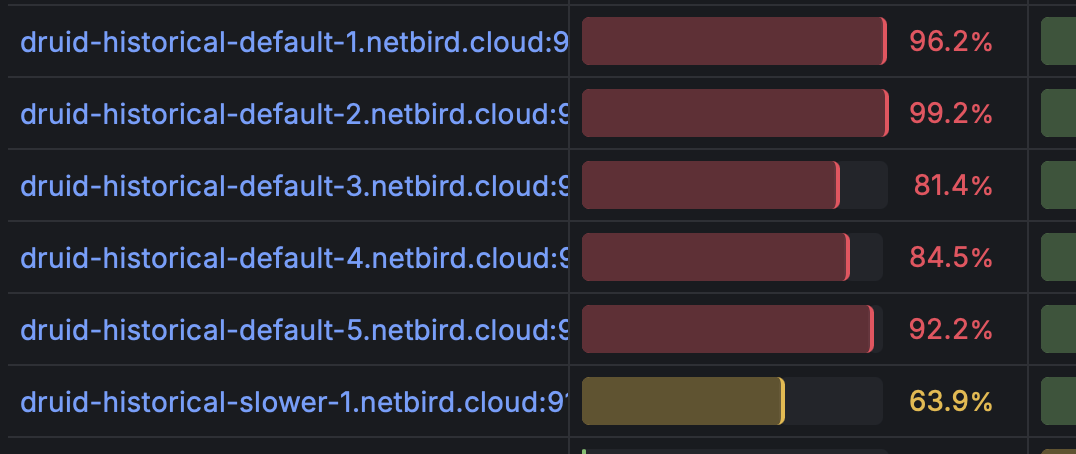
 @awinkler@openbiblio.social @toxi@mastodon.thi.ng
@awinkler@openbiblio.social @toxi@mastodon.thi.ng#ReleaseThursday 🎉 Just pushed a new version of the https://thi.ng/column-store database and query engine which adds support for new column types (fixed-size n-dimensional int/uint/float vectors) and RLE (run-…
 @nobodyinperson@fosstodon.org
@nobodyinperson@fosstodon.orgTIL that "compositing" has slowed down my #xfce since forever. I don't see any change after disabling it, just that everything is a lot faster 😅
xfconf-query -c xfwm4 -p /general/use_compositing -s false
 @aral@mastodon.ar.al
@aral@mastodon.ar.alWait, the for-profit not-for-profit privacy champion funded by half-a-billion dollars a year from Google is doing this? Do you think their then-head of public policy was actually telling the truth when she told me “we’re just another Silicon Valley tech company?” No, couldn’t possibly be. I’m sure there are some benefits of the doubt we could still dust off and send their way.
#Mozilla

@javi
Firefox updated their Terms of Use? Let's see!
As you type a search query within Firefox, Firefox offers search suggestions to provide you with faster and more direct access to what you’re looking for. Some of the search suggestions come from your search provider (“Search Suggestions”). Others come …
 @almad@fosstodon.org
@almad@fosstodon.orgWait Sama started talking Trump now, or was it always the case?
> Water is totally fake. It used to be true, we used to do evaporative cooling in data centres, but now that we don’t do that, you see these things on the internet where, don’t use ChatGPT, it’s 17 gallons of water for each query or whatever, this is completely untrue. Totally insane. No connection to reality.
 @me@mastodon.peterjanes.ca
@me@mastodon.peterjanes.caSemi-regular query to see if anyone else remembers CBC Vancouver's "The Dog and Trombone", written by Jurgen Gothe and Bill Phillips; and, more to the point, if they've got recordings of it, especially episode 5 featuring Hap Hafner's cousin Hugo?
#CBCRadio #JurgenGothe
@grahamperrin@bsd.cafe<https://github.com/freebsd/freebsd-src/blob/main/CONTRIBUTING.md#style> mentions the one-sentence-per-line rule for manual pages, however:
a) there's no such rule in mdoc(7) <
 @ruario@vivaldi.net
@ruario@vivaldi.net@… I also think that as a stop gap it would help if both proects offered some official API to query what the latest version is and perhaps offered RSS/ATOM feeds of updates so that knowledgeable users could subscribe to that and be notified right away, direct from the source.
 @socallinuxexpo@social.linux.pizza
@socallinuxexpo@social.linux.pizzaElizabeth Christensen, Devrim Gunduz, Ryan Booz will speak on 'Postgres Query Tuning - Hour 6 of Postgres Training Day' as part of our PostgreSQL@SCaLE track at SCaLE 23x. Full details: https://www.socallinuxexpo.org/scale/23x
 @thomasfuchs@hachyderm.io
@thomasfuchs@hachyderm.ioRE: https://hachyderm.io/@thomasfuchs/115945071431971557
Also, yes you can connect to WiFi in Mac OS 9.2 with AirPort in a 27 year old iBook from 1999 and yes, iTunes can still query Gracenote for CD track titles.
@fanf@mendeddrum.orgfrom my link log —
AEQuery: Apple Events command line query tool without AppleScript.
https://markalldritt.com/?p=1368
saved 2026-02-08 https://dotat.a…
 @frankel@mastodon.top
@frankel@mastodon.top @gray17@mastodon.social
@gray17@mastodon.socialtoday's rabbithole: scroll shadows with just css.
- background-attachment - well-established hack, works ok, but tricky to do in some layouts (eg sticky footer)
- container query scroll-state stuck - chrome only for now and kinda buggy
- scroll animation - works ok in chrome and safari. not yet firefox without flag. awkward if you want a smooth fade at a particular closeness.
leaning toward scroll animation, because it feels like the most natural way to express it
 @jkmartindale@mastodon.social
@jkmartindale@mastodon.socialah yes, Japan comes from Japan

 @Mediagazer@mstdn.social
@Mediagazer@mstdn.socialSource: OpenAI targets ~$60 per 1,000 views for ChatGPT ads, on par with live NFL broadcasts and above Meta's sub-$20 CPM, while offering little conversion data (The Information)
https://www.theinformation.com/articles/openai-seeks-premium-prices-early-…
 @arXiv_csDS_bot@mastoxiv.page
@arXiv_csDS_bot@mastoxiv.pageZOR filters: fast and smaller than fuse filters
Antoine Limasset
https://arxiv.org/abs/2602.03525 https://arxiv.org/pdf/2602.03525 https://arxiv.org/html/2602.03525
arXiv:2602.03525v1 Announce Type: new
Abstract: Probabilistic membership filters support fast approximate membership queries with a controlled false-positive probability $\varepsilon$ and are widely used across storage, analytics, networking, and bioinformatics \cite{chang2008bigtable,dayan2018optimalbloom,broder2004network,harris2020improved,marchet2023scalable,chikhi2025logan,hernandez2025reindeer2}. In the static setting, state-of-the-art designs such as XOR and fuse filters achieve low overhead and very fast queries, but their peeling-based construction succeeds only with high probability, which complicates deterministic builds \cite{graf2020xor,graf2022binary,ulrich2023taxor}.
We introduce \emph{ZOR filters}, a deterministic continuation of XOR/fuse filters that guarantees construction termination while preserving the same XOR-based query mechanism. ZOR replaces restart-on-failure with deterministic peeling that abandons a small fraction of keys, and restores false-positive-only semantics by storing the remainder in a compact auxiliary structure. In our experiments, the abandoned fraction drops below $1\%$ for moderate arity (e.g., $N\ge 5$), so the auxiliary handles a negligible fraction of keys. As a result, ZOR filters can achieve overhead within $1\%$ of the information-theoretic lower bound $\log_2(1/\varepsilon)$ while retaining fuse-like query performance; the additional cost is concentrated on negative queries due to the auxiliary check. Our current prototype builds several-fold slower than highly optimized fuse builders because it maintains explicit incidence information during deterministic peeling; closing this optimisation gap is an engineering target.
toXiv_bot_toot
 @NFL@darktundra.xyz
@NFL@darktundra.xyzEagles GM offers same reply to every Brown query https://www.espn.com/nfl/story/_/id/48343831/eagles-gm-howie-roseman-fields-questions-aj-brown-reiterates-aj-brown-member-eagles
 @paulwermer@sfba.social
@paulwermer@sfba.socialAny thoughts on search options?
The ad driven postings taking me to on-line but not local stores , treating every search as if I'm looking for something to buy, the return of multiple related items when I'm searching for a specific item (down to part number in the query) are making search far less useful than the printed options of my youth.
@PaulWermer@sfba.socialAny thoughts on search options?
The ad driven postings taking me to on-line but not local stores , treating every search as if I'm looking for something to buy, the return of multiple related items when I'm searching for a specific item (down to part number in the query) are making search far less useful than the printed options of my youth.
 @arXiv_csLG_bot@mastoxiv.page
@arXiv_csLG_bot@mastoxiv.pageStatistical Query Lower Bounds for Smoothed Agnostic Learning
Ilias Diakonikolas, Daniel M. Kane
https://arxiv.org/abs/2602.21191 https://arxiv.org/pdf/2602.21191 https://arxiv.org/html/2602.21191
arXiv:2602.21191v1 Announce Type: new
Abstract: We study the complexity of smoothed agnostic learning, recently introduced by~\cite{CKKMS24}, in which the learner competes with the best classifier in a target class under slight Gaussian perturbations of the inputs. Specifically, we focus on the prototypical task of agnostically learning halfspaces under subgaussian distributions in the smoothed model. The best known upper bound for this problem relies on $L_1$-polynomial regression and has complexity $d^{\tilde{O}(1/\sigma^2) \log(1/\epsilon)}$, where $\sigma$ is the smoothing parameter and $\epsilon$ is the excess error. Our main result is a Statistical Query (SQ) lower bound providing formal evidence that this upper bound is close to best possible. In more detail, we show that (even for Gaussian marginals) any SQ algorithm for smoothed agnostic learning of halfspaces requires complexity $d^{\Omega(1/\sigma^{2} \log(1/\epsilon))}$. This is the first non-trivial lower bound on the complexity of this task and nearly matches the known upper bound. Roughly speaking, we show that applying $L_1$-polynomial regression to a smoothed version of the function is essentially best possible. Our techniques involve finding a moment-matching hard distribution by way of linear programming duality. This dual program corresponds exactly to finding a low-degree approximating polynomial to the smoothed version of the target function (which turns out to be the same condition required for the $L_1$-polynomial regression to work). Our explicit SQ lower bound then comes from proving lower bounds on this approximation degree for the class of halfspaces.
toXiv_bot_toot
@michabbb@social.vivaldi.net @Marwe@troet.cafeDiese zweiteilige Doku enthält einige Knaller:
Putins Netzwerk in Europa
Das konkrete Truppenangebot in Divisionsstärke für den bewaffneten Kampf von Separatisten in Europa war mir neu.
https://mediathekviewweb.de/#query=Putins Netzwerk in Europa
@fanf@mendeddrum.orgfrom my link log —
PostgreSQL query cancellation / Ctrl-C in psql is insecure.
https://neon.com/blog/ctrl-c-in-psql-gives-me-the-heebie-jeebies
saved 2026-03-23
@Techmeme@techhub.socialSource: OpenAI targets ~$60 per 1,000 views for ChatGPT ads, on par with live NFL broadcasts and above Meta's sub-$20 CPM, while offering little conversion data (The Information)
https://www.theinformation.com/articles/openai-seeks-premium-prices-early-…
@seav@en.osm.townIs it just me or is the #Wikidata Query Service quite flaky as of late? When using the public API, I sporadically get HTTP 504 (upstream timeout) errors.
 @arXiv_csDB_bot@mastoxiv.page
@arXiv_csDB_bot@mastoxiv.pageQuantum Computing for Query Containment of Conjunctive Queries
Luisa Gerlach, Tobias K\"oppl, Ren\`e Zander, Nicole Schweikardt, Stefanie Scherzinger
https://arxiv.org/abs/2602.21803
@datascience@genomic.socialPolars is a lightning fast DataFrame library/in-memory query engine with parallel execution and cache efficiency. And now you can use is with the tidyverse syntax: #rstats
@michabbb@social.vivaldi.net⚙️ Define fields once in a Repository — #LaravelRestify auto-generates:
✅ Paginated REST endpoints with filtering & sorting
✅ MCP tool definitions with input schemas
✅ #LaravelSanctum auth protecting both
interfaces equally
🔍 Powerful query capabili…
@toxi@mastodon.thi.ng#ReleaseSunday 🎉 Quite a few https://thi.ng/column-store updates over the past month, including further performance optimizations, more tests and documentation updates...
Just also added a small section an…
 @grahamperrin@bsd.cafe
@grahamperrin@bsd.cafe@… I guess, you mean font size in the virtual terminal (vt) when you're not using MATE.
screen.font
– in vt(4) examples and in loader.conf(5).
<http…
@arXiv_csDS_bot@mastoxiv.pagePrune, Don't Rebuild: Efficiently Tuning $\alpha$-Reachable Graphs for Nearest Neighbor Search
Tian Zhang, Ashwin Padaki, Jiaming Liang, Zack Ives, Erik Waingarten
https://arxiv.org/abs/2602.08097 https://arxiv.org/pdf/2602.08097 https://arxiv.org/html/2602.08097
arXiv:2602.08097v1 Announce Type: new
Abstract: Vector similarity search is an essential primitive in modern AI and ML applications. Most vector databases adopt graph-based approximate nearest neighbor (ANN) search algorithms, such as DiskANN (Subramanya et al., 2019), which have demonstrated state-of-the-art empirical performance. DiskANN's graph construction is governed by a reachability parameter $\alpha$, which gives a trade-off between construction time, query time, and accuracy. However, adaptively tuning this trade-off typically requires rebuilding the index for different $\alpha$ values, which is prohibitive at scale. In this work, we propose RP-Tuning, an efficient post-hoc routine, based on DiskANN's pruning step, to adjust the $\alpha$ parameter without reconstructing the full index. Within the $\alpha$-reachability framework of prior theoretical works (Indyk and Xu, 2023; Gollapudi et al., 2025), we prove that pruning an initially $\alpha$-reachable graph with RP-Tuning preserves worst-case reachability guarantees in general metrics and improved guarantees in Euclidean metrics. Empirically, we show that RP-Tuning accelerates DiskANN tuning on four public datasets by up to $43\times$ with negligible overhead.
toXiv_bot_toot
@michabbb@social.vivaldi.net @fanf@mendeddrum.orgfrom my link log —
jsongrep is faster than {jq, jmespath, jsonpath-rust, jql}
https://micahkepe.com/blog/jsongrep/
saved 2026-03-27 https://dotat.a…
@arXiv_csDS_bot@mastoxiv.pageWelfarist Formulations for Diverse Similarity Search
Siddharth Barman, Nirjhar Das, Shivam Gupta, Kirankumar Shiragur
https://arxiv.org/abs/2602.08742 https://arxiv.org/pdf/2602.08742 https://arxiv.org/html/2602.08742
arXiv:2602.08742v1 Announce Type: new
Abstract: Nearest Neighbor Search (NNS) is a fundamental problem in data structures with wide-ranging applications, such as web search, recommendation systems, and, more recently, retrieval-augmented generations (RAG). In such recent applications, in addition to the relevance (similarity) of the returned neighbors, diversity among the neighbors is a central requirement. In this paper, we develop principled welfare-based formulations in NNS for realizing diversity across attributes. Our formulations are based on welfare functions -- from mathematical economics -- that satisfy central diversity (fairness) and relevance (economic efficiency) axioms. With a particular focus on Nash social welfare, we note that our welfare-based formulations provide objective functions that adaptively balance relevance and diversity in a query-dependent manner. Notably, such a balance was not present in the prior constraint-based approach, which forced a fixed level of diversity and optimized for relevance. In addition, our formulation provides a parametric way to control the trade-off between relevance and diversity, providing practitioners with flexibility to tailor search results to task-specific requirements. We develop efficient nearest neighbor algorithms with provable guarantees for the welfare-based objectives. Notably, our algorithm can be applied on top of any standard ANN method (i.e., use standard ANN method as a subroutine) to efficiently find neighbors that approximately maximize our welfare-based objectives. Experimental results demonstrate that our approach is practical and substantially improves diversity while maintaining high relevance of the retrieved neighbors.
toXiv_bot_toot
@kidehen@mastodon.socialThis feature provides syntax-level compatibility with the SERVICE wikibase:label extension, enabling queries written for the Wikidata Query Service to run more seamlessly on Virtuoso.
In practical terms, developers can reuse existing SPARQL queries that rely on SERVICE wikibase:label—without needing to rewrite label-handling logic—while benefiting from Virtuoso’s performance, flexibility, and deployment options.
@fanf@mendeddrum.orgfrom my link log —
When upserts don't update but still write: debugging PostgreSQL WAL activity.
https://www.datadoghq.com/blog/engineering/debugging-postgres-performance/
saved 2026-03-24
 @tomkalei@machteburch.social
@tomkalei@machteburch.socialOK, but the results are still just paper links, not what the LLM thinks about them. So the only thing that changed is that it is much much slower now?
Maybe the LLM just formulates a query to the old scholar? Too many layers of "oh how can we build an LLM into this"...
OK, nobody in #math uses Google Scholar like this anyway. We only use it look at publication records of people and do reverse citation search (which papers cite this one I have).
 @michabbb@social.vivaldi.net
@michabbb@social.vivaldi.net🎯 Zero accuracy loss - preserves what matters: errors, anomalies, high-scoring items & query-relevant content using BM25/embedding similarity
✅ Full provider support: #OpenAI, #Anthropic, #Google
@arXiv_csDS_bot@mastoxiv.pageReplaced article(s) found for cs.DS. https://arxiv.org/list/cs.DS/new
[1/1]:
- Optimal Hardness of Online Algorithms for Large Independent Sets
David Gamarnik, Eren C. K{\i}z{\i}lda\u{g}, Lutz Warnke
https://arxiv.org/abs/2504.11450 https://mastoxiv.page/@arXiv_csDS_bot/114346418465357434
- An Approximation Algorithm for Monotone Submodular Cost Allocation
Ryuhei Mizutani
https://arxiv.org/abs/2511.00470 https://mastoxiv.page/@arXiv_csDS_bot/115490466535056736
- Expected Cost of Greedy Online Facility Assignment on Regular Polygons (v3)
Md. Rawha Siddiqi Riad, Md. Tanzeem Rahat, Md. Manzurul Hasan
https://arxiv.org/abs/2512.00506 https://mastoxiv.page/@arXiv_csDS_bot/115648910775471187
- Nested and outlier embeddings into trees
Shuchi Chawla, Kristin Sheridan
https://arxiv.org/abs/2601.15470 https://mastoxiv.page/@arXiv_csDS_bot/115943420904659985
- Bankrupting DoS Attackers
Trisha Chakraborty, Abir Islam, Valerie King, Daniel Rayborn, Jared Saia, Maxwell Young
https://arxiv.org/abs/2205.08287
- An Algorithm for Fast and Correct Computation of Reeb Spaces for PL Bivariate Fields
Amit Chattopadhyay, Yashwanth Ramamurthi, Osamu Saeki
https://arxiv.org/abs/2403.06564 https://mastoxiv.page/@arXiv_csCG_bot/112081476174323525
- On Densest $k$-Subgraph Mining and Diagonal Loading: Optimization Landscape and Finite-Step Exact...
Qiheng Lu, Nicholas D. Sidiropoulos, Aritra Konar
https://arxiv.org/abs/2410.07388 https://mastoxiv.page/@arXiv_csSI_bot/113287589348257824
- A New Quantum Linear System Algorithm Beyond the Condition Number and Its Application to Solving ...
Jianqiang Li
https://arxiv.org/abs/2510.05588 https://mastoxiv.page/@arXiv_quantph_bot/115337999786748703
- On Purely Private Covariance Estimation
Tommaso d'Orsi, Gleb Novikov
https://arxiv.org/abs/2510.26717 https://mastoxiv.page/@arXiv_csLG_bot/115468358153466988
- The Query Complexity of Local Search in Rounds on General Graphs
Simina Br\^anzei, Ioannis Panageas, Dimitris Paparas
https://arxiv.org/abs/2601.13266 https://mastoxiv.page/@arXiv_csCC_bot/115932039505257286
toXiv_bot_toot
@michabbb@social.vivaldi.net