 @cowboys@darktundra.xyz
@cowboys@darktundra.xyz2025-10-17 12:03:57
Stephen Jones says Cowboys will look for ways to improve before NFL deadline https://www.si.com/nfl/cowboys/news/dallas-cowboys-very-serious-making-roster-better-ahead-nfl-trade-deadline
@cowboys@darktundra.xyzStephen Jones says Cowboys will look for ways to improve before NFL deadline https://www.si.com/nfl/cowboys/news/dallas-cowboys-very-serious-making-roster-better-ahead-nfl-trade-deadline
 @rasterweb@mastodon.social
@rasterweb@mastodon.socialBig thanks to the Fediverse Friends who wished me well or even just commiserated at the pain I've been going through.
I am feeling a lot better today, but I don't want to forget that pain, because I need to be mindful of the pain people are in every day. It's a struggle, it's a battle, and I wish we could all live pain-free lives.
 @crell@phpc.social
@crell@phpc.socialPhone rep: Sorry, I talk to myself while entering things.
Me: Hey, it's better than awkward silence for 10 minutes like I usually get.
Rep: I could do that if you want, I can provide Awkward Silence As A Service.
My dude, you are way, way too intelligent to be answering phones for the state government. You did a great job, but still.
 @gedankenstuecke@scholar.social
@gedankenstuecke@scholar.socialOr could methods from the environmental sciences maybe be adapted to the dynamics of digital communities/commons, to better understand these processes?
And, just as importantly (if not more so), could they help us to take better care of our digital spaces and maintain them as vibrant ecosystems that continue thriving?
Again, if that sounds of interest, e.g. as someone who maintains or contributes to communities, or as a social or environmental scientist, please get in touch with us!
🧵 5/5
 @hex@kolektiva.social
@hex@kolektiva.socialI keep coming back to the mirror dualities of the oppressed and oppressor under authoritarianism.
The oppressed is portrayed as both weak and godlike. The stereotypes are always some variation on sloth and incompetence, but yet somehow also a menace capable of destroying the "pure" society. To use the most relevant current example, Antifa being both little femme soy boys who would always get beat up by "real men" while also being an international terrorist organization on the brink of overthrowing the US government, the unarmed presence of whom makes the heavily armed agents of ICE flee for their lives. Antifa is both having absolutely no impact on ICE, and also having such an impact on ICE that the military needs to come in to protect them. The contradiction is obvious but never seems to occur to those who hold both to be true at the same time.
But few talk about the duality of the oppressor. The sovereign throughout history has always been both a ruler above the law, sometimes even the representative or incarnation of a divine force. Yet, this same superhuman/god-man is also a baby who needs constant care. This is absolutely a through line from the very earliest records of sovereign cults to modern cult leaders, CEOs, and Trump today. Power, for these people, is expressed both as the ability to force others to enact their will and in the ability to compel others to care for them. Can any of these "men" cook? Can they fix anything themselves? They are driven everywhere, cooked for all the time, constantly protected from danger. Kings are still dressed, at least for rituals. I could dissect masculinity here, but that's a whole thing.
It is as though the drive to care for our children, who must be taught to behave within acceptable norms, is hijacked by "leaders" who demand our care and attention... even at the expense of our literal children. And recently we've seen some of those very CEOs, with LLMs and return to office demands, show that their judgment is also little better than children, making decisions while pretending to understand a subject.
The oppressed are portrayed as both god-like and impotent and are, in fact, neither. Meanwhile the rulers portray themselves only as invulnerable and are, in fact, childish in their ability to survive without constant support. Their greatest fear from the collapse of society is figuring out how to make sure people keep taking care of them.
It just keeps rattling around in my head.
#USPol
 @mia@hcommons.social
@mia@hcommons.socialA surprise benefit of mRNA vaccines could be better treatments for cancer, extending lives without the side effects of chemo? Yay for good news! https://www.theguardian.com/commentisfree/2025/nov/12/covid-mrna-vaccines-cancer-patien…
 @tiotasram@kolektiva.social
@tiotasram@kolektiva.socialFinished "Lobizona" by Romina Garber. I have extremely mixed feelings about this book. It's a powerful depiction of the fear of living as an undocumented child/teen and it has interesting things to say about rejection, belonging, and the choice between seeking to be recognized for who you are and wanting you blend in enough to be accepted as normal. However, it's also an explicit homage to Harry Potter, and while it doesn't include antisemitic tropes or glorify slavery or even have any anti-trans sentiments I can detect, to me the magical school setup felt forced and I thought it would have been a better book had it not tried to fit that mould. Also, it would have been a super interesting situation to explore trans issues, and while it's definitely fine for it not to do that, the author's praise of Rowling's work has me wondering...
There's a sequel that I think could in theory be amazing, but given the execution of the first book, I think I'll wait a bit before checking it out. By putting her main character in opposition to both ICE in the human world and the magical authorities in the other world, Garber explicitly sets the stage for a revolution standing between her protagonist and any kind of lasting peace. But I'm not confident she's capable of writing that story without relying on some kind of supernatural deus ex machina, which would be disappointing to me, since "a better world if only possible through divine intervention" is an inherently regressive message.
Overall, #OwnVoices fantasy centering an undocumented immigrant is an excellent thing, and I've certainly got a lot of privilege that surely influences my criticism. However, #OwnVoices stuff has a range of levels of craft and political stances, and it can be excellent for some reasons and mediocre for others.
On that point, if anyone reading this has suggestions for fiction books grappling with borders and the carceral state, Is be happy to hear them.
#AmReading
 @luana@wetdry.world
@luana@wetdry.worldI made a script for this, but then I thought a webui would be better so I could use it in my phone and stuff
I asked an LLM to generate a python webui to run server-side the script I wrote, and surprisingly it 100% worked first try. I was sure it wouldn’t work at all, but I didn’t touch that code and it works.
I can’t even say I “vibe coded” this bc I didn’t even read the code enough to know its vibes lmao. I’m surprised this even works, and it does work well. What the actual fuck.
Welp, not my favourite way to do things but I wasn’t in the mood to do python and figure out the extra libraries and stuff.
And it works so I’ll just use that. In a hardened systemd service to make sure it doesn’t like accidentally delete my whole system or something.
 @mgorny@social.treehouse.systems
@mgorny@social.treehouse.systems"""
Traditional politics of assistance and the repression of unemployment were now called into question. The need for reform became urgent.
Poverty was gradually separated from the old moral confusions. Economic crises had shown that unemployment could not be confused with indolence, as indigence and enforced idleness spread throughout the countryside, to precisely the places that had previously been considered home to the purest and most immediate forms of moral life. This demonstrated that poverty did not solely fall under the order of the fault: ‘Begging is the fruit of poverty, which in turn is the consequence of accidents in the production of the earth or in the output of factories, of a rise in the price of basic foodstuffs, or of growth of the population, etc.’ Indigence became a matter of economics.
But it was not contingent, nor was it destined to be suppressed forever. There would always be a certain quantity of poverty that could never be effaced, a sort of fatal indigence that would accompany all forms of society until the end of time, even in places where all the idle were employed: ‘The only paupers in a well governed state must be those born in indigence, or those who fall into it by accident.’ This backdrop of poverty was somehow inalienable: whether by birth or accident, it formed an inevitable part of society. The state of lack was so firmly entrenched in the destiny of man and the structure of society that for a long time the idea of a state without paupers remained inconceivable: in the thought of philosophers, property, work and indigence were terms linked right up until the nineteenth century.
This portion of poverty was necessary because it could not be suppressed; but it was equally necessary in that it made wealth possible. Because they worked but consumed little, a class of people in need allowed a nation to become rich, to release the value of its fields, colonies and mines, making products that could be sold throughout the world. An impoverished people, in short, was a people that had no poor. Indigence became an indispensable element in the state. It hid the secret but most real life of society. The poor were the seat and the glory of nations. And their noble misery, for which there was no cure, was to be exalted:
«My intention is solely to invite the authorities to turn part of their vigilant attention to considering the portion of the People who suffer … the assistance that we owe them is linked to the honour and prosperity of the Empire, of which the Poor are the firmest bulwark, for no sovereign can maintain and extend his domain without favouring the population, and cultivating the Land, Commerce and the Arts; and the Poor are the necessary agents for the great powers that reveal the true force of a People.»
What we see here is a moral rehabilitation of the figure of the Pauper, bringing about the fundamental economic and social reintegration of his person. Paupers had no place in a mercantilist economy, as they were neither producers nor consumers, and they were idle, vagabond or unemployed, deserving nothing better than confinement, a measure that extracted and exiled them from society. But with the arrival of the industrial economy and its thirst for manpower, paupers were once again a part of the body of the nation.
"""
(Michel Foucault, History of Madness)
 @pre@boing.world
@pre@boing.worldFuture Plans:
I have like ten years of data in my log, converted from those prior prototypes. I will be adding ways to more usefully compare and analyse data going this far back.
It could maybe use a milestone function, to track singular events which don't take actual time so don't spread on the grid. Snack tracking and the like.
It could likely use a flashcard system, with spaced repetition to review the flashcards, for better memory and recall.
Synching between devices might be nice, and lots will suggest doing that through Nostr, but Nostr is a bit public. Would need an encryption layer. Do nostr relays want to relay encrypted data from one user to themselves I suspect Veilid ( https://veilid.com/ ) would be a better option. The "no servers" ethos probably includes nostr relays.
Mostly I plan just more and better ways to view the ten years and growing of data I already have. And to do some other things for a bit so my log isn't just full of "Vibecoding Exocortex" like it is the last two weeks 😉
 @scott@carfree.city
@scott@carfree.cityHere's a thoughtful critique of One Battle After Another, which I still enjoyed and recommend - and would quibble with some of the points here - but I agree the first act could've been handled better to avoid perpetuating quite so much the fetishization the film intends to condemn. https://
@tiotasram@kolektiva.socialWhen "self-driving" cars were first getting some hype back in ~2015 or so, I told people who asked me that I didn't think they'd be safe, and that I wished the same money were being invested in driver-assistance systems instead.
At the time, advocates were claiming that self-driving cars would be safer than human drivers.
We now have both self-driving cars and some nifty new driver assistance things, and it turns out that the self-driving cars are in fact being developed by corporations whose attention to the bottom line results in danger to others on the road pretty regularly. I don't actually have stats here for whether they're "safer than human drivers" or not, but the opportunity for one bad software update to make *all* self-driving cars dangerous at once kinda makes me doubt that.
Here's an example of Waymo cars getting "more aggressive" as they try to balance between being too timid and obstructing traffic (including emergency vehicles) and being too dangerous:
https://archive.ph/JJuGv
Here's another example of passing stopped schoolbusses leading to a software recall:
https://abcnews.go.com/GMA/News/waymo-issue-voluntary-software-recall-after-close-calls/story?id=128207776
In the first article, Waymo claims 91% fewer serious accidents per mile. Obviously an independent audit would be actually trustworthy, but even if we take that claim at face value, it's meaningless if an update tomorrow causes 100,000 accidents.
Note that they could be using better engineering practices, and the fact that they aren't shows that they don't care enough about the risks. They could be deploying new software versions incrementally and slowly, letting new versions rack up lots of miles only on a few vehicles before pushing them to a fleet. The should also have the equivalent of a simulation unit test for "schoolbus is stopped, what do?" and if a software version fails that test, it doesn't make it to the fleet. Clearly they don't have that.
I feel pretty vindicated in my earlier prediction that this tech is a bad idea in the hands of the current advocates.
 @al3x@hachyderm.io
@al3x@hachyderm.ioI just discovered #NetNewsWire. It’s snappy. It’s uncomplicated.
If I could find a way to make the font bigger it would be even better. Help please !
 @Mediagazer@mstdn.social
@Mediagazer@mstdn.socialPew: 62% of US parents say their child under 2 watches YouTube and 84% say their child age 2-4 does; daily use for ages 2-4 grew from 38% in 2020 to 51% in 2025 (Pew Research Center)
https://www.pewresearch.org/internet/2025/10/08/how-parents-manage-s…
 @raiders@darktundra.xyz
@raiders@darktundra.xyzBrowns, Raiders floated as landing spots for 10-time Pro Bowl quarterback https://www.sportingnews.com/us/nfl/cleveland-browns/news/browns-raiders-floated-landing-spots-10-time-pro-bowl-quarterback…
 @detondev@social.linux.pizza
@detondev@social.linux.pizzai keep being like men arent inherently evil its the environment they were in forever that did that conservatives arent inherently evil its the environment they were in forever that did that these hood kids arent worse or more prone to doing crime than u its the environment they were in forever that did that its hard but maybe if the better things had a front attached to account for the person's background and time to grow they could change things could change things might be better they&…
 @arXiv_qbioNC_bot@mastoxiv.page
@arXiv_qbioNC_bot@mastoxiv.pageMulti state neurons
Robert Worden
https://arxiv.org/abs/2512.08815 https://arxiv.org/pdf/2512.08815 https://arxiv.org/html/2512.08815
arXiv:2512.08815v1 Announce Type: new
Abstract: Neurons, as eukaryotic cells, have powerful internal computation capabilities. One neuron can have many distinct states, and brains can use this capability. Processes of neuron growth and maintenance use chemical signalling between cell bodies and synapses, ferrying chemical messengers over microtubules and actin fibres within cells. These processes are computations which, while slower than neural electrical signalling, could allow any neuron to change its state over intervals of seconds or minutes. Based on its state, a single neuron can selectively de-activate some of its synapses, sculpting a dynamic neural net from the static neural connections of the brain. Without this dynamic selection, the static neural networks in brains are too amorphous and dilute to do the computations of neural cognitive models. The use of multi-state neurons in animal brains is illustrated in hierarchical Bayesian object recognition. Multi-state neurons may support a design which is more efficient than two-state neurons, and scales better as object complexity increases. Brains could have evolved to use multi-state neurons. Multi-state neurons could be used in artificial neural networks, to use a kind of non-Hebbian learning which is faster and more focused and controllable than traditional neural net learning. This possibility has not yet been explored in computational models.
toXiv_bot_toot
 @simon_jf@mastodon.scot
@simon_jf@mastodon.scotFinished our first room renovation! Tore out the old builtin wardrobe and minging carpet, replaced skirting board and coving, plastered where the old wardrobe was, laid new flooring, painted. Took ages but happy with it on the whole!
Learnt a lot! Surface on the teal wall is pretty poor due to bad surface prep and thinking paint was more forgiving than it actually is, so will redo that in the new year, and flooring could be laid a bit better with practice. But very happy on the whole!<…




 @jeang3nie@social.linux.pizza
@jeang3nie@social.linux.pizzaOne of my professors asked me today how I would balance the principle of least privilege against efficiency and ease of use in a large organization with thousands of employees.
The best answer I could come up with is that any single organization that size is an unholy abomination, and that I would move mountains to not be in that position.
Seriously, I'm sick of the question "How can this be scaled?" The better question is, "Would scaling <thing> be a net…
 @NFL@darktundra.xyz
@NFL@darktundra.xyzJets QB Justin Fields unbothered by owner's criticism amid 0-7 effort: 'Everybody knows I need to play better'
https://www.cbssports.com/nfl/n…
 @joxean@mastodon.social
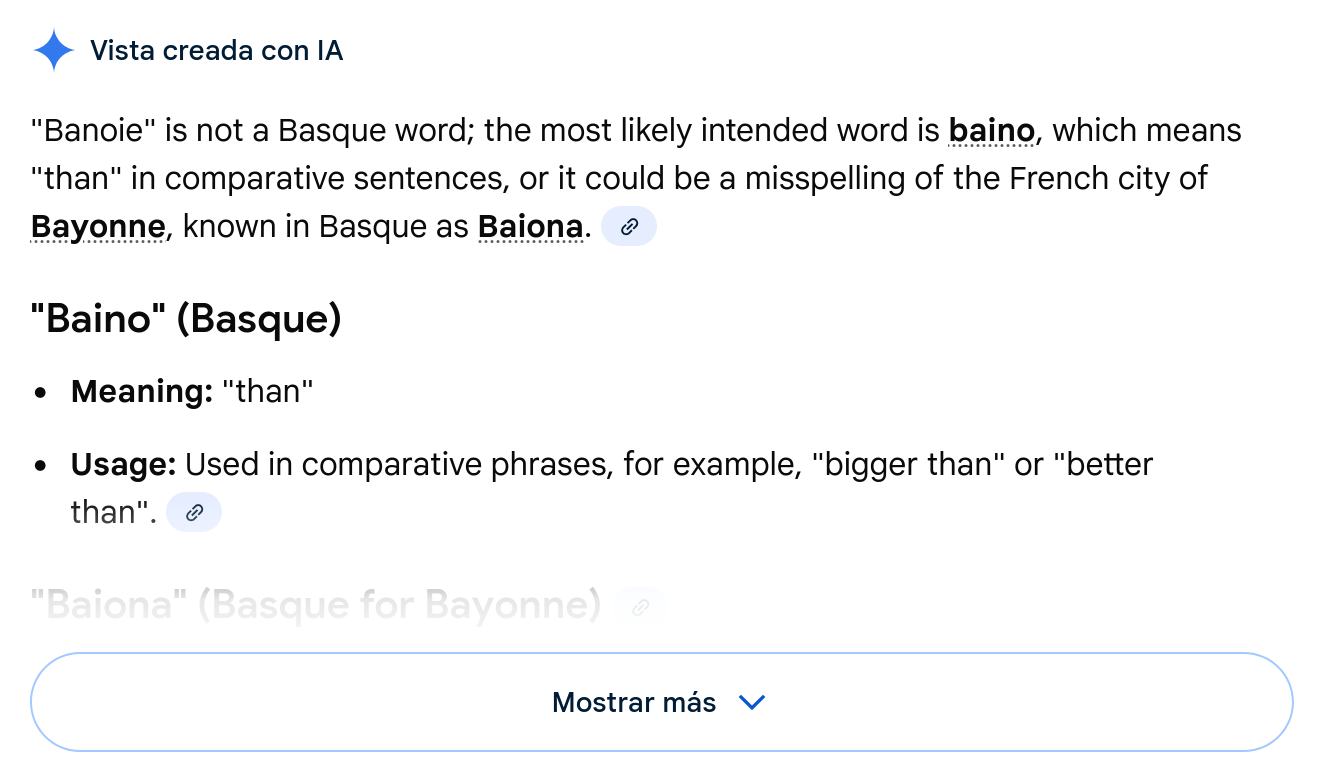
@joxean@mastodon.socialYeah, sure Google Gemini, sure.
PS: "Banoie" in Basque means "I'm leaving" in the dialect of Bizkaia.
 @pre@boing.world
@pre@boing.worldDespite much opinion to the contrary, the government money we use is crappy.
I'm at bitfest in Manchester to find out if Bitcoin could be a better money.
It could hardly be worse.
The mood is still good, people are joking about recent devaluation rather than crying. Those who aren't all in are trying to buy more at the discount.
After an introduction by Mad Bitcoins, Joe Bryan explains the problem with government money.
He imagines an island on which two types of money are tried, with a dividing wall between them.
When economic problems hit, government can just print more money on the fiat side. Everyone now using money which is worth less. Distorting prices, inflating asset prices, making the rich (who hold assets) richer and the poor (who have to pay inflated prices) poorer. Driving wealth inequality.
On the hard money side, government must tax properly. Take in more from the rich rather than inflating to take it from the poor. Reducing wealth inequality.
On the government money side, the wealthy monitize houses, stocks, resources. Saving in money is impossible, its inflated away. So they save in assets and hording resources. Capital is misallocated. The youth can't afford houses. Poverty traps are caused. The only way out is printing more for benefits. Making it all worse. More economic crises, more printing. More government debt.
Eventually, the wall is broken. Government money people can save in the hard money instead. It reduces the value of government money further. More printing. More inflation.
Eventually, war. Funded by printed money.
The dollar is the best of a bad bunch all other government money is falling in value even faster.
I wonder, is bitcoin really this better money though? It's limited, hard, and can't be printed without energy investment.
I'm still unsure that fixing money fixes the world.
--
Note: "crypto" is mostly more like government money than bitcoin. It can be printed indefinitely by it's makers, does not cost it's makers to print. Crypto is usually just a scam people to get more bitcoin. Bitcoin is not crypto.
#bitfest #bitcoin
 @tiotasram@kolektiva.social
@tiotasram@kolektiva.socialTL;DR: spending money to find the cause of autism is a eugenics project, and those resources could have been spent improving accommodations for Autistic people instead.
To preface this, I'm not Autistic but I'm neurodivergent with some overlap.
We need to be absolutely clear right now: the main purpose is *all* research into the causes of autism is eugenics: a cause is sought because non-autistic people want to *eliminate* autistic people via some kind of "cure." It should be obvious, but a "cured autistic person" who did not get a say in the decision to administer that "cure" has been subjected to non-consensual medical intervention at an extremely unethical level. Many autistic people have been exceptionally clear that they don't want to be "cured," including some people with "severe autism" such as people who are nonverbal.
When we think things like "but autism makes life so hard for some people," we're saying that the difficulties in their life are a result of their neurotype, rather than blaming the society that punished & devalues the behaviors that result from that neurotype at every turn. To the extent that an individual autistic person wants to modify their neurotype and/or otherwise use aids to modify themselves to reduce difficulties in their life, they should be free to pursue that. But we should always ask the question: "what if we changed their social or physical environment instead, so that they didn't have to change themselves?" The point is that difficulties are always the product of person x environment, and many of the difficulties we attribute to autism should instead be attributed to anti-autistic social & physical spaces, and resources spent trying to "find the cause of autism" would be *much* better spent trying to develop & promote better accommodations for autism. Or at least, that's the case if you care about the quality of life of autistic people and/or recognize their enormous contributions to society (e.g., Wikipedia could not exist in anything near its current form without autistic input). If instead you think of Autistic people as gross burdens that you'd rather be rid of, then it makes sense to investigate the causes of autism so that you can eventually find a "cure."
All of that to say: the best response to lies about the causes of autism is to ask "What is the end goal of identifying the cause?" instead of saying "That's not true, here's better info about the causes."
#autism #trump
P.S. yes, I do think about the plight of parents of autistic kids, particularly those that have huge struggles fitting into the expectations of our society. They've been put in a position where society constantly bullies and devalues their kid, and makes it mostly impossible for their kid to exist without constant parental support, which is a lot of work and which is unfair when your peers get the school system to do a massive amount of childcare. But in that situation, your kid is in an even worse position than you as the direct victim of all of that, and you have a choice: are you going to be their ally against the unfair world, or are you going to blame them and try to get them to confirm enough that you can let the school system take care of them, despite the immense pain that that will provoke? Please don't come crying for sympathy if you choose the later option (and yes, helping them be able to independently navigate society is a good thing for them, but there's a difference between helping them as their ally, at their pace, and trying to force them to conform to reduce the burden society has placed on you).
 @pbloem@sigmoid.social
@pbloem@sigmoid.social @thomasfuchs@hachyderm.io
@thomasfuchs@hachyderm.ioHas anyone making this feature actually asked any accessibility experts and any disabled people if this is a good idea?
Because in practice this will give you terrible results, because AI can’t know what you intent do communicate with the image.
Even if it would give good results (it doesn’t and never will) and you’re too lazy to write alt text yourself, it would be better to do this on the receiving end where the disabled person could fine-tune generative alt text to their specific needs.
https://mastodon.social/@MonaApp/115406286404369048
 @wraithe@mastodon.social
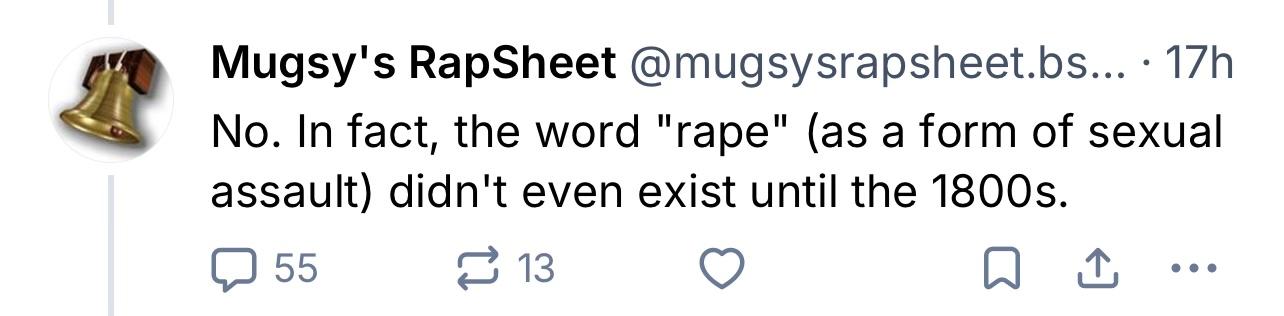
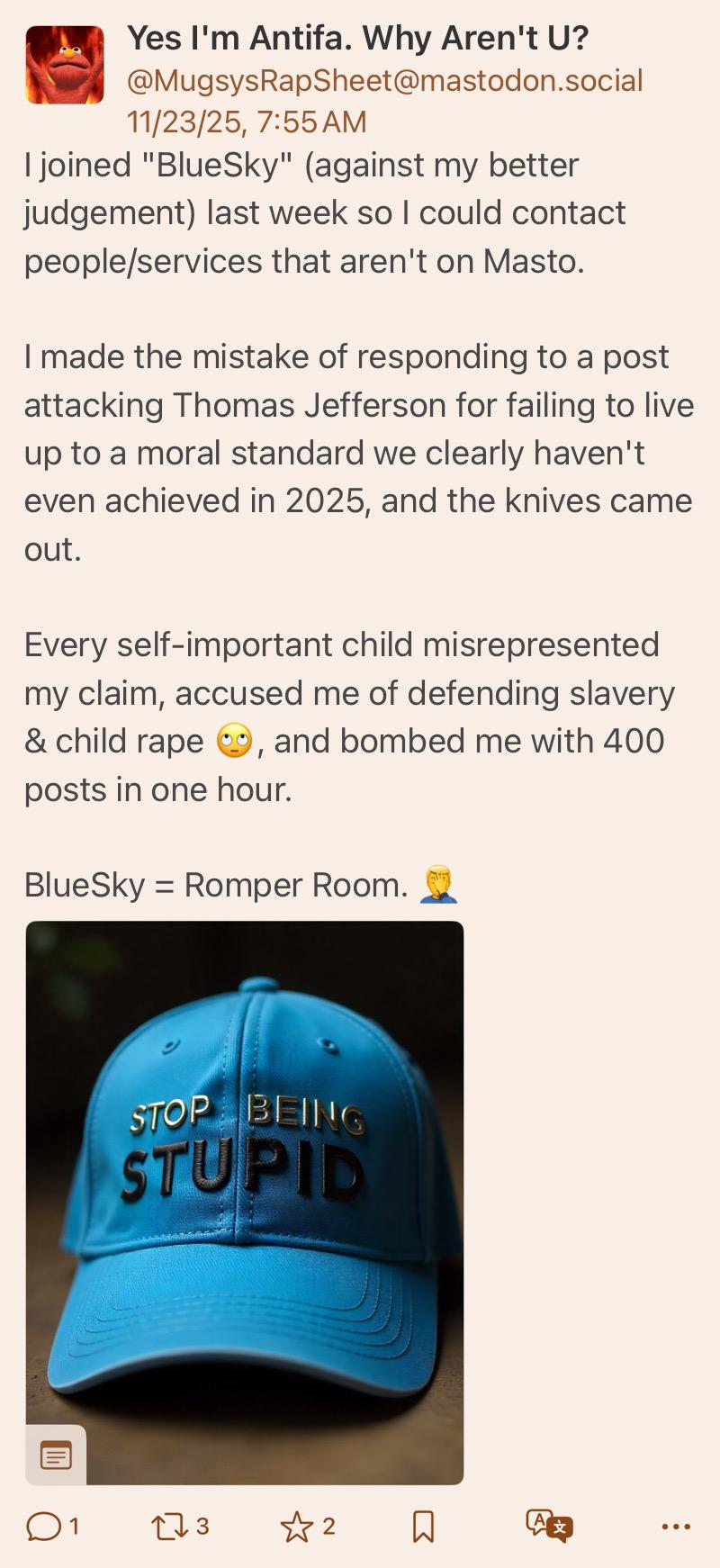
@wraithe@mastodon.socialYea I can’t imagine why anyone thought this dipshit was defending rape…I mean aside from the over half a dozen posts where he defended rape as “not immoral”, literally said “No. In fact, the word "rape"…didn't even exist until the 1800s.” and arguing that being “owned”* wasn’t “horrific”
Complete mystery why people went after him, must be some weird BlueSky thing. 😂
JFC


 @losttourist@social.chatty.monster
@losttourist@social.chatty.monsterThere's nothing to be said about Killer that thousands of other people have done a thousand times better than I ever could. So I'm just going to sit back and admire Seal at his total imperial finest. #TOTP
 @paulbusch@mstdn.ca
@paulbusch@mstdn.caGood Morning #Canada
The countdown to #Christmas has begun, according to the internet so it must be so. You've decorated the house, cat-proofed the Christmas tree, wrapped a few gifts, and, just in case, modified your behavior to stay off the naughty list. Unless being naughty gets you a better gift. All we need now is a white Christmas. Meteorologists have defined what specific conditions must exist for the picture perfect holiday, stating that we must have at least 2cm of snow on the ground at 7 a.m. on Christmas Day in order for an official declaration of a white Christmas. They also designate a "Perfect Christmas,” where we have a minimum of 2cm of snowfall on the ground, while fresh snow is actively falling during the morning on Dec. 25th. A perfect Christmas could also be finding a brand new Alfonso de Credenza parked in the garage with a big bow. It's too early to forecast a white Christmas but let's try anyway.
#CanadaIsAwesome #HappyHolidays
https://www.theweathernetwork.com/en/news/weather/forecasts/many-canadians-dream-of-a-white-christmas-but-what-are-the-odds-of-it
 @grumpybozo@toad.social
@grumpybozo@toad.socialNot interested in a debate on what ways are better or worse but it seems to me that @TheASF has a fair bit of material on "The Apache Way" which one could approach as a How-To even for projects that are not under the ASF or any other domiciling organization. It's not perfect but I'm not aware of any ASF project having the sort of nasty takeover like the Ruby affair.
OTOH, it may require the "hippie" vibe of ASF focused on consensus and community over code t…
 @usul@piaille.fr
@usul@piaille.frNot good at all
This Is How Much Anthropic and Cursor Spend On Amazon Web Services
#aibubble
 @midtsveen@social.linux.pizza
@midtsveen@social.linux.pizzaLately, I’ve been feeling burned out by how much people in my life assume things about me and my beliefs, so let's talk about it.
I spend some parts (not all) of my evenings online, usually from around 20:00 to 22:00 or sometimes even until midnight (00:00), not because I am consumed by politics but because I like to learn and reflect on how society could be better. I enjoy exploring ideas about justice, solidarity, and human rights in a way that feels meaningful to me. For me, spe…
@hex@kolektiva.socialAfter #Trump finally crashes and burns (I'm still saying I don't think he makes it to the mid terms, and I think it's more than possible he won't make it to the end of the year) we'll hear a lot of people say, "the system worked!" Today people are already talking about "saving democracy" by fighting back. This will become a big rally cry to vote (for Democrats, specifically), and the complete failure of the system will be held up as the best evidence for even greater investment in it.
I just want to point out that American democracy gave nuclear weapons to a pedophile, who, before being elected was already a well known sexual predator, and who made the campaign promise to commit genocide. He then preceded to commit genocide. And like, I don't care that he's "only" kidnaped and disappeared a few thousand brown people. That's still genocide. Even if you don't kill every member of a targeted group, any attempt to do so is still "committing genocide." Trump said he would commit genocide, then he hired all the "let's go do a race war" guys he could find and *paid* them to go do a race war. And, even now as this deranged monster is crashing out, he is still authorized to use the world's largest nuclear arsenal.
He committed genocide during his first term when his administration separated migrant parents and children, then adopted those children out to other parents. That's technically genocide. The point was to destroy the very people been sending right wing terror squads after.
There was a peaceful hand over of power to a known Russian asset *twice*, and the second time he'd already committed *at least one* act of genocide *and* destroyed cultural heritage sites (oh yeah, he also destroyed indigenous grave sites, in case you forgot, during his first term).
All of this was allowed because the system is set up to protect exactly these types of people, because *exactly* these types of people are *the entire power structure*.
Going back to that system means going back to exactly the system that gave nuclear weapons to a pedophile *TWICE*.
I'm already seeing the attempts to pull people back, the congratulations as we enter the final phase, the belief that getting Trump out will let us all get back to normal. Normal. The normal that lead here in the first place. I can already see the brunch reservations being made. When Trump is over, we will be told we won. We will be told that it's time to go back to sleep.
When they tell you everything worked, everything is better, that we can stop because we won, tell them "fuck you! Never again means never again." Destroy every system that ever gave these people power, that ever protected them from consequences, that ever let them hide what they were doing.
These democrats funded a genocide abroad and laid the groundwork for genocide at home. They protected these predators, for years. The whole power structure is guilty. As these files implicate so many powerful people, they're trying to shove everything back in the box. After all the suffering, after we've finally made it clear that we are the once with the power, only now they're willing to sacrifice Trump to calm us all down.
No, that's a good start but it can't be the end.
Winning can't be enough to quench that rage. Keep it burning. When this is over, let victory fan that anger until every institution that made this possible lies in ashes. Burn it all down and salt the earth. Taking down Trump is a great start, but it's not time to give up until this isn't possible again.
#USPol
 @brichapman@mastodon.social
@brichapman@mastodon.socialAI is transforming how we predict hurricanes. NOAA is now using machine learning to analyze billions of data points, making forecasts more accurate than ever.
The results? Better rapid intensification predictions and stronger decision support for coastal communities at risk. As hurricane season wraps, this tech could be a game-changer for saving lives.
@NFL@darktundra.xyzUpset alert in Week 12? Why these favorites could fall, including Patrick Mahomes and the Chiefs
https://www.cbssports.com/nfl/news/upset-alert-week-12-patrick-mahomes-chiefs/<…
 @chris@mstdn.chrisalemany.ca
@chris@mstdn.chrisalemany.caThere were actually a lot of good recommendations from that Committee report, the one on PR was just the final one! Here's a few more.. including some that local #Fediverse proponents could dig into! @… was on the Committee.
—>FEDI ADVANTAGE<— “The Committee heard about a number of issues related to
the electoral information environment. Members recommend
that the provincial government collaborate with Elections
BC and the federal government to review existing legislative
and regulatory measures related to misinformation,
disinformation, and hate speech during elections, including
**mechanisms to ensure the timely removal of harmful content** (**emphasis added)”
—> FEDI ADVANTAGE<— “To better address challenges associated with social media and emergent technologies such as artificial intelligence, Members recommend establishing a working group to propose amendments to BC’s privacy and election legislation. To better protect all users, the Committee recommends requiring digital platforms to act with a duty of care and establish clear safety-related requirements such as data privacy, platform design, and content policy. The Committee also heard about concerns regarding foreign interference, and recommends that these be considered by the Electoral Integrity Working Group.”
—The Committee heard about the critical importance of
civic education to ensure the public’s understanding of
democratic institutions, processes, and participation. The
Committee recommends strengthening civic education
in the K-12 school system with input from experts and a
greater emphasis on applied learning.
— the Committee suggests enhancing data collection by requiring proactive enumeration on an annual basis and ensuring that registered parties and candidates can access poll-by-poll results. Elections BC should review and improve
voter registration practices and communication, as well as
access to and public awareness of voting opportunities. With respect to expanding voter eligibility, the Committee supports further examination of extending voting rights to 16- and 17-year-olds as well as permanent residents in BC.
— Committee Members recommend modernizing the candidate nominator verification process, requiring Elections BC to collect and share voters’ contact information with registered political parties and candidates, and strengthening measures related to access to multi-unit buildings for candidates and their campaigns.
Full report to the Legislature: #BCPoli #CanPoli #CdnPoli #ElectoralReform #Democracy #ProportionalRepresentation #Polarization
 @arXiv_astrophEP_bot@mastoxiv.page
@arXiv_astrophEP_bot@mastoxiv.pageDiscovery of carbon monoxide emission from five debris disks around young A-type stars
A. Mo\'or, P. \'Abrah\'am, \'A, K\'osp\'al, G. Cataldi, A. M. Hughes, S. Marino, Q. Kral, J. Milli, N. Pawellek
https://arxiv.org/abs/2509.16104
@NFL@darktundra.xyz2025 NFL trade deadline: Nine players who could benefit from a change of scenery, including Saints Pro Bowlers
https://www.cbssports.com/nfl/news/2025-nfl-trade-deadline-biggest-tra…
@hex@kolektiva.socialI keep saying the same thing over and over with my kids: you don't make decisions with your voice, you make them with your body.
"I want to go to the park."
"Ok, put your shoes on."
"I want to go on my play date."
"Put on a jacket and get in the bike."
"I don't want to be late to school."
"I don't control time, if you don't want to be late you have to brush your teeth."
There's a fundamental truth underlying this concept though, one that I hadn't really thought about. On some level, I feel as though, any choice you can't make with your body isn't a real choice. If you're begging someone to do something for you, it's ultimately not something you control.
As I'm compelled, by threat of violence against my family, to pay for war against my comrades and to kill people I don't even know, I think about that. How far is our concept of freedom from the police state we are taught to imagine as the global beacon of liberty. My participation in the violence had always been compulsory.
Perhaps we could do better than just #NoKings.
#USPol
@pre@boing.worldA panel on bitcoin treasury companies.
Because investment law makes it hard for institutions to buy bitcoin in their funds. You can't own BTC in you tax free ISA. So some companies that do hold bitcoin, notably microstrategy, became proxy investments. If you can't hold BTC you could maybe own a company that owns BTC instead.
Microstrategy started because it's ceo realized it's dollar treasury was being debased by dollar printing. So tried buying BTC instead, with fantastic success.
Copycat companies proliferated. They boomed and then busted. One panelist calls that a grift. A way to memeticly pump share price.
A line can be drawn between profitable companies just storing their profit in bitcoin Vs those raising debt to buy without having a profitable business.
Imagine a world transiting from using seashells for money to using gold coins. A company gathers seashells from investors to buy gold coins, which will do better than sea shells. Trouble is the next step where the company pays back it's investors with... More seashells.
If you own shares in the company, you do not own bitcoin. You'll just get more old fashioned bank money.
Still. It's worked as marketing, more people being convinced BTC has value.
If you do buy a treasury company, check it's bitcoin not "digital assets" including shitcoins.
#bitfest #bitcoin #bitcoinTreasuryCompanies
 @cowboys@darktundra.xyz
@cowboys@darktundra.xyzCowboys’ Matt Eberflus Has Blunt Message for Bears Before Week 3 Game https://heavy.com/sports/nfl/dallas-cowboys/matt-eberflus-blunt-message-bears/?adt_ei=[email]




